
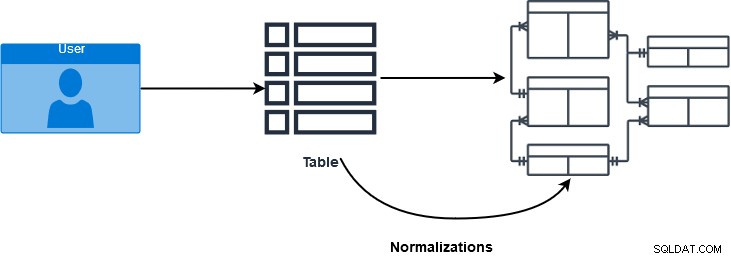
SQL JOIN er en klausul, der bruges til at kombinere flere tabeller og hente data baseret på et fælles felt i relationelle databaser. Databaseprofessionelle bruger normaliseringer til at sikre og forbedre dataintegriteten. I de forskellige normaliseringsformer er data fordelt i flere logiske tabeller. Disse tabeller bruger referencemæssige begrænsninger – primærnøgle og fremmednøgler – til at håndhæve dataintegritet i SQL Server-tabeller. På billedet nedenfor får vi et glimt af databasenormaliseringsprocessen.
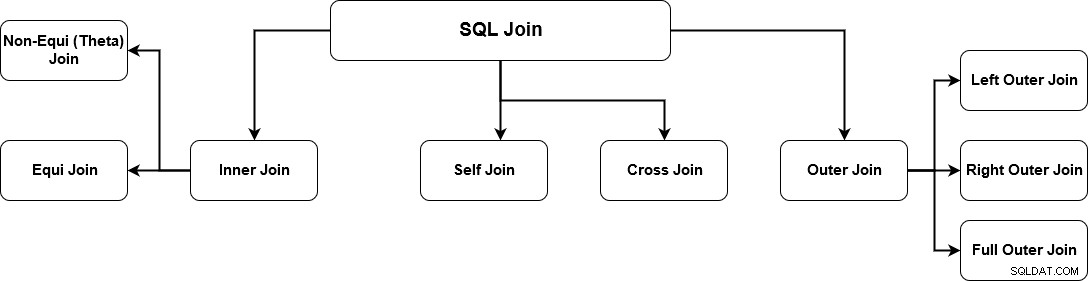
Forståelse af de forskellige SQL JOIN-typer
SQL JOIN genererer meningsfulde data ved at kombinere flere relationelle tabeller. Disse tabeller er relateret ved hjælp af en nøgle og har en-til-en eller en-til-mange relationer. For at hente de korrekte data skal du kende datakravene og korrekte joinmekanismer. SQL Server understøtter flere joinforbindelser, og hver metode har en specifik måde at hente data fra flere tabeller på. Billedet nedenfor angiver de understøttede SQL Server joins.
SQL indre joinforbindelse
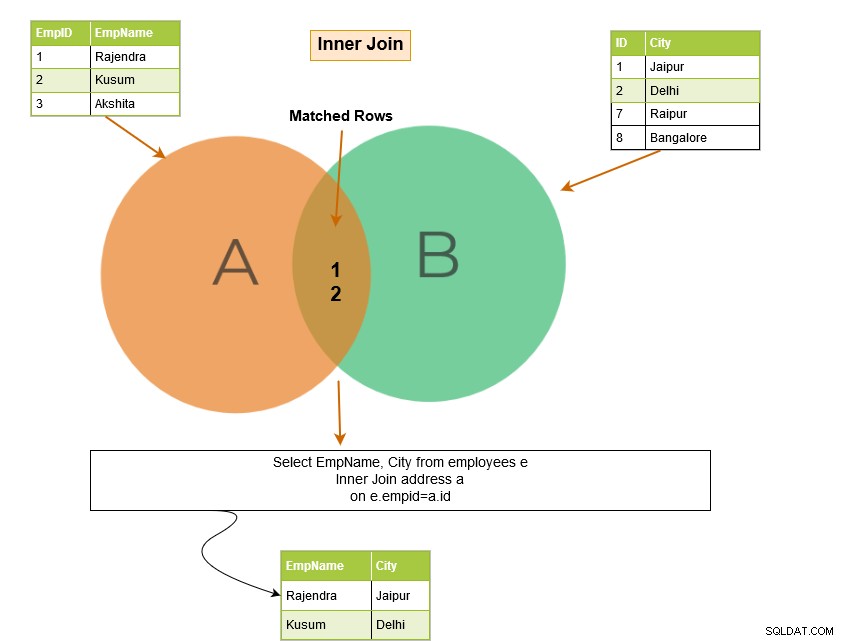
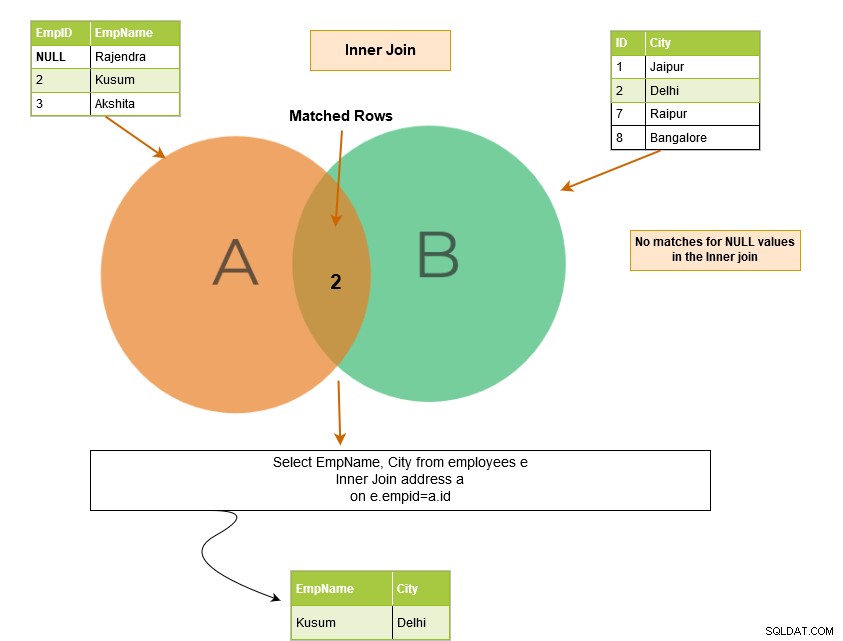
SQL indre join inkluderer rækker fra tabellerne, hvor joinbetingelserne er opfyldt. For eksempel, i Venn-diagrammet nedenfor returnerer indre joinforbindelse de matchende rækker fra tabel A og tabel B.
Bemærk følgende ting i eksemplet nedenfor:
- Vi har to tabeller – [Medarbejdere] og [Adresse].
- SQL-forespørgslen er forbundet i kolonnerne [Medarbejdere].[EmpID] og [Adresse].[ID].
Forespørgselsoutputtet returnerer medarbejderposterne for EmpID, der findes i begge tabeller.
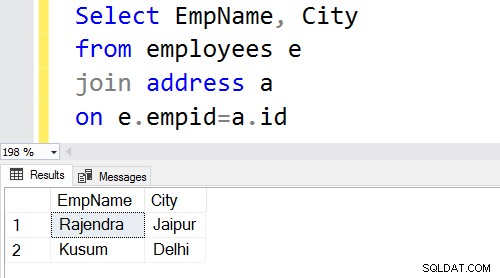
Den indre sammenføjning returnerer matchende rækker fra begge tabeller; derfor er det også kendt som Equi join. Hvis vi ikke angiver det indre nøgleord, udfører SQL Server den indre joinoperation.
I en anden type indre joinforbindelse, en theta join, bruger vi ikke lighedsoperatoren (=) i ON-sætningen. I stedet bruger vi ikke-lighedsoperatorer såsom
VÆLG * FRA Tabel1 T1, Tabel2 T2 HVOR T1.Pris
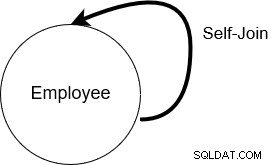
I en selv-join forbinder SQL Server tabellen med sig selv. Dette betyder, at tabelnavnet optræder to gange i fra-klausulen.
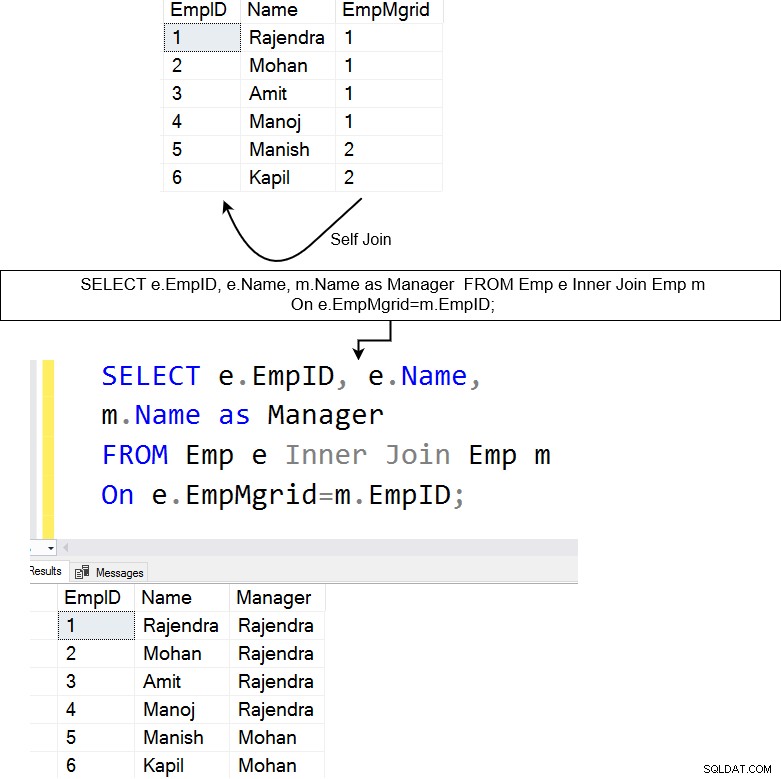
Nedenfor har vi en tabel [Emp], der har medarbejdere såvel som deres lederes data. Selvforbindelsen er nyttig til at forespørge om hierarkiske data. I medarbejdertabellen kan vi f.eks. bruge selvtilslutning til at lære hver medarbejder og deres rapporteringsleders navn.
Ovenstående forespørgsel sætter en selv-join på [Emp]-tabellen. Den forbinder EmpMgrID-kolonnen med EmpID-kolonnen og returnerer de matchende rækker.
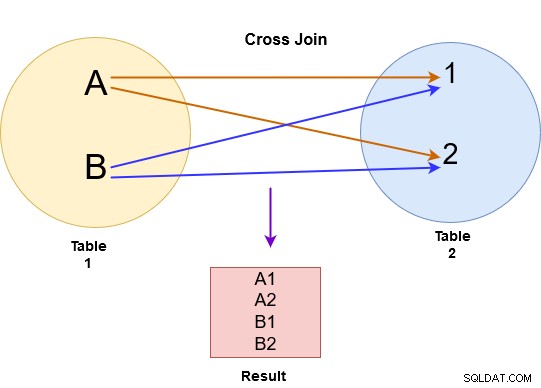
I krydsforbindelsen returnerer SQL Server et kartesisk produkt fra begge tabeller. For eksempel udførte vi på billedet nedenfor en krydsforbindelse for tabel A og B.
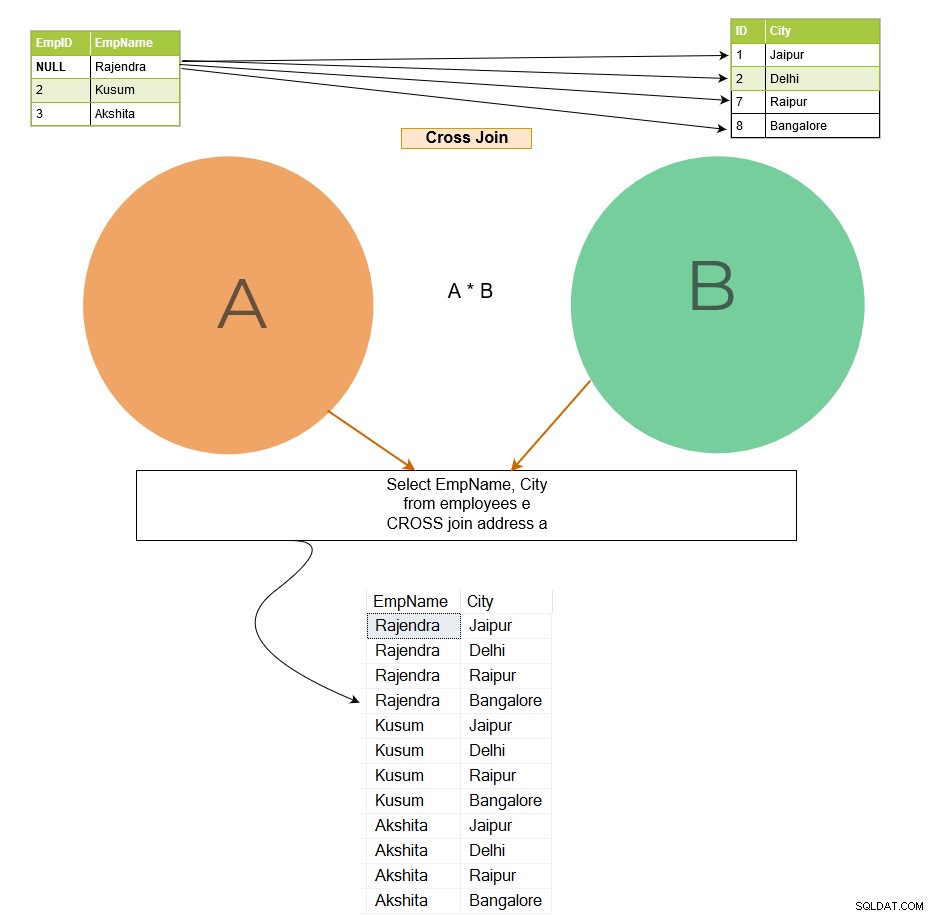
Krydsforbindelsen forbinder hver række fra tabel A til hver række tilgængelige i tabel B. Derfor er output også kendt som et kartesisk produkt af begge tabeller. Bemærk følgende på billedet nedenfor:
I krydssammenføjningsoutputtet forbindes række 1 i tabellen [Medarbejder] med alle rækker i tabellen [Adresse] og følger det samme mønster for de resterende rækker.
Hvis den første tabel har x antal rækker og den anden tabel har n antal rækker, giver cross join x*n antal rækker i outputtet. Du bør undgå cross join på større tabeller, fordi det kan returnere et stort antal poster, og SQL Server kræver meget computerkraft (CPU, hukommelse og IO) til at håndtere så omfattende data.
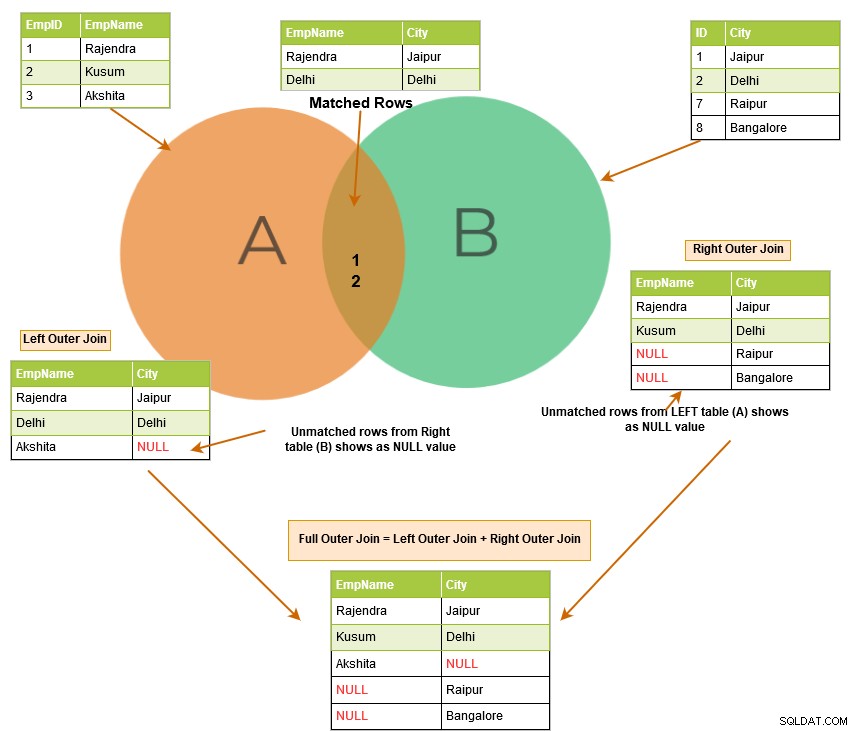
Som vi forklarede tidligere, returnerer den indre joinforbindelse de matchende rækker fra begge tabeller. Når du bruger en SQL-ydre joinforbindelse, viser den ikke kun de matchende rækker, men den returnerer også de umatchede rækker fra de andre tabeller. Den umatchede række afhænger af de venstre, højre eller hele søgeord.
Billedet nedenfor beskriver på et højt niveau venstre, højre og fuld ydre sammenføjning.
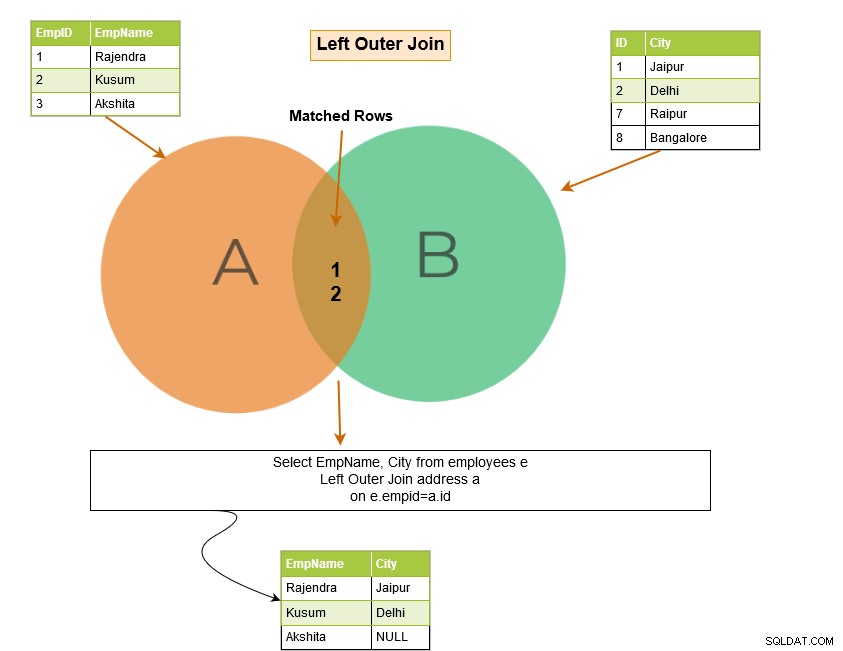
SQL venstre ydre joinforbindelse returnerer de matchende rækker i begge tabeller sammen med de umatchede rækker fra den venstre tabel. Hvis en post fra den venstre tabel ikke har nogen matchende rækker i den højre tabel, viser den posten med NULL-værdier.
I eksemplet nedenfor returnerer den venstre ydre join følgende rækker:
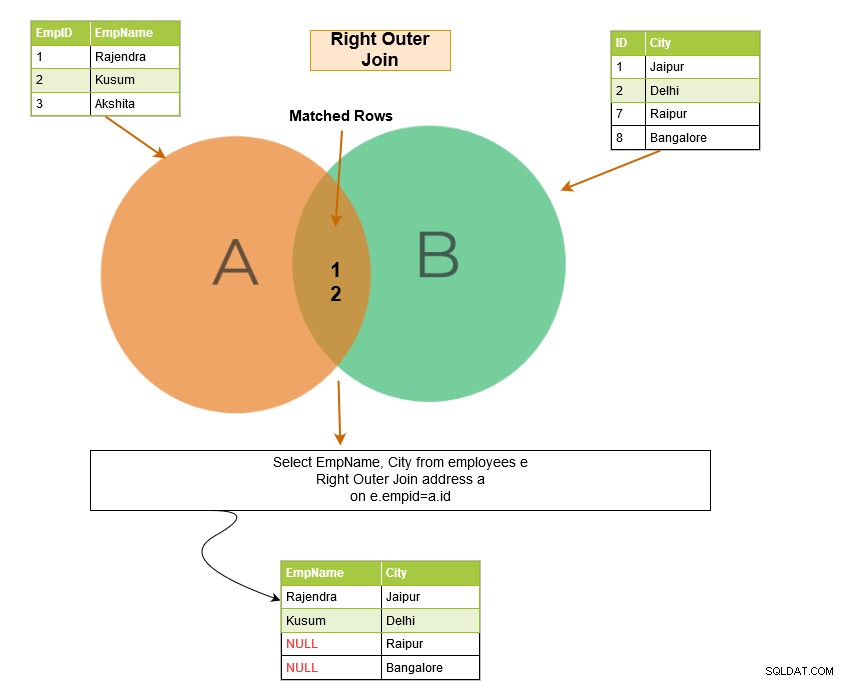
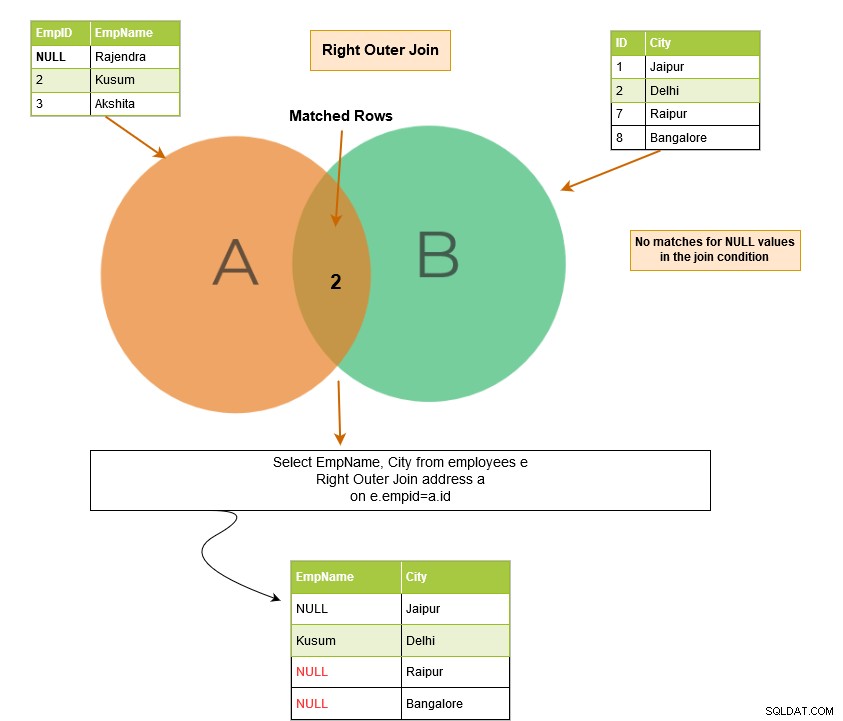
SQL right outer join returnerer de matchende rækker i begge tabeller sammen med de umatchede rækker fra den højre tabel. Hvis en post fra den højre tabel ikke har nogen matchende rækker i den venstre tabel, viser den posten med NULL-værdier.
I eksemplet nedenfor har vi følgende outputrækker:
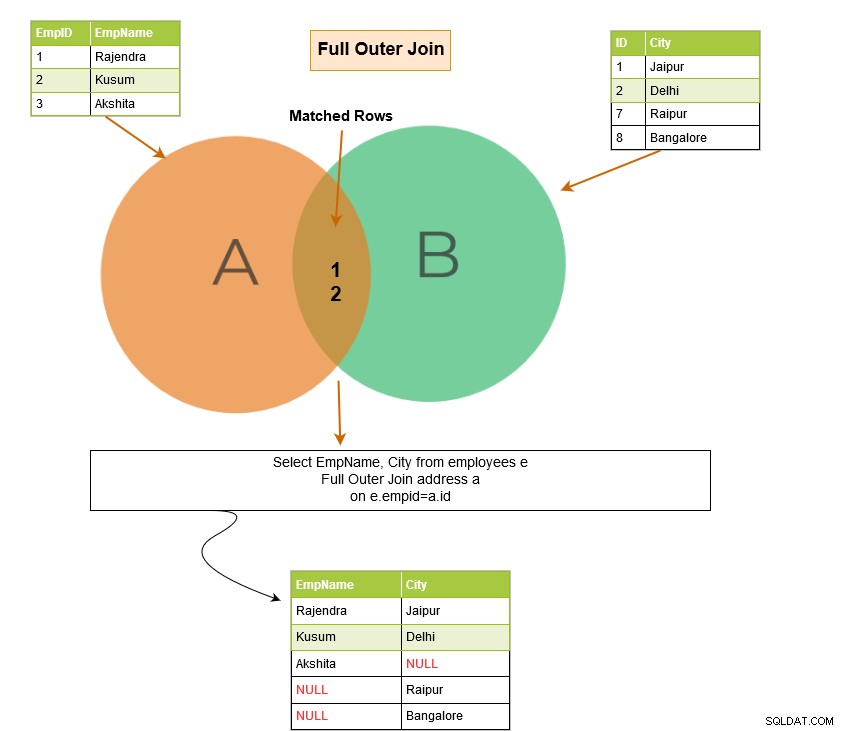
En fuld ydre joinforbindelse returnerer følgende rækker i outputtet:
I de foregående eksempler bruger vi to tabeller i en SQL-forespørgsel til at udføre join-operationer. For det meste slår vi flere tabeller sammen, og det returnerer de relevante data.
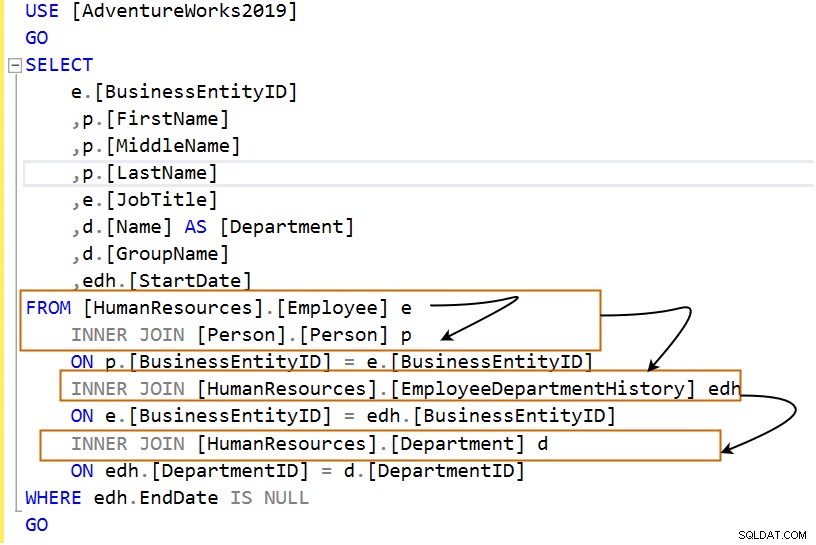
Nedenstående forespørgsel bruger flere indre joinforbindelser.
Lad os analysere forespørgslen i følgende trin:
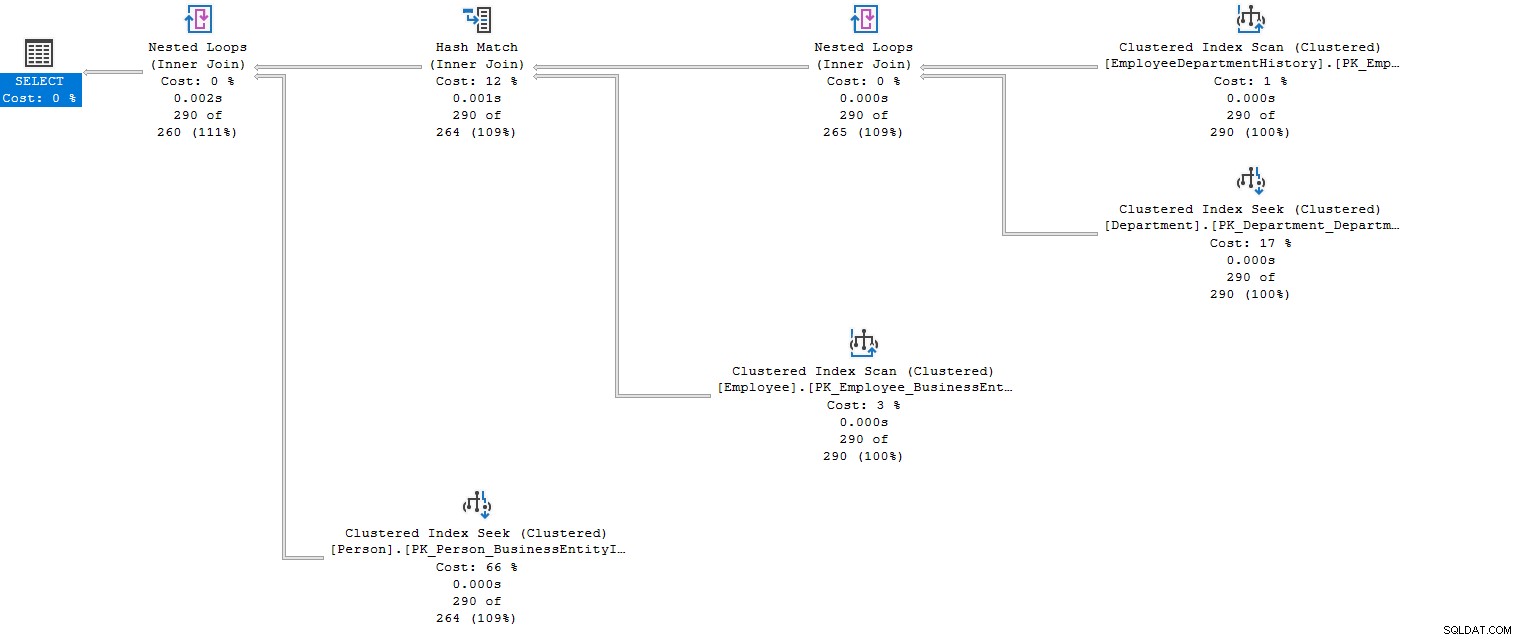
Når du udfører forespørgslen med flere joinforbindelser, forbereder forespørgselsoptimering udførelsesplanen. Den udarbejder en omkostningsoptimeret eksekveringsplan, der opfylder joinbetingelserne med ressourceforbrug - for eksempel i nedenstående faktiske udførelsesplan kan vi se på flere indlejrede loops (indre join) og hash-match (indre joinforbindelse) ved at kombinere data fra flere sammenføjningstabeller .
Antag, at vi har NULL-værdier i tabelkolonnerne, og vi forbinder tabellerne på disse kolonner. Matcher SQL Server NULL-værdier?
NULL-værdierne matcher ikke hinanden. Derfor kunne SQL Server ikke returnere den matchende række. I eksemplet nedenfor har vi NULL i EmpID-kolonnen i tabellen [Medarbejdere]. Derfor returnerer den i outputtet kun den matchende række for [EmpID] 2.
Vi kan få denne NULL-række i outputtet i tilfælde af en SQL-ydre joinforbindelse, fordi den også returnerer de umatchede rækker.
I denne artikel undersøgte vi de forskellige SQL join-typer. Her er et par vigtige bedste fremgangsmåder, du skal huske og anvende, når du bruger SQL-joins.SQL selvtilmelding
SQL cross join
SQL ydre joinforbindelse
Venstre ydre sammenføjning
Højre ydre samling
Fuld ydre sammenføjning
SQL forbindes med flere tabeller
USE [AdventureWorks2019]
GO
SELECT
e.[BusinessEntityID]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
GO
NULL-værdier og SQL-forbindelser
SQL deltager i bedste praksis