Hvad får krydsanvendelsesforespørgslen til at fungere så dårligt på dette simple XML-dokument og udføre eksponentielt langsommere, efterhånden som datasættet vokser?
Det er brugen af den overordnede akse til at hente attribut-id'et fra vareknuden.
Det er denne del af forespørgselsplanen, der er problematisk.

Læg mærke til de 423 rækker, der kommer ud af den nederste tabelværdi-funktion.
Tilføjelse af blot en vareknude mere med tre feltnoder giver dig dette.
732 rækker returneret.
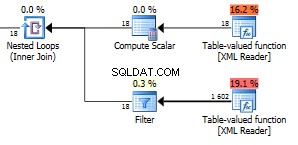
Hvad hvis vi fordobler noderne fra den første forespørgsel til i alt 6 varenoder?
Vi er oppe på hele 1602 rækker returneret.
Figuren 18 i den øverste funktion er alle feltnoder i din XML. Vi har her 6 varer med tre felter i hver vare. Disse 18 noder bruges i en indlejret sløjfe sammen med den anden funktion, så 18 udførelser, der returnerer 1602 rækker, giver, at den returnerer 89 rækker pr. iteration. Det er tilfældigvis det nøjagtige antal noder i hele XML. Nå det er faktisk en mere end alle de synlige noder. Jeg ved ikke hvorfor. Du kan bruge denne forespørgsel til at kontrollere det samlede antal noder i din XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Altså den algoritme, der bruges af SQL Server til at få værdien, når du bruger den overordnede akse .. i en værdifunktion er, at den først finder alle de noder, du makulerer på, 18 i det sidste tilfælde. For hver af disse noder makulerer og returnerer hele XML-dokumentet og tjekker filteroperatoren for den node, du rent faktisk ønsker. Der har du din eksponentielle vækst. I stedet for at bruge den overordnede akse skal du bruge et ekstra kryds. Makuler først på emne og derefter på felt.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Jeg har også ændret, hvordan du får adgang til feltets tekstværdi. Bruger . vil få SQL Server til at søge efter underordnede noder til field og sammenkæde disse værdier i resultatet. Du har ingen underordnede værdier, så resultatet er det samme, men det er en god ting at undgå at have den del i forespørgselsplanen (UDX-operatøren).
Forespørgselsplanen har ikke problemet med den overordnede akse, hvis du bruger et XML-indeks, men du vil stadig drage fordel af at ændre, hvordan du henter feltværdien.