SQL Server 2008 introducerede sparse kolonner som en metode til at reducere lagring for nul-værdier og give mere udvidelsesmuligheder. Afvejningen er, at der er ekstra overhead, når du gemmer og henter ikke-NULL værdier. Jeg var interesseret i at forstå omkostningerne ved at gemme ikke-NULL-værdier efter at have talt med en kunde, der brugte denne datatype i et staging-miljø. De søger at optimere skriveydelsen, og jeg spekulerede på, om brugen af sparsomme kolonner havde nogen effekt, da deres metode krævede at indsætte en række i tabellen og derefter opdatere den. Jeg lavede et konstrueret eksempel til denne demo, forklaret nedenfor, for at afgøre, om dette var en god metode for dem at bruge.
Intern gennemgang
Som en hurtig gennemgang skal du huske, at når du opretter en kolonne til en tabel, der tillader NULL-værdier, hvis det er en kolonne med fast længde (f.eks. en INT), vil den altid forbruge hele kolonnebredden på siden, selv når kolonnen er NUL. Hvis det er en kolonne med variabel længde (f.eks. VARCHAR), vil den forbruge mindst to bytes i kolonneoffset-arrayet, når NULL, medmindre kolonnerne er efter den sidst udfyldte kolonne (se Kimberlys blogindlæg Kolonnerækkefølgen betyder ikke noget ... generelt , men – DET AFHÆNGER). En sparsom kolonne kræver ikke plads på siden til NULL-værdier, uanset om det er en kolonne med fast længde eller variabel længde, og uanset hvilke andre kolonner der er udfyldt i tabellen. Afvejningen er, at når en sparsom kolonne er udfyldt, tager den fire (4) flere bytes lagerplads end en ikke-spare kolonne. For eksempel:
| Kolonnetype | Lagringskrav |
|---|---|
| BIGINT kolonne, ikke sparsom, med nej værdi | 8 bytes |
| BIGINT kolonne, ikke-sparsom, med en værdi | 8 bytes |
| STOR kolonne, sparsom, med nej værdi | 0 bytes |
| STOR kolonne, sparsom, med en værdi | 12 bytes |
Derfor er det vigtigt at bekræfte, at lagringsfordelen opvejer det potentielle præstationshit ved hentning - hvilket kan være ubetydeligt baseret på balancen mellem læsning og skrivning i forhold til dataene. De anslåede pladsbesparelser for forskellige datatyper er dokumenteret i Books Online-linket ovenfor.
Testscenarier
Jeg opsatte fire forskellige scenarier til test, beskrevet nedenfor, og hver tabel havde en ID-kolonne (INT), en Navn-kolonne (VARCHAR(100)) og en Type-kolonne (INT) og derefter 997 NULLABLE-kolonner.
| Test-id | Tabelbeskrivelse | DML Operations |
|---|---|---|
| 1 | 997 kolonner af INT-datatype, NULLABLE, ikke-sparse | Indsæt én række ad gangen, udfyld ID, Navn, Type og ti (10) tilfældige NULLABLE-kolonner |
| 2 | 997 kolonner af INT-datatype, NULLABLE, sparse | Indsæt én række ad gangen, udfyld ID, Navn, Type og ti (10) tilfældige NULLABLE-kolonner |
| 3 | 997 kolonner af INT-datatype, NULLABLE, ikke-sparse | Indsæt én række ad gangen, udfyld ID, Navn, Type kun, opdater derefter rækken, og tilføj værdier for ti (10) tilfældige NULLABLE-kolonner |
| 4 | 997 kolonner af INT-datatype, NULLABLE, sparse | Indsæt én række ad gangen, udfyld ID, Navn, Type kun, opdater derefter rækken, og tilføj værdier for ti (10) tilfældige NULLABLE-kolonner |
| 5 | 997 kolonner med VARCHAR-datatype, NULLABLE, ikke-spare | Indsæt én række ad gangen, udfyld ID, Navn, Type og ti (10) tilfældige NULLABLE-kolonner |
| 6 | 997 kolonner med VARCHAR-datatype, NULLABLE, sparse | Indsæt én række ad gangen, udfyld ID, Navn, Type og ti (10) tilfældige NULLABLE-kolonner |
| 7 | 997 kolonner med VARCHAR-datatype, NULLABLE, ikke-spare | Indsæt én række ad gangen, udfyld ID, Navn, Type kun, opdater derefter rækken, og tilføj værdier for ti (10) tilfældige NULLABLE-kolonner |
| 8 | 997 kolonner med VARCHAR-datatype, NULLABLE, sparse | Indsæt én række ad gangen, udfyld ID, Navn, Type kun, opdater derefter rækken, og tilføj værdier for ti (10) tilfældige NULLABLE-kolonner |
Hver test blev kørt to gange med et datasæt på 10 millioner rækker. De vedhæftede scripts kan bruges til at replikere test, og trinene var som følger for hver test:
- Opret en ny database med foruddefinerede data og logfiler
- Opret den relevante tabel
- Snapshot ventestatistik og filstatistik
- Bemærk starttidspunktet
- Kør DML'en (én indsættelse eller én indsættelse og én opdatering) for 10 millioner rækker
- Bemærk stoptidspunktet
- Snapshot ventestatistik og filstatistik, og skriv til en logningstabel i en separat database på separat lager
- Snapshot dm_db_index_physical_stats
- Slet databasen
Test blev udført på en Dell PowerEdge R720 med 64 GB hukommelse og 12 GB allokeret til SQL Server 2014 SP1 CU4-instansen. Fusion-IO SSD'er blev brugt til datalagring for databasefilerne.
Resultater
Testresultater præsenteres nedenfor for hvert testscenarie.
Varighed
I alle tilfælde tog det mindre tid (gennemsnitligt 11,6 minutter) at udfylde tabellen, når der blev brugt sparsomme kolonner, selv når rækken først blev indsat og derefter opdateret. Da rækken først blev indsat og derefter opdateret, tog testen næsten dobbelt så lang tid at køre sammenlignet med, da rækken blev indsat, da der blev udført dobbelt så mange dataændringer.
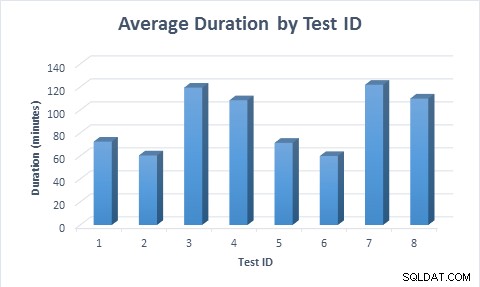 Gennemsnitlig varighed for hvert testscenarie
Gennemsnitlig varighed for hvert testscenarie
Ventstatistik
| Test-id | Gennemsnitlig procentdel | Gennemsnitlig ventetid (sekunder) |
|---|---|---|
| 1 | 16.47 | 0,0001 |
| 2 | 14.00 | 0,0001 |
| 3 | 16.65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12.80 | 0,0001 |
| 6 | 13.99 | 0,0001 |
| 7 | 14.85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Ventestatistikkerne var konsistente for alle test, og der kan ikke drages konklusioner baseret på disse data. Hardwaren opfyldte tilstrækkeligt ressourcekravene i alle testtilfælde.
Filstatistik
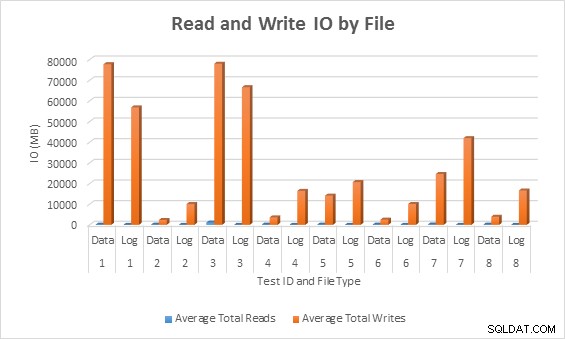 Gennemsnitlig IO (læse og skrive) pr. databasefil
Gennemsnitlig IO (læse og skrive) pr. databasefil
I alle tilfælde genererede testene med sparsomme kolonner mindre IO (især skrivninger) sammenlignet med ikke-sparsomme kolonner.
Indeks fysisk statistik
| Testcase | Rækkeantal | Samlet antal sider (klynget indeks) | Samlet plads (GB) | Gennemsnitlig plads brugt til bladsider i CI (%) | Gennemsnitlig registreringsstørrelse (bytes) |
|---|---|---|---|---|---|
| 1 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,49 |
| 2 | 10.000.000 | 301.429 | 2 | 98.51 | 237,50 |
| 3 | 10.000.000 | 10.037.312 | 76 | 51,70 | 4.184,50 |
| 4 | 10.000.000 | 460.960 | 3 | 64.41 | 237,50 |
| 5 | 10.000.000 | 1.823.083 | 13 | 90.31 | 1.326,08 |
| 6 | 10.000.000 | 324.162 | 2 | 98.40 | 255.28 |
| 7 | 10.000.000 | 3.161.224 | 24 | 52.09 | 1.326,39 |
| 8 | 10.000.000 | 503.592 | 3 | 63.33 | 255.28 |
Der er betydelige forskelle i pladsforbruget mellem de ikke-sparsomme og sparsomme borde. Dette er mest bemærkelsesværdigt, når man ser på testcase 1 og 3, hvor en datatype med fast længde blev brugt (INT), sammenlignet med testcase 5 og 7, hvor en datatype med variabel længde blev brugt (VARCHAR(255)). Heltalskolonnerne bruger diskplads, selv når de er NULL. Kolonnerne med variabel længde bruger mindre diskplads, da der kun bruges to bytes i offset-arrayet for NULL-kolonner, og ingen bytes for de NULL-kolonner, der er efter den sidst udfyldte kolonne i rækken.
Yderligere forårsager processen med at indsætte en række og derefter opdatere den fragmentering for kolonnetesten med variabel længde (tilfælde 7), sammenlignet med blot at indsætte rækken (tilfælde 5). Tabelstørrelsen fordobles næsten, når indsættelsen efterfølges af opdateringen, på grund af sideopdelinger, der opstår ved opdatering af rækkerne, hvilket efterlader siderne halvfulde (mod 90 % fulde).
Oversigt
Som konklusion ser vi en betydelig reduktion i diskplads og IO, når der bruges sparsomme kolonner, og de klarer sig lidt bedre end ikke-sparse kolonner i vores simple datamodifikationstests (bemærk, at genfindingsydeevne også bør overvejes; måske emnet for en anden post).
Sparse kolonner har et meget specifikt brugsscenarie, og det er vigtigt at undersøge mængden af gemt diskplads baseret på datatypen for kolonnen og antallet af kolonner, der typisk vil være udfyldt i tabellen. I vores eksempel havde vi 997 sparsomme kolonner, og vi udfyldte kun 10 af dem. Højst, i det tilfælde, hvor den anvendte datatype var heltal, ville en række på bladniveauet af det klyngede indeks forbruge 188 bytes (4 bytes for ID'et, 100 bytes maks. for Navnet, 4 bytes for typen og derefter 80 bytes for 10 kolonner). Når 997 kolonner ikke var sparsomme, blev der tildelt 4 bytes for hver kolonne, selv når NULL, så hver række var mindst 4.000 bytes på bladniveau. I vores scenarie er sparsomme kolonner absolut acceptable. Men hvis vi udfyldte 500 eller flere sparsomme kolonner med værdier for en INT-kolonne, så går pladsbesparelsen tabt, og modifikationsydelsen er muligvis ikke længere bedre.
Afhængigt af datatypen for dine kolonner og det forventede antal kolonner, der skal udfyldes af det samlede antal, kan det være en god ide at udføre lignende test for at sikre, at ved brug af sparsomme kolonner, er indsætningsydelse og -lagring sammenlignelig eller bedre, end når du bruger ikke -sparsomme søjler. I tilfælde, hvor ikke alle kolonner er udfyldt, er sparsomme kolonner bestemt værd at overveje.