Hvad angår grafiske udførelsesplaner, er der kun ét ikon for en fysisk sortering i SQL Server:

Det samme ikon bruges til de tre logiske sorteringsoperatorer:Sort, Top N Sort og Distinct Sort:
Går man et niveau dybere, er der fire forskellige implementeringer af Sort i udførelsesmotoren (bortset fra batchsortering for optimerede loop joins, som ikke er en fuld sortering og alligevel ikke er synlig i planer). Hvis du bruger SQL Server 2014, øges antallet af execution engine Sort-implementeringer til syv:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (kun SQL Server 2014)
- CQScanInMemSortNew
- In-Memory OLTP (Hekaton) indbygget kompileret procedure Top N Sort (kun SQL Server 2014)
- In-Memory OLTP (Hekaton) indbygget kompileret procedure General Sort (kun SQL Server 2014)
Denne artikel ser på disse slags implementeringer, og hvornår hver af dem bruges i SQL Server. Del et dækker de første fire punkter på listen.
1. CQScanSortNew
Dette er den mest generelle sorteringsklasse, der bruges, når ingen af de andre tilgængelige muligheder er anvendelige. Generel sortering bruger en arbejdsområdehukommelsesbevilling, der er reserveret lige før forespørgselsudførelsen begynder. Denne bevilling er proportional med kardinalitetsestimater og gennemsnitlige rækkestørrelsesforventninger og kan ikke øges efter at forespørgselsudførelsen begynder.
Den nuværende implementering ser ud til at bruge en række interne flettesorteringer (måske binær flettesortering), overgang til ekstern flettesortering (med flere gennemløb, hvis det er nødvendigt), hvis den reserverede hukommelse viser sig at være utilstrækkelig. Ekstern flettesortering bruger fysisk tempdb plads til sorteringsløb, der ikke passer i hukommelsen (almindeligvis kendt som et sorteringsspild). Generel sortering kan også konfigureres til at anvende distinkthed under sorteringsoperationen.
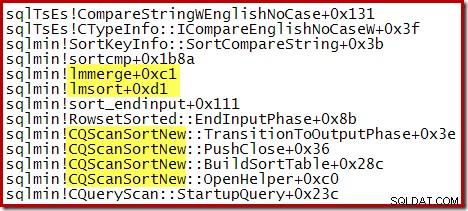
Følgende delvise staksporing viser et eksempel på CQScanSortNew klasses sorteringsstrenge ved hjælp af en intern flettesortering:
I udførelsesplaner giver Sort information om den brøkdel af den overordnede forespørgselsarbejdsområdehukommelsesbevilling, der er tilgængelig for sorteringen ved læsning af poster (inputfasen), og den brøkdel, der er tilgængelig, når sorteret output forbruges af overordnede planoperatører (outputfasen) ).
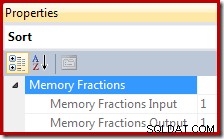
Hukommelsestildelingsbrøken er et tal mellem 0 og 1 (hvor 1 =100 % af den tildelte hukommelse) og er synlig i SSMS ved at fremhæve Sortér og se i vinduet Egenskaber. Eksemplet nedenfor er taget fra en forespørgsel med kun en enkelt sorteringsoperator, så den har den fulde forespørgselsarbejdspladshukommelse tilgængelig under både input- og outputfaser:
Hukommelsesfraktionerne afspejler det faktum, at Sort i sin inputfase skal dele den overordnede forespørgselshukommelsestildeling med samtidig eksekverende hukommelsesforbrugende operatører under den i eksekveringsplanen. På samme måde skal Sort i udgangsfasen dele tildelt hukommelse med samtidig eksekverende hukommelsesforbrugende operatører over den i udførelsesplanen.
Forespørgselsprocessoren er smart nok til at vide, at nogle operatører blokerer (stop-and-go), og markerer effektivt grænser, hvor hukommelsesbevillingen kan genbruges og genbruges. I parallelle planer er hukommelsesbevillingsfraktionen, der er tilgængelig for en generel sortering, delt jævnt mellem tråde og kan ikke rebalanceres under kørsel i tilfælde af skævhed (en almindelig årsag til spild i parallelle sorteringsplaner).
SQL Server 2012 og nyere indeholder yderligere oplysninger om den minimumstildeling af arbejdsområdehukommelse, der kræves for at initialisere hukommelseskrævende planoperatører, og den ønskede hukommelsesbevilling (den "ideelle" mængde hukommelse, der skønnes at være nødvendig for at fuldføre hele operationen i hukommelsen). I en post-execution ("faktisk") eksekveringsplan er der også ny information om eventuelle forsinkelser i erhvervelsen af hukommelsesbevillingen, den maksimale mængde hukommelse, der faktisk blev brugt, og hvordan hukommelsesreservationen blev fordelt på tværs af NUMA noder.
Følgende AdventureWorks-eksempler bruger alle en CQScanSortNew generel sortering:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Den første forespørgsel (en ikke-særlig sortering) producerer følgende eksekveringsplan:
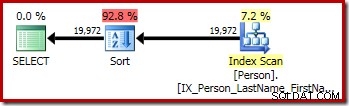
Den anden og tredje (ækvivalente) forespørgsel producerer denne plan:
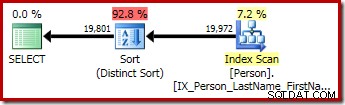
CQScanSortNew kan bruges til både logisk generel sortering og logisk distinkt sortering.
2. CQScanTopSortNew
CQScanTopSortNew er en underklasse af CQScanSortNew bruges til at implementere en Top N Sort (som navnet antyder). CQScanTopSortNew uddelegerer meget af kernearbejdet til CQScanSortNew , men ændrer den detaljerede adfærd på forskellige måder, afhængigt af værdien af N.
For N> 100, CQScanTopSortNew er i bund og grund bare en almindelig CQScanSortNew sortering, der automatisk stopper med at producere sorterede rækker efter N rækker. For N <=100, CQScanTopSortNew bevarer kun de aktuelle Top N-resultater under sorteringsoperationen og holder styr på den laveste nøgleværdi, der i øjeblikket kvalificerer.
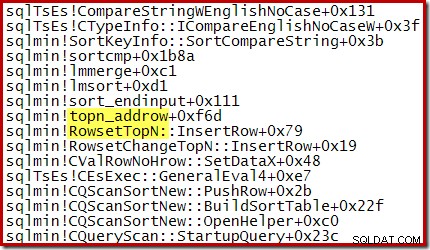
For eksempel, under en optimeret Top N Sort (hvor N <=100) har opkaldsstakken RowsetTopN hvorimod vi med den generelle sortering i afsnit 1 så RowsetSorted :
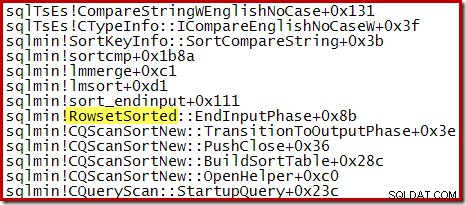
For en Top N-sortering, hvor N> 100, er opkaldsstakken på samme trin i udførelsen den samme som den generelle sortering, der er set tidligere:
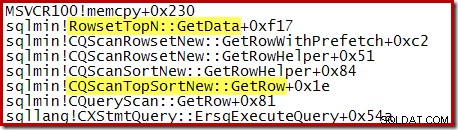
Bemærk, at CQScanTopSortNew klassenavn vises ikke i nogen af disse stakspor. Dette skyldes simpelthen måden underklassificering fungerer på. På andre tidspunkter under udførelsen af disse forespørgsler, CQScanTopSortNew metoder (f.eks. Open, GetRow og CreateTopNTable) vises eksplicit på opkaldsstakken. Som et eksempel er følgende taget på et senere tidspunkt i forespørgselsudførelsen og viser CQScanTopSortNew klassenavn:
Top N Sort og Query Optimizer
Forespørgselsoptimeringsværktøjet ved intet om Top N Sort, som kun er en execution engine-operatør. Når optimeringsværktøjet producerer et outputtræ med en fysisk Top-operator umiddelbart over en (ikke-distinkt) fysisk sortering, kan en efter-optimeringsomskrivning kollapse de to fysiske operationer til en enkelt Top N Sort-operator. Selv i N> 100 tilfælde repræsenterer dette en besparelse i forhold til at passere rækker iterativt mellem et sorteringsoutput og et topinput.
Følgende forespørgsel bruger et par udokumenterede sporingsflag til at vise optimeringsoutputtet og omskrivningen efter optimering i aktion:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352);> Optimizerens outputtræ viser separate fysiske top- og sorteringsoperatorer:
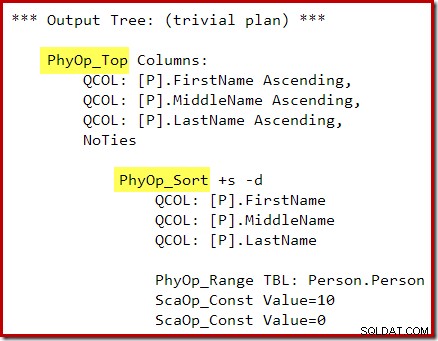
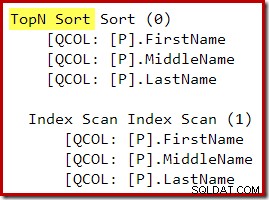
Efter omskrivningen efter optimering er Top og Sort blevet foldet sammen til en enkelt Top N Sort:
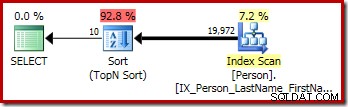
Den grafiske udførelsesplan for T-SQL-forespørgslen ovenfor viser den enkelte Top N Sort-operator:
Breaking the Top N Sort-omskrivning
Top N Sort efter-optimering omskrivningen kan kun kollapse en tilstødende Top og ikke-distinkt sortering til en Top N Sort. Tilføjelse af DISTINCT (eller den tilsvarende GROUP BY-klausul) til forespørgslen ovenfor vil forhindre Top N Sort-omskrivningen:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Den endelige udførelsesplan for denne forespørgsel indeholder separate top- og sorteringsoperatorer (Distinct Sort):
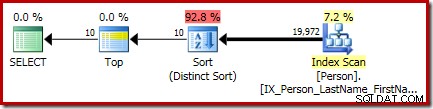
Sorteringen der er den generelle CQScanSortNew klasse kører i distinkt tilstand som set i afsnit 1 tidligere.
En anden måde at forhindre omskrivning til en Top N Sort er at introducere en eller flere ekstra operatorer mellem Top og Sort. For eksempel:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Forespørgselsoptimeringsprogrammets output har nu tilfældigvis en operation mellem Top og Sort, så en Top N Sort genereres ikke under omskrivningsfasen efter optimering:
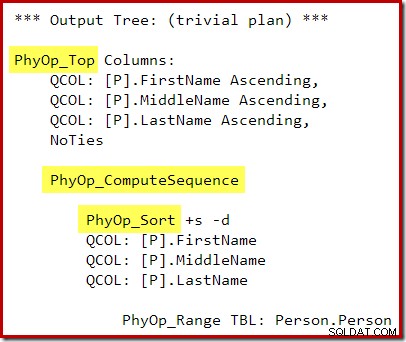
Udførelsesplanen er:

Beregningssekvensen (implementeret som to segmenter og et sekvensprojekt) mellem Top og Sort forhindrer sammenbrud af Top og Sort til en enkelt Top N Sort operator. Korrekte resultater vil naturligvis stadig blive opnået fra denne plan, men udførelsen kan være lidt mindre effektiv, end den kunne have været med den kombinerede Top N Sort-operatør.
3. CQScanIndexSortNew
CQScanIndexSortNew bruges kun til sortering i DDL indeks byggeplaner. Den genbruger nogle af de generelle sorteringsfaciliteter, vi allerede har set, men tilføjer specifikke optimeringer til indeksindsættelser. Det er også den eneste sorteringsklasse, der dynamisk kan anmode om mere hukommelse efter at udførelsen er begyndt.
Kardinalitetsestimat er ofte nøjagtigt for en indeksbygningsplan, fordi det samlede antal rækker i tabellen normalt er en kendt mængde. Dermed ikke sagt, at hukommelsesbevillinger til indeksbygningsplansortering altid vil være nøjagtige; det gør det bare lidt mindre nemt at demo. Så det følgende eksempel bruger en udokumenteret, men rimeligt velkendt udvidelse til kommandoen UPDATE STATISTICS for at narre optimeringsværktøjet til at tro, at den tabel, vi bygger et indeks på, kun har én række:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Post-execution ("faktiske") eksekveringsplan for indeksbuildet viser ikke en advarsel for en spildt sortering (når den køres på SQL Server 2012 eller nyere) på trods af 1-rækkes estimatet og de 19.972 rækker, der faktisk er sorteret:
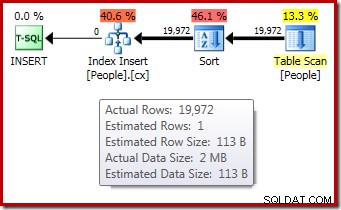
Bekræftelse af, at den oprindelige hukommelsestildeling blev dynamisk udvidet, kommer fra at se på rod-iteratorens egenskaber. Forespørgslen fik oprindeligt 1024KB hukommelse, men forbrugte til sidst 1576KB:
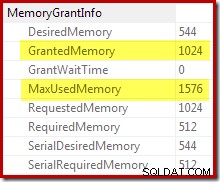
Den dynamiske stigning i tildelt hukommelse kan også spores ved hjælp af debug-kanalen Extended Event sort_memory_grant_adjustment. Denne hændelse genereres hver gang hukommelsesallokeringen øges dynamisk. Hvis denne hændelse overvåges, kan vi fange et stakspor, når det udgives, enten via udvidede hændelser (med en akavet konfiguration og et sporingsflag) eller fra en tilknyttet debugger, som nedenfor:
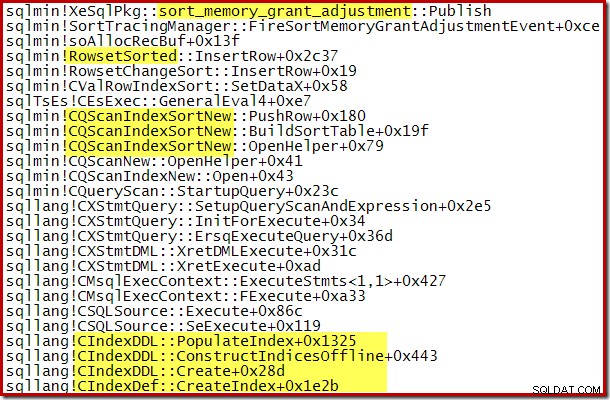
Dynamisk hukommelsestilskudsudvidelse kan også hjælpe med parallelle indeksopbygningsplaner, hvor fordelingen af rækker på tværs af tråde er ujævn. Mængden af hukommelse, der kan forbruges på denne måde, er dog ikke ubegrænset. SQL Server kontrollerer hver gang en udvidelse er nødvendig for at se, om anmodningen er rimelig i betragtning af de tilgængelige ressourcer på det tidspunkt.
En vis indsigt i denne proces kan opnås ved at aktivere udokumenteret sporingsflag 1504 sammen med 3604 (til meddelelsesoutput til konsollen) eller 3605 (output til SQL Server-fejllog). Hvis indeksopbygningsplanen er parallel, er kun 3605 effektiv, fordi parallelle arbejdere ikke kan sende sporingsmeddelelser på tværs af tråde til konsollen.
Følgende sektion af sporingsoutput blev fanget, mens der blev bygget et moderat stort indeks på en SQL Server 2014-instans med begrænset hukommelse:
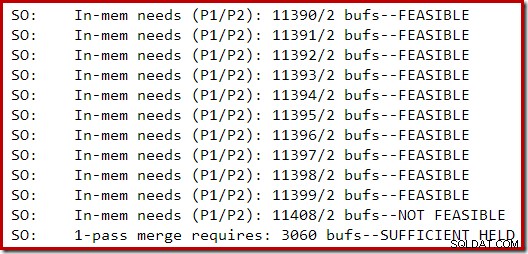
Hukommelsesudvidelsen for sorteringen fortsatte, indtil anmodningen blev anset for uigennemførlig, hvorefter det blev fastslået, at der allerede var tilstrækkelig hukommelse til, at et enkelt-pass sorteringsspil kunne fuldføres.
4. CQScanPartitionSortNew
Dette klassenavn kan tyde på, at denne type sortering bruges til partitionerede tabeldata, eller når der bygges indekser på partitionerede tabeller, men ingen af disse er faktisk tilfældet. Sortering af partitionerede data bruger CQScanSortNew eller CQScanTopSortNew som normalt; sortering af rækker til indsættelse i et partitioneret indeks bruger generelt CQScanIndexSortNew som det ses i afsnit 3.
CQScanPartitionSortNew sorteringsklassen er kun til stede i SQL Server 2014. Den bruges kun ved sortering af rækker efter partitions-id før indsættelse i et partitioneret klynget kolonnelagerindeks . Bemærk, at det kun bruges til partitioneret clustered columnstore; almindelige (ikke-opdelte) klyngede kolonnelagerindsættelsesplaner har ikke gavn af en sortering.
Indsættelser i et partitioneret clustered columnstore-indeks vil ikke altid indeholde en sortering. Det er en omkostningsbaseret beslutning, der afhænger af det estimerede antal rækker, der skal indsættes. Hvis optimeringsværktøjet vurderer, at det er værd at sortere insertene efter partition for at optimere I/O, vil columnstore insert-operatoren have DMLRequestSort egenskab sat til sand, og en CQScanPartitionSortNew sortering kan forekomme i udførelsesplanen.
Demoen i dette afsnit bruger en permanent tabel med fortløbende numre. Hvis du ikke har et af disse, kan følgende script bruges til at oprette et:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Selve demoen involverer oprettelse af en partitioneret klynget kolonnelagerindekseret tabel og indsættelse af nok rækker (fra Numbers-tabellen ovenfor) til at overbevise optimeringsværktøjet om at bruge en partitionssortering forud for indsættelse:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Udførelsesplanen for indsættelsen viser sorteringen, der bruges til at sikre, at rækker ankommer til den klyngede kolonnelagerindsættelses-iterator i partitions-id-rækkefølge:

En opkaldsstak, der blev optaget, mens CQScanPartitionSortNew sortering var i gang er vist nedenfor:
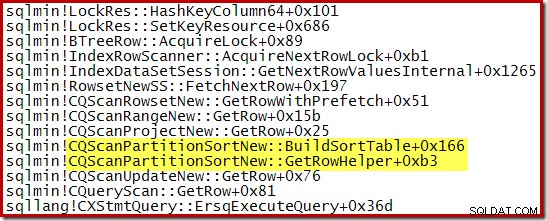
Der er noget andet interessant ved denne slags klasse. Sortering bruger normalt hele deres input i deres Open-metodekald. Efter sortering returnerer de kontrollen til deres overordnede operatør. Senere begynder sorteringen at producere sorterede outputrækker én ad gangen på den sædvanlige måde via GetRow-kald. CQScanPartitionSortNew er anderledes, som du kan se i opkaldsstakken ovenfor:Den bruger ikke sit input under sin Open-metode – den venter, indtil GetRow kaldes af sin forælder for første gang.
Ikke enhver sortering på partitions-id, der vises i en eksekveringsplan, der indsætter rækker i et partitioneret clustered columnstore-indeks, vil være et CQScanPartitionSortNew sortere. Hvis sorteringen vises umiddelbart til højre for kolonnelagerindeksindsættelsesoperatoren, er chancerne meget gode for, at det er en CQScanPartitionSortNew sortere.
Til sidst, CQScanPartitionSortNew er en af kun to sorteringsklasser, der sætter egenskaben Soft Sort synlig, når sorteringsoperatørens udførelsesplanegenskaber genereres med udokumenteret sporingsflag 8666 aktiveret:
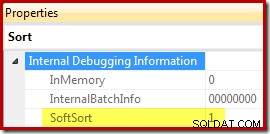
Betydningen af "blød sort" i denne sammenhæng er uklar. Det spores som en egenskab i forespørgselsoptimeringsstrukturen og ser ud til at være relateret til optimerede partitionerede dataindsættelser, men at bestemme præcis, hvad det betyder, kræver yderligere forskning. I mellemtiden kan denne egenskab bruges til at udlede, at en sortering er implementeret med CQScanPartitionSortNew uden at tilslutte en debugger. Betydningen af InMemory-egenskabsflaget vist ovenfor vil blive dækket i del 2. Det gør ikke angive, om en almindelig sortering blev udført i hukommelsen eller ej.
Sammendrag af første del
- CQScanSortNew er den generelle sorteringsklasse, der bruges, når ingen anden mulighed er anvendelig. Det ser ud til, at den bruger en række interne flettesorteringer i hukommelsen, der skifter til ekstern flettesortering ved hjælp af tempdb hvis tildelt hukommelsesarbejdsplads viser sig at være utilstrækkelig. Denne klasse kan bruges til generel sortering og distinkt sortering.
- CQScanTopSortNew redskaber Top N Sort. Hvor N <=100, udføres en intern fletningssortering i hukommelsen, og den løber aldrig ud til tempdb . Kun de nuværende top n elementer bevares i hukommelsen under sorteringen. For N> 100 CQScanTopSortNew svarer til en CQScanSortNew sortering, der automatisk stopper efter N rækker er blevet udskrevet. En N> 100 sortering kan spredes til tempdb hvis det er nødvendigt.
- Den Top N Sort, der ses i eksekveringsplaner, er en omskrivning efter forespørgselsoptimering. Hvis forespørgselsoptimeringsværktøjet producerer et outputtræ med en tilstødende Top og ikke-distinkt sortering, kan denne omskrivning kollapse de to fysiske operatorer til en enkelt Top N Sort operator.
- CQScanIndexSortNew bruges kun i indeksbygning af DDL-planer. Det er den eneste standard sorteringsklasse, der dynamisk kan erhverve mere hukommelse under udførelse. Indeksbygningssorteringer kan stadig spredes til disken under nogle omstændigheder, herunder når SQL Server beslutter, at en anmodet hukommelsesforøgelse ikke er kompatibel med den aktuelle arbejdsbyrde.
- CQScanPartitionSortNew er kun til stede i SQL Server 2014 og bruges kun til at optimere indsættelser til et partitioneret clustered columnstore-indeks. Det giver en "blød sort".
Den anden del af denne artikel vil se på CQScanInMemSortNew , og de to indbyggede OLTP-kompilerede lagrede proceduresorteringer i hukommelsen.