Forsinket holdbarhed er en sen, men interessant funktion i SQL Server 2014; den høje elevator-pitch af funktionen er ganske enkelt:
- "Byt holdbarhed for ydeevne."
Først lidt baggrund. Som standard bruger SQL Server en WAL (Write-ahead-log), hvilket betyder, at ændringer skrives til loggen, før de får lov til at blive committet. I systemer, hvor transaktionslogskrivning bliver flaskehalsen, og hvor der er en moderat tolerance for datatab , har du nu mulighed for midlertidigt at suspendere kravet om at vente på logskylning og bekræftelse. Dette tager tilfældigvis bogstaveligt talt D'et ud af ACID, i det mindste for en lille del af data (mere om dette senere).
Du har sådan set allerede gjort dette offer nu. I fuld gendannelsestilstand er der altid en vis risiko for datatab, det måles bare i tid frem for størrelse. Hvis du f.eks. sikkerhedskopierer transaktionsloggen hvert femte minut, kan du miste op til lige under 5 minutters data, hvis der skete noget katastrofalt. Jeg taler ikke om simpel failover her, men lad os sige, at serveren bogstaveligt talt brænder, eller nogen snubler over netledningen - databasen kan meget vel være uoprettelig, og du skal muligvis gå tilbage til tidspunktet for den sidste log backup . Og det forudsætter, at du endda tester dine sikkerhedskopier ved at gendanne dem et sted – i tilfælde af en kritisk fejl har du muligvis ikke det gendannelsespunkt, du tror, du har. Vi har selvfølgelig en tendens til ikke at tænke på dette scenarie, fordi vi aldrig forventer dårlige ting™ ske.
Sådan virker det
Forsinket holdbarhed gør det muligt for skrivetransaktioner at fortsætte med at køre, som om loggen var blevet tømt til disken; i virkeligheden er skrivningerne til disk blevet grupperet og udskudt for at blive håndteret i baggrunden. Transaktionen er optimistisk; det antager, at loggen skylles vil ske. Systemet bruger en 60KB del af logbuffer og forsøger at skylle loggen til disken, når denne 60KB blok er fuld (senest – det kan og vil ofte ske før det). Du kan indstille denne mulighed på databaseniveau, på individuel transaktionsniveau eller – i tilfælde af native kompilerede procedurer i In-Memory OLTP – på procedureniveau. Databaseindstillingen vinder i tilfælde af en konflikt; for eksempel, hvis databasen er sat til deaktiveret, vil forsøg på at udføre en transaktion ved hjælp af den forsinkede mulighed simpelthen blive ignoreret uden fejlmeddelelse. Nogle transaktioner er også altid fuldt holdbare, uanset databaseindstillinger eller commit-indstillinger; f.eks. systemtransaktioner, transaktioner på tværs af databaser og operationer, der involverer FileTable, Change Tracking, Change Data Capture og Replikering.
På databaseniveau kan du bruge:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Hvis du indstiller den til ALLOWED , betyder det, at enhver individuel transaktion kan bruge Forsinket holdbarhed; FORCED betyder, at alle transaktioner, der kan bruge Forsinket Holdbarhed, vil (undtagelserne ovenfor er stadig relevante i dette tilfælde). Du vil sandsynligvis bruge ALLOWED i stedet for FORCED – men sidstnævnte kan være nyttigt i tilfælde af en eksisterende applikation, hvor du vil bruge denne mulighed hele vejen igennem og også minimere mængden af kode, der skal røres. En vigtig ting at bemærke om ALLOWED er, at fuldt varige transaktioner kan blive nødt til at vente længere, da de vil tvinge fjernelse af eventuelle forsinkede varige transaktioner først.
På transaktionsniveau kan du sige:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Og i en in-Memory OLTP-native-kompileret procedure kan du tilføje følgende mulighed til BEGIN ATOMIC blokere:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Et almindeligt spørgsmål er omkring, hvad der sker med låsning og isolation semantik. Intet ændrer sig, virkelig. Låsning og blokering sker stadig, og transaktioner begås på samme måde og med de samme regler. Den eneste forskel er, at ved at tillade commit at finde sted uden at vente på, at loggen skylles til disken, frigives eventuelle relaterede låse så meget hurtigere.
Hvornår du skal bruge det
Ud over den fordel, du får ved at lade transaktionerne fortsætte uden at vente på, at logskrivningen sker, får du også færre logskrivninger af større størrelser. Dette kan fungere meget godt, hvis dit system har en høj andel af transaktioner, der faktisk er mindre end 60 KB, og især når log-disken er langsom (selvom jeg fandt lignende fordele på SSD og traditionel HDD). Det fungerer ikke så godt, hvis dine transaktioner for det meste er større end 60KB, hvis de typisk er langvarige, eller hvis du har høj gennemstrømning og høj samtidighed. Det, der kan ske her, er, at du kan fylde hele logbufferen, før skylningen afsluttes, hvilket blot betyder, at du overfører dine ventetider til en anden ressource og i sidste ende ikke forbedrer den opfattede ydeevne af applikationens brugere.
Med andre ord, hvis din transaktionslog ikke i øjeblikket er en flaskehals, skal du ikke slå denne funktion til. Hvordan kan du se, om din transaktionslog i øjeblikket er en flaskehals? Den første indikator ville være høj WRITELOG venter, især når den er koblet sammen med PAGEIOLATCH_** . Paul Randal (@PaulRandal) har en fantastisk serie i fire dele om identifikation af transaktionslogproblemer samt konfiguration for optimal ydeevne:
- Trimning af transaktionsloggen fedt
- Trimning af mere transaktionslogfedt
- Konfigurationsproblemer med transaktionslog
- Overvågning af transaktionslog
Se også dette blogindlæg fra Kimberly Tripp (@KimberlyLTripp), 8 Steps to Better Transaction Log Throughput og SQL CAT-teamets blogindlæg, Diagnosing Transaction Log Performance Issues and Limits of the Log Manager.
Denne undersøgelse kan føre dig til den konklusion, at forsinket holdbarhed er værd at undersøge; det kan det ikke. At teste din arbejdsbyrde vil være den mest pålidelige måde at vide med sikkerhed. Som mange andre tilføjelser i nyere versioner af SQL Server (*host* Hekaton ), er denne funktion IKKE designet til at forbedre hver enkelt arbejdsbyrde - og som nævnt ovenfor kan den faktisk gøre nogle arbejdsbyrder værre. Se dette blogindlæg af Simon Harvey for nogle andre spørgsmål, du bør stille dig selv om din arbejdsbyrde for at afgøre, om det er muligt at ofre noget holdbarhed for at opnå bedre ydeevne.
Potentiale for datatab
Jeg har tænkt mig at nævne dette flere gange og lægge vægt hver gang jeg gør det:Du skal være tolerant over for tab af data . Under en velfungerende disk er det maksimale, du kan forvente at miste i en katastrofe – eller endda en planlagt og yndefuld nedlukning – op til en hel blok (60KB). Men i det tilfælde, hvor dit I/O-undersystem ikke kan følge med, er det muligt, at du kan miste så meget som hele logbufferen (~7MB).
For at præcisere, fra dokumentationen (min fremhævelse):
For forsinket holdbarhed er der ingen forskel mellem en uventet nedlukning og en forventet nedlukning/genstart af SQL Server . Ligesom katastrofale begivenheder bør du planlægge datatab . I en planlagt nedlukning/genstart kan nogle transaktioner, der ikke er blevet skrevet til disken, først gemmes på disken, men du bør ikke planlægge det. Planlæg som om en nedlukning/genstart, uanset om den er planlagt eller uplanlagt, mister dataene på samme måde som en katastrofal hændelse.Så det er meget vigtigt, at du afvejer din risiko for tab af data med dit behov for at afhjælpe problemer med transaktionsloggens ydeevne. Hvis du driver en bank eller andet, der beskæftiger sig med penge, kan det være meget mere sikkert og mere passende for dig at flytte din log til en hurtigere disk end at kaste terningerne ved hjælp af denne funktion. Hvis du forsøger at forbedre responstiden i din Web Gamerz Chat Room-applikation, er risikoen måske mindre alvorlig.
Du kan kontrollere denne adfærd til en vis grad for at minimere din risiko for tab af data. Du kan tvinge alle forsinkede varige transaktioner til at blive tømt til disken på en af to måder:
- Forpligte enhver fuldt holdbar transaktion.
- Ring til
sys.sp_flush_logmanuelt.
Dette giver dig mulighed for at vende tilbage til at kontrollere datatab i form af tid, snarere end størrelse; du kan for eksempel planlægge skylningen hvert 5. sekund. Men du vil gerne finde dit søde sted her; skylning for ofte kan opveje fordelen med forsinket holdbarhed i første omgang. Under alle omstændigheder skal du stadig være tolerant over for tab af data , selvom det kun er
Du skulle tro, at CHECKPOINT kan hjælpe her, men denne operation garanterer faktisk ikke teknisk, at loggen bliver tømt til disken.
Interaktion med HA/DR
Du undrer dig måske over, hvordan Delayed Durablity fungerer med HA/DR-funktioner såsom logforsendelse, replikering og tilgængelighedsgrupper. Med de fleste af disse fungerer det uændret. Logforsendelse og replikering afspiller de logposter, der er blevet hærdet, så det samme potentiale for datatab eksisterer der. Med AG'er i asynkron tilstand, venter vi alligevel ikke på den sekundære bekræftelse, så den vil opføre sig på samme måde som i dag. Med synkron kan vi dog ikke forpligte den primære, før transaktionen er forpligtet og hærdet til fjernloggen. Selv i det scenarie kan vi have en vis fordel lokalt ved ikke at skulle vente på, at den lokale log skal skrives, vi skal stadig vente på fjernaktiviteten. Så i det scenarie er der mindre fordele, og potentielt ingen; undtagen måske i det sjældne scenarie, hvor den primære log-disk er virkelig langsom, og den sekundæres log-disk er virkelig hurtig. Jeg formoder, at de samme betingelser gælder for synkronisering/asynkron-spejling, men du vil ikke få nogen officiel forpligtelse fra mig om, hvordan en skinnende ny funktion fungerer med en forældet. :-)
Ydeevneobservationer
Dette ville ikke være meget af et indlæg her, hvis jeg ikke viste nogle faktiske præstationsobservationer. Jeg har oprettet 8 databaser for at teste virkningerne af to forskellige arbejdsbelastningsmønstre med følgende egenskaber:
- Gendannelsesmodel:enkel vs. fuld
- Logplacering:SSD vs. HDD
- Holdbarhed:forsinket vs. fuldt holdbar
Jeg er virkelig, virkelig, virkelig doven effektiv omkring den slags. Da jeg vil undgå at gentage de samme operationer i hver database, oprettede jeg følgende tabel midlertidigt i model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Derefter byggede jeg et sæt dynamiske SQL-kommandoer til at bygge disse 8 databaser, i stedet for at oprette databaserne individuelt og derefter tude med indstillingerne:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Du er velkommen til at køre denne kode selv (med EXEC). stadig kommenteret ud) for at se, at dette ville skabe 4 databaser med forsinket holdbarhed OFF (to i FULD gendannelse, to i SIMPLE, en af hver med log på langsom disk, og en af hver med log på SSD). Gentag det mønster for 4 databaser med Forsinket holdbarhed FORCED – jeg gjorde dette for at forenkle koden i testen i stedet for at afspejle, hvad jeg ville gøre i det virkelige liv (hvor jeg sandsynligvis vil behandle nogle transaktioner som kritiske, og nogle som, godt, mindre end kritisk).
Til fornuftskontrol kørte jeg følgende forespørgsel for at sikre, at databaserne havde den rigtige matrix af attributter:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Resultater:
| navn | recovery_model | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | FULD | TVUNGT | SSD |
| dd2 | ENKELT | TVUNGT | SSD |
| dd3 | FULD | TVUNGT | HDD |
| dd4 | ENKELT | TVUNGT | HDD |
| dd5 | FULD | DEAKTIVERET | SSD |
| dd6 | ENKELT | DEAKTIVERET | SSD |
| dd7 | FULD | DEAKTIVERET | HDD |
| dd8 | ENKELT | DEAKTIVERET | HDD |
Relevant konfiguration af de 8 testdatabaser
Jeg kørte også testen rent flere gange for at sikre, at en 1 GB datafil og 1 GB logfil ville være tilstrækkelig til at køre hele sættet af arbejdsbelastninger uden at introducere nogen autogrowth-hændelser i ligningen. Som en bedste praksis går jeg rutinemæssigt ud af min måde for at sikre, at kundernes systemer har nok allokeret plads (og korrekte indbyggede advarsler), så der aldrig opstår nogen væksthændelse på et uventet tidspunkt. I den virkelige verden ved jeg, at dette ikke altid sker, men det er ideelt.
Jeg konfigurerede systemet til at blive overvåget med SQL Sentry – dette ville give mig mulighed for nemt at vise de fleste af de præstationsmålinger, jeg ville fremhæve. Men jeg oprettede også en midlertidig tabel til at gemme batch-metrics inklusive varighed og meget specifikt output fra sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Dette ville give mig mulighed for at registrere start- og sluttidspunktet for hver enkelt batch og måle deltaer i DMV mellem starttidspunkt og sluttidspunkt (kun pålideligt i dette tilfælde, fordi jeg ved, at jeg er den eneste bruger på systemet).
Masser af små transaktioner
Den første test, jeg ville udføre, var en masse små transaktioner. For hver database ønskede jeg at ende op med 500.000 separate batches af et enkelt indlæg hver:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Husk, jeg prøver at være doven effektiv omkring den slags. Så for at generere koden til alle 8 databaser, kørte jeg denne:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Jeg kørte denne test og så på #Metrics tabel med følgende forespørgsel:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Dette gav følgende resultater (og jeg bekræftede gennem flere test, at resultaterne var konsistente):
| database | skriver | bytes | bytes/skriv | io_stall_ms | starttid | sluttidspunkt | varighed (sekunder) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418,56 | 2.740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8.246 | 262.254.592 | 31.803,85 | 3.996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32.487,68 | 4.231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052,87 | 35.593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051,71 | 35.435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1.052,20 | 50.857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | 133 |
Små transaktioner:Varighed og resultater fra sys.dm_io_virtual_file_stats
Absolut nogle interessante observationer her:
- Antallet af individuelle skriveoperationer var meget lille for databaserne med forsinket holdbarhed (~60X for traditionelle).
- Det samlede antal skrevne bytes blev halveret ved hjælp af Forsinket holdbarhed (jeg formoder, fordi alle skrivningerne i det traditionelle tilfælde indeholdt en masse spildt plads).
- Antallet af bytes pr. skrivning var meget højere for forsinket holdbarhed. Dette var ikke særlig overraskende, da hele formålet med funktionen er at samle skrivninger sammen i større partier.
- Den samlede varighed af I/O-stall var flygtig, men nogenlunde en størrelsesorden lavere for Forsinket holdbarhed. Båsene under fuldt holdbare transaktioner var meget mere følsomme over for typen af disk.
- Hvis noget ikke har overbevist dig indtil videre, er varighedskolonnen meget sigende. Fuldt holdbare partier, der tager to minutter eller mere, skæres næsten i halve.
Kolonnerne for start/sluttidspunkt gjorde det muligt for mig at fokusere på Performance Advisor-dashboardet i den præcise periode, hvor disse transaktioner fandt sted, hvor vi kan tegne en masse yderligere visuelle indikatorer:
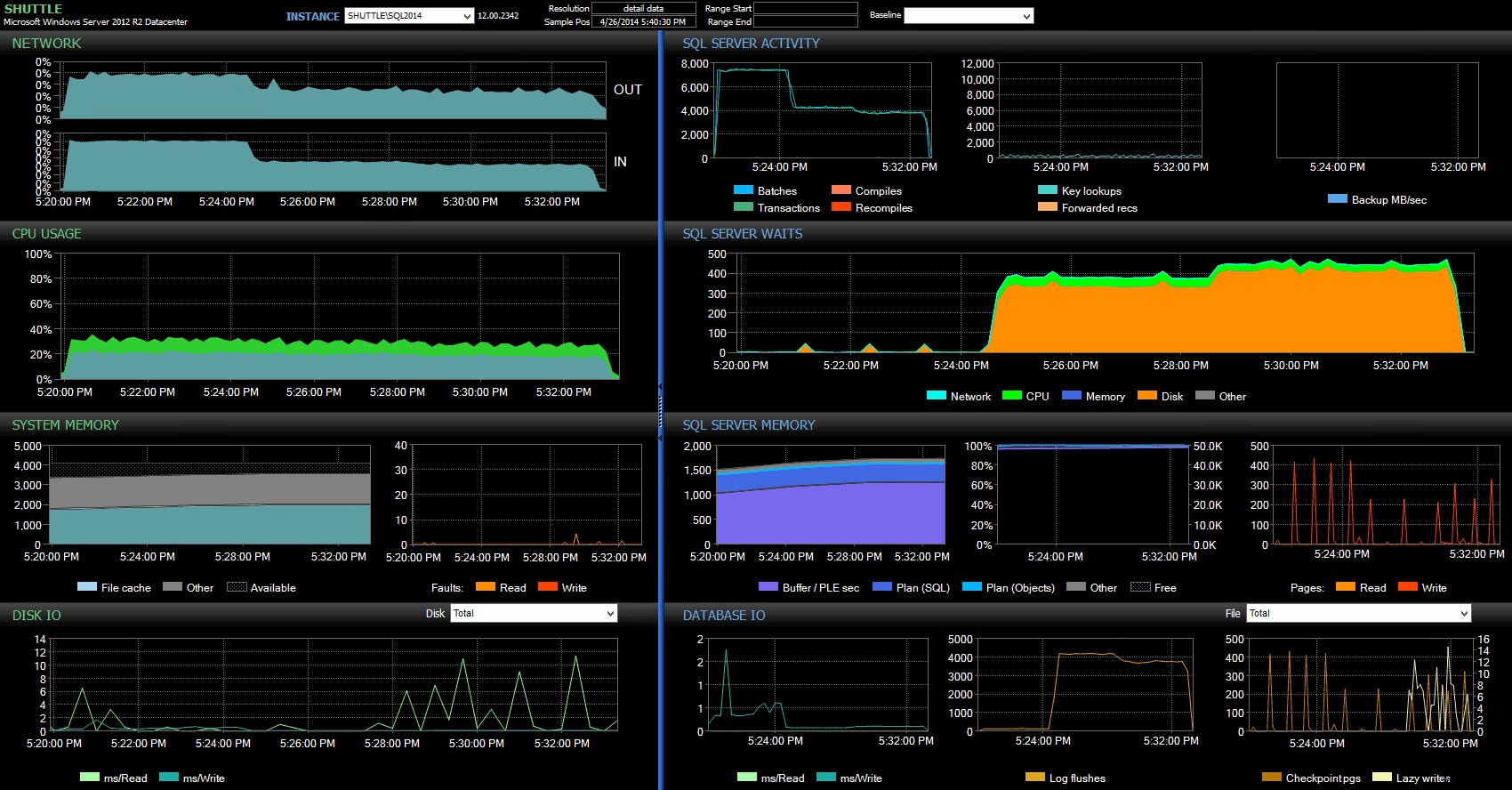
SQL Sentry-dashboard – klik for at forstørre
Yderligere observationer her:
- På flere grafer kan du tydeligt se præcis, hvornår den ikke-forsinket holdbarhed-del af batchen tog over (~17:24:32).
- Der er ingen observerbar indvirkning på CPU eller hukommelse, når du bruger Forsinket holdbarhed.
- Du kan se en enorm indvirkning på batches/transaktioner pr. sekund i den første graf under SQL Server Activity.
- SQL Server-venter går gennem taget, når de fuldt holdbare transaktioner startede. Disse bestod næsten udelukkende af
WRITELOGventer med et lille antalPAGEIOLOATCH_EXogPAGEIOLATCH_UPventer på god foranstaltning. - Det samlede antal log skylninger i løbet af de forsinket holdbarhed operationer var ret lille (lave 100s/sek), mens dette sprang til over 4.000/sek for den traditionelle adfærd (og lidt lavere for HDD varigheden af testen).
Færre, større transaktioner
Til den næste test ville jeg se, hvad der ville ske, hvis vi udførte færre operationer, men sørgede for, at hvert udsagn påvirkede en større mængde data. Jeg ønskede, at denne batch skulle køre mod hver database:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Så igen brugte jeg den dovne metode til at producere 8 kopier af dette script, en pr. database:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Jeg kørte denne batch og ændrede derefter forespørgslen mod #Metrics ovenfor for at se på den anden test i stedet for den første. Resultaterne:
| database | skriver | bytes | bytes/skriv | io_stall_ms | starttid | sluttidspunkt | varighed (sekunder) |
|---|---|---|---|---|---|---|---|
| dd1 | 20.970 | 1.271.911.936 | 60.653.88 | 12.577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20.997 | 1.272.145.408 | 60.587,00 | 14.698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20.973 | 1.272.982.016 | 60.696.22 | 12.085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20.958 | 1.272.064.512 | 60.695,89 | 11.795 | 143 | ||
| dd5 | 30.138 | 1.282.231.808 | 42.545,35 | 7.402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30.138 | 1.282.260.992 | 42.546.31 | 7.806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30.129 | 1.281.575.424 | 42.536,27 | 9.888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30.130 | 1.281.449.472 | 42.530,68 | 11.452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Større transaktioner:Varighed og resultater fra sys.dm_io_virtual_file_stats
Denne gang er virkningen af forsinket holdbarhed meget mindre mærkbar. Vi ser et lidt mindre antal skriveoperationer, med et lidt større antal bytes pr. skrivning, med det samlede antal bytes skrevet næsten identisk. I dette tilfælde ser vi faktisk, at I/O-båsene er højere for forsinket holdbarhed, og dette forklarer sandsynligvis det faktum, at varighederne også var næsten identiske.
Fra Performance Advisor-dashboardet har vi nogle ligheder med den tidligere test og også nogle markante forskelle:
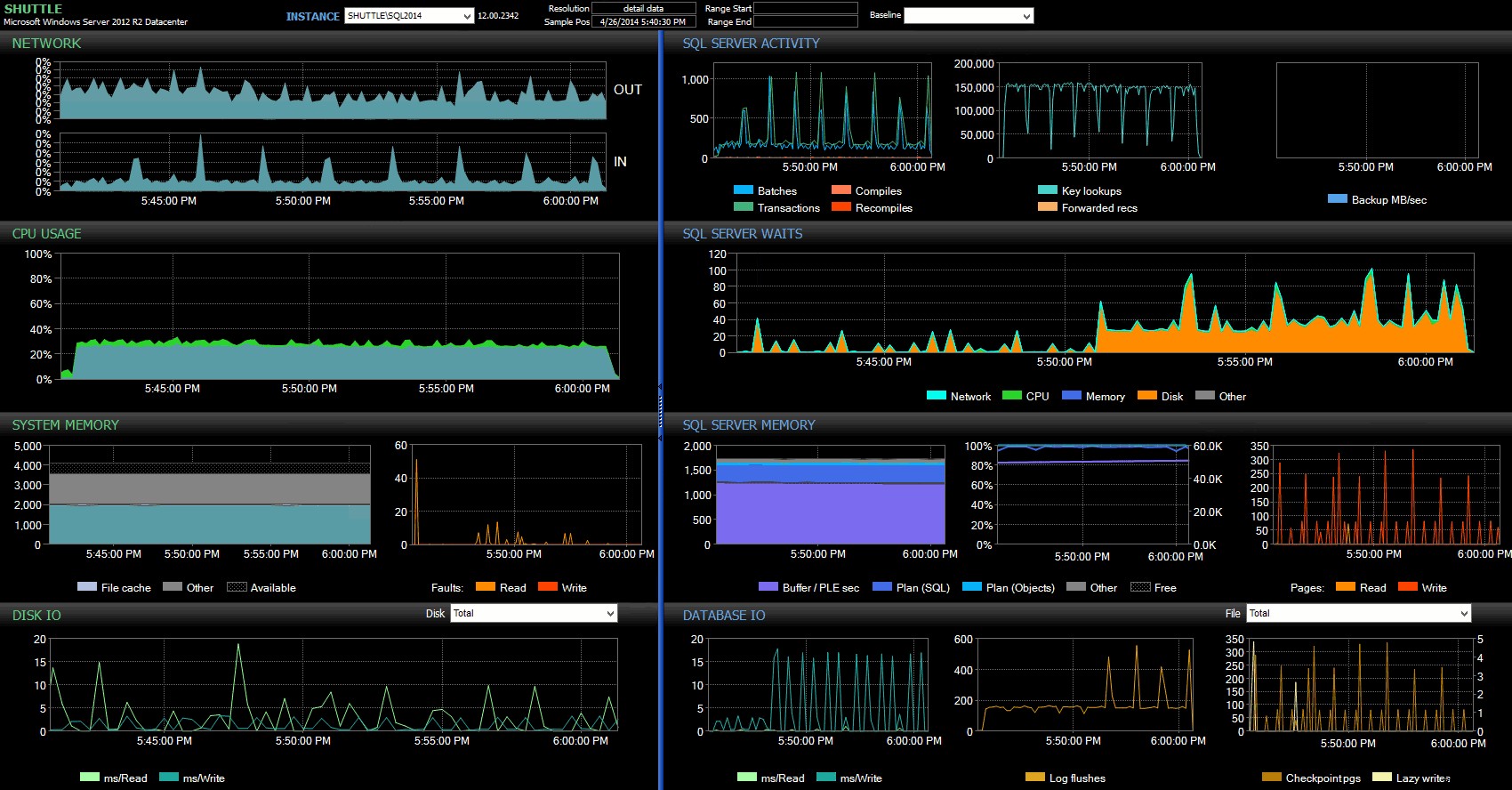
SQL Sentry-dashboard – klik for at forstørre
En af de store forskelle at påpege her er, at delta in wait-statistikken ikke er helt så udtalt som med den forrige test – der er stadig en meget højere frekvens af WRITELOG venter på de fuldt holdbare partier, men ikke i nærheden af niveauerne set med de mindre transaktioner. En anden ting, du kan få øje på med det samme, er, at den tidligere observerede indvirkning på batches og transaktioner pr. sekund ikke længere er til stede. Og endelig, mens der er flere log-flush med fuldt holdbare transaktioner end ved forsinkelse, er denne forskel langt mindre udtalt end med de mindre transaktioner.
Konklusion
Det skal være klart, at der er visse typer arbejdsbyrder, der kan have stor gavn af forsinket holdbarhed – naturligvis forudsat at du har en tolerance for tab af data . Denne funktion er ikke begrænset til In-Memory OLTP, er tilgængelig på alle udgaver af SQL Server 2014 og kan implementeres med få eller ingen kodeændringer. Det kan bestemt være en kraftfuld teknik, hvis din arbejdsbyrde kan understøtte det. Men igen, du bliver nødt til at teste din arbejdsbyrde for at være sikker på, at den vil drage fordel af denne funktion, og også kraftigt overveje, om dette øger din eksponering for risikoen for tab af data.
Som en sidebemærkning kan dette for SQL Server-mængden virke som en frisk ny idé, men i virkeligheden introducerede Oracle dette som "Asynchronous Commit" i 2006 (se COMMIT WRITE ... NOWAIT som dokumenteret her og blogget om i 2007). Og selve ideen har eksisteret i næsten 3 årtier; se Hal Berensons korte krønike om dens historie.
Næste gang
En idé, som jeg har slået rundt, er at forsøge at forbedre ydeevnen af tempdb ved at tvinge Forsinket Holdbarhed dertil. En speciel egenskab for tempdb det, der gør det til en så fristende kandidat, er, at det er forbigående af natur – alt i tempdb er designet, eksplicit, til at kunne kastes i kølvandet på en lang række systemhændelser. Jeg siger det nu uden at have nogen idé om, om der er en arbejdsbyrdeform, hvor dette vil fungere godt; men jeg planlægger at prøve det, og hvis jeg finder noget interessant, kan du være sikker på, at jeg vil skrive om det her.