Der er en regressionsfejl i SQL Server 2012 og SQL Server 2014, hvor du kan opleve datatab eller korruption . Dette burde være et relativt sjældent scenarie (Phil Brammer har en simpel repro i Connect #795134), men datatab er datatab, og jeg er ikke parat til at spille. Rettelsen er beskrevet i KB #2969896:RETNING:Datatab i klynget indeks opstår, når du kører online build-indeks i SQL Server 2012.
Ikke alle behøver at være bekymrede over dette problem. Hvis du ikke kører Enterprise (eller en tilsvarende) Edition, kan du ikke udføre parallelle eller online genopbygninger i første omgang (og der er sikkert nogle folk på Enterprise, der ikke genopbygger eller genopbygger ikke online). Hvis du har MAXDOP for hele instansen sat til 1, kan de ikke gå parallelt, medmindre du tilsidesætter det på sætningsniveauet. Men hvis du er på 2012 eller 2014 og kører en passende udgave, og dine online-genopbygninger kan gå parallelt, er du sårbar over for dette problem.
Som jeg nævnte ovenfor, kunne dette problem manifestere sig i SQL Server 2012 RTM, Service Pack 1 og endda Service Pack 2, som blev udgivet den 10. juni. Fejlen blev først rettet længe efter, at SP2-koden blev frosset, så SP2 gør det. ikke inkludere denne rettelse eller nogen af rettelserne fra SP1 CU #10 eller #11. Jeg bloggede om det her. RTM-filialen er officielt ude af support, så du vil ikke se en løsning der. Problemet kan også opstå i SQL Server 2014.
Der er nu kumulative opdateringer tilgængelige til SQL Server 2012 Service Pack 1 &2 samt SQL Server 2014. En hurtig oversigt over de muligheder, jeg anbefaler:
Hvis din filial / @@VERSION er...
| ...du burde... | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Gør ingenting; du har allerede rettelsen. | |||||
| |||||
| Gør ingenting; du har allerede rettelsen. | |||||
| SQL Server 2014 RTM |
| ||||
| Gør ingenting; du har allerede rettelsen. | |||||
| * Hvis du installerer SP1-hotfixet eller kumulativ opdatering #11 og derefter installerer SP2, vil du fortryde disse ændringer, bl.a. denne rettelse. | |||||
Løsninger til hotfixet/CU-averse
Da alle berørte grene (godt, undtagen 2012 RTM) har et on-demand hotfix og/eller en kumulativ opdatering, der løser problemet, er det nemme svar blot at installere den relevante opdatering. Du kan dog være i et scenarie, hvor din virksomhedspolitik eller testcyklusser forhindrer dig i at implementere disse opdateringer hurtigt eller måske nogensinde. Så hvilke andre muligheder har du?
- Du kan stoppe med at udføre genopbygninger, indtil der er en ny servicepakke tilgængelig for din filial (måske kan du bare holde dig til
REORGANIZEfor nu). Desværre, hvis du er i en "kun service pack"-virksomhed, er dine muligheder meget begrænsede:du kan kæmpe hårdere for at ændre denne politik, eller du kan vente på SQL Server 2012 Service Pack 3 (som kan tage lang tid, eller evt. kom simpelthen aldrig – se FAQ #21 her) eller SQL Server 2014 Service Pack 1 (som vi nok ikke ser før 2015 ruller rundt). - Du kan indstille instansdækkende
max degree of parallelismtil 1, men dette kan have en negativ effekt på resten af din arbejdsbyrde – tænk på ting som multi-threaded DBCC, parallelle forespørgsler mod eller mellem partitionerede tabeller og andre operationer, hvor du måske ønsker at reducere parallelitet, men ikke helt eliminere det. Denne indstilling vil heller ikke påvirke en online genopbygning med f.eks. en eksplicitMAXDOP = 8hårdkodet ind i kommandoen, da dette vil tilsidesættesp_configureindstilling.
- Du kan tilføje
WITH (MAXDOP = 1)mulighed manuelt til alle dine genopbygningskommandoer. (Bemærk:du behøver ikke at gøre dette for XML-indekser, da de i sagens natur kører single-threaded, men jeg ville bare anvende det på alle genopbygninger for konsistens og for at undgå unødvendig betinget logik.)
- Du kan indstille dine indeksvedligeholdelsesjob til at køre som et specifikt login og derefter bruge Resource Governor til at oprette en arbejdsbelastningsgruppe, der begrænser loginets
MAX_DOPtil 1, uanset hvad de laver. Jeg har et eksempel på dette i hvidbogen fra 2008, jeg skrev sammen med Boris Baryshnikov, Using the Resource Governor, i afsnittet med titlen "Limiting Parallelism for Intensive Background Jobs."
- Hvis du bruger Ola Hallengrens indeksvedligeholdelsesløsning, kan du tilføje
@MaxDopparameter til dine opkald tildbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Hvis du bruger SQL Sentry Fragmentation Manager, kan du diktere niveauet for
MAXDOPat bruge under Indstillinger – og du kan gøre dette på hele virksomheden, pr. instans, pr. database eller endda pr. individuelt indeks (i dette tilfælde vil du sandsynligvis indstille dette pr. instans, for alle instanser uden en tilgængelig rettelse):
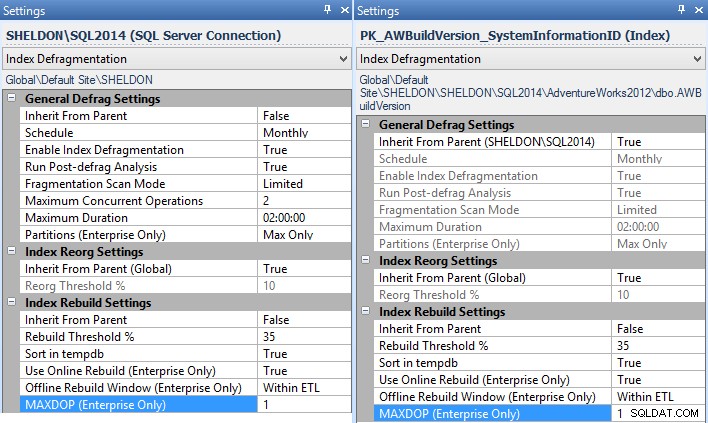
Fragmentation Manager-indstillinger for forekomsten (venstre) og et individuelt indeks (højre). - Hvis du bruger vedligeholdelsesplaner til dine indeksgenopbygninger, bliver du nødt til at ændre dem for at bruge Execute T-SQL Statement Tasks og skrive dit
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);kommandoer manuelt (så kan lige så godt skifte til en automatiseret løsning). Se, indeksgenopbygningsopgaven har ikke en eksponeret egenskab forMAXDOP, selvom det er blevet anmodet om flere gange (senest i 2012 af Alberto Morillo og så langt tilbage som i 2006 af Linchi Shea). Og se bare på alle disse andre nyttige egenskaber, de afslører, såsomAdvSortInTempdb,ObjectTypeSelection, ogTaskAllowesDatbaseSelection[sic!]:
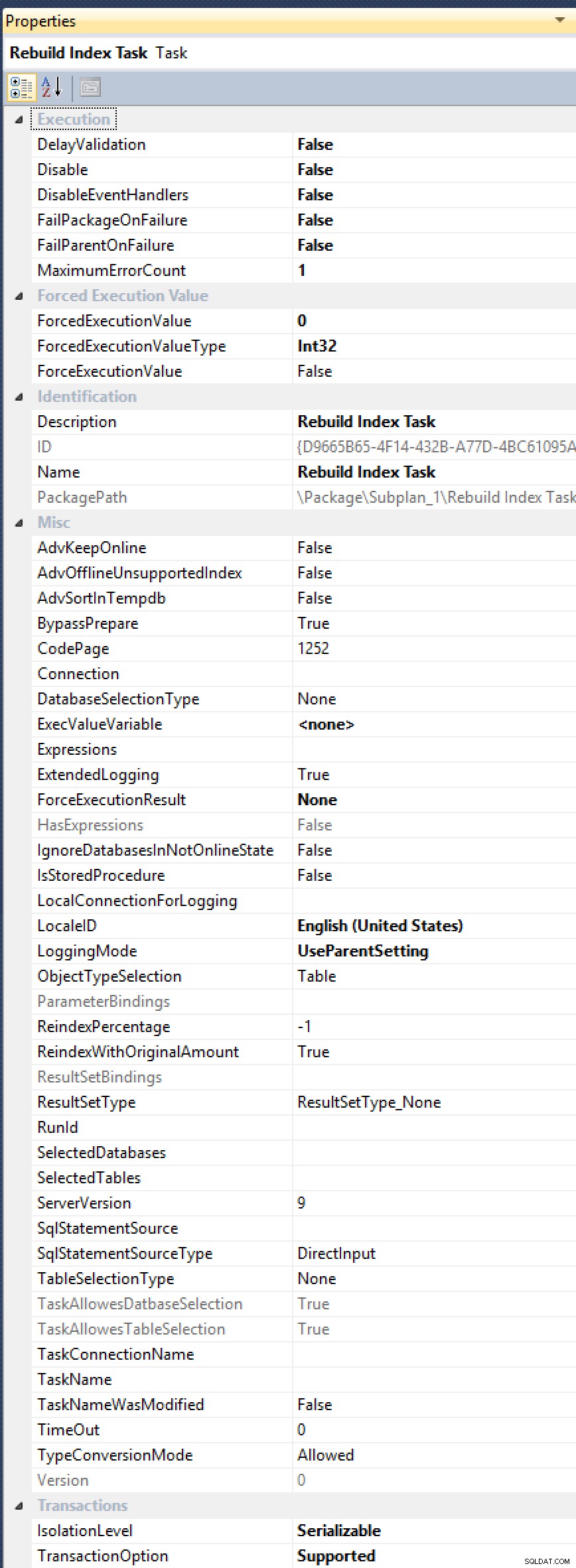
Alle disse muligheder, men stadig ingen kur mod MAXDOP.