I den første del af denne serie introducerede jeg grundlæggende terminologi omkring logning, så jeg anbefaler dig at læse det, før du fortsætter med dette indlæg. Alt andet, jeg vil dække i serien, kræver at kende noget til arkitekturen i transaktionsloggen, så det er det, jeg vil diskutere denne gang. Selvom du ikke har tænkt dig at følge serien, er nogle af de begreber, jeg vil forklare nedenfor, værd at kende til daglige opgaver, som DBA'er varetager i produktionen.
Strukturelt hierarki
Transaktionsloggen er internt organiseret ved hjælp af et tre-niveau hierarki som vist i figur 1 nedenfor.
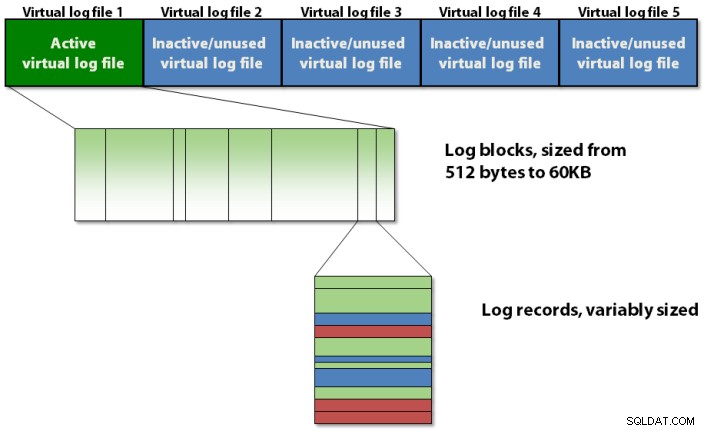 Figur 1:Det strukturelle hierarki på tre niveauer i transaktionsloggen em>
Figur 1:Det strukturelle hierarki på tre niveauer i transaktionsloggen em>
Transaktionsloggen indeholder virtuelle logfiler, som indeholder logblokke, som gemmer de faktiske logposter.
Virtuelle logfiler
Transaktionsloggen er delt op i sektioner kaldet virtuelle logfiler , almindeligvis bare kaldet VLF'er . Dette gøres for at gøre det nemmere at administrere operationer i transaktionsloggen for logmanageren i SQL Server. Du kan ikke angive, hvor mange VLF'er, der oprettes af SQL Server, når databasen først oprettes, eller logfilen automatisk vokser, men du kan påvirke den. Algoritmen for hvor mange VLF'er der oprettes er som følger:
- Logfilstørrelse mindre end 64 MB:Opret 4 VLF'er, hver omkring 16 MB store
- Logfilstørrelse fra 64MB til 1GB:Opret 8 VLF'er, hver ca. 1/8 af den samlede størrelse
- Logfilstørrelse større end 1 GB:Opret 16 VLF'er, hver ca. 1/16 af den samlede størrelse
Før SQL Server 2014, når logfilen vokser automatisk, bestemmes antallet af nye VLF'er, der tilføjes til slutningen af logfilen, af algoritmen ovenfor, baseret på størrelsen på automatisk vækst. Men ved brug af denne algoritme, hvis størrelsen på automatisk vækst er lille, og logfilen gennemgår mange automatiske vækster, kan det føre til et meget stort antal små VLF'er (kaldetVLF-fragmentering ), der kan være et stort ydeevneproblem for nogle operationer (se her).
På grund af dette problem blev algoritmen i SQL Server 2014 ændret for automatisk vækst af logfilen. Hvis den automatiske vækststørrelse er mindre end 1/8 af den samlede logfilstørrelse, oprettes kun én ny VLF, ellers bruges den gamle algoritme. Dette reducerer drastisk antallet af VLF'er for en logfil, der har gennemgået en stor mængde automatisk vækst. Jeg forklarede et eksempel på forskellen i dette blogindlæg.
Hver VLF har et sekvensnummer der unikt identificerer det og bruges på en række forskellige steder, hvilket jeg vil forklare nedenfor og i fremtidige indlæg. Man skulle tro, at sekvensnumrene ville starte ved 1 for en helt ny database, men det er ikke tilfældet.
På en SQL Server 2019-instans oprettede jeg en ny database uden at angive nogen filstørrelser, og tjekkede derefter VLF'erne ved hjælp af koden nedenfor:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Bemærk sys.dm_db_log_info DMV blev tilføjet i SQL Server 2016 SP2. Før det (og i dag, fordi det stadig eksisterer) kan du bruge den udokumenterede DBCC LOGINFO kommando, men du kan ikke give den en valgliste - bare gør DBCC LOGINFO(N'NewDB'); og VLF-sekvensnumrene er i FSeqNo kolonne i resultatsættet.
Under alle omstændigheder, resultaterne fra forespørgsler på sys.dm_db_log_info var:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Bemærk, at den første VLF starter ved offset 8.192 bytes i logfilen. Dette skyldes, at alle databasefiler, inklusive transaktionsloggen, har en filoverskriftsside, der fylder de første 8KB og gemmer forskellige metadata om filen.
Så hvorfor vælger SQL Server 37 og ikke 1 for det første VLF-sekvensnummer? Den finder det højeste VLF-sekvensnummer i modellen database og derefter, for enhver ny database, bruger transaktionsloggens første VLF dette tal plus 1 som sekvensnummer. Jeg ved ikke, hvorfor denne algoritme blev valgt tilbage i tidens tåger, men sådan har det været siden i det mindste SQL Server 7.0.
For at bevise det kørte jeg denne kode:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Og resultaterne var:
Max_VLF_SeqNo -------------------- 36
Så der har du det.
Der er mere at diskutere om VLF'er og hvordan de bruges, men indtil videre er det nok at vide, at hver VLF har et sekvensnummer, som stiger med én for hver VLF.
Logblokke
Hver VLF indeholder en lille metadata-header, og resten af rummet er fyldt med logblokke. Hver logblok starter med 512 bytes og vil vokse i intervaller på 512 byte til en maksimal størrelse på 60 KB, hvorefter den skal skrives til disken. En logblok kan blive skrevet til disken, før den når sin maksimale størrelse, hvis et af følgende sker:
- En transaktion begår, og forsinket holdbarhed bliver ikke brugt til denne transaktion, så logblokken skal skrives til disken for at gøre transaktionen holdbar
- Forsinket holdbarhed er i brug, og baggrunden "skyll den aktuelle logblok til disk" 1ms timeropgave udløses
- En datafilside bliver skrevet til disken af et kontrolpunkt eller den dovne skriver, og der er en eller flere logposter i den aktuelle logblok, der påvirker den side, der er ved at blive skrevet (husk at fremskrivningslogning skal være garanteret)
Du kan betragte en logblok som noget i retning af en side med variabel størrelse, der gemmer logposter i den rækkefølge, de oprettes af transaktioner, der ændrer databasen. Der er ikke en logblok for hver transaktion; logposterne for flere samtidige transaktioner kan blandes i en logblok. Du tror måske, at dette ville give problemer for operationer, der skal finde alle logposter for en enkelt transaktion, men det gør det ikke, som jeg vil forklare, når jeg dækker, hvordan tilbagerulninger af transaktioner fungerer i et senere indlæg.
Ydermere, når en logblok skrives til disken, er det fuldt ud muligt, at den indeholder logposter fra ikke-forpligtede transaktioner. Dette er heller ikke et problem på grund af den måde, gendannelse af nedbrud fungerer på - hvilket er et par gode indlæg i seriens fremtid.
Logsekvensnumre
Logblokke har et ID i en VLF, der starter ved 1 og stiger med 1 for hver ny logblok i VLF. Logposter har også et ID i en logblok, der starter ved 1 og stiger med 1 for hver ny logpost i logblokken. Så alle tre elementer i transaktionsloggens strukturelle hierarki har et ID, og de trækkes sammen til en trepartsidentifikation kaldet et logsekvensnummer , mere almindeligt blot omtalt som en LSN .
Et LSN er defineret som
Grundarbejde udført!
Selvom VLF'er er vigtige at kende til, er LSN efter min mening det vigtigste koncept at forstå omkring SQL Servers implementering af logning, da LSN'er er hjørnestenen, som transaktionsrulning og crash-gendannelse er bygget på, og LSN'er vil dukke op igen og igen som Jeg går videre gennem serien. I det næste indlæg vil jeg dække logafkortning og transaktionsloggens cirkulære karakter, som alt har at gøre med VLF'er, og hvordan de bliver genbrugt.