Tabelindekseringsstrategi er en af de vigtigste præstationsjusterings- og optimeringsnøgler. I SQL Server oprettes indekserne (både klyngede og ikke-klyngede indekser) ved hjælp af en B-træstruktur, hvor hver side fungerer som en dobbelt linket listeknude, der har en information om den forrige og den næste side. Denne B-træstruktur, kaldet Forward Scan, gør det nemmere at læse rækkerne fra indekset ved at scanne eller søge dets sider fra begyndelsen til slutningen. Selvom den fremadrettede scanning er standard- og meget kendte indeksscanningsmetode, giver SQL Server os mulighed for at scanne indeksrækkerne i B-træstrukturen fra slutningen til begyndelsen. Denne evne kaldes Backward Scan. I denne artikel vil vi se, hvordan dette sker, og hvad der er fordele og ulemper ved baglæns scanningsmetoden.
SQL Server giver os muligheden for at læse data fra tabelindekset ved at scanne indeksets B-træstrukturknudepunkter fra begyndelsen til slutningen ved hjælp af Forward Scan-metoden, eller læse B-træstrukturnoderne fra slutningen til begyndelsen ved hjælp af Baglæns scanningsmetode. Som navnet indikerer, udføres baglæns scanningen, mens den læser modsat rækkefølgen af kolonnen inkluderet i indekset, som udføres med DESC-indstillingen i ORDER BY T-SQL-sorteringssætningen, der angiver retningen for scanningsoperationen.
I specifikke situationer finder SQL Server Engine ud af, at læsning af indeksdata fra slutningen til begyndelsen med Backward scan-metoden er hurtigere end at læse dem i sin normale rækkefølge med Forward scanningsmetoden, hvilket kan kræve en dyr sorteringsproces af SQL'en Motor. Sådanne tilfælde omfatter brugen af MAX()-aggregatfunktionen og situationer, hvor sortering af forespørgselsresultatet er modsat indeksrækkefølgen. Den største ulempe ved baglæns scanningsmetoden er, at SQL Server Query Optimizer altid vil vælge at udføre den ved hjælp af seriel planudførelse uden at være i stand til at drage fordel af de parallelle eksekveringsplaner.
Antag, at vi har følgende tabel, der vil indeholde oplysninger om virksomhedens ansatte. Tabellen kan oprettes ved hjælp af CREATE TABLE T-SQL-sætningen nedenfor:
OPRET TABEL [dbo].[Virksomhedsmedarbejdere]( [ID] [INT] IDENTITET (1,1) , [EmpID] [int] IKKE NULL, [Emp_First_Name] [nvarchar](50) NULL, [Emp_Last_Name] [ nvarchar](50) NULL, [EmpDepID] [int] NOT NULL, [Emp_Status] [int] NOT NULL, [EMP_PhoneNumber] [nvarchar](50) NULL, [Emp_Adress] [nvarchar](max) NULL, [Emp_EmploymentDate] [DATETIME] NULL,PRIMÆR NØGLE KLYNGET ( [ID] ASC)ON [PRIMARY]))
Efter at have oprettet tabellen, udfylder vi den med 10.000 dummy-poster ved at bruge INSERT-sætningen nedenfor:
INSERT INTO [dbo].[CompanyEmployees] ([EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_Empe_Em AAA','BBB',4,1,9624488779,'AMM','2006-10-15')GO 10000
Hvis vi udfører nedenstående SELECT-sætning for at hente data fra den tidligere oprettede tabel, vil rækkerne blive sorteret i henhold til ID-kolonneværdierne i stigende rækkefølge, det er den samme som den klyngede indeksrækkefølge:
VÆLG [ID],[Emp_ID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRA [SQLShackyDemoE] ] BESTIL AF [ID] ASC
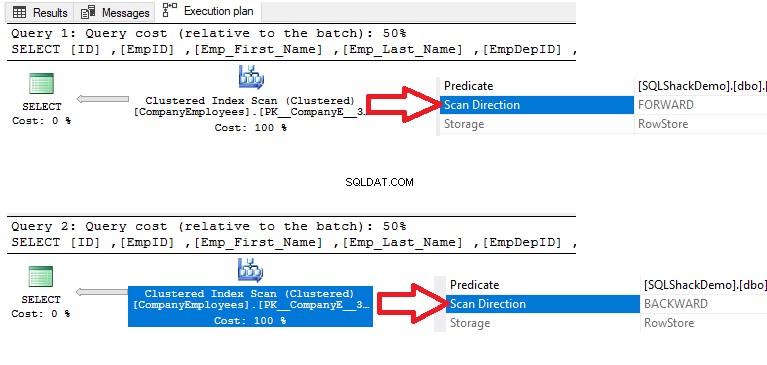
Når du derefter tjekker udførelsesplanen for den forespørgsel, vil der blive udført en scanning på det klyngede indeks for at få de sorterede data fra indekset som vist i udførelsesplanen nedenfor:
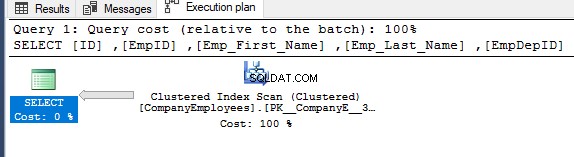
For at få retningen for den scanning, der udføres på det klyngede indeks, skal du højreklikke på indeksscanningsnoden for at gennemse knudeegenskaberne. Fra egenskaberne for Clustered Index Scan node vil egenskaben Scan Direction vise retningen af scanningen, der udføres på indekset i den forespørgsel, som er Forward Scan som vist på snapshotet nedenfor:

Indeksscanningsretningen kan også hentes fra XML-udførelsesplanen fra egenskaben ScanDirection under IndexScan-noden, som vist nedenfor:
Antag, at vi skal hente den maksimale ID-værdi fra tabellen CompanyEmployees, der er oprettet tidligere, ved hjælp af T-SQL-forespørgslen nedenfor:
VÆLG MAX([ID]) FRA [dbo].[CompanyEmployees]
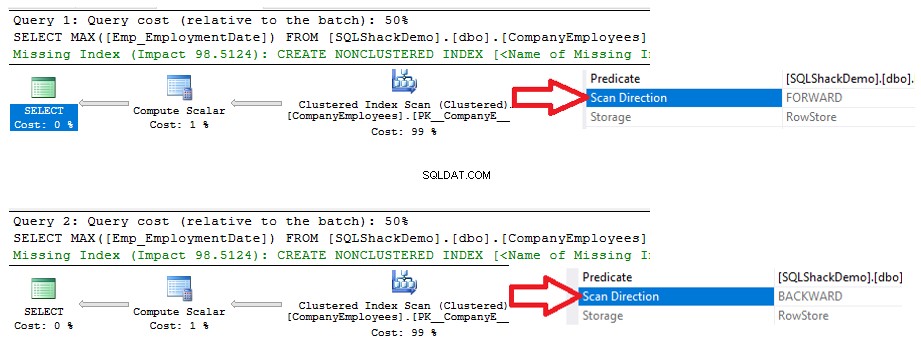
Gennemgå derefter den eksekveringsplan, der genereres ved at udføre denne forespørgsel. Du vil se, at en scanning vil blive udført på det klyngede indeks som vist i udførelsesplanen nedenfor:
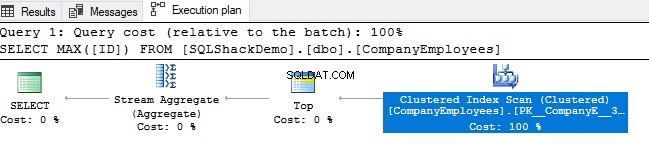
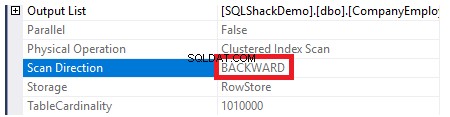
For at kontrollere retningen af indeksscanningen vil vi gennemse egenskaberne for Clustered Index Scan-noden. Resultatet vil vise os, at SQL Server Engine foretrækker at scanne det klyngede indeks fra slutningen til begyndelsen, hvilket vil være hurtigere i dette tilfælde, for at få den maksimale værdi af ID-kolonnen, på grund af det faktum, at indekset er allerede sorteret efter ID-kolonnen, som vist nedenfor:
Desuden, hvis vi forsøger at hente de tidligere oprettede tabeldata ved hjælp af følgende SELECT-sætning, vil posterne blive sorteret i henhold til ID-kolonnens værdier, men denne gang, modsat den klyngede indeksrækkefølge, ved at angive DESC-sorteringsindstillingen i ORDER BY-klausul vist nedenfor:
VÆLG [ID],[Emp_ID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRA [SQLShackyDemoE] ] BESTIL AF [ID] DESC
Hvis du kontrollerer den eksekveringsplan, der blev genereret efter udførelse af den forrige SELECT-forespørgsel, vil du se, at en scanning vil blive udført på det klyngede indeks for at få de anmodede poster i tabellen, som vist nedenfor:
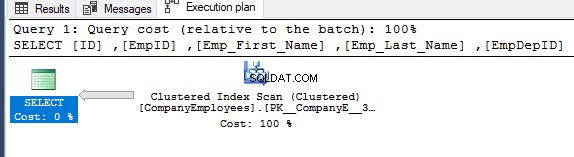
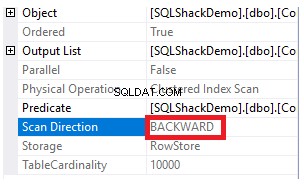
Egenskaberne for Clustered Index Scan node vil vise, at retningen af scanningen, som SQL Server Engine foretrækker at tage, er Backward Scan-retningen, som er hurtigere i dette tilfælde, på grund af at sortere dataene modsat den reelle sortering af det klyngede indeks, under hensyntagen til, at indekset allerede er sorteret i stigende rækkefølge i henhold til ID-kolonnen, som vist nedenfor:
Sammenligning af ydeevne
Antag, at vi har nedenstående SELECT-udsagn, der henter information om alle medarbejdere, der er blevet ansat fra 2010, to gange; første gang vil det returnerede resultatsæt blive sorteret i stigende rækkefølge i henhold til ID-kolonneværdierne, og anden gang vil det returnerede resultatsæt blive sorteret i faldende rækkefølge i henhold til ID-kolonneværdierne ved hjælp af T-SQL-sætningerne nedenfor:
VÆLG [ID],[Emp_ID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRA [SQLShackyDemoE] ] HVOR Emp_EmploymentDate>='2010-01-01' BESTIL AF [ID] ASC OPTION (MAXDOP 1) GÅ VÆLG [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ] ,[E, EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRA [SQLShackDemo].[dbo].[CompanyEmployees] WHERE Emp_EmploymentDate>='2010-01-01' BESTIL EFTER [ID] DESC VALGMULIGHED 1) (MAX.Ved at kontrollere udførelsesplanerne, der genereres ved at udføre de to SELECT-forespørgsler, vil resultatet vise, at en scanning vil blive udført på det klyngede indeks i de to forespørgsler for at hente dataene, men retningen af scanningen i den første forespørgsel vil være Fremad Scan på grund af ASC-datasortering og Baglæns Scan i den anden forespørgsel på grund af brug af DESC-datasortering for at erstatte behovet for at omarrangere dataene igen, som vist nedenfor:
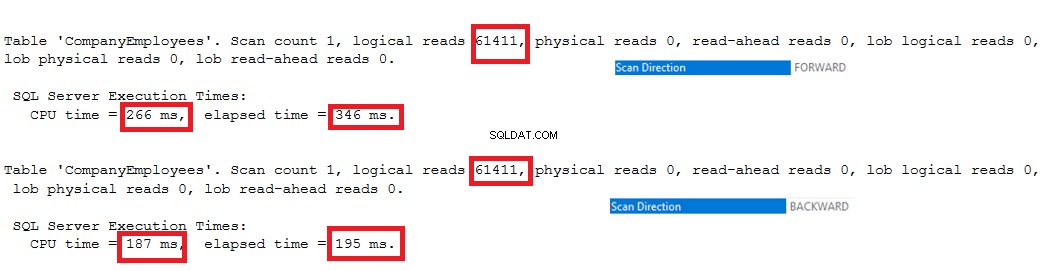
Hvis vi også tjekker IO- og TIME-udførelsesstatistikkerne for de to forespørgsler, vil vi se, at begge forespørgsler udfører de samme IO-operationer og bruger næsten værdier for eksekveringen og CPU-tiden.
Disse værdier viser os, hvor smart SQL Server Engine er, når den skal vælge den bedst egnede og hurtigste indeksscanningsretning til at hente data for brugeren, som er Forward Scan i det første tilfælde og Backward Scan i det andet tilfælde, som det fremgår af statistikken nedenfor. :
Lad os besøge det forrige MAX-eksempel igen. Antag, at vi skal hente det maksimale ID for de medarbejdere, der er blevet ansat i 2010 og senere. Til dette vil vi bruge følgende SELECT-sætninger, der vil sortere de læste data i henhold til ID-kolonnens værdi med ASC-sortering i den første forespørgsel og med DESC-sortering i den anden forespørgsel:
VÆLG MAX([Emp_EmploymentDate]) FRA [SQLShackDemo].[dbo].[CompanyEmployees] HVOR [Emp_EmploymentDate]>='2017-01-01' GRUPPER EFTER ID ORDRE EFTER [ID] ASC OPTION (MAXDOP 1) VÆLG MAX([Emp_EmploymentDate]) FRA [SQLShackDemo].[dbo].[CompanyEmployees] HVOR [Emp_EmploymentDate]>='2017-01-01' GRUPPER EFTER ID ORDRE EFTER [ID] DESC OPTION (MAXDOP 1) .>Du vil se fra de eksekveringsplaner, der er genereret fra udførelse af de to SELECT-sætninger, at begge forespørgsler vil udføre en scanningsoperation på det klyngede indeks for at hente den maksimale ID-værdi, men i forskellige scanningsretninger; Fremad Scan i den første forespørgsel og Baglæns Scan i den anden forespørgsel på grund af ASC- og DESC-sorteringsmulighederne, som vist nedenfor:
IO-statistikken genereret af de to forespørgsler viser ingen forskel mellem de to scanningsretninger. Men TIME-statistikken viser en stor forskel mellem at beregne rækkernes maksimale ID, når disse rækker scannes fra begyndelsen til slutningen ved hjælp af Forward Scan-metoden, og at scanne den fra slutningen til begyndelsen ved hjælp af Backward Scan-metoden. Det fremgår tydeligt af nedenstående resultat, at baglæns scanningsmetoden er den optimale scanningsmetode til at få den maksimale ID-værdi:
Ydeevneoptimering
Som jeg nævnte i begyndelsen af denne artikel, er forespørgselsindeksering den vigtigste nøgle i ydelsesjustering og optimeringsprocessen. I den foregående forespørgsel, hvis vi arrangerer at tilføje et ikke-klynget indeks i kolonnen EmploymentDate i tabellen CompanyEmployees ved hjælp af CREATE INDEX T-SQL-sætningen nedenfor:
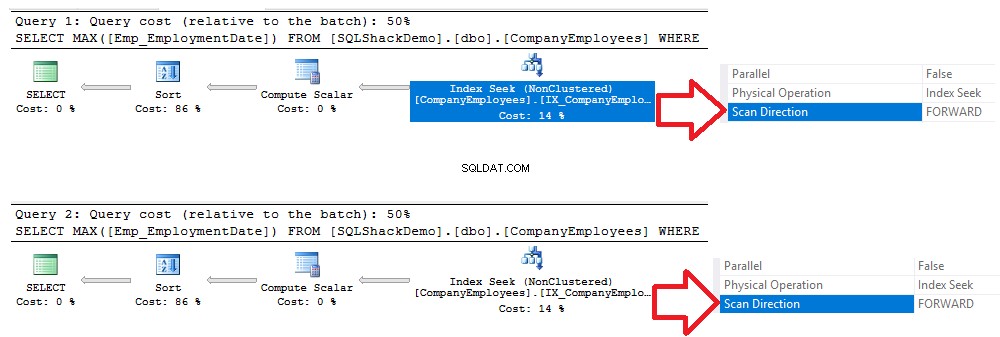
OPRET IKKE-KLUSTERET INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate)Derefter vil vi udføre de samme tidligere forespørgsler som vist nedenfor:SELECT MAX([Emp_EmploymentDate]) FROM] ='2017-01-01' GRUPPER EFTER ID ORDRE EFTER [ID] ASC OPTION (MAXDOP 1) GÅ VÆLG MAX([Emp_EmploymentDate]) FRA [SQLShackDemo].[dbo].[CompanyEmployees] HVOR [Emp_EmploymentDate]> -01-01' GRUPPER EFTER ID BESTILLING AF [ID] DESC MULIGHED (MAXDOP 1) GÅNår du tjekker de eksekveringsplaner, der er genereret efter udførelse af de to forespørgsler, vil du se, at der vil blive udført en søgning på det nyoprettede ikke-klyngede indeks, og begge forespørgsler vil scanne indekset fra begyndelsen til slutningen ved hjælp af Forward Scan-metoden, uden at behovet for at udføre en baglæns scanning for at fremskynde datahentningen, selvom vi brugte DESC-sorteringsindstillingen i den anden forespørgsel. Dette skete på grund af at søge indekset direkte uden behov for at udføre en fuld indeksscanning, som vist i sammenligningen af eksekveringsplaner nedenfor:
Det samme resultat kan udledes af IO- og TIME-statistikkerne genereret fra de to foregående forespørgsler, hvor de to forespørgsler vil forbruge den samme mængde af eksekveringstid, CPU- og IO-operationer, med en meget lille forskel, som vist i statistik-øjebliksbilledet nedenfor :
Nyttigt værktøj:
dbForge Index Manager – praktisk SSMS-tilføjelse til at analysere status for SQL-indekser og løse problemer med indeksfragmentering.