På tværs af alle større RDBMS-produkter, Primærnøgle i SQL-begrænsninger har en afgørende rolle. De identificerer optegnelserne i en tabel unikt. Derfor bør vi vælge Primary Keys-server omhyggeligt under tabeldesignet for at forbedre ydeevnen.
I denne artikel lærer vi, hvad en primærnøglebegrænsning er. Vi vil også se, hvordan du opretter, ændrer eller sletter begrænsninger for primære nøgler.
SQL-serverbegrænsninger
I SQL Server, Begrænsninger er regler, der regulerer indtastning af data i de nødvendige kolonner. Begrænsninger håndhæver nøjagtigheden af data, og hvordan disse data matcher forretningskrav. De gør også dataene pålidelige for slutbrugerne. Det er derfor, det er afgørende at identificere korrekte begrænsninger i designfasen af database- eller tabelskemaet.
SQL Server understøtter følgende Begrænsningstyper at håndhæve dataintegritet:
Primære nøglebegrænsninger oprettes på en enkelt kolonne eller kombination af kolonner for at håndhæve registreringernes unikke karakter og identificere posterne hurtigere. De involverede kolonner bør ikke indeholde NULL-værdier. Derfor bør egenskaben NOT NULL defineres på kolonnerne.
fremmednøglebegrænsninger oprettes på en enkelt kolonne eller kombination af kolonner for at skabe en relation mellem to tabeller og håndhæve dataene i en tabel til en anden. Ideelt set refererer tabelkolonner, hvor vi skal håndhæve dataene med Foreign Key-begrænsninger, til Kildetabellen med en Primary Key i SQL eller Unique Key-begrænsning. Med andre ord er det kun de poster, der er tilgængelige i kildetabellens primære eller unikke nøgle-begrænsninger, der kan indsættes eller opdateres til destinationstabellen.
Unikke nøglebegrænsninger oprettes på en enkelt kolonne eller kombination af kolonner for at håndhæve unikhed på tværs af kolonnedataene. De ligner Primary Key-begrænsningerne med en enkelt ændring. Forskellen mellem Primary Key og Unique Key Constraints er, at sidstnævnte kan oprettes på Nullable kolonner og tillad én NULL-værdipost i dens kolonne.
Tjek begrænsninger oprettes på en enkelt kolonne eller kombination af kolonner ved at begrænse de accepterede dataværdier for de involverede kolonner via et logisk udtryk. Der er forskel på Foreign Key og Check Constraints. Den fremmede nøgle håndhæver dataintegriteten ved at kontrollere data fra en anden tabels primære eller unikke nøgle. Dog gør Check Constraint dette ved at bruge et logisk udtryk.
Lad os nu gennemgå de primære nøglebegrænsninger.
Primær nøglebegrænsning
Primary Key Constraint gennemtvinger unikhed på en enkelt kolonne eller kombination af kolonner uden nogen NULL-værdier inde i de involverede kolonner.
For at gennemtvinge unikhed opretter SQL Server et unikt klynget indeks på de kolonner, hvor Primære nøgler blev oprettet. Hvis der er eksisterende klyngede indekser, opretter SQL Server et unikt ikke-klynget indeks på tabellen for den primære nøgle.
Lad os se, hvordan vi opretter, ændrer, sletter, deaktiverer eller aktiverer primære nøgler på en tabel ved hjælp af T-SQL-scripts.
Opret en primær nøgle
Vi kan oprette primære nøgler på en tabel enten under oprettelsen af tabellen eller derefter. Syntaksen varierer lidt for disse scenarier.
Oprettelse af den primære nøgle under tabeloprettelse
Syntaksen er nedenfor:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Lad os oprette en tabel med navnet Medarbejdere i HumanResources skema til testformål med nedenstående script:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
Vi har med succes skabt HumanResources.Employees tabel på AdventureWorks database:
Vi kan se, at det klyngede indeks blev oprettet på tabellen, der matcher navnet på den primære nøgle som fremhævet ovenfor.
Lad os droppe tabellen ved at bruge nedenstående script og prøve igen med den nye syntaks.
DROP TABLE HumanResources.EmployeesSådan oprettes den primære nøgle i SQL på en tabel med det brugerdefinerede primærnøglenavn PK_Employees , brug nedenstående syntaks:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Vi har oprettet HumanResources.Employees tabel med Primary Key-navnet PK_Employees :
Oprettelse af den primære nøgle efter tabeloprettelse
Nogle gange glemmer udviklere eller DBA'er de primære nøgler og opretter tabeller uden dem. Men det er muligt at oprette en primær nøgle på eksisterende tabeller.
Lad os droppe HumanResources.Employees tabel og genskab den ved hjælp af nedenstående script:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Når du udfører dette script med succes, kan vi se HumanResources.Employees tabel oprettet uden nogen primære nøgler eller indekser:

For at oprette en primær nøgle ved navn PK_Employees på denne tabel, brug nedenstående syntaks:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Udførelse af dette script opretter den primære nøgle på vores bord:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Oprettelse af primær nøgle på flere kolonner
I vores eksempler oprettede vi primære nøgler på enkelte kolonner. Hvis vi vil oprette primære nøgler på flere kolonner, har vi brug for en anden syntaks.
For at tilføje flere kolonner som en del af den primære nøgle, skal vi blot tilføje kommaseparerede værdier af de kolonnenavne, der skal være en del af den primære nøgle.
Primær nøgle under oprettelsen af bordet
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Primær nøgle efter tabeloprettelse
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Slip den primære nøgle
For at droppe den primære nøgle bruger vi nedenstående syntaks. Det er lige meget, om den primære nøgle var på enkelte eller flere kolonner.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
For at droppe den primære nøglebegrænsning på HumanResources.Employees tabel, skal du bruge nedenstående script:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Slipning af den primære nøgle fjerner både de primære nøgler og de klyngede eller ikke-klyngede indekser, der er oprettet sammen med oprettelsen af den primære nøgle:
Rediger den primære nøgle
I SQL Server er der ingen direkte kommandoer til at ændre primære nøgler. Vi er nødt til at droppe en eksisterende primærnøgle og genskabe den med nødvendige ændringer. Derfor er trinene til at ændre den primære nøgle:
- Slip en eksisterende primær nøgle.
- Opret nye primære nøgler med nødvendige ændringer.
Deaktiver/aktiver primær nøgle
Mens du udfører massebelastning på en tabel med mange poster, skal du deaktivere den primære nøgle og aktivere den igen for bedre ydeevne. Trinene er nedenfor:
Deaktiver den eksisterende primære nøgle med nedenstående syntaks:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;Sådan deaktiveres den primære nøgle på HumanResources.Employees tabel, er scriptet:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Aktiver eksisterende primære nøgler, der er i deaktiveret tilstand. Vi skal GENOPBYGGE indekset ved at bruge nedenstående syntaks:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;For at aktivere den primære nøgle på HumanResources.Employees tabel, skal du bruge følgende script:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Myterne om den primære nøgle
Mange mennesker bliver forvirrede over nedenstående myter relateret til primære nøgler i SQL Server.
- Tabel med primær nøgle er ikke en heap-tabel
- Primære nøgler har det grupperede indeks og data sorteret i fysisk rækkefølge
Lad os afklare dem.
Tabel med primærnøgle er ikke en heap-tabel
Inden vi dykker dybere, lad os revidere definitionen af den primære nøgle og heaptabellen.
Den primære nøgle opretter et klynget indeks på en tabel, hvis der ikke er andre klyngede indekser tilgængelige der. En tabel uden et Clustered Index vil være en Heap-tabel.
Baseret på disse definitioner kan vi forstå, at den primære nøgle kun opretter et Clustered Index, hvis der ikke er andre Clustered Indexes på bordet. Hvis der er nogen eksisterende klyngede indekser, vil oprettelsen af den primære nøgle skabe et ikke-klynget indeks på tabellen, der matcher den primære nøgle.
Lad os bekræfte dette ved at droppe HumanResources.Employees Tabel og genskabe den:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Vi kan angive indstillingen IKKE-KLUSTERET indeks for den primære nøgle (se ovenfor). Der blev oprettet en tabel med et unikt, ikke-klynget indeks for de primære nøgle-PK_medarbejdere .
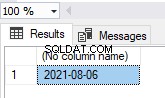
Derfor er denne tabel en heap-tabel, selvom den har en primær nøgle.
Lad os se, om SQL Server kan oprette et ikke-klynget indeks for den primære nøgle, hvis vi ikke angiver søgeordet Ikke-klynget under oprettelsen af den primære nøgle. Brug nedenstående script:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
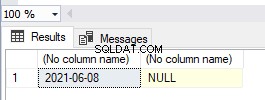
Her har vi oprettet et klynget indeks separat før oprettelsen af den primære nøgle. Og en tabel kan kun have ét klynget indeks. Derfor har SQL Server oprettet den primære nøgle som et unikt, ikke-klynget indeks. Lige nu er tabellen ikke en heap-tabel, fordi den har et klynget indeks.
Hvis jeg ombestemte mig og droppede det klyngede indeks på Fornavn og Efternavn kolonner ved hjælp af nedenstående script:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Vi har droppet det klyngede indeks med succes. HumanResources.Employees table er en heap-tabel, selvom vi har en primær nøgle tilgængelig i tabellen:
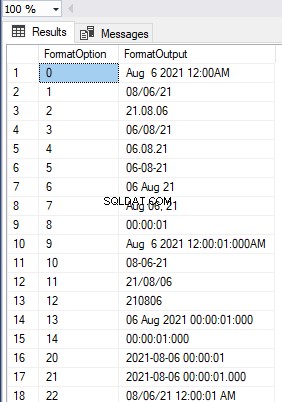
Dette fjerner myten om, at en tabel med en primær nøgle kan være en heap-tabel, hvis der ikke er nogen klyngede indekser tilgængelige på tabellen.
Primærnøgle vil have et grupperet indeks og data sorteret i fysisk rækkefølge
Som vi lærte fra det foregående eksempel, kan en primær nøgle i SQL have et ikke-klynget indeks. I så fald ville posterne ikke blive sorteret i fysisk rækkefølge.
Lad os verificere tabellen med det klyngede indeks på en primær nøgle. Vi skal tjekke, om den sorterer posterne i fysisk rækkefølge.
Genskab HumanResources.Employees tabel med minimale kolonner og IDENTITY-egenskaben fjernet for Employee_ID kolonne:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Nu hvor vi har oprettet tabellen uden den primære nøgle eller et klynget indeks, kan vi INDSÆTTE 3 poster i en ikke-sorteret rækkefølge for Employee_Id kolonne:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Lad os vælge fra HumanResources.Employees tabel:
SELECT *
FROM HumanResources.Employees
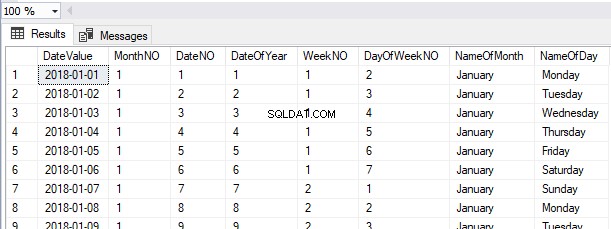
Vi kan se posterne hentet i samme rækkefølge som posterne indsat fra heap-tabellen i øjeblikket.
Lad os oprette en primær nøgle på denne heap-tabel og se, om den har nogen indflydelse på SELECT-sætningen:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Efter oprettelsen af den primære nøgle kan vi se, at SELECT-sætningen hentede poster i stigende rækkefølge efter Employee_Id (Primær nøglekolonne). Det skyldes det klyngede indeks på Employee_Id .
Hvis en primær nøgle oprettes med den ikke-klyngede indstilling, vil tabeldataene ikke blive sorteret baseret på kolonnen Primær nøgle.
Hvis længden af en enkelt post i en tabel overstiger 4030 bytes, kan kun én post passe til en side. Det klyngede indeks sikrer, at siderne er i fysisk rækkefølge.
En side er en grundlæggende lagerenhed i SQL Server-datafiler med en størrelse på 8 KB (8192 bytes). Kun 8060 bytes af den enhed kan bruges til datalagring. Det resterende beløb er til sidehoveder og andre interne elementer.
Tips til at vælge primære nøglekolonner
- Heltalsdatatypekolonner er bedst egnede til primærnøglekolonner, da de optager mindre lagerstørrelser og kan hjælpe med at hente dataene hurtigere.
- Da primære nøglekolonner har et klynget indeks som standard, skal du bruge IDENTITY-indstillingen på heltalsdatatypekolonner for at få nye værdier genereret i trinvis rækkefølge.
- I stedet for at oprette en primær nøgle på flere kolonner, skal du oprette en ny heltalskolonne med egenskaben IDENTITY defineret. Opret også et unikt indeks på flere kolonner, der oprindeligt blev identificeret for bedre ydeevne.
- Prøv at undgå kolonner med strengdatatype som varchar, nvarchar osv. Vi kan ikke garantere den sekventielle stigning af data på disse datatyper. Det kan påvirke INSERT-ydelsen på disse kolonner.
- Vælg kolonner, hvor værdier ikke bliver opdateret som primære nøgler. Hvis den primære nøgleværdi f.eks. kan ændres fra 5 til 1000, skal B-træet, der er knyttet til det klyngede indeks, opdateres, hvilket resulterer i en mindre ydeevneforringelse.
- Hvis strengdatatypekolonner skal vælges som primærnøglekolonner, skal du sikre dig, at længden af varchar- eller nvarchar-datatypekolonner forbliver lille for bedre ydeevne.
Konklusion
Vi har gennemgået det grundlæggende i begrænsninger, der er tilgængelige i SQL Server. Vi undersøgte de primære nøglebegrænsninger i detaljer og lærte, hvordan man opretter, dropper, ændrer, deaktiverer og genopbygger primære nøgler. Derudover har vi afklaret nogle populære myter omkring Primære nøgler med eksempler.
Hold øje med den næste artikel!