Introduktion
Før eller siden får ethvert informationssystem en database, ofte - mere end én. Med tiden samler den database meget data, fra adskillige GB'er til snesevis af TB'er. For at forstå, hvordan funktionaliteterne vil præstere med stigende datamængder, er vi nødt til at generere dataene for at fylde denne database.

Alle scripts, der præsenteres og implementeres, vil køre på JobEmplDB database over en rekrutteringstjeneste. Databaserealiseringen er tilgængelig her.
Tilgange til dataudfyldning af databaser til test og udvikling
Databaseudvikling og -test involverer to primære tilgange til at udfylde data:
- At kopiere hele databasen fra produktionsmiljøet med personlige og andre følsomme data ændret. På denne måde sikrer du dataene og sletter fortrolige data.
- At generere syntetiske data. Det betyder at generere testdata svarende til de rigtige data i udseende, egenskaber og sammenkoblinger.
Fordelen ved Approach 1 er, at den tilnærmer dataene og deres fordeling efter forskellige kriterier til produktionsdatabasen. Det giver os mulighed for at analysere alting præcist og derfor drage konklusioner og prognose i overensstemmelse hermed.
Denne tilgang lader dig dog ikke øge selve databasen mange gange. Det bliver problematisk at forudsige ændringer i hele informationssystemets funktionalitet i fremtiden.
På den anden måde kan du analysere upersonlige desinficerede data hentet fra produktionsdatabasen. Baseret på dem kan du definere, hvordan du genererer testdata, der ville være som de rigtige data ved deres udseende, egenskaber og indbyrdes forhold. På denne måde producerer tilgang 1 tilgang 2.
Lad os nu i detaljer gennemgå begge tilgange til dataudfyldning af databaser til test og udvikling.
Datakopiering og ændring i en produktionsdatabase
Lad os først definere den generelle algoritme for kopiering og ændring af data fra produktionsmiljøet.
Den generelle algoritme
Den generelle algoritme er som følger:
- Opret en ny tom database.
- Opret et skema i den nyoprettede database – det samme system som det fra produktionsdatabasen.
- Kopiér de nødvendige data fra produktionsdatabasen til den nyoprettede database.
- Desinficer og ændr de hemmelige data i den nye database.
- Lav en sikkerhedskopi af den nyoprettede database.
- Lever og gendan sikkerhedskopien i det nødvendige miljø.
Algoritmen bliver dog mere kompliceret efter trin 5. For eksempel kræver trin 6 et specifikt, beskyttet miljø til indledende test. Det trin skal sikre, at alle data er upersonlige, og de hemmelige data ændres.
Efter dette trin kan du vende tilbage til trin 5 igen for den testede database i det beskyttede ikke-produktionsmiljø. Derefter videresender du den testede sikkerhedskopi til de nødvendige miljøer for at gendanne den og bruge den til udvikling og test.
Vi har præsenteret den generelle algoritme for produktionsdatabasens datakopiering og ændring. Lad os beskrive, hvordan det implementeres.
Realisering af den generelle algoritme
En ny tom databaseoprettelse
Du kan lave en tom database ved hjælp af CREATE DATABASE-konstruktionen som her.
Databasen hedder JobEmplDB_Test . Den har tre filgrupper:
- PRIMÆR – det er den primære filgruppe som standard. Den definerer to filer:JobEmplDB_Test1(sti D:\DBData\JobEmplDB_Test1.mdf) , og JobEmplDB_Test2 (sti D:\DBData\JobEmplDB_Test2.ndf) . Hver fils oprindelige størrelse er 64 Mb, og væksttrinnet er 8 Mb for hver fil.
- DBTableGroup – en brugerdefineret filgruppe, der bestemmer to filer:JobEmplDB_TestTableGroup1 (sti D:\DBData\JobEmplDB_TestTableGroup1.ndf) og JobEmplDB_TestTableGroup2 (sti D:\DBData\JobEmplDB_TestTableGroup2.ndf) . Den oprindelige størrelse af hver fil er 8 Gb, og væksttrinnet er 1 Gb for hver fil.
- DBIndexGroup – en brugerdefineret filgruppe, der bestemmer to filer:JobEmplDB_TestIndexGroup1 (sti D:\DBData\JobEmplDB_TestIndexGroup1.ndf) , og JobEmplDB_TestIndexGroup2 (sti D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . Den oprindelige størrelse er 16 Gb for hver fil, og væksttrinnet er 1 Gb for hver fil.
Denne database indeholder også en journal over transaktioner:JobEmplDB_Testlog , sti E:\DBLog\JobEmplDB_Testlog.ldf . Filens oprindelige størrelse er 8 Gb, og væksttrinnet er 1 Gb.
Kopiering af skemaet og de nødvendige data fra produktionsdatabasen til en nyoprettet database
For at kopiere skemaet og de nødvendige data fra produktionsdatabasen til den nye, kan du bruge flere værktøjer. For det første er det Visual Studio (SSDT). Eller du kan bruge tredjepartsværktøjer som:
- DbForge Schema Compare og DbForge Data Compare
- ApexSQL Diff og Apex Data Diff
- SQL Compare Tool og SQL Data Compare Tool
Udførelse af scripts til dataændringer
Væsentlige krav til dataændringernes scripts
1. Det skal være umuligt at gendanne de rigtige data ved hjælp af det script.
f.eks. vil linjernes inversion ikke passe, da det giver os mulighed for at gendanne de rigtige data. Normalt er metoden at erstatte hvert tegn eller byte med et pseudotilfældigt tegn eller byte. Det samme gælder for dato og klokkeslæt.
2. Dataændringen må ikke ændre selektiviteten af deres værdier.
Det virker ikke at tildele NULL til tabellens felt. I stedet skal du sikre dig, at de samme værdier i de rigtige data forbliver de samme i de ændrede data. For eksempel, i rigtige data har du en værdi på 103785 fundet 12 gange i tabellen. Når du ændrer denne værdi i de ændrede data, skal den nye værdi forblive 12 gange i de samme felter i tabellen.
3. Størrelsen og længden af værdierne bør ikke afvige væsentligt i de ændrede data. F.eks. erstatter du hver byte eller tegn med en pseudorandom byte eller tegn. Den indledende streng forbliver den samme i størrelse og længde.
4. Indbyrdes sammenhænge i dataene må ikke brydes efter ændringerne. Det vedrører de eksterne nøgler og alle andre tilfælde, hvor du henviser til de ændrede data. Ændrede data skal forblive i de samme relationer som de reelle data var.
Implementering af scripts for ændringer af data
Lad os nu gennemgå det særlige tilfælde, hvor dataene ændres for at depersonalisere og skjule de hemmelige oplysninger. Eksemplet er rekrutteringsdatabasen.
Eksempeldatabasen indeholder følgende personlige data, som du skal bruge for at depersonalisere:
- Efter- og fornavn;
- Fødselsdato;
- Id-kortets udstedelsesdato;
- Fjernadgangscertifikatet som bytessekvensen;
- Servicegebyret for CV-promovering.
Først vil vi tjekke simple eksempler for hver type af de ændrede data:
- Dato og klokkeslæt ændres;
- Numerisk værdiændring;
- Ændring af bytesekvenserne;
- Ændring af karakterdata.
Ændring af dato og klokkeslæt
Du kan få en tilfældig dato og tid ved at bruge følgende script:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Her, @StartDate og @FinishDate er start- og slutværdierne for området. De korrelerer henholdsvis for den pseudorandom-generering af dato og klokkeslæt.
For at generere disse data bruger du systemfunktionerne RAND, CHECKSUM og NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Feltet [DocDate] står for dokumentets udstedelsesdato. Vi erstatter den med en pseudotilfældig dato, idet vi husker datointervallerne og deres begrænsninger.
Den "nederste" grænse er kandidatens fødselsdato. Den "øverste" kant er den aktuelle dato. Vi har ikke brug for tiden her, så klokkeslættet og datoformatets transformation til den nødvendige dato kommer i sidste ende. Du kan få pseudotilfældige værdier for enhver del af datoen og klokkeslættet på samme måde.
Numerisk værdiændring
Du kan få et tilfældigt heltal ved hjælp af følgende script:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal og @MaxVal er start- og slutintervallets værdier for generering af pseudorandomtal. Vi genererer det ved hjælp af systemfunktionerne RAND, CHECKSUM og NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Feltet [CountRequest] står for antallet af anmodninger, som virksomheder stiller til denne kandidats CV.
På samme måde kan du få pseudorandom-værdier for enhver numerisk værdi. Tag f.eks. et kig på det tilfældige tal for generationen af decimaltypen (18,2):
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Således kan du opdatere gebyret for CV-promovering på følgende måde:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Ændring af bytesekvenserne
Du kan få en tilfældig bytesekvens ved at bruge følgende script:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Længde står for sekvensens længde. Den definerer antallet af returnerede bytes. Her må @Length ikke være større end 16.
Generering sker ved hjælp af systemfunktionerne CRYPT_GEN_RANDOM og NEWID.
Du kan f.eks. opdatere fjernadgangscertifikatet for hver kandidat på følgende måde:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Vi genererer en pseudotilfældig bytesekvens af samme længde, som findes i feltet [RemoteAccessCertificate] på tidspunktet for ændringen. Vi antager, at bytesekvenslængden ikke overstiger 16.
På samme måde kan vi oprette vores funktion, der returnerer pseudotilfældige bytesekvenser af enhver længde. Det vil sætte resultaterne af systemfunktionen CRYPT_GEN_RANDOM til at arbejde sammen ved hjælp af den simple "+" tilføjelsesoperator. Men 16 bytes er normalt nok i praksis.
Lad os lave en prøvefunktion, der returnerer den pseudotilfældige bytesekvens af den bestemte længde, hvor det vil være muligt at indstille længden på mere end 16 bytes. Til dette skal du lave følgende præsentation:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Vi har brug for det for at undgå begrænsningen, der forbyder os at bruge NEWID i funktionen.
Opret på samme måde den næste præsentation til samme formål:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Opret en præsentation mere:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Alle tre funktioners definitioner er her. Og her er implementeringen af funktionen, der returnerer en pseudotilfældig bytesekvens af den bestemte længde.
Først definerer vi, om den nødvendige funktion er til stede. Hvis ikke - laver vi først en stud. Under alle omstændigheder involverer koden en passende ændring af funktionsdefinitionen. Til sidst tilføjer vi funktionens beskrivelse via de udvidede egenskaber. Flere detaljer om databasens dokumentation findes i denne artikel.
For at opdatere fjernadgangscertifikatet for hver kandidat kan du gøre som følger:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Som du kan se, er der ingen begrænsninger for bytesekvenslængden her.
Dataændring – Tegndataændring
Her tager vi et eksempel for det engelske og det russiske alfabet, men du kan gøre det for et hvilket som helst andet alfabet. Den eneste betingelse er, at dens tegn skal være til stede i NCHAR-typerne.
Vi skal oprette en funktion, der accepterer linjen, erstatter hvert tegn med et pseudotilfældigt tegn og derefter sætter resultatet sammen og returnerer det.
Vi skal dog først forstå, hvilke karakterer vi har brug for. Til det kan vi udføre følgende script:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Vi laver tabellen [test].[TblCharacterCode], der inkluderer følgende felter:
- ValueInt – den numeriske værdi af tegnet;
- ValueNChar – tegnet af NCHAR-typen;
- ValueChar – tegnet af CHAR-typen.
Lad os gennemgå indholdet af denne tabel. Vi har brug for følgende anmodning:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
Tallene er i intervallet 48 til 57:
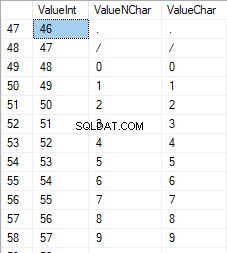
De latinske tegn med store bogstaver er i intervallet 65 til 90:
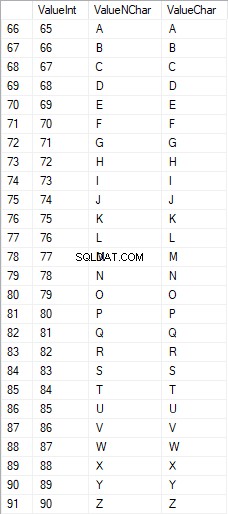
Latinske tegn i underordnet er i intervallet 97 til 122:
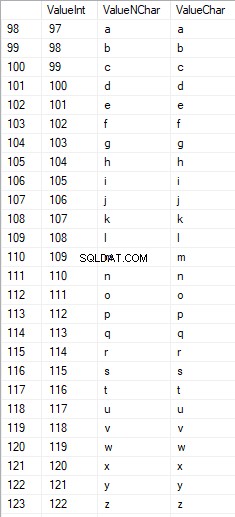
Russiske tegn med store bogstaver er i intervallet 1040 til 1071:

Russiske tegn med små bogstaver er i intervallet 1072 til 1103:


Og tegn i intervallet 58 til 64:

Vi vælger de nødvendige tegn og sætter dem i tabellen [test].[SelectCharactersCode] på følgende måde:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Lad os nu undersøge indholdet af denne tabel ved hjælp af følgende script:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Vi modtager følgende resultat:

På denne måde har vi [test].[SelectCharactersCode] tabel, hvor:
- ValueInt – tegnets numeriske værdi
- ValueNChar – tegnet af NCHAR-typen
- ValueChar – CHAR-typen
- IsNumeral – kriteriet om, at et tegn er et ciffer
- IsUpperCase – kriteriet for et tegn med store bogstaver
- islatinsk – kriteriet om, at et tegn er et latinsk tegn;
- IsRus – kriteriet om, at et tegn er et russisk tegn
- IsExtra – kriteriet om, at et tegn er et ekstra tegn
Nu kan vi få koden til de nødvendige tegns indsættelse. Sådan gør du for eksempel for de latinske tegn med små bogstaver:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Vi modtager følgende resultat:

Det er det samme for de russiske tegn med små bogstaver:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Vi får følgende resultat:

Det er det samme for karaktererne:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Resultatet er som følger:

Så vi har koder til at indsætte følgende data separat:
- De latinske tegn med små bogstaver.
- De russiske tegn med små bogstaver.
- Cifrene.
Det virker for både NCHAR- og CHAR-typerne.
På samme måde kan vi forberede et indsættelsesscript for ethvert sæt tegn. Desuden vil hvert sæt få sin egen tabuleringsfunktion.
For at være enkel implementerer vi den fælles tabuleringsfunktion, der returnerer det nødvendige datasæt for de tidligere valgte data på følgende måde:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Det endelige resultat er som følger:

Klar-scriptet er pakket ind i tabuleringsfunktionen [test].[GetSelectCharacters].
Det er vigtigt at fjerne en ekstra UNION ALL i slutningen af det genererede script, og i [ValueInt]=39 skal vi ændre "' til "":
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLDenne tabelfunktion returnerer følgende sæt felter:
- Nummer – linjenummeret i det returnerede datasæt;
- ValueInt – tegnets numeriske værdi;
- ValueNChar – tegnet af NCHAR-typen;
- ValueChar – karakteren CHAR;
- IsNumeral – kriteriet om, at tegnet er et ciffer;
- IsUpperCase – kriteriet, der definerer, at tegnet er med store bogstaver;
- islatinsk – kriteriet, der definerer, at tegnet er et latinsk tegn;
- IsRus – kriteriet, der definerer, at tegnet er et russisk tegn;
- IsExtra – kriteriet, der definerer, at karakteren er en ekstra.
Til input har du følgende parametre:
- @IsNumeral – hvis det skulle returnere tallene;
- @IsUpperCase :
- 0 – det må kun returnere små bogstaver for bogstaver;
- 1 – det må kun returnere de store bogstaver;
- NULL – det skal returnere breve i alle tilfælde.
- @IsLatin – den skal returnere de latinske tegn
- @IsRus – den skal returnere de russiske tegn
- @IsExtra – den skal returnere yderligere tegn.
Alle flag bruges i henhold til den logiske OR. Hvis du f.eks. skal have tal og latinske tegn med små bogstaver returneret, kalder du tabuleringsfunktionen på følgende måde:
Vi får følgende resultat:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Vi får følgende resultat:

Vi implementerer [test].[GetRandString]-funktionen, der vil erstatte linjen med pseudotilfældige tegn, mens den oprindelige strenglængde bevares. Denne funktion skal omfatte muligheden for kun at betjene de tegn, der er cifre. Det kan fx være nyttigt, når du ændrer ID-kortets serie og nummer.
Når vi implementerer [test].[GetRandString]-funktionen, får vi først det sæt af tegn, der er nødvendige for at generere en pseudotilfældig linje med den specificerede længde i inputparameteren @Length. Resten af parametrene fungerer som beskrevet ovenfor.
Derefter sætter vi det modtagne sæt af data i tabelvariablen @tbl . Denne tabel gemmer felterne [ID] – ordrenummeret i den resulterende tabel med tegn og [Værdi] – karakterens præsentation i NCHAR-typen.
Derefter genererer den i en cyklus et pseudotilfældigt tal i intervallet 1 til kardinaliteten af @tbl-tegnene modtaget tidligere. Vi sætter dette nummer ind i [ID] af tabelvariablen @tbl til søgning. Når søgningen returnerer linjen, tager vi tegnet [Værdi] og "limer" det til den resulterende linje @res.
Når cyklussens arbejde slutter, kommer den modtagne linje tilbage via @res-variablen.
Du kan ændre både for- og efternavn på kandidaten på følgende måde:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Derfor har vi undersøgt funktionens implementering og dens brug for NCHAR- og NVARCHAR-typerne. Vi kan nemt gøre det samme for CHAR- og VARCHAR-typerne.
Nogle gange er vi dog nødt til at generere en linje i henhold til tegnsættet, ikke de alfabetiske tegn eller tal. På denne måde skal vi først bruge følgende multi-operator funktion [test].[GetListCharacters].
Funktionen [test].[GetListCharacters] får de to følgende parametre for input:
- @str – selve tegnlinjen;
- @IsGroupUnique – den definerer, om den skal gruppere unikke tegn i linjen.
Med den rekursive CTE omdannes inputlinjen @str til tegntabellen – @ListCharacters. Denne tabel indeholder følgende felter:
- ID – rækkefølgenummeret på linjen i den resulterende tegntabel;
- Karakter – præsentationen af karakteren i NCHAR(1)
- Tæl – antallet af karakterens gentagelser i linjen (det er altid 1, hvis parameteren @IsGroupUnique=0)
Lad os tage to eksempler på denne funktions brug for at forstå dens arbejde bedre:
- Transformation af linjen til listen over ikke-unikke tegn:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Vi får resultatet:

Dette eksempel viser, at linjen transformeres til listen over tegn "som den er", uden at den grupperes efter karakterernes unikke karakter (feltet [Optælling] indeholder altid 1).
- Transformationen af linjen til listen over unikke tegn
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Resultatet er som følger:
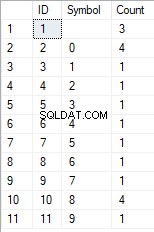
Dette eksempel viser, at linjen er omdannet til listen over tegn grupperet efter deres unikke karakter. Feltet [Tæl] viser antallet af fund af hvert tegn i inputlinjen.
Baseret på multi-operator-funktionen [test].[GetListCharacters], opretter vi en skalarfunktion [test].[GetRandString2].
Definitionen af den nye skalarfunktion viser dens lighed med skalarfunktionen [test].[GetRandString]. Den eneste forskel er, at den bruger [test].[GetListCharacters] multi-operator-funktionen i stedet for [test].[GetSelectCharacters]-tabuleringsfunktionen.
Lad os her gennemgå to eksempler på den implementerede skalarfunktion :
Vi genererer en pseudotilfældig linje på 12 tegns længde fra inputlinjen med tegn, der ikke er grupperet efter unikhed:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Resultatet er:
64017!!5!!!7
Nøgleordet er DEFAULT. Den angiver, at standardværdien sætter parameteren. Her er den nul (0).
Eller
Vi genererer en pseudotilfældig linje med en længde på 12 tegn fra inputlinjen med tegn grupperet efter unikhed:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Resultatet er:
35792!428273
Implementering af det generelle script til datasanering og de hemmelige dataændringer
Vi har undersøgt simple eksempler for hver type ændrede data:
- Ændring af dato og klokkeslæt;
- Ændring af den numeriske værdi;
- Ændring af bytesekvensen;
- Ændring af karakterernes data.
Disse eksempler opfylder dog ikke kriterierne 2 og 3 for de dataændrende scripts:
- Kriterium 2 :selektiviteten af værdier vil ikke ændre sig væsentligt i de ændrede data. Du kan ikke bruge NULL til tabellens felt. I stedet skal du sikre dig, at de samme reelle dataværdier forbliver de samme i de ændrede data. Hvis de rigtige data f.eks. indeholder 103785-værdien 12 gange i en tabels felt med forbehold for ændringer, skal de ændrede data inkludere en anden (ændret) værdi fundet 12 gange i det samme felt i tabellen.
- Kriterium 3 :længden og størrelsen af værdier bør ikke ændres væsentligt i de ændrede data. F.eks. erstatter du hvert tegn/byte med et pseudotilfældigt tegn/byte.
Derfor skal vi oprette et script, der tager værdiernes selektivitet i tabellens felter i betragtning.
Lad os tage et kig på vores database for rekrutteringstjenesten. Som vi ser, er personoplysninger kun til stede i kandidattabellen [dbo].[Medarbejder].
Antag, at tabellen indeholder følgende felter:
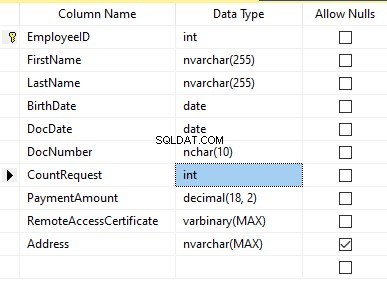
Beskrivelser:
- Fornavn – navn, linje NVARCHAR(255)
- Efternavn – efternavn, linje NVARCHAR(255)
- Fødselsdato – fødselsdato, DATO
- Dokumentnummer – ID-kortnummeret med to cifre i begyndelsen for passerien, og de næste syv cifre er dokumentets nummer. Mellem dem har vi en bindestreg som NCHAR(10)-linjen.
- DocDate – udstedelsesdatoen for ID-kortet, DATO
- CountRequest – antallet af anmodninger for den pågældende kandidat under søgningen efter CV, hele tallet INT
- Betalingsbeløb – det modtagne gebyr for CV-kampagneservice, decimaltallet (18,2)
- Fjernadgangscertifikat – fjernadgangscertifikatet, bytesekvens VARBINARY
- Adresse – bopælsadressen eller registreringsadressen, linje NVARCHAR(MAX)
Derefter, for at bevare den indledende selektivitet, skal vi implementere følgende algoritme:
- Udtræk alle unikke værdier for hvert felt, og behold resultaterne i midlertidige tabeller eller tabelvariabler;
- Generer en pseudotilfældig værdi for hver unik værdi. Denne pseudotilfældige værdi må ikke afvige væsentligt i længde og størrelse fra den oprindelige værdi. Gem resultatet samme sted, hvor vi gemte punkt 1-resultaterne. Hver nygenereret værdi skal have en unik aktuel værdi korreleret.
- Erstat alle værdier i tabellen med nye værdier fra punkt 2.
I begyndelsen afpersonaliserer vi for- og efternavne på kandidater. Vi antager, at efternavn og fornavn altid er til stede, og de er ikke mindre end to tegn lange i hvert felt.
Først vælger vi unikke navne. Derefter genererer den en pseudorandom linje for hvert navn. Navnets længde forbliver den samme; det første tegn er med store bogstaver, og de andre tegn er med små bogstaver. Vi bruger den tidligere oprettede skalarfunktion [test].[GetRandString] til at generere en pseudotilfældig linje af den specifikke længde i henhold til karakterernes definerede kriterier.
Derefter opdaterer vi navnene i kandidaternes tabel i henhold til deres unikke værdier. Det er det samme for efternavnene.
Vi depersonaliserer DocNumber-feltet. Det er ID-kortets (pas) nummeret. De første to tegn står for dokumentets serie, og de sidste syv cifre er nummeret på dokumentet. Bindestregen er mellem dem. Derefter udfører vi desinficeringsoperationen.
Vi indsamler alle unikke dokumenters numre og genererer en pseudorandom linje for hver enkelt. Linjens format er 'XX-XXXXXXX', hvor X er cifferet i intervallet 0 til 9. Her bruger vi den tidligere oprettede [test].[GetRandString] skalarfunktion til at generere en pseudorandom linje af den angivne længde iflg. karakterernes parametre indstillet.
Derefter opdateres [DocNumber]-feltet i kandidattabellen [dbo].[Medarbejder].
Vi depersonaliserer DocDate-feltet (udstedelsesdatoen for ID-kortet) og feltet Fødselsdato (kandidatens fødselsdato).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Eller:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
Resultatet er:
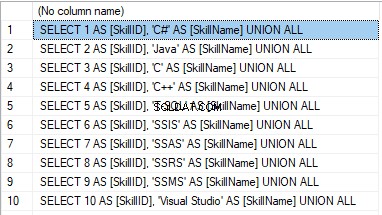
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
DTM Data Generator
Datanamic Data Generator MultiDB
Now, let’s examine one of these tools more precisely.
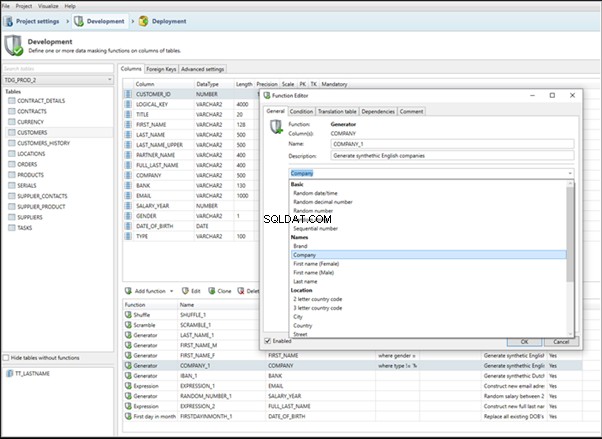
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
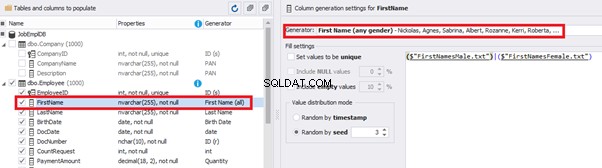
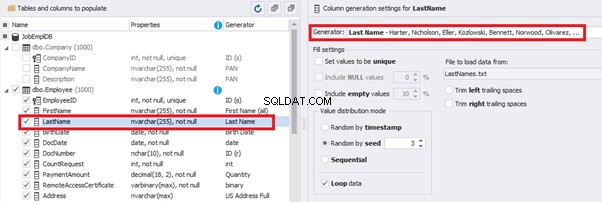
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
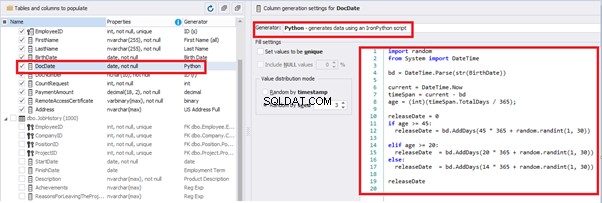
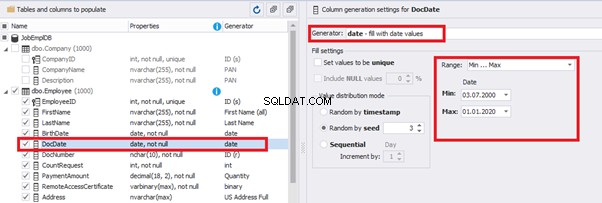
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
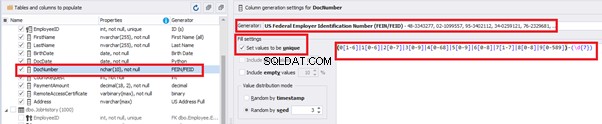
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
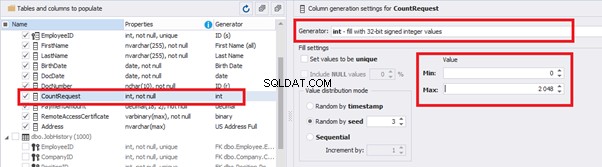
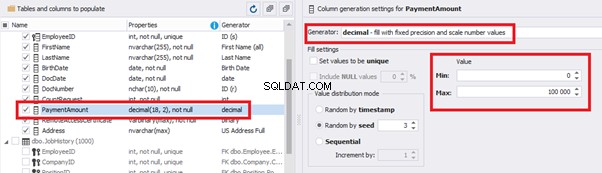
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
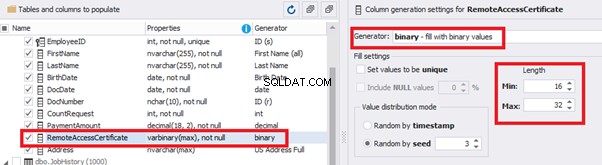
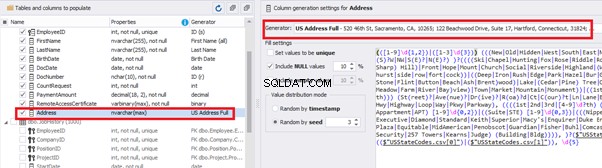
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
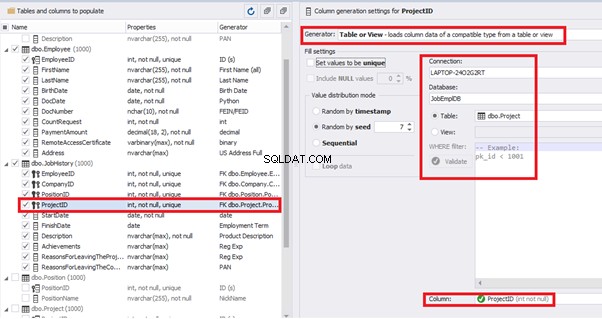
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
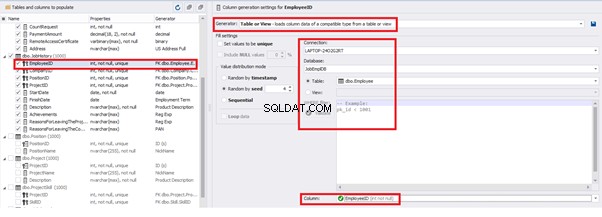
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
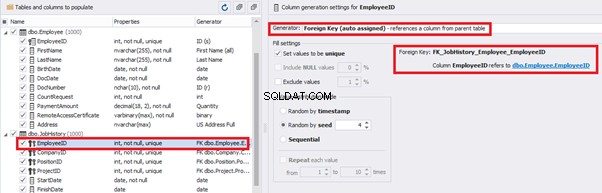
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
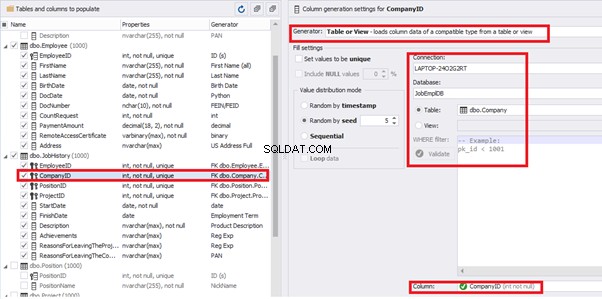
[PositionID] – from the table of positions [dbo].[Position]:
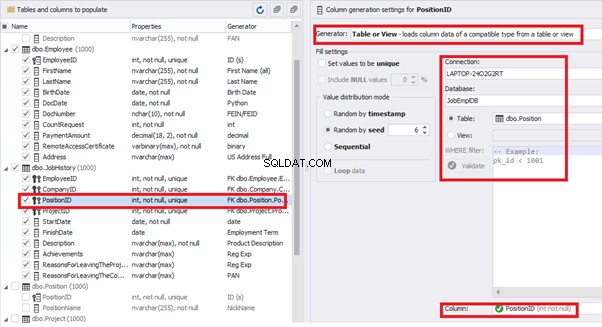
[ProjectID] – from the table of projects [dbo].[Project]:
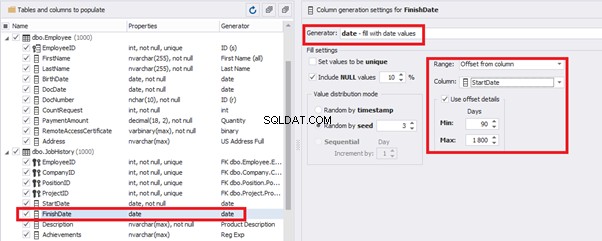
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
That’s why we resolve the dates’ problem (BirthDate
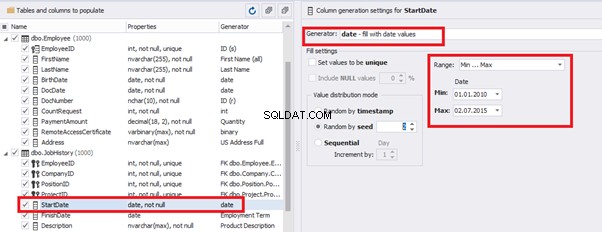
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
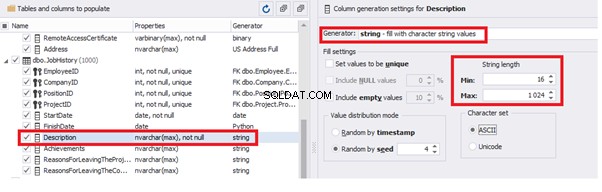
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
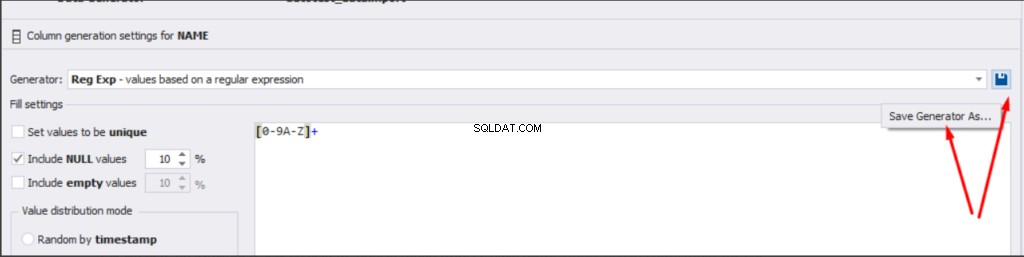
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 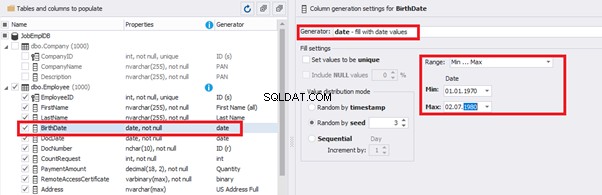
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate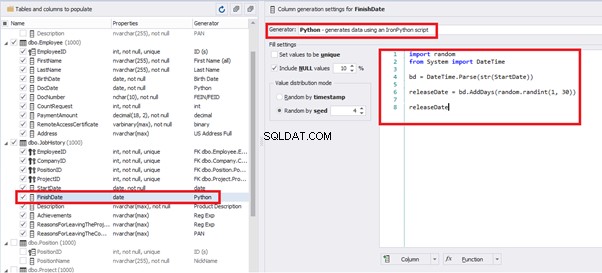
Konklusion
Referencer
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation