SQL Server giver os en række vinduesfunktioner, der hjælper os med at udføre beregninger på tværs af et sæt rækker uden at skulle gentage kaldene til databasen. I modsætning til standard aggregerede funktioner vil vinduesfunktionerne ikke gruppere rækkerne i en enkelt outputrække, de vil returnere en enkelt aggregeret værdi for hver række, og beholde de separate identiteter for disse rækker. Window-udtrykket her er ikke relateret til Microsoft Windows-operativsystemet, det beskriver det sæt af rækker, som funktionen vil behandle.
En af de mest nyttige typer vinduesfunktioner er Rangeringsvinduefunktioner, der bruges til at rangere specifikke feltværdier og kategorisere dem i henhold til rangeringen af hver række, hvilket resulterer i en enkelt aggregeret værdi for hver deltagende række. Der er fire rangeringsvinduefunktioner, der understøttes i SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() og NTILE(). Alle disse funktioner bruges til at beregne ROWID for det angivne rækkevindue på deres egen måde.
Fire rangeringsvinduefunktioner bruger OVER()-sætningen, der definerer et brugerspecificeret sæt rækker i et forespørgselsresultatsæt. Ved at definere OVER()-udtrykket, kan du også inkludere PARTITION BY-udtrykket, der bestemmer det sæt af rækker, som vinduesfunktionen vil behandle, ved at angive kolonne- eller kommaseparerede kolonner til at definere partitionen. Derudover kan ORDER BY-sætningen inkluderes, som definerer sorteringskriterierne inden for partitionerne, som funktionen vil gå gennem rækkerne under behandlingen.
I denne artikel vil vi diskutere, hvordan man praktisk anvender fire rangeringsvinduefunktioner:ROW_NUMBER(), RANK(), DENSE_RANK() og NTILE() og forskellen mellem dem.
For at tjene vores demo vil vi oprette en ny simpel tabel og indsætte nogle få poster i tabellen ved hjælp af T-SQL scriptet nedenfor:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Du kan kontrollere, at dataene er indsat korrekt ved hjælp af følgende SELECT-sætning:
SELECT * FROM StudentScore ORDER BY Student_ScoreMed det sorterede resultat anvendt, er resultatsættet som følger nedenfor:

ROW_NUMBER()
Rangeringsvinduefunktionen ROW_NUMBER() returnerer et unikt sekventielt nummer for hver række inden for partitionen i det angivne vindue, startende ved 1 for den første række i hver partition og uden at gentage eller springe tal over i rangeringsresultatet for hver partition. Hvis der er duplikerede værdier i rækkesættet, vil rangerings-id-numrene blive tildelt vilkårligt. Hvis PARTITION BY-klausulen er angivet, nulstilles rækkefølgenummeret for hver partition. I den tidligere oprettede tabel viser forespørgslen nedenfor, hvordan man bruger ROW_NUMBER rangeringsvinduefunktionen til at rangere StudentScore-tabellens rækker i henhold til hver elevs score:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Det fremgår tydeligt af resultatsættet nedenfor, at ROW_NUMBER-vinduefunktionen rangerer tabelrækkerne i henhold til Student_Score-kolonnens værdier for hver række ved at generere et unikt tal for hver række, der afspejler dens Student_Score-rangering startende fra tallet 1 uden dubletter eller huller og beskæftiger sig med alle rækkerne som én partition. Du kan også se, at duplikatresultaterne tildeles forskellige rækker tilfældigt:
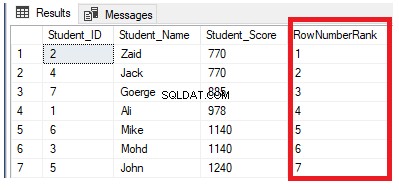
Hvis vi ændrer den tidligere forespørgsel ved at inkludere PARTITION BY-klausulen til at have mere end én partition, som vist i T-SQL-forespørgslen nedenfor:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Resultatet vil vise, at ROW_NUMBER-vinduefunktionen vil rangere tabelrækkerne i henhold til Student_Score-kolonnens værdier for hver række, men den vil omhandle de rækker, der har den samme Student_Score-værdi som én partition. Du vil se, at der vil blive genereret et unikt tal for hver række, der afspejler dens Student_Score-rangering, startende fra tallet 1 uden dubletter eller huller inden for samme partition, og nulstille rangnummeret, når du flytter til en anden Student_Score-værdi.
For eksempel vil elever med score 770 blive rangeret inden for denne score ved at tildele den et rangnummer. Men når det flyttes til eleven med score 885, nulstilles startnummeret til at starte igen ved 1, som vist nedenfor:
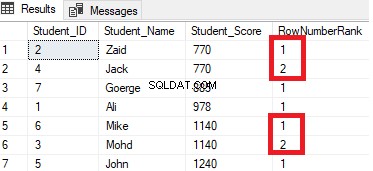
RANK()
Rangeringsvinduefunktionen RANK() returnerer et unikt rangnummer for hver særskilt række i partitionen i henhold til en specificeret kolonneværdi, startende ved 1 for den første række i hver partition, med samme rangering for duplikerede værdier og efterlader huller mellem rækkerne; dette hul vises i rækkefølgen efter de duplikerede værdier. Med andre ord opfører RANK() rangeringsvinduefunktionen sig som funktionen ROW_NUMBER() bortset fra rækkerne med lige værdier, hvor den vil rangere med det samme rangerings-id og generere et hul efter det. Hvis vi ændrer den forrige rangeringsforespørgsel til at bruge RANK() rangeringsfunktionen:
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreDu vil se fra resultatet, at RANK-vinduefunktionen vil rangere tabelrækkerne i henhold til kolonneværdierne for Student_Score for hver række, med en rangeringsværdi, der afspejler dens Student_Score startende fra tallet 1, og rangordner de rækker, der har samme Student_Score med samme rangværdi. Du kan også se, at to rækker med Student_Score lig med 770 er rangeret med samme værdi, hvilket efterlader et hul, som er det missede nummer 2, efter den andenrangerede række. Det samme sker med de rækker, hvor Student_Score er lig med 1140, der er rangeret med samme værdi, hvilket efterlader et hul, som er det manglende tal 6, efter den anden række, som vist nedenfor:
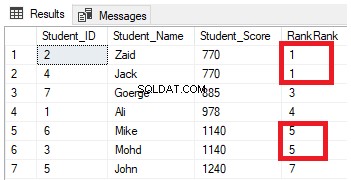
Ændring af den tidligere forespørgsel ved at inkludere PARTITION BY-klausulen til at have mere end én partition, som vist i T-SQL-forespørgslen nedenfor:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreRangeringsresultatet vil ikke have nogen betydning, da rangeringen vil blive udført i henhold til Student_Score-værdier pr. hver partition, og dataene vil blive opdelt i henhold til Student_Score-værdierne. Og på grund af det faktum, at hver partition vil have rækker med de samme Student_Score-værdier, vil rækkerne med de samme Student_Score-værdier i samme partition blive rangeret med en værdi lig med 1. Når man flytter til den anden partition, vil rangeringen således nulstilles, startende igen med tallet 1, med alle rangeringsværdier lig med 1 som vist nedenfor:
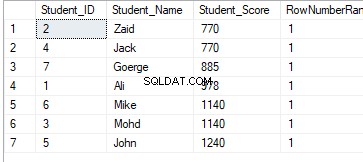
DENSE_RANK()
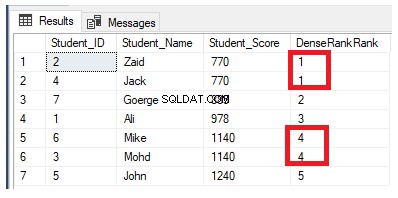
DENSE_RANK()-rangeringsvinduefunktionen ligner RANK()-funktionen ved at generere et unikt rangnummer for hver særskilt række i partitionen i henhold til en specificeret kolonneværdi, startende ved 1 for den første række i hver partition, rangering af rækkerne med ens værdier med det samme rangnummer, bortset fra at det ikke springer nogen rang over, og efterlader ingen mellemrum mellem rækkerne.
Hvis vi omskriver den forrige rangeringsforespørgsel til at bruge DENSE_RANK() rangeringsfunktionen:
Rediger igen den forrige forespørgsel ved at inkludere PARTITION BY-sætningen, så den har mere end én partition, som vist i T-SQL-forespørgslen nedenfor:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
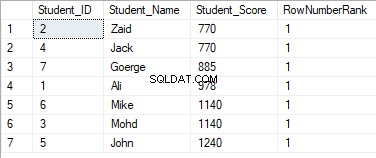
Rangeringsværdierne vil ikke have nogen betydning, hvor alle rækkerne vil blive rangeret med værdien 1, på grund af at tildele de duplikerede værdier til den samme rangeringsværdi og nulstille rangstart-id'et ved behandling af en ny partition, som vist nedenfor:
NTILE(N)
Funktionen NTILE(N)-rangeringsvindue bruges til at fordele rækkerne i rækkesættet i et specificeret antal grupper, hvilket giver hver række i rækkesættet et unikt gruppenummer, startende med tallet 1, der viser den gruppe, denne række tilhører til, hvor N er et positivt tal, som definerer antallet af grupper, du skal fordele rækkerne i.
Med andre ord, hvis du har brug for at opdele specifikke datarækker i tabellen i 3 grupper, baseret på bestemte kolonneværdier, vil funktionen NTILE(3)-rangeringsvindue hjælpe dig med at opnå dette nemt.
Antallet af rækker i hver gruppe kan beregnes ved at dividere antallet af rækker i det nødvendige antal grupper. Hvis vi ændrer den forrige rangeringsforespørgsel til at bruge NTILE(4) rangeringsvinduefunktion til at rangere syv tabelrækker i fire grupper som T-SQL-forespørgslen nedenfor:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
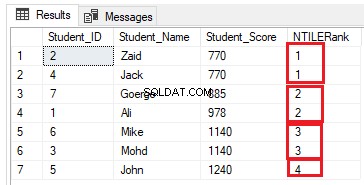
Antallet af rækker skal være (7/4=1,75) rækker i hver gruppe. Ved at bruge funktionen NTILE() vil SQL Server Engine tildele 2 rækker til de første tre grupper og en række til den sidste gruppe, for at få alle rækkerne inkluderet i grupperne, som vist i resultatsættet nedenfor:
Ændring af den tidligere forespørgsel ved at inkludere PARTITION BY-klausulen til at have mere end én partition, som vist i T-SQL-forespørgslen nedenfor:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
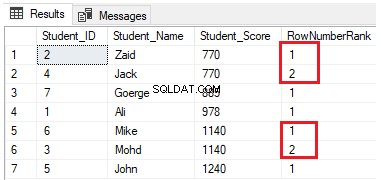
FROM StudentScoreRækkerne vil blive fordelt i fire grupper på hver partition. For eksempel vil de første to rækker med Student_Score lig med 770 være i den samme partition og vil blive fordelt inden for grupperne, der rangerer hver enkelt med et unikt nummer, som vist i resultatsættet nedenfor:
Putting All Together
For at få et mere klart sammenligningsscenarie, lad os afkorte den foregående tabel, tilføje et andet klassifikationskriterium, som er elevernes klasse, og til sidst indsætte nye syv rækker ved hjælp af T-SQL-scriptet nedenfor:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Derefter vil vi rangere syv rækker i henhold til hver elevs score, og opdele eleverne efter deres klasse. Med andre ord vil hver partition omfatte én klasse, og hver klasse af elever vil blive rangeret i henhold til deres score inden for samme klasse ved at bruge fire tidligere beskrevne rangeringsvinduefunktioner, som vist i T-SQL-scriptet nedenfor:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOPå grund af det faktum, at der ikke er nogen duplikerede værdier, vil fire rangeringsvinduefunktioner fungere på samme måde og returnere det samme resultat, som vist i resultatsættet nedenfor:
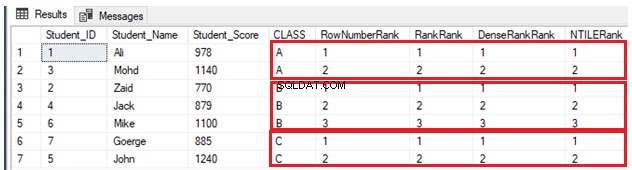
Hvis en anden elev er inkluderet i klasse A med en score, som en anden elev i samme klasse allerede har, ved hjælp af INSERT-sætningen nedenfor:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Intet vil ændre sig for ROW_NUMBER() og NTILE() rangeringsvinduefunktionerne. Funktionerne RANK og DENSE_RANK() vil tildele den samme rangering for eleverne med samme score, med et hul i rækkerne efter de dubletrækker ved brug af funktionen RANK og ingen hul i rækkerne efter de duplikerede rækker ved brug af DENSE_RANK( ), som vist i resultatet nedenfor:
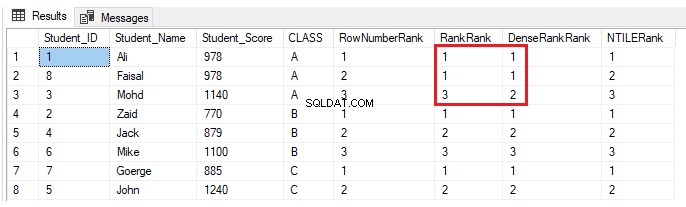
Praktisk scenarie
Rangeringsvinduets funktioner bruges i vid udstrækning af SQL Server-udviklere. Et af de almindelige scenarier for brug af rangeringsfunktioner, når du vil hente bestemte rækker og springe andre over, ved at bruge ROW_NUMBER(,) rangeringsvinduefunktionen i en CTE, som i T-SQL scriptet nedenfor, der returnerer eleverne med rangeringer mellem 2 og 5 og spring de andre over:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Resultatet vil vise, at kun elever med rang mellem 2 og 5 vil blive returneret:
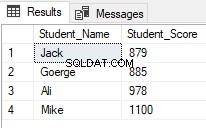
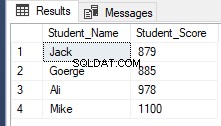
Startende fra SQL Server 2012, en ny nyttig kommando, OFFSET FETCH blev introduceret, som kan bruges til at udføre den samme tidligere opgave ved at hente specifikke poster og springe de andre over ved at bruge T-SQL-scriptet nedenfor:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Henter det samme tidligere resultat som vist nedenfor:
Konklusion
SQL Server giver os fire rangeringsvinduefunktioner, der hjælper os med at rangere de angivne rækker i henhold til specifikke kolonneværdier. Disse funktioner er:ROW_NUMBER(), RANK(), DENSE_RANK() og NTILE(). Alle disse rangeringsfunktioner udfører rangeringsopgaven på sin egen måde, og returnerer det samme resultat, når der ikke er duplikerede værdier i rækkerne. Hvis der er en dubletværdi i rækkesættet, vil RANK-funktionen tildele det samme rangerings-id til alle rækker med samme værdi, hvilket efterlader huller mellem rækkerne efter duplikaterne. Funktionen DENSE_RANK vil også tildele det samme rangerings-id for alle rækker med samme værdi, men vil ikke efterlade noget hul mellem rækkerne efter dubletterne. Vi gennemgår forskellige scenarier i denne artikel for at dække alle mulige tilfælde, der hjælper dig med at forstå placeringsvinduets funktioner praktisk.
Referencer:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- OFFSET FETCH-klausul (SQL Server Compact)