I denne artikel vil vi tale om SQL Server Checkpoints.
For at forbedre ydeevnen anvender SQL Server ændringer til databasesider i hukommelsen. Ofte kaldes denne hukommelse buffercachen eller bufferpuljen. SQL Server tømmer ikke disse sider til disk efter hver ændring. I stedet udfører databasemotoren kontrolpunkter på hver database fra tid til anden. KJEKKEPUNKT operation skriver de beskidte sider (aktuelt modificerede sider i hukommelsen) og skriver også detaljer om transaktionsloggen.
SQL Server understøtter fire typer kontrolpunkter:
1. Automatisk — Denne type kontrolpunkter forekommer bag kulisserne og afhænger af serverkonfigurationerne for gendannelsesinterval. Værdien måles i minutter, og standardværdien er 1 minut (kan ikke indstilles lavere). Kontrolpunktet afsluttes på den tid, der minimerer påvirkningen af ydeevnen.
EXEC sp_configure 'recovery interval', 'seconds'
Under SIMPLE-gendannelsesmodellen udløses et automatisk kontrolpunkt også, når transaktionsloggen er 70 % fuld.
2. Indirekte — Denne type kontrolpunkter forekommer også bag kulisserne i henhold til de brugerspecificerede indstillinger for databasegendannelsestid. Fra SQL Server 2016 CTP2 er standardværdien for denne type kontrolpunkt 1 minut. Det betyder, at en database vil bruge indirekte kontrolpunkter. For ældre SQL Server-versioner er standarden 0. Det betyder, at en database vil bruge automatiske kontrolpunkter, hvis frekvens afhænger af indstillingen af gendannelsesinterval for SQL Server-instansen. Microsoft anbefaler 1 minut for de fleste systemer.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Når du indstiller dette, skal du overveje det underliggende I/O-undersystems muligheder. Det kan være fornuftigt at indstille denne lavere for hurtigere I/O-undersystemer (f.eks. SSD'er). Vær forsigtig, denne indstilling fortsætter gennem backup og gendannelse, så gendannelse til langsommere hardware kan forårsage ydeevneproblemer på grund af for meget I/O-belastning.
3. Manual — Opstår under udførelse af T-SQL CHECKPOINT-kommandoen.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration er et heltal, der bruges til at definere den tid, hvor et kontrolpunkt skal fuldføres. Denne parameter styrer også, hvor mange ressourcer der er tildelt kontrolpunktsoperationen. Hvis parameteren ikke er specificeret, afsluttes kontrolpunktet inden for den tid, der minimerer indvirkningen på ydeevnen.
4. Intern — Nogle SQL Server-operationer udsteder denne type kontrolpunkter for at sikre, at diskbilleder matcher den aktuelle transaktionslogtilstand. Disse er kontrolpunkter, der udføres, når en bestemt operation finder sted:
- En datafil tilføjes eller fjernes
- En databasenedlukning sker (uanset grund)
- Der oprettes en sikkerhedskopi eller et øjebliksbillede af databasen
- Der køres en DBCC-kommando, der opretter et skjult database-øjebliksbillede (eller f.eks. DBCC_CHECKDB, DBCC_CHECKTABLE).
Hvorfor er kontrolpunkter nyttige?
Kontrolpunkter reducerer tid for gendannelse af nedbrud. Dette sker, fordi datafilsider ikke skrives til disken samtidig med logposterne. Der er datafilsider i hukommelsen, der er mere opdaterede end datafilsider på disken.
Kontrolpunkter reducerer I/O til disk og forbedrer ydeevnen. Grunden til, at datafilsider ikke skrives til disken på det tidspunkt, transaktionen forpligtes, er for at reducere antallet af I/O-operationer. Forestil dig de flere tusinde OPDATERINGStransaktioner til en enkelt dataside. Det er mere effektivt at skrive en dataside til disken én gang, under et kontrolpunkt, i stedet for efter hver ændring.
Rene og snavsede sider
Bufferpuljen opretholder et antal datasider i hukommelsen. Der er to typer datasider:ren og snavset . En ren side er en, der ikke er blevet ændret, siden den sidst blev læst fra disk eller skrevet til disk. En beskidt side er en side, der er blevet ændret, og ændringerne er ikke blevet skrevet til disken. Kontrolpunkter henviser til "beskidte sider".
Informationen om siden kan ses ved hjælp af sys.dm_os_buffer_descriptors . Lad os se, hvad denne funktion returnerer:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
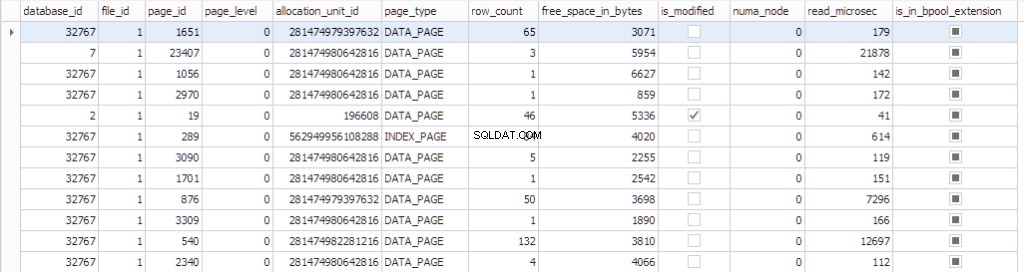
Hver side har en kontrolstruktur tilknyttet sig, der sporer sidetilstand:
- En database, der har datdabase_id 32767 er en skrivebeskyttet ressourcedatabase, der indeholder alle systemobjekter.
- fil_id , side_id , allocation_unit_id den side tilhører.
- Hvad slags side er det:enten dataside eller indeksside.
- Antallet af rækker på siden.
- Den ledige plads på siden
- Om siden er beskidt eller ej
- Numa_node, som den bestemte side tilhører
- Nogle oplysninger om algoritmen sidst brugte
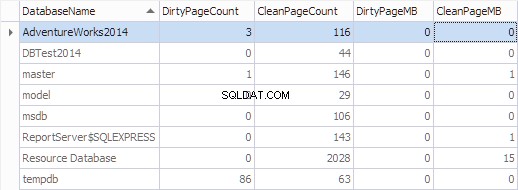
Lad os samle disse oplysninger efter database ved hjælp af følgende kode:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Checkpoint-mekanisme
Når kontrolpunktet opstår, skriver det alle beskidte sider til disken. Sider markeret som beskidte, så snart de har nogle ændringer. Det er ligegyldigt, om transaktionen, der foretog ændringen, er forpligtet eller ikke-forpligtet på tidspunktet for kontrolpunktet. Når siderne er blevet skrevet til disken, ryddes den "beskidte" bit. Når kontrolpunktet opstår, sker følgende handlinger:
- En ny logpost angiver starten på et kontrolpunkt
- Yderligere logposter vises med kontrolpunktoplysninger (såsom status for transaktionsloggen på det tidspunkt, hvor kontrolpunktet startes)
- Alle beskidte sider skrives til disken
- Marker LSN for kontrolpunktet på databasens startside (i dbi_checkptLSN), dette er afgørende for gendannelse af nedbrud
- Hvis SIMPLE gendannelsesmodel bruges, så prøv at rydde loggen
- En endelig logpost angiver, at kontrolpunktet er udført
Det er muligt for kontrolpunkter af flere databaser at forekomme parallelt. SQL Server 2000 var begrænset til ét kontrolpunkt ad gangen. Når buffermanageren skriver en side, søger den efter tilstødende beskidte sider, der kan inkluderes i en enkelt samle-skrive-handling. Bufferpuljen vil også forsøge at sikre, at den ikke overbelaster I/O-undersystemet. Den holder styr på, hvor lang tid det tager for I/O at fuldføre. Hvis skrivelatensen overstiger 20 ms under kontrolpunktet, drosler den sig selv. Under nedlukningen øges drosletærsklen til 100 ms. Du kan finde en mere detaljeret forklaring her. Du kan bruge udokumenteret "-kXX" opstartsmulighed til at indstille checkpoint I/O-hastigheden til XX MB/s.
Når datafilsiden skrives til disken af et kontrolpunkt, garanterer fremskrivningslogning, at alle logposter, der påvirker denne side, først skal skrives til transaktionsloggen på disken. Alle logposter til og med den sidste, der påvirkede siden, skrives ud, uanset hvilken transaktion de er en del af. Logposter skrives ud på tre måder:
- Når en transaktion begår eller afbrydes
- Når datafilsiden skrives til disken
- Når en logblok rammer den maksimale størrelse på 60 KB og tvangssluttet
Kontrolpostlogpost
Kontrolpunkter skriver flere logposter i transaktionsloggen:
- LOP_BEGIN_CKPT — angiver, at kontrolpunktet startede
- LOP_XACT_CKPT med NULL-kontekst (kun hvis der er ikke-forpligtede transaktioner på det tidspunkt, hvor kontrolpunktet startede) — indeholder en optælling af antallet af ikke-forpligtede transaktioner. Den viser også LSN'erne for LOP_BEGIN_XACT-logposterne for de ikke-forpligtede transaktioner.
- LOP_BEGIN_CKPT med en kontekst på LOP_BOOT_PAGE_CKPT (kun SQL Server 2012) — angiver, at startsiden er blevet opdateret.
- LOP_END_CKPT — angiver slutningen af kontrolpunktet.
Tjekpunktsovervågning
Det kan være nyttigt at korrelere kontrolpunkter, der forekommer med spidser i I/O, så der kan foretages ændringer i den specifikke database (for I/O-undersystemet) for at afhjælpe I/O-stigningen, hvis det overbelaster I/O-undersystemet. For eksempel at udføre hyppigere, manuelle kontrolpunkter eller konfigurere et lavere gendannelsesinterval på SQL Server 2012 med indirekte kontrolpunkter. Dette vil producere en mere konstant I/O-belastning uden høje spidser, der overbelaster I/O-undersystemet. Grundårsagen kan dog være, at der udføres mere I/O på grund af en ændring et eller andet sted, så du skal ikke bare acceptere en pludselig stigning i checkpoint-aktivitet uden at undersøge, hvorfor det opstod.
Buffer Manager/Checkpoint sider/sek tælleren er ikke databasespecifik, så identifikationen af hvilken database der er involveret kræver sporingsflag eller udvidede hændelser.
Sporingsflag 3502 skriver beskeder til fejlloggen om, hvilket databasekontrolpunkt der opstår for.
Sporingsflag 3504 skriver mere detaljeret information om, hvor mange sider der blev skrevet ud og den gennemsnitlige skriveforsinkelse.
Disse sporflag er sikre at bruge i produktionen til en begrænset kalk. Det eneste, de gør, er at udskrive meddelelser i fejlloggen.
Hvis du vil bruge udvidede begivenheder, er der to begivenheder, du kan bruge:checkpoint_begin og checkpoint_end.
Oversigt
I denne artikel har vi talt om kontrolpunkter i SQL Server - hovedmekanismen til at skrive datafilsider til disk, efter at de er blevet ændret.