SQL Server Transactional Replication er en af de mest almindelige replikeringsteknikker, der bruges til at kopiere eller distribuere data på tværs af flere destinationer.
I de tidligere artikler diskuterede vi SQL Server-replikering, hvordan det fungerer internt, og hvordan man konfigurerer replikering via Replication Wizard eller T-SQL-tilgangen. Nu fokuserer vi på SQL-replikeringsproblemer og fejlfinding af dem korrekt.
SQL-replikeringsproblemer
Størstedelen af kunder, der bruger SQL Server Transactional Replication, fokuserer hovedsageligt på at opnå nær-realtidsdata, der er tilgængelige i Subscriber-databasen. Derfor bør den DBA, der administrerer replikeringen, være opmærksom på forskellige mulige SQL-replikeringsrelaterede problemer, der kan opstå. Desuden skal DBA være i stand til at løse disse problemer inden for kort tid.
Vi kan kategorisere alle SQL-replikeringsproblemer i nedenstående kategorier (baseret på min erfaring):
Konfigurationsproblemer
- Maksimal tekstreplikeringsstørrelse
- SQL Server Agent Service er ikke indstillet til at starte automatisk tilstand
- Uovervågede replikeringsforekomster kommer i en ikke-initialiseret abonnementstilstand
- Kendte problemer i SQL Server
Tilladelser
- SQL Server Agent Jobtilladelse Problemer
- Snapshot Agent-joblegitimationsoplysninger kan ikke få adgang til Snapshot-mappestien
- Log Reader Agent-joblegitimationsoplysninger kan ikke oprette forbindelse til udgiver-/distributionsdatabase
- Distributionsagentjoblegitimationsoplysninger kan ikke oprette forbindelse til distributions-/abonnentdatabase
Forbindelsesproblemer
- Udgiverserver blev ikke fundet eller var ikke tilgængelig
- Distributionsserveren blev ikke fundet eller var ikke tilgængelig
- Abonnentserver blev ikke fundet eller var ikke tilgængelig
Problemer med dataintegritet
- Fejl ved overtrædelse af primær nøgle eller unik nøgle
- Række ikke fundet-fejl
- Fejl med fremmednøgle eller andre begrænsningsovertrædelser
Ydeevneproblemer
- Langevarende aktive transaktioner i udgiverdatabase
- Masse INSERT/UPDATE/DELETE operationer på artikler
- Enorme dataændringer inden for en enkelt transaktion
- Blokeringer i distributionsdatabasen
Korruptionsrelaterede problemer
- Korruption af udgiverdatabase
- Korruption af udgivertransaktionslogfil
- Korruption af distributionsdatabase
- Abonnentdatabasekorruption
DEMO-miljøforberedelse
Før vi dykker ned i detaljer om SQL-replikeringsproblemerne, skal vi forberede vores miljø til demoen. Som diskuteret i mine tidligere artikler, vil eventuelle dataændringer, der sker på abonnentdatabasen i Transactional Replication, ikke være synlige direkte for Publisher-databasen. Derfor vil vi foretage visse ændringer direkte i abonnentdatabasen til læringsformål.
Vær yderst forsigtig og modificer ikke noget i produktionsdatabaserne. Det vil påvirke abonnentdatabasernes dataintegritet. Jeg tager backup-scripts for hver ændring, der udføres og vil bruge disse scripts til at løse SQL-replikeringsproblemerne.
Ændring 1 – Indsættelse af poster i Person.ContactType-tabellen
Før du indsætter poster i Person.ContacType tabel, lad os se på den tabelstruktur, et par standardbegrænsninger og udvidede egenskaber redigeret i scriptet nedenfor:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Jeg har valgt denne tabel, da den har færre kolonner. Det er mere bekvemt til testformål. Lad os nu tjekke, hvad vi har om dens struktur:
- ContactTypeId er defineret som en IDENTITETSKOLONNE – den vil autogenerere de primære nøgleværdier og IKKE TIL REPLIKATION.
- IKKE TIL REPLIKATION er en speciel egenskab, der kan bruges på forskellige objekttyper såsom tabeller, begrænsninger som fremmednøglebegrænsninger, kontrolbegrænsninger, udløsere og identitetskolonner på enten udgiver eller abonnent, mens du kun bruger nogen af replikeringsmetoderne. Det lader DBA planlægge eller implementere replikering for at sikre, at visse funktionaliteter opfører sig anderledes i Publisher/Subscriber, mens du bruger replikering.
- I vores tilfælde instruerer vi SQL Server i at bruge IDENTITY-værdierne, der kun genereres på Publisher-databasen. Egenskaben IDENTITY bør ikke bruges på Person.ContactType tabel i abonnentdatabasen. På samme måde kan vi ændre begrænsningerne eller triggerne for at få dem til at opføre sig anderledes, mens replikering er konfigureret ved hjælp af denne mulighed.
- 2 andre IKKE NULL-kolonner er tilgængelige i tabellen.
- Tabellen har en primær nøgle defineret på ContactTypeId . Bare for at huske, den primære nøgle er et obligatorisk krav for replikering. Uden den på en tabel ville vi ikke være i stand til at replikere en tabelartikel.
Lad os nu INDSÆTTE en prøvepost til Person .Kontakttype tabellen i AdventureWorks_REPL database:
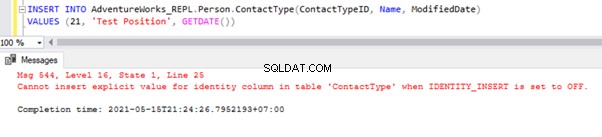
Den direkte INSERT på bordet vil mislykkes i abonnentdatabasen, fordi identitetsegenskaben kun er deaktiveret for replikering ved IKKE TIL REPLIKATION. Når vi udfører INSERT-handlingen manuelt, skal vi stadig bruge indstillingen SET IDENTITY_INSERT som denne:
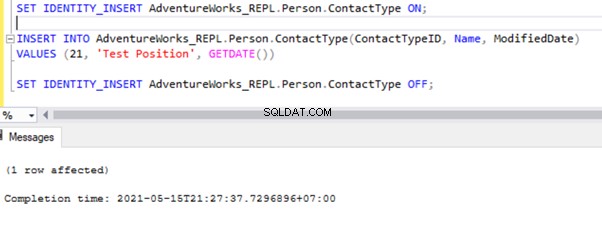
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Efter at have tilføjet indstillingen SET IDENTITY_INSERT, kan vi INSERT record med succes i Person.ContactType tabel.
Udførelse af SELECT på tabellen viser den nyligt indsatte post:
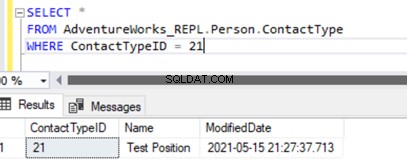
Vi har kun tilføjet en ny post til abonnentdatabasen, som ikke er tilgængelig i Publisher-databasen på Person.ContactType tabel.
Udførelse af en SELECT på den samme tabel i Publisher-databasen viser ingen poster. Ændringer i abonnentdatabasen replikeres således ikke til Publisher-databasen.
Ændring 2 – Sletning af 2 poster fra Person.ContactType-tabellen
Vi holder os til vores velkendte Person.ContactType bord. Før vi sletter poster fra abonnentdatabasen, skal vi kontrollere, om disse poster eksisterer på tværs af både udgiver og abonnent. Se nedenfor:
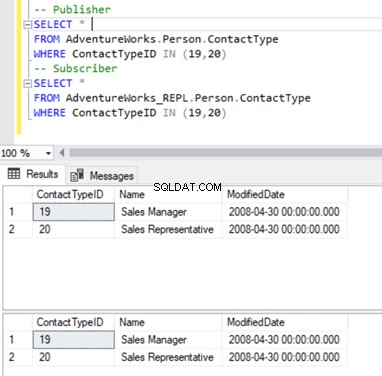
Nu kan vi slette disse 2 ContactTypeId ved hjælp af følgende sætning:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Ovenstående script lader os slette 2 poster fra Person.ContactType tabel i abonnentdatabasen:
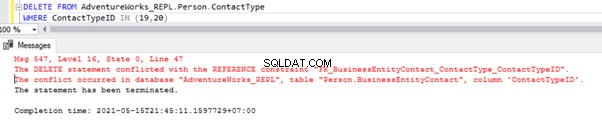
Vi har en udenlandsk nøglereference, der forhindrer sletning af disse 2 poster fra Person.ContactType bord. Vi kan håndtere dette scenarie ved midlertidigt at deaktivere Foreign key constraint på den underordnede tabel. Scriptet er nedenfor:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Når fremmednøglerne er deaktiveret, kan vi slette poster fra Person.ContactType tabel:
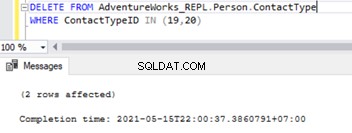
Dette har også ændret Foreign key Referential constraint på tværs af de 2 tabeller. Vi kan prøve at simulere SQL-replikeringsproblemer baseret på dette scenarie.
I vores nuværende scenarie ved vi, at Person.ContactType tabellen havde ikke synkroniserede data på tværs af udgiveren og abonnenten.
Tro mig, i få produktionsmiljøer laver udviklere eller DBA'er nogle datarettelser på abonnentdatabasen. ligesom alle ændringer, vi udførte tidligere, forårsagede dataintegritetsproblemerne på tværs af Publisher- og Subscriber-databaserne i samme tabel. Som DBA har jeg brug for en enklere mekanisme til at verificere den slags uoverensstemmelser. Ellers ville det gøre DBA’s liv patetisk.
Her kommer løsningen fra Microsoft, der giver os mulighed for at verificere data-uoverensstemmelserne på tværs af tabeller i Publisher og Abonnenten. Ja, du gættede rigtigt. Det er TableDiff-værktøjet, som vi diskuterede i tidligere artikler.
TableDiff Utility
TableDiff-værktøjet bruges primært i replikeringsmiljøer. Vi kan også bruge det til andre tilfælde, hvor vi skal sammenligne 2 SQL Server-tabeller for ikke-konvergens. Vi kan sammenligne dem og identificere forskellene mellem disse 2 tabeller. Så hjælper værktøjet med at synkronisere destinationen tabel til Kilden tabel ved at generere nødvendige INSERT/UPDATE/DELETE scripts.
TableDiff er et selvstændigt program tablediff.exe installeret som standard på C:\Program Files\Microsoft SQL Server\130\COM, når vi har installeret replikeringskomponenterne. Bemærk venligst, at standardstien kan variere afhængigt af SQL Server-installationsparametrene. Tallet 130 i stien angiver SQL Server-versionen (SQL Server 2016). Derfor vil det variere for hver anden version af SQL Server-installationen.
Du kan kun få adgang til TableDiff-værktøjet via kommandoprompt eller fra batchfiler. Værktøjet har ikke en fancy Wizard eller GUI at bruge. Den detaljerede syntaks for TableDiff-værktøjet er i MSDN-artiklen. Vores nuværende artikel fokuserer kun på nogle nødvendige muligheder.
For at sammenligne 2 tabeller ved hjælp af TableDiff-værktøjet skal vi angive obligatoriske detaljer for kilde- og destinationstabellerne, såsom kildeservernavn, kildedatabasenavn, kildeskemanavn, kildetabelnavn, destinationsservernavn, destinationsdatabasenavn, destination Skemanavn og destinationstabelnavn.
Lad os prøve at teste TableDiff med Person.ContactType tabel med forskelle på tværs af udgiveren og abonnenten.
Åbn kommandoprompten, og naviger til TableDiff-værktøjsstien (hvis stien ikke er tilføjet til miljøvariablerne).
For at se listen over alle tilgængelige parametre skal du skrive kommandoen "tablediff-?" for at liste alle tilgængelige muligheder og parametre. Resultaterne er nedenfor:
Lad os tjekke personen.ContactType tabel på tværs af vores udgiver- og abonnentdatabaser ved at køre nedenstående kommando:
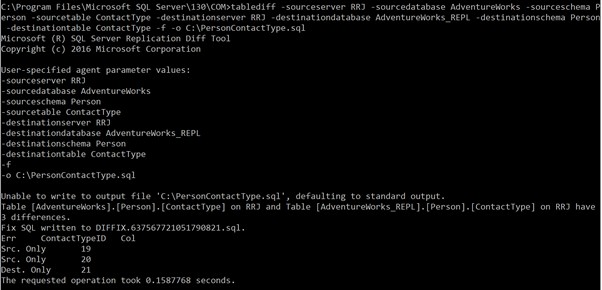
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeBemærk, at jeg ikke har angivet kildebrugeren , kildeadgangskode , destinationuser , og destinationpassword da mit Windows-login har adgang til tabellerne. Hvis du ønsker at bruge SQL-legitimationsoplysninger i stedet for Windows-godkendelse, er ovenstående parametre obligatoriske for at få adgang til tabellerne til sammenligning . Ellers vil du modtage fejl.
Resultaterne af den korrekte kommandoudførelse:
Det viser, at vi har 3 uoverensstemmelser. Den ene er en ny post i destinationsdatabasen, og to poster er ikke tilgængelige i destinationsdatabasen.
Lad os nu tage et hurtigt kig på Diverse tilgængelige muligheder for TableDiff-værktøjet.
- -et – logger resultatoversigten til destinationstabellen
- -dt – sletter resultatdestinationstabellen, hvis den allerede eksisterer
- -f – genererer et T-SQL DML-script med INSERT/UPDATE/DELETE-sætninger for at bringe destinationstabellen til at konvergere med kildetabellen.
- -o – output filnavn hvis mulighed -f bruges til at generere konvergensfilen.
Vi opretter en konvergensfil med -f og -o muligheder til vores tidligere kommando:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlKonvergensfilen er oprettet med succes:
Som du kan se, er oprettelsen af en ny fil i rodmappen på C:-drevet ikke tilladt af sikkerhedsmæssige årsager. Derfor viser den en fejlmeddelelse og opretter outputfilen DIFFIX.*.sql-fil i hjælpemappen TableDiff. Når vi åbner den fil, kan vi se nedenstående detaljer:

INSERT-scripts blev oprettet for de 2 slettede poster, og DELETE-scripts blev oprettet for poster, der for nylig blev indsat i Subscriber-databasen. Værktøjet bekymrer sig også om at bruge IDENTITY_INSERT-indstillingerne efter behov for Destinationen bord. Derfor vil dette værktøj være til stor nytte, når en DBA skal synkronisere to tabeller.
I vores tilfælde vil jeg ikke udføre scripts, da vi har brug for disse afvigelser for at simulere vores SQL-replikeringsproblemer.
Fordele ved TableDiff Utility
- TableDiff er et gratis værktøj, der kommer som en del af installationen af SQL Server-replikeringskomponenter, der skal bruges til tabelsammenligning eller konvergens.
- Scripts til oprettelse af konvergens kan oprettes uden manuel indgriben.
Begrænsninger af TableDiff Utility
- TableDiff-værktøjet kan kun udføres fra kommandoprompten eller batchfilen.
- Fra kommandoprompten kan du kun udføre én tabelsammenligning ad gangen, medmindre du har flere kommandoprompter åbne parallelt for at sammenligne flere tabeller.
- Kildetabellen, som du skal sammenligne ved hjælp af TableDiff-værktøjet, kræver enten en Primary Key eller en Identity-kolonne defineret, eller ROWGUID-kolonnen, der er tilgængelig for at udføre række-for-række-sammenligningen. Hvis -streng bruges, kræver Destinationstabellen også en Primær nøgle eller en Identitetskolonne eller ROWGUID kolonnen tilgængelig.
- Hvis kilde- eller destinationstabellen indeholder sql_variant datatype-kolonnen, kan du ikke bruge TableDiff-værktøjet til at sammenligne det.
- Ydeevneproblemer kan bemærkes, mens du udfører TableDiff-værktøjet på tabeller, der indeholder enorme poster, da det vil udføre række-for-række-sammenligning på disse tabeller.
- Konvergensscripts oprettet af TableDiff-værktøjet inkluderer ikke BLOB-tegndatatypekolonnerne, såsom varchar(max) , nvarchar(max) , varbinary(max) , tekst , ntekst eller billede kolonner og xml eller tidsstempel kolonner. Derfor har du brug for alternative metoder til at håndtere tabellerne med disse datatypekolonner.
Men selv med disse begrænsninger kan TableDiff-værktøjet bruges på tværs af enhver SQL Server-tabel til hurtig dataverifikation eller konvergenstjek. Du kan dog også købe et godt tredjepartsværktøj.
Lad os nu overveje de forskellige SQL-replikeringsproblemer i detaljer.
Konfigurationsproblemer
Ud fra min erfaring har jeg kategoriseret de ofte savnede replikeringskonfigurationsindstillinger, der kan føre til kritiske SQL-replikeringsproblemer som Konfiguration problemer. Nogle af dem er nedenfor.
Maksimal tekstreplikeringsstørrelse
Maks. tekstrepl.størrelse henviser til Maksimal tekstreplikeringsstørrelse i bytes . Det gælder for alle datatyper som char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, og billede .
SQL Server har en standardindstilling til at begrænse den maksimale strengdatatypekolonnelængde (i bytes), der skal replikeres som 65536 bytes.
Vi er nødt til at evaluere Max Text Repl Size omhyggeligt, når replikering er konfigureret til en database. Til det skal vi kontrollere alle ovenstående datatypekolonner og identificere de maksimalt mulige bytes, der vil blive overført via replikering.
Ændring af værdien til -1 indikerer, at der ikke er nogen grænser. Vi anbefaler dog, at du evaluerer den maksimale strenglængde og konfigurerer denne værdi.
Vi kan konfigurere Max Text Repl Size ved hjælp af SSMS eller T-SQL.
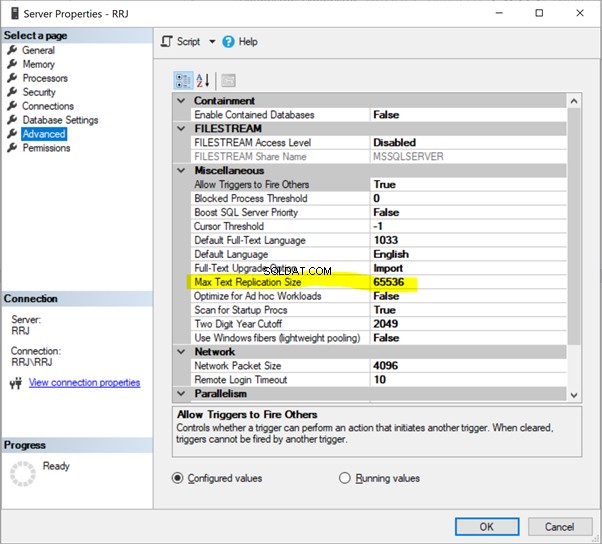
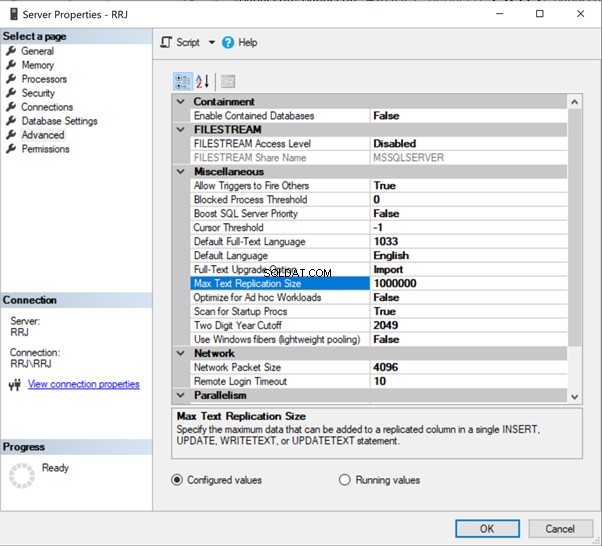
I SSMS skal du højreklikke på servernavnet> Egenskaber > Avanceret :
Bare klik på 65536 at ændre det. Til test har jeg ændret 65536 til 1000000 og klikket på OK :
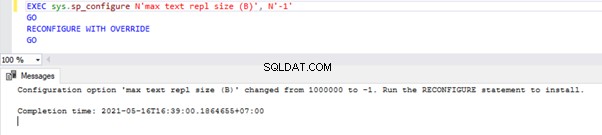
For at konfigurere indstillingen Max Text Repl Size via T-SQL skal du åbne et nyt forespørgselsvindue og udføre nedenstående script mod masterdatabasen:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Denne forespørgsel vil tillade, at Replikering ikke begrænser størrelsen af ovenstående datatypekolonner.
For at verificere kan vi udføre et SELECT på sys.configurations DMV og tjek værdi_i_brug kolonne som nedenfor:

SQL Server Agent Service ikke indstillet til at starte automatisk tilstand
Replikering er afhængig af replikeringsagenter, der udføres som SQL Server Agent-job. Derfor vil ethvert problem med nogle SQL Server Agent-tjenester have en direkte indvirkning på replikeringsfunktionaliteten.
Vi skal sikre os, at starttilstanden for SQL Server og SQL Server Agent Services er indstillet til Automatisk. Hvis indstillet til Manuel, bør vi konfigurere nogle advarsler. De ville give DBA eller serveradministratorer besked om at starte SQL Server Agent Service, når serveren genstarter enten planlagte eller uplanlagte.
Hvis det ikke er gjort, kører replikeringen muligvis ikke i lang tid, hvilket også påvirker andre SQL Server Agent-job.
Uovervågede replikeringsforekomster kommer ind i en ikke-initialiseret abonnementstilstand
I lighed med overvågning af SQL Server Agent Service, spiller konfiguration af Database Mail Service i enhver SQL Server-instans en afgørende rolle i at advare DBA eller den person, der er konfigureret rettidigt. For alle jobfejl eller problemer kan SQL Server Agent-job som Log Reader Agent eller Distribution Agent konfigureres til at sende advarsler til DBA eller det respektive teammedlem via e-mail. Fejl ved udførelse af Replication Agent-job kan føre til følgende scenarier:
Ikke-udførelse af Log Reader Agent Job . Transaktionslogfilen i Publisher-databasen genbruges kun efter kommandoen markeret til replikering læses af Log Reader Agent og sendes til distributionsdatabasen. Ellers er log_reuse_wait_desc kolonne af sys.databases vil vise værdien som replikering, hvilket indikerer, at databaseloggen ikke kan genbruges, før den overfører ændringer til distributionsdatabasen. Derfor vil manglende eksekvering af Log Reader-agenten blive ved med at øge størrelsen af Transactional Log-filen i Publisher-databasen, og vi vil støde på ydeevneproblemer under den fulde sikkerhedskopiering eller problemer med diskplads på Publisher-databaseforekomsten.
Ikke-udførelse af distributionsagentjob. Distributionsagent-jobbet læser dataene fra distributionsdatabasen og sender dem til abonnentdatabasen. Derefter markerer den disse poster til sletning i distributionsdatabasen. Hvis distributionsagentjobbet ikke udføres, vil det øge størrelsen af distributionsdatabasen, hvilket forårsager ydeevneproblemer til den overordnede replikeringsydeevne. Som standard er distributionsdatabasen konfigureret til at holde poster i maksimalt 0-72 timer som vist i egenskaben Transaktionsbevarelse nedenfor. Hvis replikeringen mislykkes i mere end 72 timer, vil det tilsvarende abonnement blive markeret som ikke-initialiseret, hvilket tvinger os til enten at omkonfigurere abonnementet eller generere et nyt snapshot for at få replikeringen til at fungere igen.
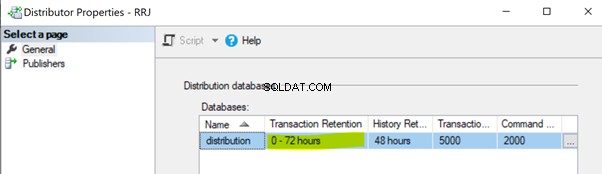
Ikke-udførelse af distributionsoprydning:distributionsjob . Distributionsoprydningsjobbet er ansvarligt for at slette alle replikerede poster fra distributionsdatabasen for at holde distributionsdatabasens størrelse under kontrol. Manglende udførelse af dette job fører til en øget størrelse af distributionsdatabasen, hvilket resulterer i problemer med replikeringsydelse.
For at sikre, at vi ikke lander på tværs af nogen af disse uovervågede problemer, bør Database Mail konfigureres til at rapportere alle jobfejl eller genforsøg til de respektive teammedlemmer for hurtig handling.
Kendte problemer i SQL Server
Visse SQL Server-versioner havde kendte replikeringsproblemer i RTM-versionen eller tidligere versioner. Disse problemer blev rettet i de efterfølgende servicepakker eller CU-pakker. Derfor anbefales det at anvende de nyeste servicepakker eller CU-pakker, når de er tilgængelige for alle SQL Server efter at have testet dem i QA-miljøet. Selvom dette er en generel anbefaling til servere, der kører SQL Server, gælder den også for replikering.
Tilladelser
I et miljø med SQL Server Transactional Replication konfigureret, kan vi observere tilladelsesproblemerne ofte. Vi kan møde dem under replikeringskonfigurationen eller enhver vedligeholdelsesaktivitet på udgiveren, distributøren eller abonnentdatabasen. Det resulterer i mistede legitimationsoplysninger eller tilladelser. Lad os nu observere nogle hyppige tilladelsesproblemer relateret til replikering.
SQL Server Agent Jobtilladelsesproblemer
Alle replikeringsagenter bruger SQL Server Agent-job. Hvert SQL Server Agent-job relateret til Snapshot eller Log Reader Agent eller Distribution udføres under nogle Windows- eller SQL Login-legitimationsoplysninger som vist nedenfor:
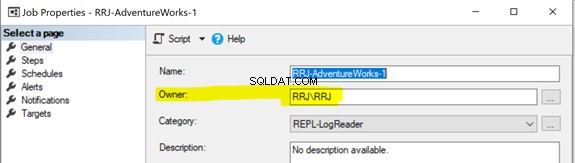
For at starte et SQL Server Agent-job skal du have enten SQLAgentOperatorRole for at starte alle job eller enten SQLAgentUserRole eller SQLAgentReaderRole at starte job, som du ejer. Hvis et job ikke kunne starte korrekt, skal du kontrollere, om jobejeren har de nødvendige rettigheder til at udføre jobbet.
Snapshot Agent Job-legitimationsoplysninger kan ikke få adgang til Snapshot-mappestien
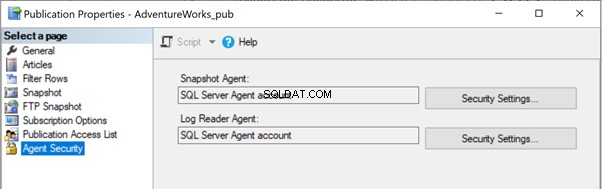
I vores tidligere artikler bemærkede vi, at Snapshot-agentens udførelse ville skabe et øjebliksbillede af artiklerne i enten lokal eller delt mappesti for at blive udbredt til abonnentdatabasen via distributionsagenten. Snapshot-stiens placering kan identificeres under Publikationsegenskaber > Snapshot :
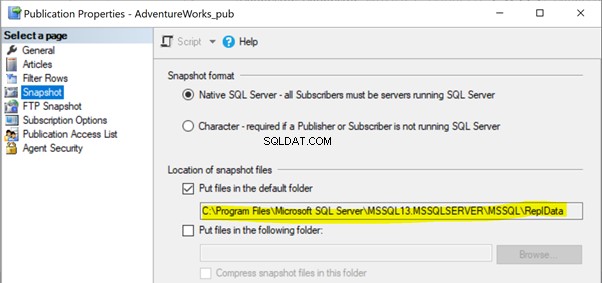
Hvis Snapshot-agenten ikke har adgang til denne Snapshot-filplacering, kan vi modtage fejlen:
Adgang til stien 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\ÅÅÅÅMMDDHHMISS\' nægtes.
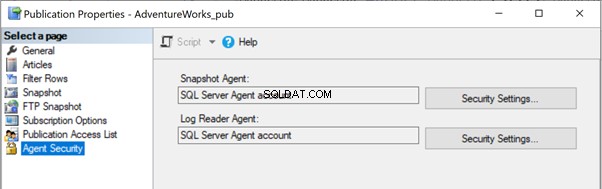
For at løse problemet er det bedre at give fuldstændig adgang til mappestien C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ for den konto, som Snapshot Agent udfører under. I vores konfiguration bruger vi SQL Server Agent-kontoen, og SQL Server Agent-tjenesten kører under RRJ\RRJ-kontoen.
Loglæseragent-joblegitimationsoplysningerne kan ikke oprette forbindelse til udgiver-/distributionsdatabase
Log Reader Agent opretter forbindelse til Publisher-databasen for at udføre sp_replcmds procedure for at scanne efter de transaktioner, der er markeret til replikering fra udgiverdatabasens transaktionslogfiler.
Hvis databaseejeren af Publisher-databasen ikke er indstillet korrekt, kan vi muligvis modtage følgende fejl:
Processen kunne ikke udføre 'sp_replcmds' på 'RRJ.
Eller
Kan ikke udføres som databaseprincipal, fordi principal "dbo" ikke eksisterer, denne type principal kan ikke efterlignes, eller du ikke har tilladelse.
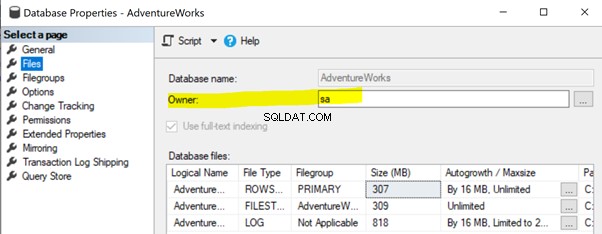
For at løse dette problem skal du sørge for, at databaseejer-egenskaben for Publisher-databasen er indstillet til sa eller en anden gyldig konto (se nedenfor).
Højreklik på Udgiveren database (AdventureWorks )> Egenskaber > Filer . Sørg for, at Ejer feltet er sat til sa eller et gyldigt login og ikke tomt .
Hvis der opstår problemer med tilladelser, når vi opretter forbindelse til udgiver- eller distributionsdatabasen, skal du kontrollere de legitimationsoplysninger, der bruges til Log Reader Agent, og give dem tilladelse til at få adgang til disse databaser.
Distributionsagentjoblegitimationen kan ikke oprette forbindelse til distributions-/abonnentdatabasen
Distributionsagenten kan have tilladelsesproblemer, hvis kontoen ikke har tilladelse til at få adgang til distributionsdatabasen eller oprette forbindelse til abonnentdatabasen. I dette tilfælde kan vi få følgende fejl:
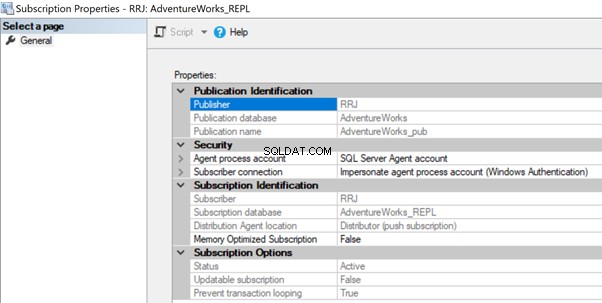
Kan ikke starte udførelse af trin 2 (årsag:Fejl ved godkendelse af proxy RRJ\RRJ, systemfejl:Brugernavnet eller adgangskoden er forkert.)
Processen kunne ikke oprette forbindelse til abonnent 'RRJ.
Login mislykkedes for brugeren 'RRJ\RRJ'.
For at løse det skal du kontrollere kontoen, der bruges i abonnementsegenskaberne og sikre, at den har de nødvendige tilladelser til at oprette forbindelse til distributions- eller abonnentdatabasen.
Forbindelsesproblemer
Vi konfigurerer normalt Transaktionsreplikeringen på tværs af servere inden for det samme netværk eller på tværs af geografisk distribuerede lokationer. Hvis distributionsdatabasen er placeret på en dedikeret server bortset fra udgiveren eller abonnenten, bliver den modtagelig for netværkspakketab – forbindelsesproblemer.
I tilfælde af sådanne problemer kan replikeringsagenter (loglæser eller distributionsagent) rapportere nedenstående fejl:
Udgiverserver blev ikke fundet eller var ikke tilgængelig
Distributionsserveren blev ikke fundet eller var ikke tilgængelig
Abonnentserver blev ikke fundet eller var ikke tilgængelig
For at fejlfinde disse problemer kan vi prøve at oprette forbindelse til udgiveren, distributøren eller abonnentdatabasen i SSMS for at kontrollere, om vi er i stand til at oprette forbindelse til disse SQL Server-instanser uden problemer eller ej.
Hvis der ofte opstår forbindelsesproblemer, kan vi prøve at pinge serveren løbende for at identificere eventuelle pakketab. Vi er også nødt til at arbejde med de nødvendige teammedlemmer for at løse disse problemer og få serveren op at køre, så replikering kan genoptage overførsel af data.
Problemer med dataintegritet
Da transaktionsreplikering er en envejsmekanisme, vil eventuelle dataændringer, der sker på abonnenten (manuelt eller fra applikationen), ikke blive afspejlet på udgiveren. Det kan føre til dataafvigelser på tværs af udgiveren og abonnenten.
Lad os gennemgå disse problemer relateret til dataintegritet og se, hvordan du løser dem. Bemærk, at vi har indsat en post i Person.ContactType tabel og slettede 2 poster fra Person.ContactType tabel i abonnentdatabasen. Vi skal bruge disse 3 poster til at finde fejl.
Den primære nøgle eller Unique Key Violation-fejl
Jeg vil teste INSERT-posten på Person.ContactType bord. Lad os indsætte den post i Publisher-databasen og se, hvad der sker:
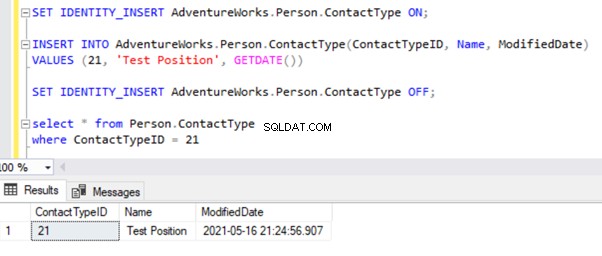
Start replikeringsmonitoren for at se, hvordan det går. Vi får fejlen:
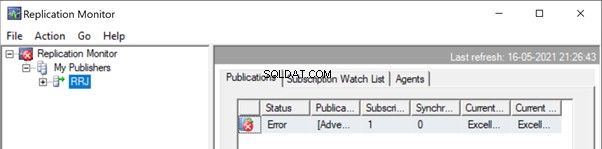
Udvider Udgiver og Publikation , får vi følgende detaljer:
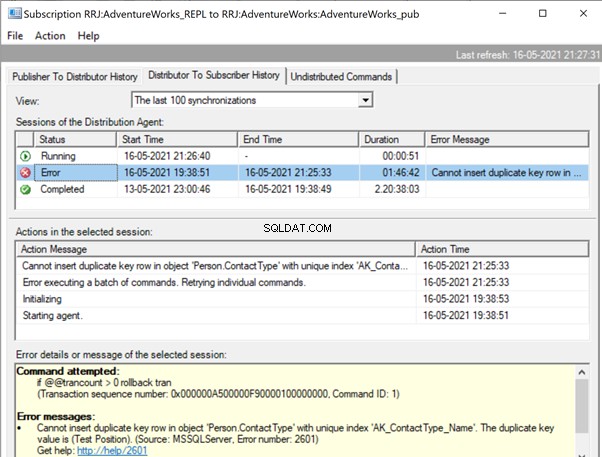
Hvis vi har konfigureret replikeringsadvarslerne og tildelt respektive personer til at modtage deres e-mailbesked, vil vi modtage passende e-mailmeddelelser med fejlmeddelelsen:Kan ikke indsætte en dublet nøglerække i objektet 'Person.ContactType' med det unikke indeks 'AK_ContactType_Name' ' . Duplikatnøgleværdien er (Testposition). (Kilde:MSSQLServer, fejlnummer:2601)
For at løse problemet vedrørende unikke nøgleovertrædelser eller primære nøgleproblemer har vi flere muligheder:
- Analyser, hvorfor denne fejl er sket, hvordan posten var tilgængelig i abonnentdatabasen, og hvem der indsatte den af hvilke årsager. Identificer, om det var nødvendigt eller ej.
- Tilføj springfejlene parameter til distributionsagentprofilen for at springe Fejlnummer 2601 over eller Fejlnummer 2627 i tilfælde af overtrædelse af den primære nøgle.
I vores tilfælde har vi målrettet indsat data for at modtage denne fejl. For at håndtere dette problem skal du slette den manuelt indsatte post for at fortsætte med at replikere ændringer modtaget fra udgiveren.
DELETE from Person.ContactType
where ContactTypeID = 21
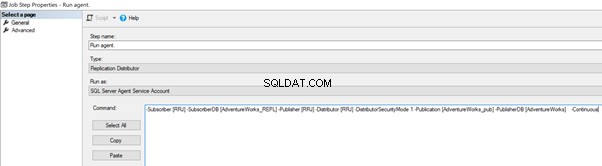
For at studere andre muligheder og sammenligne forskellene mellem disse to tilgange springer jeg den første mulighed over (som er effektiv og anbefalet) og fortsætter til den anden mulighed ved at tilføje -skiperrors parameter til distributionsagentjobbet.
Vi kan implementere det ved at redigere Distribution Agent Job > Trin > klik på 2 jobtrin med navnet Kør agent > klik på Rediger for at se den tilgængelige kommando:
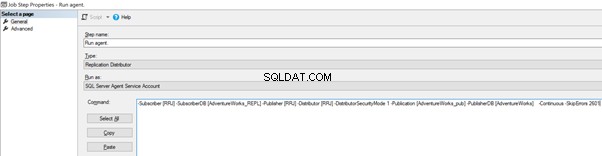
Tilføj nu -SkipErrors 2601 søgeord til sidst (2601 er fejlnummeret – vi kan springe ethvert fejlnummer over, der modtages som en del af replikering), og klik på OK .
For at sikre, at distributionsjobbet er opmærksom på denne konfigurationsændring, skal vi genstarte distributionsagentjobbet. For det skal du stoppe det og starte igen fra trin 1 som vist nedenfor:
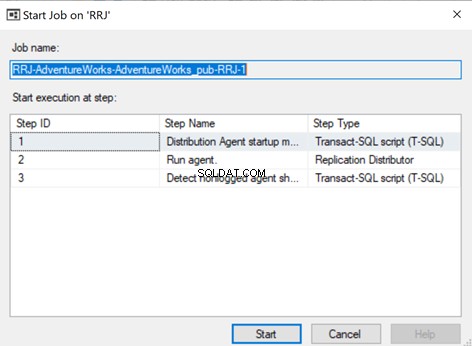
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
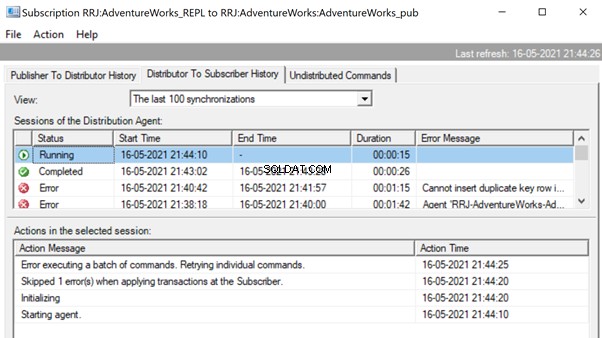
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
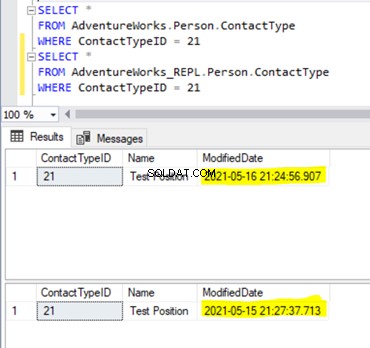
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors kommando.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
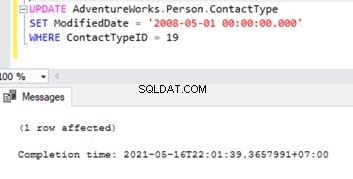
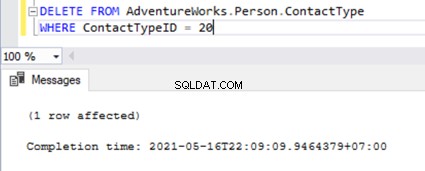
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
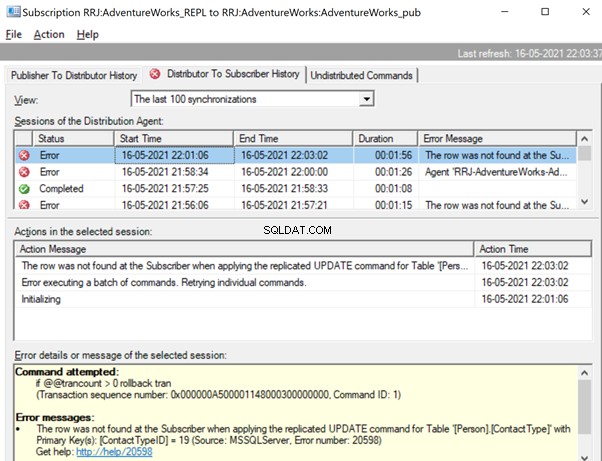
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors mulighed. Instead, we’ll apply the INSERT approach.
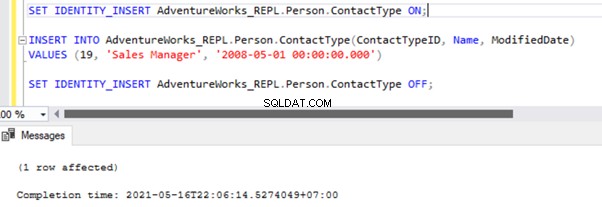
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
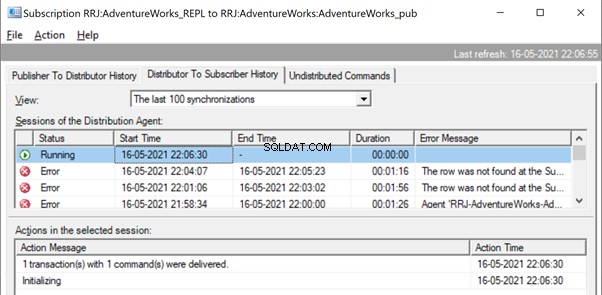
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
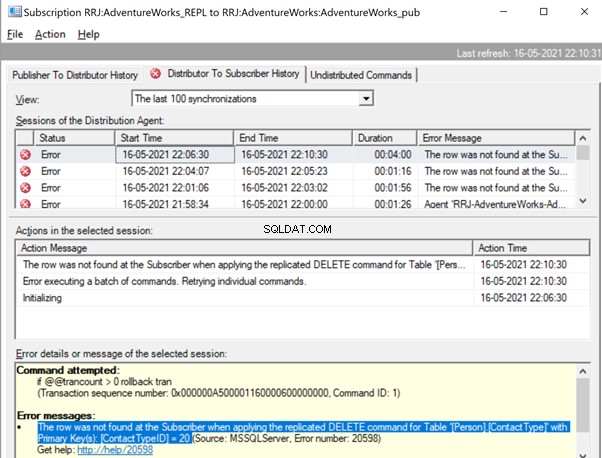
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Konklusion
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.