Relationelle databaser repræsenterer en organisations data i tabeller, der bruger kolonner med forskellige datatyper, så de kan gemme gyldige værdier. Udviklere og DBA'er har brug for at kende og forstå den passende datatype for hver kolonne for bedre forespørgselsydeevne.
Denne artikel vil omhandle de populære datatyper VARCHAR() og NVARCHAR(), deres sammenligning og ydelsesanmeldelser i SQL Server.
VARCHAR [ ( n | maks. ) ] i SQL
VARCHAR datatypen repræsenterer ikke-Unicode streng datatype med variabel længde. Du kan gemme bogstaver, tal og specialtegn i den.
- N repræsenterer strengstørrelse i bytes.
- VARCHAR-datatypekolonnen gemmer maksimalt 8000 ikke-Unicode-tegn.
- VARCHAR-datatypen tager 1 byte pr. tegn. Hvis du ikke udtrykkeligt angiver værdien for N, tager det 1-byte lagerplads.
Bemærk:Du må ikke forveksle N med en værdi, der repræsenterer antallet af tegn i en streng.
Følgende forespørgsel definerer VARCHAR-datatypen med 100 bytes data.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Det returnerer længden som 17 på grund af 1 byte pr. tegn, inklusive et mellemrumstegn.
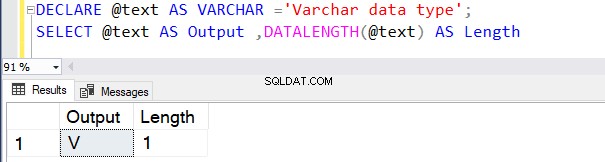
Følgende forespørgsel definerer VARCHAR-datatypen uden nogen værdi på N . Derfor betragter SQL Server standardværdien som 1 byte, som vist nedenfor.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
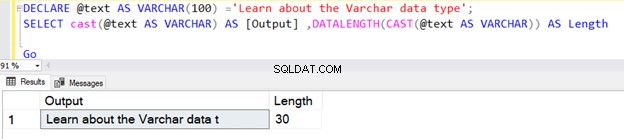
Vi kan også bruge VARCHAR ved at bruge CAST- eller CONVERT-funktionen. I de to eksempler nedenfor erklærede vi f.eks. en variabel med en længde på 100 bytes og brugte senere CAST-operatoren.
Den første forespørgsel returnerer længden som 30, fordi vi ikke har angivet N i CAST-operatoren VARCHAR-datatypen. Standardlængden er 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Men hvis strengens længde er mindre end 30, tager den den faktiske størrelse af strengen.

NVARCHAR [ ( n | maks. ) ] i SQL
NVARCHAR datatypen er for Unicode karakterdatatype med variabel længde. Her refererer N til National Language Character Set og bruges til at definere Unicode-strengen. Du kan gemme både ikke-Unicode- og Unicode-tegn (japansk Kanji, koreansk Hangul osv.).
- N repræsenterer strengstørrelse i bytes.
- Den kan maksimalt gemme 4000 Unicode- og Ikke-Unicode-tegn.
- VARCHAR-datatypen tager 2 bytes pr. tegn. Det tager 2 bytes lagerplads, hvis du ikke angiver nogen værdi for N.
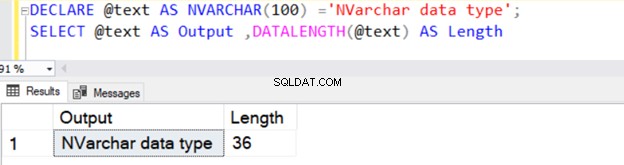
Følgende forespørgsel definerer VARCHAR-datatypen med 100 bytes data.
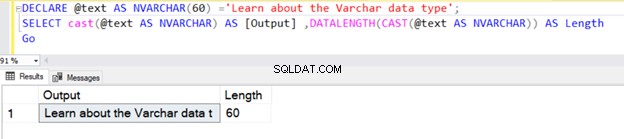
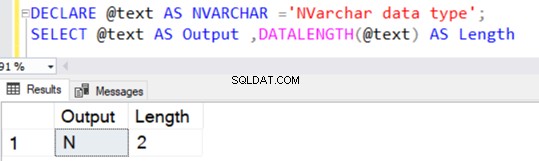
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Det returnerer strenglængden på 36, fordi NVARCHAR tager 2 bytes pr. tegnlager.
I lighed med VARCHAR-datatypen har NVARCHAR også en standardværdi på 1 tegn (2 bytes) uden at angive en eksplicit værdi for N.
Hvis vi anvender NVARCHAR-konverteringen ved hjælp af CAST- eller CONVERT-funktionen uden nogen eksplicit værdi af N, er standardværdien 30 tegn, dvs. 60 bytes.
Lagring af Unicode- og ikke-Unicode-værdier i VARCHAR-datatype
Antag, at vi har en tabel, der registrerer kundefeedback fra en e-shopping-portal. Til dette formål har vi en SQL-tabel med følgende forespørgsel.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
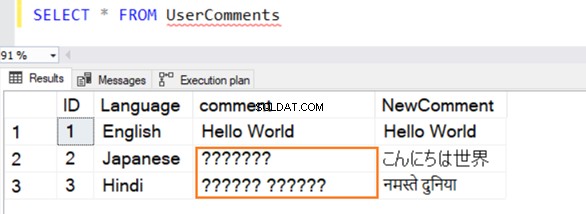
Vi indsætter flere eksempler på poster i denne tabel på engelsk, japansk og hindi. Datatypen for [Kommentar] er VARCHAR og [Nykommentar] er NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
Forespørgslen udføres med succes, og den giver følgende rækker, mens du vælger en værdi fra den. For række 2 og 3 genkender den ikke data, hvis den ikke er på engelsk.
VARCHAR- og NVARCHAR-datatyper:Præstationssammenligning
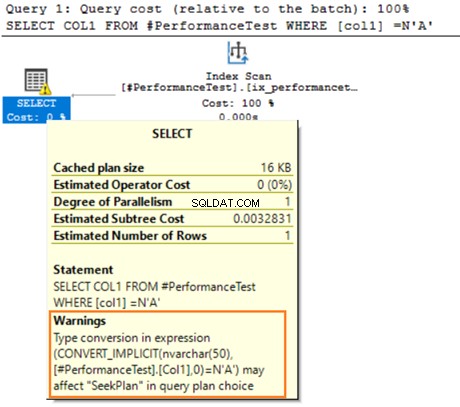
Vi bør ikke blande brugen af VARCHAR- og NVARCHAR-datatyper i JOIN- eller WHERE-prædikaterne. Det ugyldiggør de eksisterende indekser, fordi SQL Server kræver de samme datatyper på begge sider af JOIN. SQL Server forsøger at udføre den implicitte konvertering ved hjælp af funktionen CONVERT_IMPLICIT() i tilfælde af uoverensstemmelse.
SQL Server bruger datatypeprioriteten til at bestemme, hvilken måldatatypen er. NVARCHAR har højere forrang end VARCHAR-datatypen. Derfor konverterer SQL Server under datatypekonverteringen de eksisterende VARCHAR-værdier til NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Lad os nu udføre to SELECT-sætninger, der henter poster i henhold til deres datatyper.
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Begge forespørgsler bruger indekssøgeoperatoren og de indekser, vi definerede tidligere.
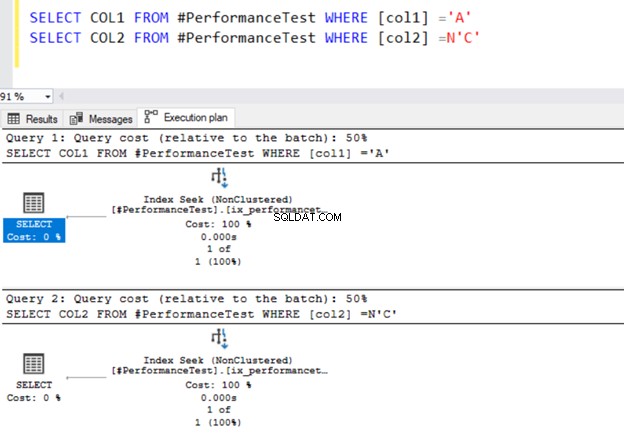
Nu skifter vi datatypeværdierne til sammenligning med WHERE-prædikatet. Kolonne 1 har en VARCHAR-datatype, men vi angiver N'A' for at sætte den som NVARCHAR-datatype.
På samme måde er col2 NVARCHAR-datatypen, og vi angiver værdien 'C', der refererer til VARCHAR-datatypen.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'I den faktiske udførelsesplan for forespørgslen får du en indeksscanning, og SELECT-sætningen har et advarselssymbol.
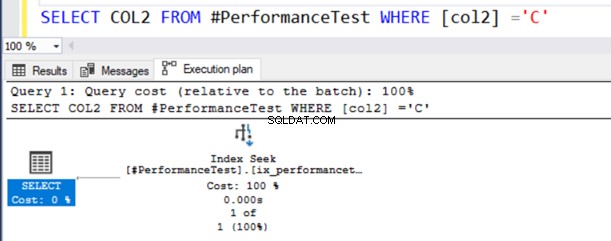
Denne forespørgsel fungerer fint, fordi NVARCHAR()-datatypen kan have både Unicode- og ikke-Unicode-værdier.
Nu bruger den anden forespørgsel en indeksscanning og udsteder et advarselssymbol på SELECT-operatøren.
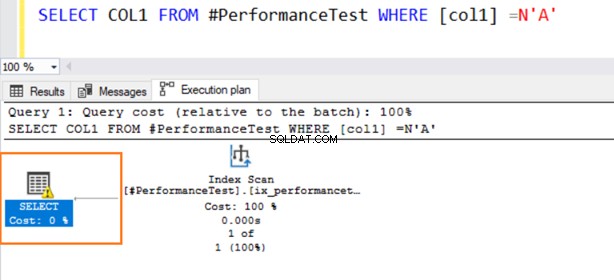
Hold musen over SELECT-sætningen, der udsender en advarsel om den implicitte konvertering. SQL Server kunne ikke bruge det eksisterende indeks korrekt. Det skyldes de forskellige datasorteringsalgoritmer for både VARCHAR og NVARCHAR datatyper.
Hvis tabellen har millioner af rækker, skal SQL Server udføre yderligere arbejde og konvertere data ved hjælp af datakonvertering implicit. Det kan påvirke din forespørgsels ydeevne negativt. Derfor bør du undgå at blande og matche disse datatyper ved optimering af forespørgslerne.
Konklusion
Du bør gennemgå dine datakrav, mens du designer databasetabeller og deres kolonnedatatype korrekt. Normalt leverer VARCHAR datatypeservere de fleste af dine datakrav. Men hvis du har brug for at gemme både Unicode og ikke-Unicode datatyper i en kolonne, kan du overveje at bruge NVARCHAR. Du bør dog gennemgå dens præstationsimplikation, lagerstørrelse, før du træffer den endelige beslutning.