Hvad er forespørgselsoptimering i SQL Server? Det er et stort emne. Hver teknik eller problem har brug for en separat artikel til at dække baserne. Men når du lige er begyndt at opgradere dit spil med forespørgsler, har du brug for noget, der er enklere at stole på. Dette er målet med denne artikel.
Du kan sige, at dine forespørgsler er optimale, alt fungerer godt, og brugerne er glade. Selvfølgelig er ydeevne ikke alt. Resultaterne skal også være korrekte. Uanset om det er en joinforbindelse, en underforespørgsel, et synonym, en CTE, en visning eller hvad som helst, skal den fungere acceptabelt.
Og sidst på dagen kan du tage hjem med dine brugere. Du ønsker ikke at blive på kontoret og løse de langsomt kørende forespørgsler natten over.
Inden vi begynder, lad mig forsikre dig om, at rejsen ikke bliver hård. Dette vil kun være en primer. Vi har eksempler, der ikke også vil være fremmede for dig. Til sidst, når du er klar til en dybere undersøgelse, vil vi præsentere nogle links, du kan tjekke ud.
Lad os begynde.
1. SQL-forespørgselsoptimering starter fra design og arkitektur
Overrasket? SQL-forespørgselsoptimering er ikke en eftertanke eller et plaster, når noget går i stykker. Din forespørgsel kører så hurtigt, som dit design tillader. Vi taler om normaliserede tabeller, de rigtige datatyper, brugen af indekser, arkivering af gamle data og enhver af de bedste fremgangsmåder, du kan komme i tanke om.
Et godt databasedesign fungerer i synergi med den rigtige hardware og SQL Server-indstillinger. Har du designet den til at køre problemfrit i flere år og stadig føles ny? Det er en stor drøm, men vi har kun en vis (normalt - kort) tid til at tænke over det.
Det vil ikke være perfekt på dag 1 i produktionen, men vi burde have dækket baserne. Vi minimerer teknisk gæld. Hvis du arbejder med et team, er det fantastisk sammenlignet med et one-man show. Du kan dække meget af klokkerne og fløjten.
Men hvad nu hvis databasen kører live, og du rammer ydeevnevæggen? Her er nogle tips og tricks til optimering af SQL-forespørgsler.
2. Find problematiske forespørgsler med SQL Server Standard Report
Når du koder, er det nemt at få øje på en lang række kode eller en lagret procedure. Du kan fejlsøge det linje for linje. Linjen, der halter, er den, der skal rettes.
Men hvad nu hvis din helpdesk smed et dusin af billetter, fordi det er langsomt? Brugere kan ikke lokalisere den nøjagtige placering i koden, og det kan helpdesk heller ikke. Tiden er din værste fjende.
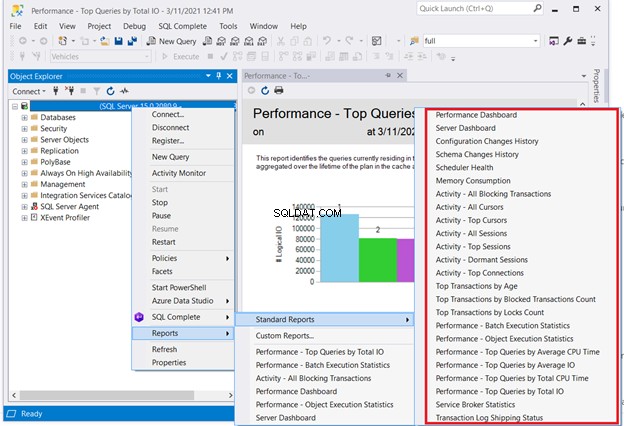
En løsning, der ikke kræver kodning, er at tjekke SQL Serverens standardrapporter. Højreklik på den nødvendige server i SQL Server Management Studio> Rapporter> Standardrapporter . Vores interessepunkt kan være Performance Dashboard eller Ydeevne – Topforespørgsler efter samlet I/O . Vælg den første forespørgsel, der klarer sig dårligt. Start derefter SQL-forespørgselsoptimeringen eller SQL-ydeevnejusteringen derfra.
3. SQL Query Tuning med STATISTICS IO
Efter at have lokaliseret den pågældende forespørgsel, kan du begynde at kontrollere logiske læsninger i STATISTICS IO. Dette er et af SQL-forespørgselsoptimeringsværktøjerne.
Der er et par I/O-punkter, men du bør fokusere på logiske læsninger. Jo højere de logiske læsninger er, jo mere problematisk er forespørgselsydelsen.
Ved at reducere følgende 3 faktorer kan du fremskynde ydelsesjusteringsforespørgslerne i SQL:
- høj logisk læsning,
- høj LOB logiske læsninger,
- eller høje logiske WorkTable/WorkFile-læsninger.
For at få oplysninger om logiske læsninger skal du aktivere STATISTICS IO i SQL Server Management Studio-forespørgselsvinduet.
SÆT STATISTIK IO TIL
Du kan få output på fanen Meddelelser, efter at forespørgslen er udført. Figur 2 viser prøveoutputtet:
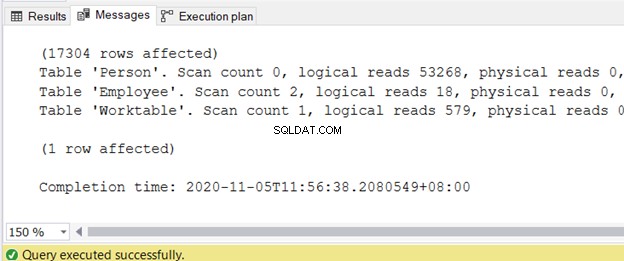
Jeg har skrevet en separat artikel om at reducere logiske læsninger i 3 grimme I/O-statistikker, der forsinker SQL-forespørgselsydeevne. Se den for de nøjagtige trin og kodeeksempler med høje logiske læsninger og måder at reducere dem på.
4. Tuning af SQL-forespørgsler med eksekveringsplaner
Logisk læsning alene giver dig ikke hele billedet. Rækken af trin, der vælges af forespørgselsoptimeringsværktøjet, fortæller historien om dit resultatsæt. Hvordan starter det hele, efter du har udført forespørgslen?
Figur 3 nedenfor er et diagram over, hvad der sker, efter du har udløst eksekveringen, indtil det øjeblik, du får resultatet sat.
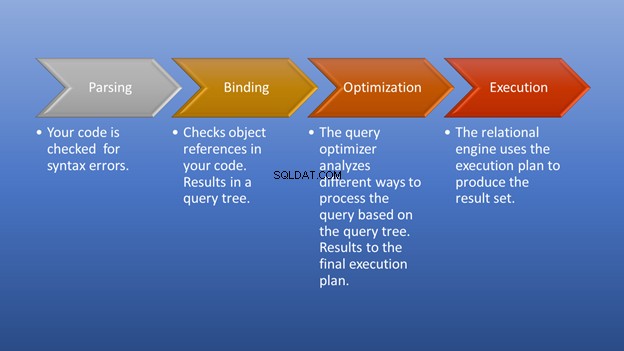
Parsing og binding vil ske lynhurtigt. Den fantastiske del er optimeringsfasen, som er vores fokus. På dette stadium spiller forespørgselsoptimeringsværktøjet en central rolle i udvælgelsen af den bedst mulige eksekveringsplan. Selvom denne del har brug for nogle ressourcer, sparer den en masse tid, når den vælger en effektiv eksekveringsplan. Dette sker dynamisk, da databasen ændrer sig over tid. På denne måde kan programmøren fokusere på, hvordan man danner det endelige resultat.
Hver plan, som forespørgselsoptimeringsværktøjet overvejer, har sine forespørgselsomkostninger. Blandt mange muligheder vil optimeringsværktøjet vælge planen med den mest rimelige pris. Bemærk :Rimelige omkostninger er ikke lig med de mindste omkostninger. Det skal også overveje, hvilken plan der giver de hurtigste resultater. Planen med de mindste omkostninger er ikke altid den hurtigste. For eksempel kan optimeringsværktøjet vælge at bruge flere processorkerner. Det kalder vi parallel eksekvering. Dette vil forbruge flere ressourcer, men køre hurtigere i forhold til seriel udførelse.
Et andet punkt at overveje er statistik. Forespørgselsoptimeringsværktøjet er afhængigt af det til at oprette eksekveringsplaner. Hvis statistikken er forældet, skal du ikke forvente den bedste beslutning fra forespørgselsoptimeringsværktøjet.
Når planen er besluttet og eksekveringen fortsætter, vil du se resultaterne. Hvad nu?
Undersøg forespørgselsudførelsesplanen i SQL Server
Når du danner en forespørgsel, vil du først se resultaterne. Resultaterne skal være korrekte. Når det er, er du færdig.
Er det sådan?
Hvis du mangler tid, og jobbet er på spil, kan du godt gå med til det. Desuden kan du altid komme tilbage. Men hvis der opstår andre problemer, kan du glemme dem igen og igen. Og så vil fortidens spøgelse jage dig.
Hvad er nu den bedste ting at gøre efter at have fået de korrekte resultater?
Undersøg den faktiske udførelsesplan eller Live forespørgselsstatistikker !
Sidstnævnte er godt, hvis din forespørgsel kører langsomt, og du vil se, hvad der sker hvert sekund, mens rækkerne behandles.
Til tider vil situationen tvinge dig til at inspicere planen med det samme. Tryk på Control-M for at starte eller klik på Medtag faktisk eksekveringsplan fra værktøjslinjen i SQL Server Management Studio. Hvis du foretrækker dbForge Studio til SQL Server, skal du gå til Query Profiler – det giver den samme information + nogle klokker og fløjter, som du ikke kan finde i SSMS.
Vi har set den faktiske udførelsesplan . Lad os gå videre.
Er der et manglende indeks eller indeksanbefalinger?
Et manglende indeks er let at få øje på – du får advarslen med det samme.
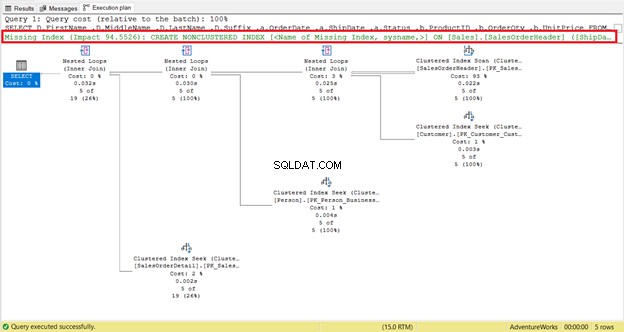
For at få en øjeblikkelig kode til at oprette indekset skal du højreklikke på Manglende indeks besked (indrammet i rødt). Vælg derefter Manglende indeksdetaljer . Et nyt forespørgselsvindue med koden til at oprette det manglende indeks vises. Opret indekset.
Denne del er nem at følge. Det er et godt udgangspunkt for at opnå hurtigere eksekvering. Men i nogle tilfælde vil der ingen effekt. Hvorfor? Nogle kolonner, der er nødvendige for din forespørgsel, er ikke i indekset. Derfor vil den vende tilbage til en Clustered Index Scan.
Du skal geninspicere udførelsesplanen efter oprettelse af indekset for at se, om Inkluderede kolonner er nødvendige. Juster derefter indekset i overensstemmelse hermed, og kør din forespørgsel igen. Derefter skal du kontrollere udførelsesplanen igen.
Men hvad hvis der ikke mangler noget indeks?
Læs udførelsesplanen
Du skal vide et par grundlæggende ting for at komme i gang:
- Operatører
- Egenskaber
- Læsevejledning
- Advarsler
OPERATORER
Forespørgselsoptimeringsværktøjet bruger en slags miniprogrammer kaldet operatører. Du har set nogle af dem i figur 4 – Clustered Index Seek , Clustered Index Scan , Indlejrede sløjfer , og Vælg .
For at få en omfattende liste med navne, ikoner og beskrivelser kan du tjekke denne reference fra Microsoft.
EGENSKABER
Grafiske diagrammer er ikke nok til at forstå, hvad der sker bag kulisserne. Du skal grave dybere ned i hver enkelt operatørs egenskaber. For eksempel Clustered Index Scan i figur 4 har følgende egenskaber:
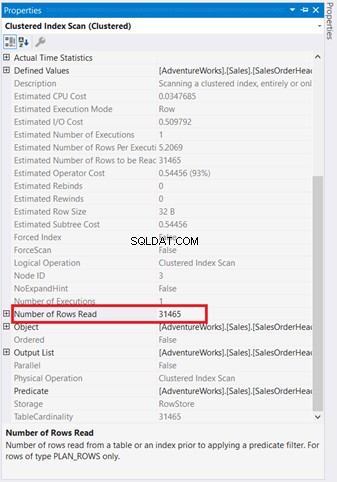
Hvis du vil undersøge det omhyggeligt, Clustered Index Scan operatøren er forfærdelig. Som figur 5 viser, læste den 31.465 rækker, men det endelige resultatsæt er kun 5 rækker. Derfor er der en indeksanbefaling i figur 4 for at reducere antallet af læste rækker. Den logiske læsning af forespørgslen er også høj, og det forklarer hvorfor.
For at vide mere om disse egenskaber, tjek listen over almindelige operatøregenskaber og planejendomme.
LÆSERETNING
Generelt er det som at læse japansk manga - fra højre mod venstre. Følg pilene, der peger til venstre. Her er et simpelt eksempel fra dbForge Studio til SQL Server.
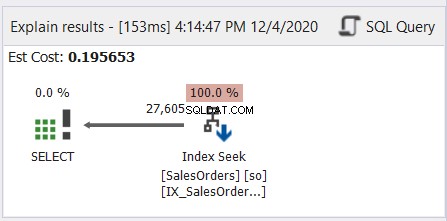
Som figur 6 viser, peger pilen til venstre fra indekssøgningsoperatoren til SELECT-operatoren.
Men at læse fra højre mod venstre er muligvis ikke altid korrekt. Se figur 7 med et eksempel fra SSMS:
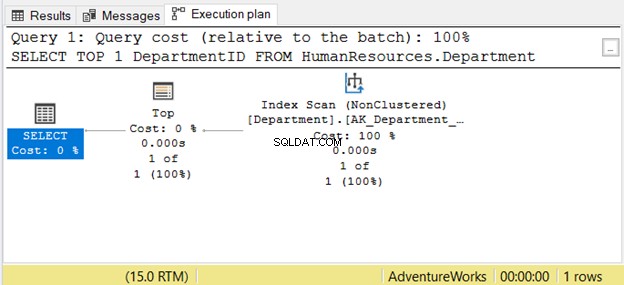
Hvis du læser det fra højre mod venstre, vil du se, at indeksscanningen operatør output er 1 af 1 række. Hvordan kunne den vide, at den kun skulle hente 1 række? Det er på grund af Top operatør. Dette vil forvirre os, hvis vi læser det fra højre mod venstre.
For at forstå denne sag bedre, læs den som "SELECT-operatoren bruger Top til at hente 1 række ved hjælp af Index Scan". Det er venstre mod højre.
Hvad skal vi bruge? Højre mod venstre eller venstre mod højre?
Det er sådan set begge dele - alt efter hvad der hjælper dig med at forstå planen.
Mens pilen giver os retningen af datastrømmen, giver dens tykkelse os nogle hints om størrelsen af dataene. Lad os henvise til figur 4 igen.
Clustered Index Scan gå til Indlejret løkke har en tykkere pil i forhold til de andre. Egenskaberne detaljer om indeksscanning i figur 5 fortæl os, hvorfor den er tyk (31.465 rækker aflæst for et endeligt resultat på 5 rækker).
ADVARSLER
Et advarselsikon, der vises i udførelsesplanoperatøren, fortæller os, at der er sket noget slemt i den pågældende operatør. Dette kan hæmme din SQL-forespørgselsoptimering ved at forbruge flere ressourcer.
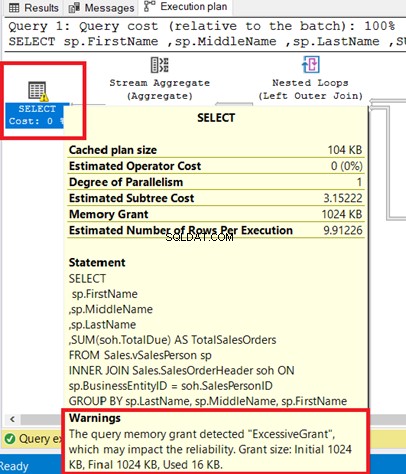
Du kan se advarslen i SELECT-operatoren. Hvis du holder musemarkøren til den pågældende operatør, afsløres advarselsmeddelelsen. En Overdreven Grant har forårsaget denne advarsel.
Overdreven bevilling sker, når der bruges mindre hukommelse, end der var reserveret til forespørgslen. For flere oplysninger henvises til denne Microsoft-dokumentation.
Figur 8 viser forespørgslen brugt som en INNER JOIN af en visning til en tabel. Du kan fjerne advarslen ved at forbinde basistabeller i stedet for visningen.
Nu hvor du har en grundlæggende idé om at læse eksekveringsplaner, hvordan definerer du, hvad der gør din forespørgsel langsom?
Kend de 5 Fælles Plan Operator Rogues
Forsinkelsen i udførelsen af din forespørgsel er som en forbrydelse. Du skal jagte og arrestere disse slyngler.
1. Clustered eller Non-Clustered Index Scan
Den første slyngel, som alle lærer om, er Clustered eller Ikke-klynget indeksscanning . Dens almindelige viden inden for SQL-forespørgselsoptimering om, at scanninger er dårlige, og søgninger er gode. Vi har set en i figur 4. På grund af det manglende indeks er Clustered Index Scan læser 31.465 for at få 5 rækker.
Det er dog ikke altid tilfældet. Overvej 2 forespørgsler på den samme tabel i figur 9. En vil have en søgning, og en anden har en scanning.
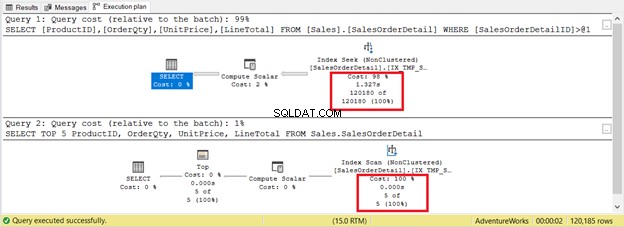
Hvis du kun baserer kriterierne på antallet af poster, vinder indeksscanningen med kun 5 poster mod 120.180. Indekssøgningen vil tage længere tid at udføre.
Her er et andet tilfælde, hvor enten scanning eller søgning næsten ikke betyder noget. De returnerer de samme 6 poster fra samme tabel. De logiske aflæsninger er de samme, og den forløbne tid er nul i begge tilfælde. Bordet er meget lille med kun 6 poster. Medtag den faktiske udførelsesplan og kør sætningerne nedenfor.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Gem derefter udførelsesplanen til sammenligning senere. Højreklik på udførelsesplanen> Gem udførelsesplan som .
Kør nu nedenstående forespørgsel.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Højreklik derefter på eksekveringsplanen og vælg Sammenlign Showplan . Vælg derefter den fil, du gemte tidligere. Du skal have samme output som i figur 10 nedenfor.
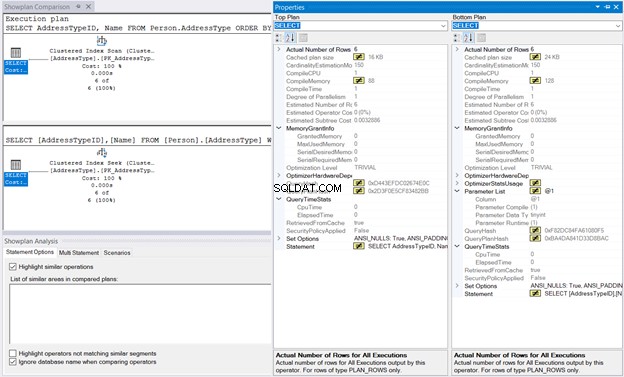
MemoryGrant og QueryTimeStats er det samme. 128KB CompileMemory brugt i Clustered Index Seek sammenlignet med 88KB af Clustered Index Scan er næsten ubetydelig. Uden disse tal at sammenligne, vil udførelsen føles den samme.
2. Undgå tabelscanninger
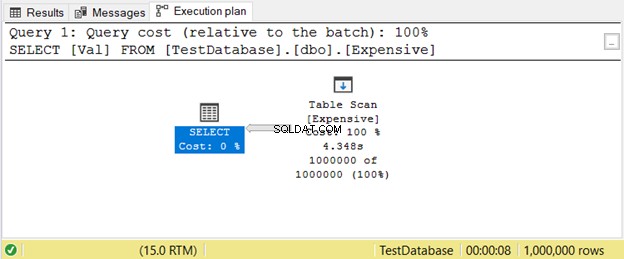
Dette sker, når du ikke har et indeks. I stedet for at søge værdier ved hjælp af et indeks, vil SQL Server scanne rækker én efter én, indtil den får det, du har brug for i din forespørgsel. Dette vil halte meget på store borde. Den enkle løsning er at tilføje det passende indeks.
Her er et eksempel på en eksekveringsplan med Tabelscanning operatør i figur 11.
3. Håndtering af sorteringsydelse
Som det kommer fra navnet, ændrer det rækkefølgen af rækker. Dette kan være en dyr operation.
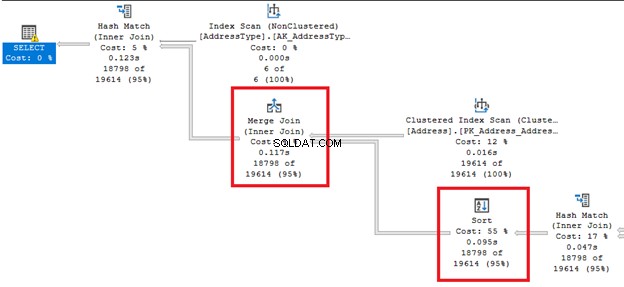
Se på de fede pilelinjer fra højre og venstre for Sorter operatør. Da forespørgselsoptimeringsværktøjet besluttede at foretage en Flet tilmelding , en sortering er påkrævet. Bemærk også, at det har den højeste procentvise omkostninger af alle operatører (55%).
Sortering kan være mere besværligt, hvis SQL Server skal bestille rækker flere gange. Du kan undgå denne operator, hvis din tabel er forhåndssorteret baseret på forespørgselskravet. Eller du kan dele en enkelt forespørgsel op i flere.
4. Fjern nøgleopslag
I figur 4 før anbefalede SQL Server at tilføje endnu et indeks. Jeg gjorde det, men det gav mig ikke præcis, hvad jeg ønskede. I stedet gav det mig en indekssøgning til det nye indeks parret med et nøgleopslag operatør.
Så det nye indeks tilføjede et ekstra trin.
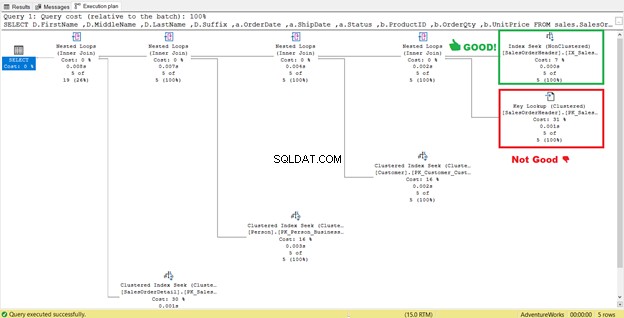
Hvad betyder dette nøgleopslag operatør gør?
Forespørgselsprocessoren brugte et nyt ikke-klynget indeks indrammet med grønt i figur 13. Da vores forespørgsel kræver kolonner, der ikke er i det nye indeks, skal den hente disse data ved hjælp af et nøgleopslag fra det klyngede indeks. Hvordan ved vi det? Hold musen hen til Nøgleopslag afslører nogle af dens egenskaber og beviser vores pointe.
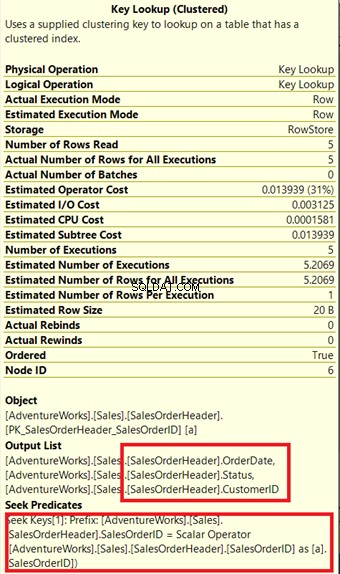
Læg mærke til outputlisten i figur 14. Vi skal hente 3 kolonner ved hjælp af PK_SalesOrderHeader_SalesOrderID klynget indeks. For at fjerne dette skal du inkludere disse kolonner i det nye indeks. Her er den nye plan, når disse kolonner er inkluderet.
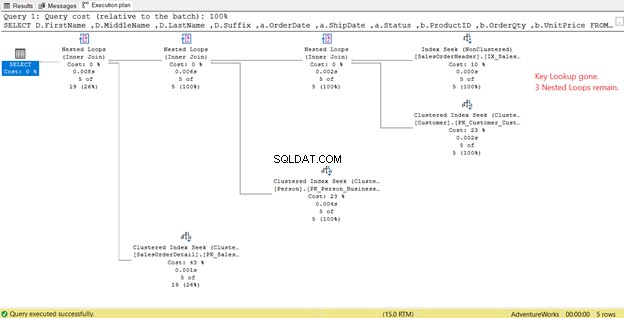
I figur 14 så vi 4 Indlejrede løkker . Den fjerde er nødvendig for det tilføjede nøgleopslag . Men efter at have tilføjet 3 kolonner som Inkluderede kolonner i det nye indeks, er der kun 3 Indlejrede løkker forblive, og Nøgleopslag er fjernet. Vi har ikke brug for nogle ekstra trin.
5. Parallelisme i SQL Server Execution Plan
Indtil videre har du set udførelsesplaner i serieudførelse. Men her er planen, der udnytter parallel eksekvering. Dette betyder, at mere end 1 processor bruges af forespørgselsoptimeringsværktøjet til at køre forespørgslen. Når vi bruger parallel eksekvering, ser vi Parallelisme operatører i planen og andre ændringer også.
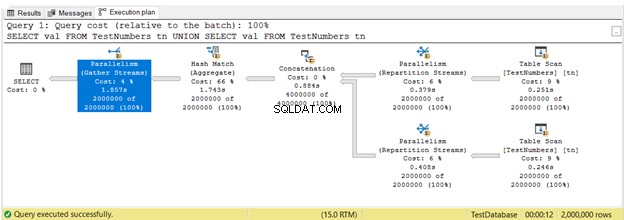
I figur 16, 3 Parallelisme operatører blev brugt. Bemærk også, at Tabelscanning operatørikonet er lidt anderledes. Dette sker, når der bruges parallel udførelse.
Parallelisme er ikke i sig selv dårligt. Det øger hastigheden af forespørgsler ved at bruge flere processorkerner. Det bruger dog flere CPU-ressourcer. Når mange af dine forespørgsler bruger paralleller, sænker det serveren. Du ønsker måske at tjekke omkostningstærsklen for indstilling af parallelitet i din SQL Server.
5. Bedste praksis for optimering af SQL-forespørgsler
Indtil videre har vi beskæftiget os med SQL-forespørgselsoptimering med metoder, der afdækker problemer, som er svære at få øje på. Men der er måder at få øje på det i kode. Her er nogle kode lugte i SQL.
Ved brug af SELECT *
Har du travlt? Så kan det være lettere at skrive * end at angive kolonnenavne. Der er dog en hage. Kolonner, du ikke har brug for, forsinker din forespørgsel.
Der er beviser. Eksempelforespørgslen, jeg brugte til figur 15, er denne:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Vi har allerede optimeret det. Men lad os ændre det til SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Det er kortere okay, men tjek udførelsesplanen nedenfor:
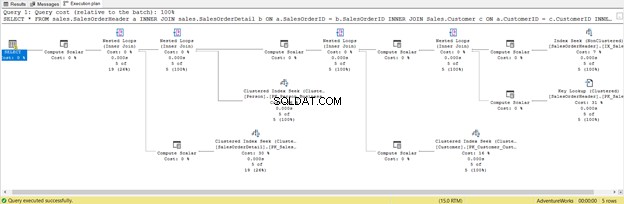
Dette er konsekvensen af at inkludere alle kolonner, også dem du ikke har brug for. Det returnerede Nøgleopslag og masser af Compute Scalar . Kort sagt, denne forespørgsel har en stor belastning og vil halte som et resultat. Bemærk også advarslen i SELECT-operatoren. Det var der ikke før. Sikke et spild!
Funktioner i en WHERE-klausul eller JOIN
En anden kodelugt har en funktion i WHERE-sætningen. Overvej følgende 2 SELECT-sætninger med det samme resultatsæt. Forskellen ligger i WHERE-sætningen.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
Den første SELECT bruger YEAR- og MONTH-datofunktionerne til at angive afsendelsesdatoer inden for juli 2011. Den anden SELECT-sætning bruger BETWEEN-operatoren med bogstaver for dato.
Den første SELECT-sætning vil have en udførelsesplan svarende til figur 4, men uden indeksanbefalingen. Den anden vil have en bedre udførelsesplan svarende til figur 15.
Den, der er bedre optimeret, er indlysende.
Brug af jokertegn
Hvor vilde kan jokertegn påvirke vores SQL-forespørgselsoptimering? Lad os tage et eksempel.
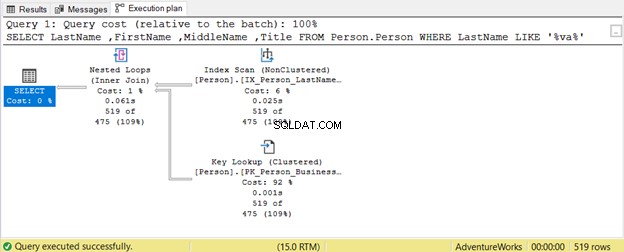
Forespørgslen forsøger at lede efter en tilstedeværelse af en streng i Efternavn i enhver stilling. Derfor Efternavn LIKE '%va%' . Dette er ineffektivt på store tabeller, fordi rækker vil blive inspiceret én efter én for tilstedeværelsen af denne streng. Det er derfor en indeksscanning anvendes. Da intet indeks indeholder titlen kolonne, et Nøgleopslag bruges også.
Dette kan rettes ved design.
Kræver opkaldsappen det? Eller vil det være nok at bruge LIKE ‘va%’?
SOM 'va%' bruger en indekssøgning fordi tabellen har et indeks på efternavn , fornavn , og mellemnavn .
Kan du også tilføje flere filtre i WHERE-klausulen for at reducere posternes læsning?
Dine svar på disse spørgsmål vil hjælpe dig med, hvordan du løser denne forespørgsel.
Implicit konvertering
SQL Server udfører implicit konvertering bag kulisserne for at afstemme datatyper ved sammenligning af værdier. For eksempel er det praktisk at tildele et nummer til en strengkolonne uden anførselstegn. Men der er en hage. Effekten er den samme, når du bruger en funktion i en WHERE-sætning.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner er NVARCHAR(15), men er lig med et tal. Det vil køre med succes på grund af implicit konvertering. Men læg mærke til udførelsesplanen i figur 19 nedenfor.
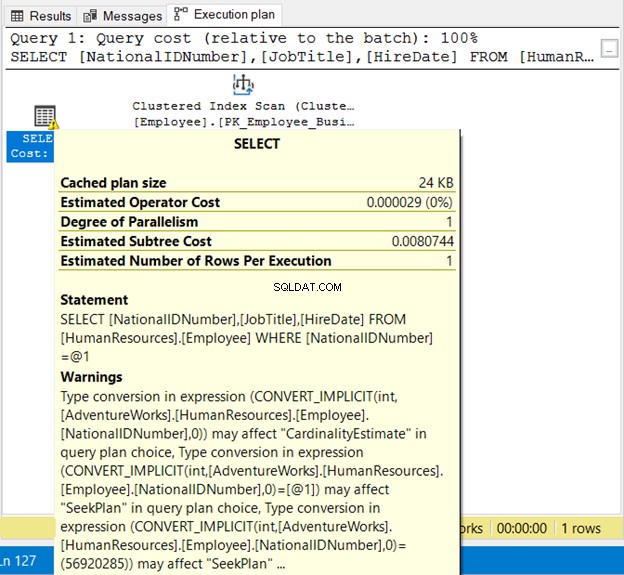
Vi ser 2 dårlige ting her. Først advarslen. Derefter indeksscanning . Indeksscanningen skete på grund af implicit konvertering. Sørg derfor for at omslutte strenge i anførselstegn eller test bogstavelige værdier med samme datatype som kolonnen.
SQL-forespørgselsoptimering takeaways
Det er det. Fik det grundlæggende i SQL-forespørgselsoptimering dig til at føle dig en smule klar til dine forespørgsler? Lad os få en opsummering.
- Hvis du vil have dine forespørgsler optimeret, så start med et godt databasedesign.
- Hvis databasen allerede er i produktion, kan du se de problematiske forespørgsler ved hjælp af SQL Server-standardrapporter.
- Find ud af, hvor stor virkningen af den langsomme forespørgsel er med logiske læsninger fra STATISTICS IO.
- Grav dybere ned i historien om din langsomme forespørgsel med udførelsesplaner.
- Se 4 kodelugte, der gør dine forespørgsler langsommere.
Der er andre SQL-forespørgselsoptimeringstip til at få en langsom forespørgsel til at køre hurtigt. Som jeg sagde i starten, er dette et stort emne. Så fortæl os i kommentarsektionen, hvad vi ellers gik glip af.
Og hvis du kan lide dette opslag, så del det på dine foretrukne sociale medieplatforme.
Mere SQL-forespørgselsoptimering fra tidligere artikler
Hvis du har brug for flere eksempler, er her nogle nyttige indlæg relateret til forespørgselsoptimeringsteknikker i SQL Server.
- Er underforespørgsler dårlige for ydeevnen? Se Den nemme vejledning om, hvordan du bruger underforespørgsler i SQL Server .
- Brug af HierarchyID vs. forælder/underordnet design – hvad er hurtigere? Besøg Sådan bruger du SQL Server HierarchyID gennem nemme eksempler .
- Kan grafdatabaseforespørgsler udkonkurrere deres relationelle ækvivalenter i et anbefalingssystem i realtid? Se Sådan gør du brug af SQL Server Graph Database-funktioner .
- Hvad er hurtigere:COALESCE eller ISNULL? Find ud af det i Top svar på 5 brændende spørgsmål om SQL COALESCE-funktion .
- VÆLG FRA visning vs. VÆLG FRA basistabeller – hvilken vil køre hurtigere? Besøg Top 3 tips, du skal vide for at skrive hurtigere SQL-visninger .
- CTE vs. midlertidige tabeller vs. underforespørgsler. Find ud af, hvilken der vinder i Alt hvad du behøver at vide om SQL CTE på ét sted .
- Brug af SQL SUBSTRING i en WHERE-sætning – en præstationsfælde? Se, om det er sandt med eksempler i Sådan analyserer man strenge som en professionel ved hjælp af SQL SUBSTRING()-funktionen?
- SQL UNION ALL er hurtigere end UNION. Find ud af hvorfor i SQL UNION snydeark med 10 nemme og nyttige tips .