Introduktion
Denne tutorial indeholder information om SQL (DDL, DML), som jeg har indsamlet i løbet af mit professionelle liv. Dette er det minimum, du behøver at vide, mens du arbejder med databaser. Hvis der er behov for at bruge komplekse SQL-konstruktioner, så surfer jeg normalt på MSDN-biblioteket, som nemt kan findes på internettet. Efter min mening er det meget svært at holde alt i hovedet, og det er der i øvrigt ikke behov for. Jeg anbefaler, at du bør kende alle de vigtigste konstruktioner, der bruges i de fleste relationelle databaser såsom Oracle, MySQL og Firebird. Alligevel kan de variere i datatyper. For at oprette objekter (tabeller, begrænsninger, indekser osv.), kan du for eksempel bruge integreret udviklingsmiljø (IDE) til at arbejde med databaser, og der er ingen grund til at studere visuelle værktøjer til en bestemt databasetype (MS SQL, Oracle , MySQL, Firebird osv.). Dette er praktisk, fordi du kan se hele teksten, og du behøver ikke at kigge gennem adskillige faner for at oprette for eksempel et indeks eller en begrænsning. Hvis du konstant arbejder med databaser, er oprettelse, ændring og især genopbygning af et objekt ved hjælp af scripts meget hurtigere end i en visuel tilstand. Desuden er det, efter min mening, i script-tilstanden (med passende præcision) lettere at specificere og kontrollere regler for navngivning af objekter. Derudover er det praktisk at bruge scripts, når du skal overføre databaseændringer fra en testdatabase til en produktionsdatabase.
SQL er opdelt i flere dele. I min artikel vil jeg gennemgå de vigtigste:
DDL – Data Definition Language
DML – Data Manipulation Language, som omfatter følgende konstruktioner:
- VÆLG – datavalg
- INDSÆT – ny dataindsættelse
- OPDATERING – dataopdatering
- SLET – datasletning
- FLET – datasammenfletning
Jeg vil forklare alle konstruktionerne i studiecases. Derudover synes jeg, at et programmeringssprog, især SQL, bør studeres i praksis for bedre forståelse.
Dette er en trin-for-trin tutorial, hvor du skal udføre eksempler, mens du læser den. Men hvis du har brug for at kende kommandoen i detaljer, så surf på internettet, for eksempel MSDN.
Da jeg oprettede denne vejledning, har jeg brugt MS SQL Server-databasen, version 2014, og MS SQL Server Management Studio (SSMS) til at udføre scripts.
Kort om MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) er Microsoft SQL Server-værktøjet til at konfigurere, administrere og administrere databasekomponenter. Det inkluderer en script-editor og et grafikprogram, der arbejder med serverobjekter og -indstillinger. Hovedværktøjet i SQL Server Management Studio er Object Explorer, som giver en bruger mulighed for at se, hente og administrere serverobjekter. Denne tekst er delvist taget fra Wikipedia.
For at oprette en ny script-editor skal du bruge knappen Ny forespørgsel:
For at skifte fra den aktuelle database kan du bruge rullemenuen:
For at udføre en bestemt kommando eller et sæt af kommandoer, skal du fremhæve det og trykke på knappen Udfør eller F5. Hvis der kun er én kommando i editoren, eller du skal udføre alle kommandoer, skal du ikke fremhæve noget.
Når du har udført scripts, der opretter objekter (tabeller, kolonner, indekser), skal du vælge det tilsvarende objekt (f.eks. tabeller eller kolonner) og derefter klikke på Opdater på genvejsmenuen for at se ændringerne.
Faktisk er dette alt hvad du behøver at vide for at udføre eksemplerne heri.
Teori
En relationsdatabase er et sæt tabeller, der er forbundet med hinanden. Generelt er en database en fil, der gemmer strukturerede data.
Database Management System (DBMS) er et sæt værktøjer til at arbejde med bestemte databasetyper (MS SQL, Oracle, MySQL, Firebird osv.).
Bemærk: Som i vores daglige liv siger vi "Oracle DB" eller bare "Oracle", der rent faktisk betyder "Oracle DBMS", så i denne tutorial vil jeg bruge udtrykket "database".
En tabel er et sæt af kolonner. Meget ofte kan du høre følgende definitioner af disse termer:felter, rækker og poster, som betyder det samme.
En tabel er hovedobjektet for relationsdatabasen. Alle data gemmes række for række i tabelkolonner.
For hver tabel såvel som for dens kolonner skal du angive et navn, i henhold til hvilket du kan finde et påkrævet element.
Navnet på objektet, tabellen, kolonnen og indekset kan have minimumslængden – 128 symboler.
Bemærk: I Oracle-databaser kan et objektnavn have minimumslængden – 30 symboler. I en bestemt database er det således nødvendigt at oprette brugerdefinerede regler for objektnavne.
SQL er et sprog, der gør det muligt at udføre forespørgsler i databaser via DBMS. I et bestemt DBMS kan et SQL-sprog have sin egen dialekt.
DDL og DML – SQL-undersproget:
- DDL-sproget tjener til at oprette og ændre en databasestruktur (sletning af tabel og link);
- DML-sproget gør det muligt at manipulere tabeldata, dets rækker. Det tjener også til at vælge data fra tabeller, tilføje nye data samt opdatere og slette aktuelle data.
Det er muligt at bruge to typer kommentarer i SQL (enkeltlinje og afgrænset):
-- single-line comment
og
/* delimited comment */
Det handler alt sammen om teorien.
DDL – Data Definition Language
Lad os overveje en eksempeltabel med data om medarbejdere repræsenteret på en måde, som en person, der ikke er programmør, kender.
| Medarbejder-id | Fuldt navn | Fødselsdato | Position | Afdeling | |
| 1000 | John | 19.02.1955 | eksempel@sqldat.com | administrerende direktør | Administration |
| 1001 | Daniel | 03.12.1983 | eksempel@sqldat.com | programmør | IT |
| 1002 | Mike | 07.06.1976 | eksempel@sqldat.com | Revisor | Kontoafdeling |
| 1003 | Jordan | 17.04.1982 | eksempel@sqldat.com | Senior programmør | IT |
I dette tilfælde har kolonnerne følgende titler:Medarbejder-id, Fulde navn, Fødselsdato, E-mail, Stilling og Afdeling.
Vi kan beskrive hver kolonne i denne tabel efter dens datatype:
- Medarbejder-id – heltal
- Fuldt navn – streng
- Fødselsdato – dato
- E-mail – streng
- Position – streng
- Afdeling – streng
En kolonnetype er en egenskab, der specificerer, hvilken datatype hver kolonne kan gemme.
Til at starte med skal du huske de vigtigste datatyper, der bruges i MS SQL:
| Definition | Betegnelse i MS SQL | Beskrivelse |
| Streng med variabel længde | varchar(N) og nvarchar(N) | Ved at bruge N-tallet kan vi angive den maksimalt mulige strenglængde for en bestemt kolonne. For eksempel, hvis vi vil sige, at værdien af kolonnen Fuldt navn kan indeholde 30 symboler (højst), så er det nødvendigt at angive typen af nvarchar(30).
Forskellen mellem varchar og nvarchar er, at varchar tillader lagring af strenge i ASCII-formatet, mens nvarchar gemmer strenge i Unicode-formatet, hvor hvert symbol tager 2 bytes. |
| streng med fast længde | char(N) og nchar(N) | Denne type adskiller sig fra strengen med variabel længde i det følgende:hvis strengens længde er mindre end N symboler, tilføjes der altid mellemrum til N-længden til højre. I en database tager det altså præcis N symboler, hvor et symbol tager 1 byte for char og 2 byte for nchar. I min praksis bliver denne type ikke brugt meget. Alligevel, hvis nogen bruger det, så har denne type normalt char(1)-formatet, dvs. når et felt er defineret med 1 symbol. |
| Heltal | int | Denne type tillader os kun at bruge heltal (både positivt og negativt) i en kolonne. Bemærk:et talinterval for denne type er som følger:fra 2 147 483 648 til 2 147 483 647. Normalt er det hovedtypen, der bruges til at identificere identifikatorer. |
| Flydende kommatal | flydende | Tal med et decimaltegn. |
| Dato | dato | Det bruges til kun at gemme en dato (dato, måned og år) i en kolonne. For eksempel 15/02/2014. Denne type kan bruges til følgende kolonner:kvitteringsdato, fødselsdato osv., når du kun skal angive en dato, eller når tiden ikke er vigtig for os, og vi kan droppe den. |
| Tid | tid | Du kan bruge denne type, hvis det er nødvendigt at gemme tid:timer, minutter, sekunder og millisekunder. For eksempel har du 17:38:31.3231603, eller du skal tilføje flyets afgangstidspunkt. |
| Dato og klokkeslæt | datotid | Denne type giver brugerne mulighed for at gemme både dato og klokkeslæt. For eksempel har du begivenheden den 15/02/2014 17:38:31.323. |
| Indikator | bit | Du kan bruge denne type til at gemme værdier såsom 'Ja'/'Nej', hvor 'Ja' er 1, og 'Nej' er 0. |
Derudover er det ikke nødvendigt at angive feltværdien, medmindre det er forbudt. I dette tilfælde kan du bruge NULL.
For at udføre eksempler vil vi oprette en testdatabase med navnet 'Test'.
For at oprette en simpel database uden yderligere egenskaber skal du køre følgende kommando:
CREATE DATABASE Test
For at slette en database skal du udføre denne kommando:
DROP DATABASE Test
For at skifte til vores database, brug kommandoen:
USE Test
Alternativt kan du vælge testdatabasen fra rullemenuen i SSMS-menuområdet.
Nu kan vi oprette en tabel i vores database ved hjælp af beskrivelser, mellemrum og kyrilliske symboler:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
I dette tilfælde skal vi indpakke navne i firkantede parenteser […].
Alligevel er det bedre at angive alle objektnavne på latin og ikke bruge mellemrum i navnene. I dette tilfælde starter hvert ord med et stort bogstav. For eksempel, for "EmployeeID"-feltet, kunne vi angive PersonnelNumber-navnet. Du kan også bruge numre i navnet, f.eks. PhoneNumber1.
Bemærk: I nogle DBMS'er er det mere praktisk at bruge følgende navneformat «PHONE_NUMBER». For eksempel kan du se dette format i ORACLE-databaser. Desuden bør feltnavnet ikke falde sammen med de søgeord, der bruges i DBMS.
Af denne grund kan du glemme syntaksen for firkantede parenteser og kan slette tabellen Medarbejdere:
DROP TABLE [Employees]
For eksempel kan du navngive tabellen med medarbejdere som "Medarbejdere" og angive følgende navne for dens felter:
- ID
- Navn
- Fødselsdag
- Position
- Afdeling
Meget ofte bruger vi 'ID' til identifikationsfeltet.
Lad os nu oprette en tabel:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
For at indstille de obligatoriske kolonner kan du bruge NOT NULL-indstillingen.
For den aktuelle tabel kan du omdefinere felterne ved hjælp af følgende kommandoer:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Bemærk: Det generelle koncept for SQL-sproget for de fleste DBMS'er er det samme (fra min egen erfaring). Forskellen mellem DDL'er i forskellige DBMS'er er hovedsageligt i datatyperne (de kan afvige ikke kun ved deres navne, men også ved deres specifikke implementering). Derudover er den specifikke SQL-implementering (kommandoer) den samme, men der kan være små forskelle i dialekten. Ved at kende det grundlæggende i SQL kan du nemt skifte fra et DBMS til et andet. I dette tilfælde behøver du kun at forstå detaljerne ved implementering af kommandoer i et nyt DBMS.
Sammenlign de samme kommandoer i ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE adskiller sig i implementeringen af varchar2-typen. Dens format afhænger af DB-indstillingerne, og du kan gemme en tekst, for eksempel i UTF-8. Derudover kan du angive feltlængden både i bytes og symboler. For at gøre dette skal du bruge BYTE- og CHAR-værdierne efterfulgt af længdefeltet. For eksempel:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
Værdien (BYTE eller CHAR), der skal bruges som standard, når du blot angiver varchar2(30) i ORACLE, afhænger af DB-indstillingerne. Ofte kan du nemt blive forvirret. Derfor anbefaler jeg eksplicit at specificere CHAR, når du bruger varchar2-typen (for eksempel med UTF-8) i ORACLE (da det er mere praktisk at læse strengens længde i symboler).
Men i dette tilfælde, hvis der er nogen data i tabellen, er det nødvendigt at udfylde felterne ID og Navn i alle tabelrækkerne for at kunne udføre kommandoer.
Jeg vil vise det i et bestemt eksempel.
Lad os indsætte data i felterne ID, Position og Afdeling ved hjælp af følgende script:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
I dette tilfælde returnerer kommandoen INSERT også en fejl. Dette sker, fordi vi ikke har angivet værdien for det obligatoriske felt Navn.
Hvis der var nogle data i den originale tabel, så ville kommandoen "ALTER TABLE Employees ALTER COLUMN ID int NOT NULL" virke, mens kommandoen "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" ville returnere en fejl, som feltet Navn har NULL-værdier.
Lad os tilføje værdier i feltet Navn:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Derudover kan du bruge NOT NULL, når du opretter en ny tabel med CREATE TABLE-sætningen.
Lad os først slette en tabel:
DROP TABLE Employees
Nu skal vi oprette en tabel med de obligatoriske felter ID og Navn:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Du kan også angive NULL efter et kolonnenavn, hvilket antyder, at NULL-værdier er tilladt. Dette er ikke obligatorisk, da denne mulighed er indstillet som standard.
Hvis du skal gøre den aktuelle kolonne ikke-obligatorisk, skal du bruge følgende syntaks:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Alternativt kan du bruge denne kommando:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Derudover kan vi med denne kommando enten ændre felttypen til en anden kompatibel eller ændre dens længde. Lad os f.eks. udvide feltet Navn til 50 symboler:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Primær nøgle
Når du opretter en tabel, skal du angive en kolonne eller et sæt kolonner, der er unikke for hver række. Ved at bruge denne unikke værdi kan du identificere en post. Denne værdi kaldes den primære nøgle. ID-kolonnen (der indeholder «en medarbejders personlige nummer» – i vores tilfælde er dette den unikke værdi for hver medarbejder og kan ikke duplikeres) kan være den primære nøgle til vores medarbejdere-tabel.
Du kan bruge følgende kommando til at oprette en primær nøgle til tabellen:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
'PK_Employees' er et begrænsningsnavn, der definerer den primære nøgle. Normalt består navnet på en primær nøgle af 'PK_'-præfikset og tabelnavnet.
Hvis den primære nøgle indeholder flere felter, skal du angive disse felter i parentes adskilt af et komma:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Husk, at i MS SQL skal alle felter i den primære nøgle IKKE være NULL.
Desuden kan du definere en primær nøgle, når du opretter en tabel. Lad os slette tabellen:
DROP TABLE Employees
Opret derefter en tabel ved hjælp af følgende syntaks:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Tilføj data til tabellen:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
Faktisk behøver du ikke at angive begrænsningsnavnet. I dette tilfælde vil et systemnavn blive tildelt. For eksempel, «PK__Employee__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
eller
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Personligt vil jeg anbefale eksplicit at specificere begrænsningsnavnet for permanente tabeller, da det er lettere at arbejde med eller slette en eksplicit defineret og klar værdi i fremtiden. For eksempel:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Alligevel er det mere behageligt at anvende denne korte syntaks uden begrænsningsnavne, når du opretter midlertidige databasetabeller (navnet på en midlertidig tabel begynder med # eller ##.
Oversigt:
Vi har allerede analyseret følgende kommandoer:
- OPRET TABEL tabelnavn (liste over felter og deres typer, såvel som begrænsninger) – tjener til at oprette en ny tabel i den aktuelle database;
- SLIP TABEL tabelnavn – tjener til at slette en tabel fra den aktuelle database;
- ÆNDRINGSTABEL tabelnavn ALTER COLUMN kolonnenavn … – tjener til at opdatere kolonnetypen eller til at ændre dens indstillinger (f.eks. når du skal indstille NULL eller NOT NULL);
- ÆNDRINGSTABEL tabelnavn TILFØJ BEGRÆNSNING constraint_name PRIMÆR NØGLE (felt1, felt2,...) – bruges til at tilføje en primærnøgle til den aktuelle tabel;
- ÆNDRINGSTABEL tabelnavn SLIP BEGRÆNSNING constraint_name – bruges til at slette en begrænsning fra tabellen.
Midlertidige tabeller
Abstrakt fra MSDN. Der er to typer midlertidige tabeller i MS SQL Server:lokal (#) og global (##). Lokale midlertidige tabeller er kun synlige for deres skabere, før forekomsten af SQL Server afbrydes. De slettes automatisk, efter at brugeren afbrydes fra instansen af SQL Server. Globale midlertidige tabeller er synlige for alle brugere under enhver forbindelsessession efter oprettelse af disse tabeller. Disse tabeller slettes, når brugere afbrydes fra forekomsten af SQL Server.
Midlertidige tabeller oprettes i tempdb systemdatabasen, hvilket betyder, at vi ikke oversvømmer hoveddatabasen. Derudover kan du slette dem ved at bruge kommandoen DROP TABLE. Meget ofte bruges lokale (#) midlertidige tabeller.
For at oprette en midlertidig tabel kan du bruge kommandoen CREATE TABLE:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
Du kan slette den midlertidige tabel med kommandoen DROP TABLE:
DROP TABLE #Temp
Derudover kan du oprette en midlertidig tabel og udfylde den med data ved hjælp af SELECT … INTO-syntaksen:
SELECT ID,Name INTO #Temp FROM Employees
Bemærk: I forskellige DBMS'er kan implementeringen af midlertidige databaser variere. For eksempel, i ORACLE og Firebird DBMS'erne, skal strukturen af midlertidige tabeller være defineret på forhånd af kommandoen CREATE GLOBAL TEMPORARY TABLE. Du skal også specificere måden at gemme data på. Herefter ser en bruger den blandt almindelige tabeller og arbejder med den som med en konventionel tabel.
Databasenormalisering:opdeling i undertabeller (referencetabeller) og definering af tabelrelationer
Vores nuværende medarbejdertabel har en ulempe:en bruger kan skrive en hvilken som helst tekst i stillings- og afdelingsfelterne, hvilket kan returnere fejl, da han for en medarbejder kan angive "IT" som en afdeling, mens han for en anden medarbejder kan angive "IT" afdeling". Det vil derfor være uklart, hvad brugeren mente, om disse medarbejdere arbejder for samme afdeling eller om der er stavefejl, og der er 2 forskellige afdelinger. Desuden vil vi i dette tilfælde ikke være i stand til korrekt at gruppere dataene til en rapport, hvor vi skal vise antallet af medarbejdere for hver afdeling.
En anden ulempe er lagervolumen og dets duplikering, dvs. du skal angive et fulde navn på afdelingen for hver medarbejder, hvilket kræver plads i databaser til at gemme hvert symbol af afdelingsnavnet.
Den tredje ulempe er kompleksiteten ved at opdatere feltdata, når du skal ændre et navn på enhver stilling - fra programmør til juniorprogrammør. I dette tilfælde skal du tilføje nye data i hver tabelrække, hvor positionen er "Programmer".
For at undgå sådanne situationer anbefales det at bruge databasenormalisering – opdeling i undertabeller – referencetabeller.
Lad os oprette 2 referencetabeller "Positioner" og "Afdelinger":
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Bemærk at vi her har brugt en ny ejendom IDENTITET. Det betyder, at data i ID-kolonnen automatisk vil blive listet startende med 1. Ved tilføjelse af nye poster vil værdierne 1, 2, 3 osv. således blive tildelt sekventielt. Normalt kaldes disse felter autoincrement-felter. Kun ét felt med egenskaben IDENTITY kan defineres som en primær nøgle i en tabel. Normalt, men ikke altid, er et sådant felt den primære nøgle i tabellen.
Bemærk: I forskellige DBMS'er kan implementeringen af felter med en inkrementer være forskellig. I MySQL, for eksempel, er et sådant felt defineret af AUTO_INCREMENT egenskaben. I ORACLE og Firebird kan du efterligne denne funktionalitet ved hjælp af sekvenser (SEQUENCE). Men så vidt jeg ved, er egenskaben GENERATED AS IDENTITY blevet tilføjet i ORACLE.
Lad os udfylde disse tabeller automatisk baseret på de aktuelle data i stillings- og afdelingsfelterne i tabellen Medarbejdere:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
Du skal udføre de samme trin for afdelingstabellen:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Hvis vi nu åbner tabellerne Stillinger og Afdelinger, vil vi se en nummereret liste over værdier i ID-feltet:
SELECT * FROM Positions
| ID | Navn |
| 1 | Revisor |
| 2 | administrerende direktør |
| 3 | Programmer |
| 4 | Senior programmør |
SELECT * FROM Departments
| ID | Navn |
| 1 | Administration |
| 2 | Kontoafdeling |
| 3 | IT |
Disse tabeller vil være referencetabeller til at definere stillinger og afdelinger. Nu vil vi henvise til identifikatorer for stillinger og afdelinger. Lad os først oprette nye felter i tabellen Medarbejdere for at gemme identifikatorerne:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
Typen af referencefelter skal være den samme som i referencetabellerne, i dette tilfælde er det int.
Derudover kan du tilføje flere felter ved at bruge én kommando ved at angive felterne adskilt af kommaer:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Nu vil vi tilføje referencebegrænsninger (FOREIGN KEY) til disse felter, så en bruger ikke kan tilføje nogen værdier, der ikke er ID-værdierne for referencetabellerne.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
De samme trin skal udføres for det andet felt:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Nu kan brugere kun indsætte ID-værdierne fra den tilsvarende referencetabel i disse felter. For at bruge en ny afdeling eller stilling skal en bruger tilføje en ny post i den tilsvarende referencetabel. Da stillinger og afdelinger er gemt i referencetabeller i én kopi, skal du for at ændre deres navn kun ændre det i referencetabellen.
Navnet på en referencebegrænsning er normalt sammensat. Den består af præfikset «FK» efterfulgt af et tabelnavn og et feltnavn, der refererer til referencetabelidentifikationen.
Identifikationen (ID) er normalt en intern værdi, der kun bruges til links. Det er lige meget, hvilken værdi det har. Forsøg derfor ikke at slippe af med huller i rækkefølgen af værdier, der opstår, når du for eksempel arbejder med tabellen, når du sletter poster fra referencetabellen.
I nogle tilfælde er det muligt at bygge en reference fra flere felter:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
I dette tilfælde er en primær nøgle repræsenteret af et sæt af flere felter (felt1, felt2, …) i tabellen "reference_table".
Lad os nu opdatere felterne PositionID og DepartmentID med ID-værdierne fra referencetabellerne.
For at gøre dette bruger vi kommandoen UPDATE:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Kør følgende forespørgsel:
SELECT * FROM Employees
| ID | Navn | Fødselsdag | Position | Afdeling | Positions-ID | Afdelings-id | |
| 1000 | John | NULL | NULL | administrerende direktør | Administration | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Programmer | IT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Revisor | Kontoafdeling | 1 | 2 |
| 1003 | Jordan | NULL | NULL | Senior programmør | IT | 4 | 3 |
Som du kan se, matcher felterne PositionID og DepartmentID stillinger og afdelinger. Du kan således slette felterne Stilling og Afdeling i tabellen Medarbejdere ved at udføre følgende kommando:
ALTER TABLE Employees DROP COLUMN Position,Department
Kør nu denne erklæring:
SELECT * FROM Employees
| ID | Navn | Fødselsdag | Positions-ID | Afdelings-id | |
| 1000 | John | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordan | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
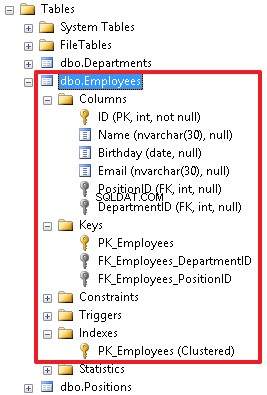
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Then create a diagram and check how our tables are linked:
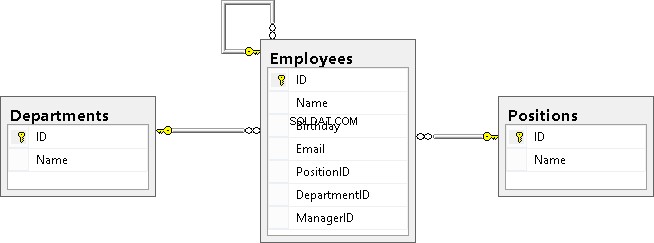
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
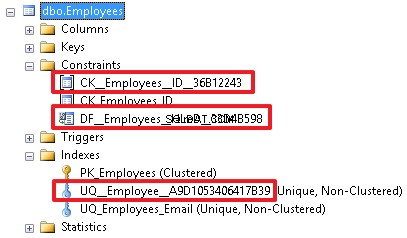
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Summary
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.