Dette er den første artikel i en serie af artikler om In-Memory OLTP. Det hjælper dig med at forstå, hvordan den nye Hekaton-motor fungerer internt. Vi vil fokusere på detaljer om in-memory optimerede tabeller og indekser. Dette er artiklen på entry-level, hvilket betyder, at du ikke behøver at være SQL Server-ekspert, men du skal dog have noget grundlæggende viden om den traditionelle SQL Server-motor.
Introduktion
SQL Server 2014 In-Memory OLTP-motoren (Hekaton-projektet) blev skabt fra nulpunktet for at udnytte terabyte af tilgængelig hukommelse og et stort antal behandlingskerner. In-Memory OLTP giver brugerne mulighed for at arbejde med hukommelsesoptimerede tabeller og indekser og native kompilerede lagrede procedurer. Du kan bruge det sammen med de diskbaserede tabeller og indekser og T-SQL-lagrede procedurer, som SQL Server altid har leveret.
In-Memory OLTP-motorens indre og egenskaber adskiller sig væsentligt fra standard relationsmotoren. Du skal revidere næsten alt, hvad du vidste om, hvordan flere samtidige processer håndteres.
SQL Server-motoren er optimeret til disk-baseret lagring. Den læser 8KB datasider ind i hukommelsen til behandling og skriver 8KB datasider tilbage til disken efter ændringer. SQL Server retter naturligvis først og fremmest ændringerne til disken i transaktionsloggen. At læse 8 KB datasider fra disk og skrive det tilbage, kan generere en masse I/O og føre til en højere latensomkostning. Selv når dataene er i buffercachen, er SQL-serveren designet til at antage, at det ikke er det, hvilket fører til ineffektiv CPU-brug.
I betragtning af begrænsningerne ved traditionelle diskbaserede lagerstrukturer begyndte SQL Server-teamet at bygge en databasemotor optimeret til stor hovedhukommelse og multiple-core CPU'er. Holdet satte følgende mål:
- Optimeret til data, der blev gemt fuldstændigt i hukommelsen, men som også var holdbare ved genstart af SQL Server
- Fuldt integreret i den eksisterende SQL Server-motor
- Meget høj ydeevne til OLTP-operationer
- Designet til moderne CPU'er
SQL Server In-Memory OLTP opfylder alle disse mål.
Om OLTP i hukommelsen
SQL Server 2014 In-Memory OLTP giver en række teknologier til at arbejde med hukommelsesoptimerede tabeller sammen med de diskbaserede tabeller. For eksempel giver det dig adgang til data i hukommelsen ved at bruge standardgrænseflader som T-SQL og SSMS. Følgende illustration viser hukommelsesoptimerede tabeller og indekser som en del af In-Memory OLTP (til venstre) og de diskbaserede tabeller (til venstre), der kræver at læse og skrive 8KB datasider. In-Memory OLTP understøtter også indbygget kompilerede lagrede procedurer og giver en ny OLTP-compiler i hukommelsen.
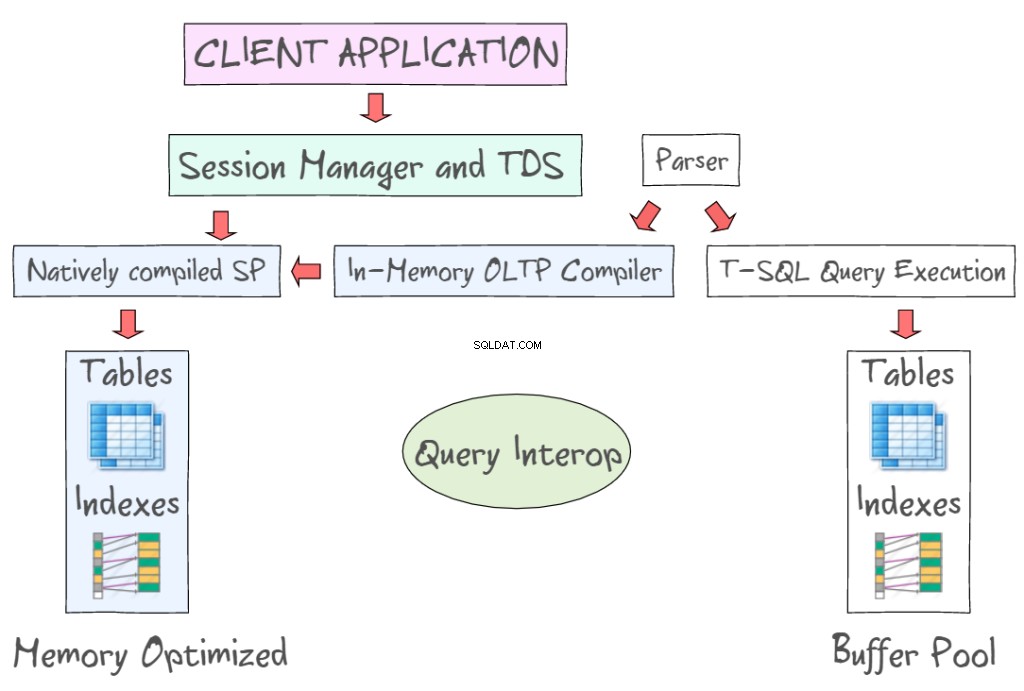
Query Interop gør det muligt at fortolke T-SQL for at referere til hukommelsesoptimerede tabeller. Hvis en transaktion refererer til både hukommelsesoptimerede og diskbaserede tabeller, kan den omtales som en cross-container transaktion. Klientappen bruger Tabular Data Stream - en applikationslagsprotokol, der bruges til at overføre data mellem en databaseserver og en klient. Det blev oprindeligt designet og udviklet af Sybase Inc. til deres Sybase SQL Server relationsdatabasemotor i 1984 og senere af Microsoft i Microsoft SQL Server.
Hukommelsesoptimerede tabeller
Mens du får adgang til diskbaserede tabeller, er de nødvendige data muligvis allerede i hukommelsen, selvom det måske ikke er det. Hvis data ikke er i hukommelsen, skal SQL Server læse dem fra disken. Den mest fundamentale forskel ved brug af hukommelsesoptimerede tabeller er, at hele tabellen og dens indekser er gemt i hukommelsen hele tiden . Samtidige dataoperationer kræver ingen låsning eller låsning.
Mens en bruger ændrer data i hukommelsen, udfører SQL Server nogle disk I/O for enhver tabel, der skal være holdbar, ellers sagt, hvor vi har brug for en tabel til at beholde data i hukommelsen på tidspunktet for et servernedbrud eller genstart.
Rækkebaseret lagerstruktur
En anden væsentlig forskel er den underliggende lagerstruktur. De diskbaserede tabeller er optimeret til blokadresserbare disklager, hvorimod in-memory-optimerede tabeller er optimeret til byte-adresserbare hukommelseslagring.
SQL Server opbevarer datarækker på 8K-datasider med pladsallokering fra omfang til diskbaserede tabeller. Datasiden er den grundlæggende enhed for disk- og hukommelseslagring. Mens du læser og skriver data fra disk, læser og skriver SQL Server kun de relevante datasider. En dataside vil kun indeholde data fra én tabel eller et indeks. Ansøgningsprocesser ændrer rækker på forskellige datasider efter behov. Senere, under CHECKPOINT-operationen, retter SQL Server først logposterne til disken og skriver derefter alle beskidte sider til disken. Denne operation forårsager ofte en masse tilfældige fysiske I/O.
For hukommelsesoptimerede tabeller er der ingen datasider, samt ingen omfang. Der er kun datarækker skrevet til hukommelsen sekventielt i den rækkefølge, transaktionerne fandt sted. Hver række indeholder en indeksmarkør til den næste række. Al I/O er in-memory scanning af disse strukturer. Der er ingen forestilling om, at datarækker skrives til en bestemt placering, der tilhører et specificeret objekt. Selvom du ikke behøver at tro, at hukommelsesoptimerede tabeller er gemt som det uorganiserede sæt af datarækker (svarende til diskbaserede dynger). Hver CREATE TABLE-sætning for en hukommelsesoptimeret tabel opretter mindst ét indeks, som SQL Server bruger til at sammenkæde alle datarækkerne i den tabel.
Hver enkelt datarække består af rækkeoverskriften og nyttelasten, der er de faktiske kolonnedata. Headeren gemmer information om den sætning, der skabte rækken, pointere for hvert indeks på måltabellen og tidsstempelværdier. Tidsstempel angiver det tidspunkt, hvor en transaktion indsatte og slettede en række. SQL Server-poster opdateres ved at indsætte en ny rækkeversion og markere den gamle version som slettet. Der kan eksistere flere versioner af samme række på ethvert givet tidspunkt. Dette giver mulighed for samtidig adgang til den samme række under dataændringen. SQL Server viser rækkeversionen, der er relevant for hver transaktion i henhold til det tidspunkt, transaktionen startede i forhold til tidsstemplet for rækkeversionen. Dette er kernen i den nye multiversion samtidighedskontrol mekanisme til tabeller i hukommelsen.
Oracle har i øvrigt et fremragende multi-version kontrolsystem. Grundlæggende fungerer det som følger:
- Bruger A starter en transaktion og opdaterer 1000 rækker med en vis værdi på tidspunktet T1.
- Bruger B læser de samme 1000 rækker på tidspunktet T2.
- Bruger A opdaterer række 565 med værdien Y (den oprindelige værdi var X).
- Bruger B når række 565 og finder, at en transaktion er i drift siden Tid T1.
- Databasen returnerer den umodificerede post fra logfilerne. Den returnerede værdi er den værdi, der blev begået på det tidspunkt, mindre end eller lig med T2.
- Hvis posten ikke kunne hentes fra redo-logfilerne, betyder det, at databasen ikke er konfigureret korrekt. Der skal tildeles mere plads til logfilerne.
- De returnerede resultater er altid de samme med hensyn til starttidspunktet for transaktionen. Så inden for transaktionen opnås læsekonsistensen.
Native kompilerede tabeller
Den sidste store forskel er, at de in-memory-optimerede tabeller er native kompilerede . Når en bruger opretter en hukommelsesoptimeret tabel eller et indeks, gemmer SQL Server strukturen af hver tabel (sammen med alle indekser) i metadataene. Senere bruger SQL Server disse metadata til at kompilere et sæt modersmålsrutiner i DDL til at få adgang til tabellen. Sådanne DDL er forbundet med databasen, men er faktisk ikke en del af den.
Med andre ord opbevarer SQL Server ikke kun tabeller og indekser i hukommelsen, men også DDL for at få adgang til og ændre disse strukturer. Når en tabel er blevet ændret, skal SQL Server genskabe alle DDL til tabeloperationer. Det er derfor, du ikke kan ændre en tabel, når den først er oprettet. Disse handlinger er usynlige for brugerne.
Native kompilerede lagrede procedurer
Den bedste ydeevne opnås, mens der bruges native kompilerede lagrede procedurer til at få adgang til native kompilerede tabeller. Sådanne procedurer indeholder processorinstruktioner og kan udføres direkte af CPU uden yderligere kompilering. Der er dog nogle begrænsninger på T-SQL-konstruktionerne for de oprindeligt kompilerede lagrede procedurer (sammenlignet med traditionelt fortolket kode). Et andet væsentligt punkt er, at native kompilerede lagrede procedurer kun kan få adgang til hukommelsesoptimerede tabeller.
Ingen låse
In-Memory OLTP er et låsefrit system. Dette er muligt, fordi SQL Server aldrig ændrer nogen eksisterende række. OPDATERING-operationen opretter den nye version og markerer den tidligere version som slettet. Derefter indsætter den en ny rækkeversion med nye data indeni.
Indekser
Som du måske har gættet, er indekser meget anderledes end de traditionelle. In-memory-optimerede tabeller har ingen sider. SQL Server bruger indekser til at forbinde alle rækker, der hører til en tabel, til en enkelt struktur. Vi kan ikke bruge CREATE INDEX-sætningen til at oprette et indeks for den in-memory-optimerede tabel. Når du har oprettet den PRIMÆR NØGLE på en kolonne, opretter SQL Server automatisk et unikt indeks på den kolonne. Faktisk er det det eneste tilladte unikke indeks. Du kan maksimalt oprette otte indekser på en hukommelsesoptimeret tabel.
Analogt med tabeller holder SQL Server hukommelsesoptimerede indekser i hukommelsen. SQL Server logger dog aldrig operationer på indekser. SQL Server vedligeholder indekser automatisk under tabelændringer.
Hukommelsesoptimerede tabeller understøtter to typer indekser:hash-indeks og områdeindeks . Begge er ikke-klyngede strukturer.
hash-indekset er en ny type indeks, designet specifikt til hukommelsesoptimerede tabeller. Det er yderst nyttigt til at udføre opslag på specifikke værdier. Selve indekset gemmes som en hash-tabel. Det er en række hash-buckets, hvor hver bucket er en pegepind til en enkelt række.
intervalindekset (ikke-grupperet) er nyttig til at hente værdiområder.
Gendannelse
Den grundlæggende gendannelsesmekanisme for en database med hukommelsesoptimerede tabeller er den samme som gendannelsesmekanismen for databaser med diskbaserede tabeller. Gendannelse af hukommelsesoptimerede tabeller inkluderer imidlertid trinnet at indlæse de hukommelsesoptimerede tabeller i hukommelsen, før databasen er tilgængelig for brugeradgang.
Når SQL Server genstarter, gennemgår hver database følgende faser af gendannelsesprocessen:analyse , gentag og fortryd .
I analysefasen identificerer In-Memory OLTP-motoren kontrolpunktopgørelsen, der skal indlæses, og forudindlæser dens systemtabellogposter. Det vil også behandle nogle filallokeringslogposter.
I genoptagefasen indlæses data fra data- og deltafilparrene i hukommelsen. Derefter opdateres dataene fra den aktive transaktionslog baseret på det sidste holdbare kontrolpunkt, og tabellerne i hukommelsen udfyldes og indekser genopbygges. I denne fase kører diskbaseret og hukommelsesoptimeret tabelgendannelse samtidigt.
Fortryd-fasen er ikke nødvendig for hukommelsesoptimerede tabeller, da In-Memory OLTP ikke registrerer nogen ikke-forpligtede transaktioner for hukommelsesoptimerede tabeller.
Når alle handlinger er udført, er databasen tilgængelig for adgang.
Oversigt
I denne artikel tog vi et hurtigt kig på SQL Server In-Memory OLTP-motoren. Vi har lært, at hukommelsesoptimerede strukturer er lagret i hukommelsen. Applikationsprocesser kan finde de nødvendige data ved at få adgang til disse strukturer i hukommelsen uden behov for disk I/O. I de følgende artikler vil vi tage et kig på, hvordan du opretter og får adgang til OLTP-databaser og -tabeller i hukommelsen.
Yderligere læsning
In-Memory OLTP:Hvad er nyt i SQL Server 2016
Brug af indekser i SQL Server-hukommelsesoptimerede tabeller