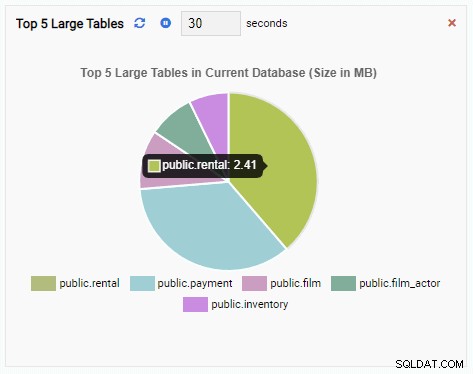
I en tidligere artikel i denne serie oprettede vi en to-node PostgreSQL 12-klynge i AWS-skyen. Vi installerede og konfigurerede også 2ndQuadrant OmniDB i en tredje node. Billedet nedenfor viser arkitekturen:
Vi kunne oprette forbindelse til både den primære og standby-knuden fra OmniDBs webbaserede brugergrænseflade. Vi gendannede derefter en prøvedatabase kaldet "dvdrental" i den primære node, som begyndte at replikere til standby.
I denne del af serien lærer vi, hvordan du opretter og bruger et overvågningsdashboard i OmniDB. DBA'er og driftsteams foretrækker ofte grafiske værktøjer frem for komplekse forespørgsler til visuelt at inspicere databasens sundhed. OmniDB kommer med en række vigtige widgets, der nemt kan bruges i et overvågningsdashboard. Som vi vil se senere, giver det også brugere mulighed for at skrive deres egne overvågnings-widgets.
Opbygning af et præstationsovervågnings-dashboard
Lad os starte med standarddashboardet, som OmniDB kommer med.
På billedet nedenfor er vi forbundet til den primære node (PG-Node1). Vi højreklikker på forekomstens navn, og vælger derefter "Monitor" fra pop op-menuen og vælger derefter "Dashboard".
Dette åbner et dashboard med nogle widgets i.
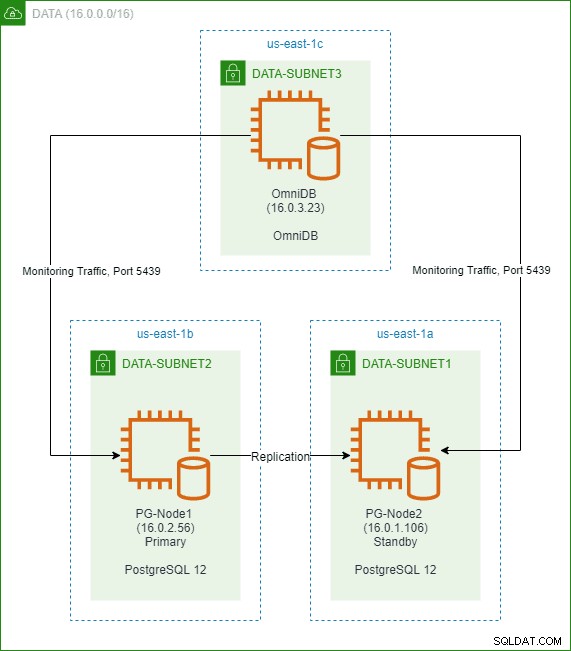
I OmniDB-termer kaldes de rektangulære widgets i dashboardet Monitoring Units . Hver af disse enheder viser en specifik metrik fra den PostgreSQL-instans, den er forbundet til, og opdaterer dens data dynamisk.
Forstå overvågningsenheder
OmniDB leveres med fire typer overvågningsenheder:
- Et gitter er en tabelstruktur, der viser resultatet af en forespørgsel. For eksempel kan dette være outputtet af SELECT * FROM pg_stat_replication. Et gitter ser sådan ud:
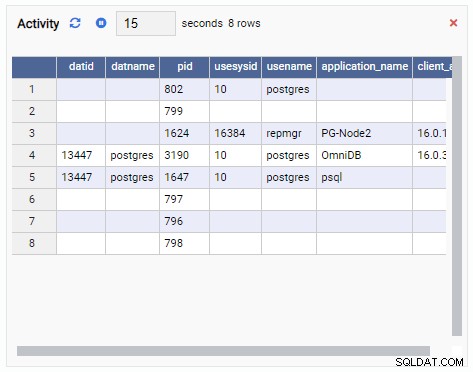
- Et diagram viser dataene i grafisk format, som linjer eller cirkeldiagrammer. Når det opdateres, tegnes hele diagrammet igen på skærmen med en ny værdi, og den gamle værdi er væk. Med disse overvågningsenheder kan vi kun se den aktuelle værdi af metrikken. Her er et eksempel på et diagram:
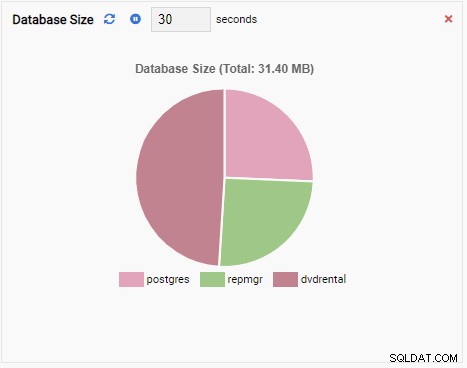
- En Tilføj til diagram er også en overvågningsenhed af diagramtype, undtagen når den opdateres, tilføjer den den nye værdi til den eksisterende serie. Med Chart-Append kan vi nemt se tendenser over tid. Her er et eksempel:
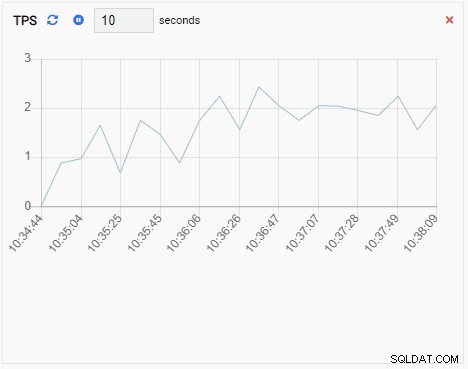
- En Graf viser relationer mellem PostgreSQL-klyngeforekomster og en tilhørende metrik. Ligesom diagramovervågningsenheden opdaterer en grafovervågningsenhed også sin gamle værdi med en ny. Billedet nedenfor viser den aktuelle node (PG-Node1) replikerer til PG-Node2:
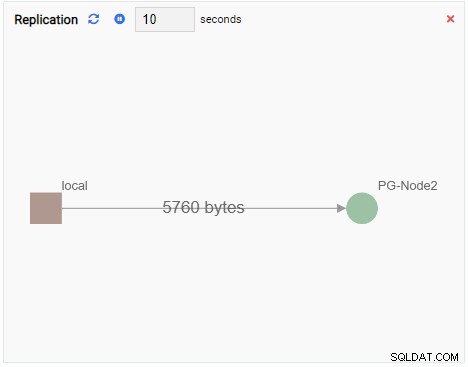
Hver overvågningsenhed har en række fælles elementer:
- Overvågningsenhedens navn
- En "opdater"-knap til manuelt at opdatere enheden
- En "pause"-knap for midlertidigt at stoppe overvågningsenheden i at opdatere
- En tekstboks, der viser det aktuelle opdateringsinterval. Dette kan ændres
- En "luk"-knap (rødt kryds) for at fjerne overvågningsenheden fra instrumentbrættet
- Overvågningens faktiske tegneområde
Forudbyggede overvågningsenheder
OmniDB kommer med en række overvågningsenheder til PostgreSQL, som vi kan tilføje til vores dashboard. For at få adgang til disse enheder klikker vi på knappen "Administrer enheder" øverst på dashboardet:
Dette åbner listen "Administrer enheder":
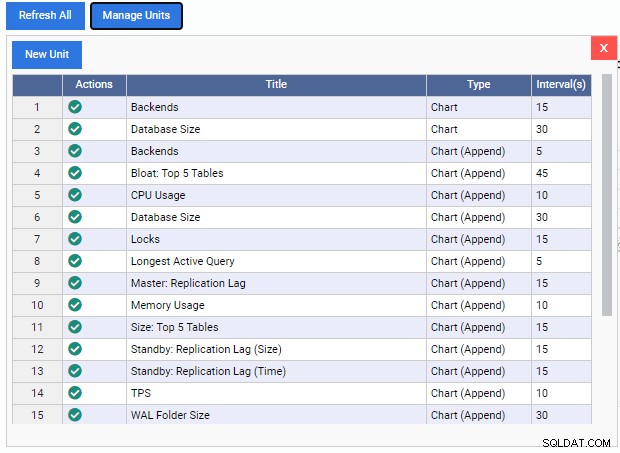
Som vi kan se, er der få præbyggede overvågningsenheder her. Koderne til disse overvågningsenheder kan frit downloades fra 2ndQuadrants GitHub-repo. Hver enhed, der er anført her, viser dens navn, type (Chart, Chart Append, Graph eller Grid) og standardopdateringshastigheden.
For at tilføje en overvågningsenhed til dashboardet skal vi blot klikke på det grønne flueben under kolonnen "Handlinger" for den pågældende enhed. Vi kan blande og matche forskellige overvågningsenheder for at bygge det dashboard, vi ønsker.
På billedet nedenfor har vi tilføjet følgende enheder til vores præstationsovervågnings-dashboard og fjernet alt andet:
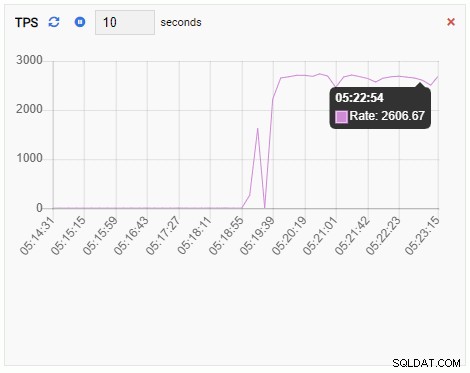
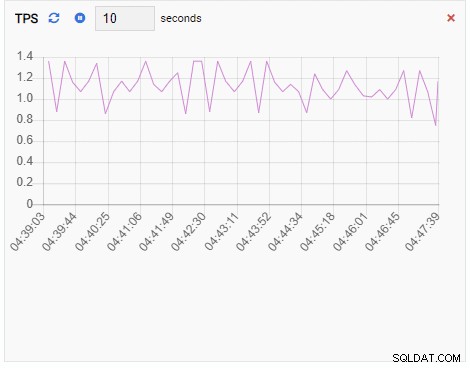
TPS (transaktion pr. sekund):
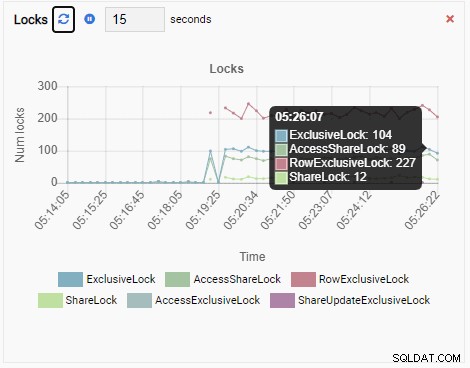
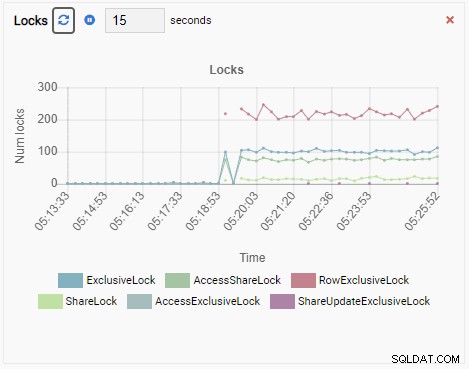
Antal låse:
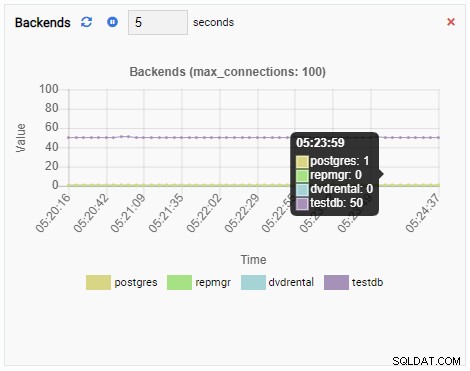
Antal backends:
Da vores instans er inaktiv, kan vi se værdierne for TPS, Locks og Backends er minimale.
Test af overvågningsdashboardet
Vi vil nu køre pgbench i vores primære node (PG-Node1). pgbench er et simpelt benchmarkingværktøj, der leveres med PostgreSQL. Som de fleste andre værktøjer af sin art opretter pgbench et eksempel på OLTP-systemers skema og tabeller i en database, når det initialiseres. Derefter kan den emulere flere klientforbindelser, der hver kører et antal transaktioner på databasen. I dette tilfælde vil vi ikke benchmarke PostgreSQL primære node; vi vil kun oprette databasen for pgbench og se, om vores dashboard-overvågningsenheder opfanger ændringen i systemtilstand.
Først opretter vi en database til pgbench i den primære node:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
Dernæst initialiserer vi "testdb"-databasen for pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbdropper gamle tabeller...opretter tabeller...genererer data...100000 af 2000000 tupler (5%) udførte (forløbet 0,02 s, resterende 0,43 s)200000 af 2000000 tupler (10%) udførte (forløbet 0,05 s, resterende 0,41 s)...00002 0002 s)...0000 s)... færdig (forløbet 1,84 s, resterende 0,00 s) støvsugning...oprettelse af primærnøgler...færdig.
Med databasen initialiseret starter vi nu selve indlæsningsprocessen. I kodestykket nedenfor beder vi pgbench om at starte med 50 samtidige klientforbindelser mod testdb-databasen, hvor hver forbindelse kører 100.000 transaktioner på sine tabeller. Belastningstesten vil køre på tværs af to tråde.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstarter vakuum...end.……Hvis vi nu går tilbage til vores OmniDB-dashboard, ser vi, at overvågningsenhederne viser nogle meget forskellige resultater.
TPS-metrikken viser ret høj værdi. Der er et pludseligt spring fra mindre end 2 til mere end 2000:
Antallet af backends er steget. Som forventet har testdb 50 forbindelser mod sig, mens andre databaser er inaktive:
Og endelig er antallet af rækkeeksklusive låse i testdb-databasen også højt:
Forestil dig nu dette. Du er en DBA, og du bruger OmniDB til at administrere en flåde af PostgreSQL-instanser. Du bliver ringet op til at undersøge langsom ydeevne i et af tilfældene.
Ved at bruge et dashboard som det, vi lige har set (selvom det er meget simpelt), kan du nemt finde årsagen. Du kan tjekke antallet af backends, låse, tilgængelig hukommelse osv. for at se, hvad der forårsager problemet.
Og det er her, OmniDB kan være et virkelig nyttigt værktøj.
Oprettelse af brugerdefinerede overvågningsenheder
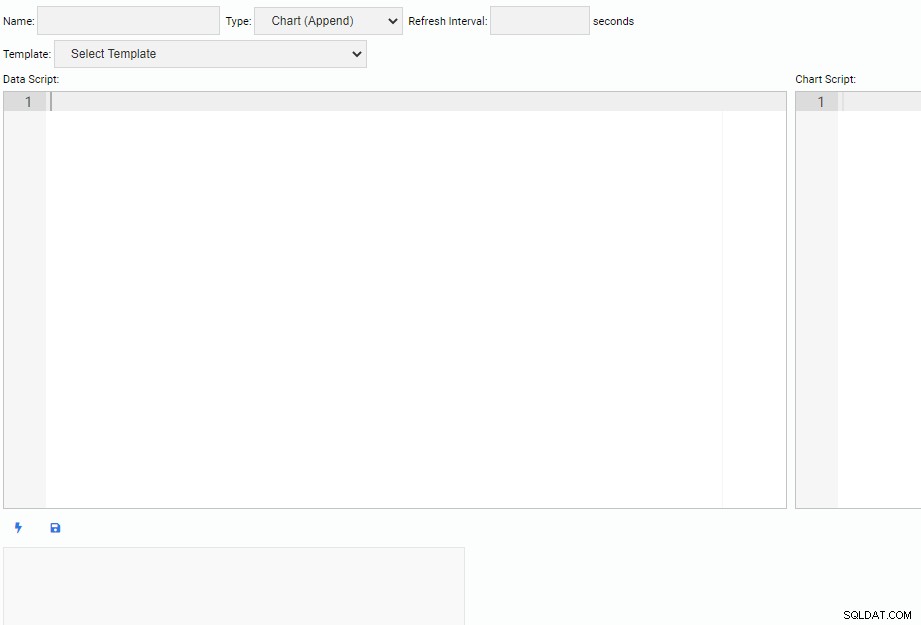
Nogle gange bliver vi nødt til at oprette vores egne overvågningsenheder. For at skrive en ny overvågningsenhed klikker vi på knappen "Ny enhed" på listen "Administrer enheder". Dette åbner en ny fane med et tomt lærred til at skrive kode:
Øverst på skærmen skal vi angive et navn til vores overvågningsenhed, vælge dens type og angive standard opdateringsinterval. Vi kan også vælge en eksisterende enhed som skabelon.
Under overskriftssektionen er der to tekstbokse. "Data Script"-editoren er, hvor vi skriver kode for at få data til vores overvågningsenhed. Hver gang en enhed opdateres, kører datascriptkoden. "Chart Script"-editoren er, hvor vi skriver kode til at tegne den faktiske enhed. Dette køres, når enheden tegnes første gang.
Al datascriptkode er skrevet i Python. For diagramtypens overvågningsenhed skal OmniDB have diagramscriptet skrevet i Chart.js.
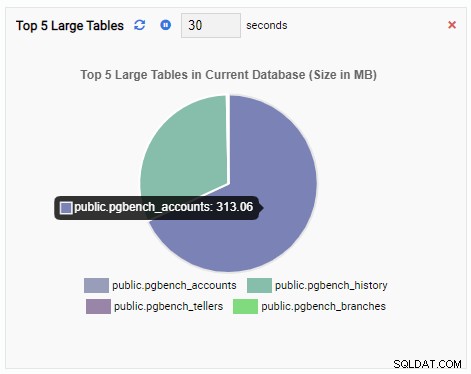
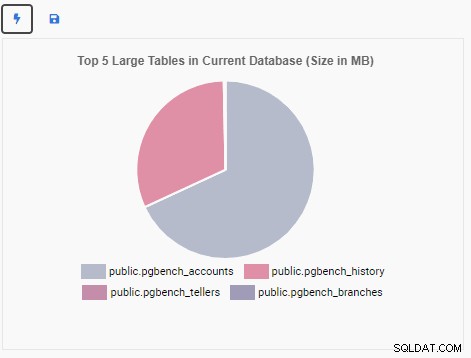
Vi vil nu oprette en overvågningsenhed for at vise top 5 store tabeller i den aktuelle database. Baseret på den database, der er valgt i OmniDB, vil overvågningsenheden ændre sin visning, så den afspejler navnene på de fem største tabeller i databasen.
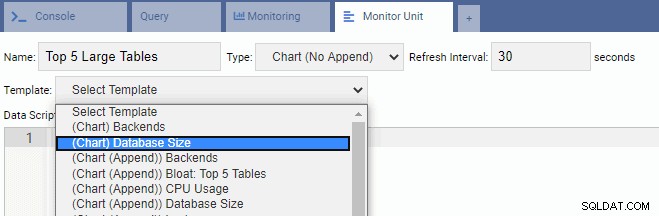
For at skrive en ny enhed er det bedst at starte med en eksisterende skabelon og ændre dens kode. Dette vil spare både tid og kræfter. På det følgende billede har vi navngivet vores overvågningsenhed "Top 5 store borde". Vi har valgt det til at være af diagramtypen (ingen tilføjelse) og har givet en opdateringshastighed på 30 sekunder. Vi har også baseret vores overvågningsenhed på skabelonen for databasestørrelse:
Data Script-tekstboksen udfyldes automatisk med koden for Database Size Monitoring Unit:
from datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS datname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size _ fROM pg database. FROM pgHERE catalog. datname not in ('template0','template1')''')data =[]farve =[]label =[]for db i databaser.Rækker: data.append(db["size") color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =forbindelse.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FRA pg_catalog.pg_database Hvor IKKE kataloget') resultat'abel'l') resultat' ":etiket, "datasæt":[ { "data":data, "baggrundsfarve:farve, "etiket":"Datasæt 1" "MB)"}Og Chart Script-tekstboksen er også udfyldt med kode:
total_size =forbindelse.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FRA pg_catalog.pg_database Hvor IKKE datistemplate'' ') resultat"":" , "data":Ingen, "options":{ "responsive":True, "title":{ "display":True, "tekst":"Databasestørrelse (total:basestørrelse) (total:"_) } }}Vi kan modificere datascriptet for at få de 5 bedste store tabeller i databasen. I scriptet nedenfor har vi beholdt det meste af den originale kode, undtagen SQL-sætningen:
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" FRA pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) HVOR nspname NOT IN ('pg_catalog', 'information_schema') OG C.relkind <> 'i' AND nspname !~ '^pg_DER to BY 2 DESC LIMIT 5;''')data =[]color =[]label =[]for tabel i tabeller. Rækker: data.append(tabel["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(tabel["tabelnavn" ])result ={ "etiketter":etiket, "datasæt":[ { "data":data, "baggrundsfarve:farve, ”label” 5Her får vi den kombinerede størrelse af hver tabel og dens indekser i den aktuelle database. Vi sorterer resultaterne i faldende rækkefølge og vælger de øverste fem rækker.
Dernæst udfylder vi tre Python-arrays ved at iterere over resultatsættet.
Til sidst bygger vi en JSON-streng baseret på arrayernes værdier.
I Chart Script-tekstboksen har vi ændret koden for at fjerne den originale SQL-kommando. Her specificerer vi kun det kosmetiske aspekt af diagrammet. Vi definerer diagrammet som cirkeltype og giver det en titel:
result ={ "type":"pie", "data":Ingen, "options":{ "responsive":Sand, "title":{ "display":True, " Tabeller i den aktuelle database (størrelse i MB)" } }}Nu kan vi teste enheden ved at klikke på lynikonet. Dette vil vise den nye overvågningsenhed i preview-tegneområdet:
Dernæst gemmer vi enheden ved at klikke på diskikonet. En beskedboks bekræfter, at enheden er blevet gemt:
Vi går nu tilbage til vores overvågningsdashboard og tilføjer den nye overvågningsenhed:
Bemærk, hvordan vi har yderligere to ikoner under kolonnen "Handlinger" for vores tilpassede overvågningsenhed. Den ene er til at redigere den, den anden er til at fjerne den fra OmniDB.
Overvågningsenheden "Top 5 store tabeller" viser nu de fem største tabeller i den aktuelle database:
Hvis vi lukker dashboardet, skifter til en anden database fra navigationsruden og åbner dashboardet igen, vil vi se, at overvågningsenheden er ændret for at afspejle tabellerne i den database:
Afsluttende ord
Dette afslutter vores todelte serie om OmniDB. Som vi så, har OmniDB nogle smarte overvågningsenheder, som PostgreSQL DBA'er vil finde nyttige til præstationssporing. Vi så, hvordan vi kan bruge disse enheder til at identificere potentielle flaskehalse i serveren. Vi så også, hvordan man laver vores egne brugerdefinerede enheder. Læsere opfordres til at oprette og teste præstationsovervågningsenheder for deres specifikke arbejdsbelastninger. 2ndQuadrant glæder sig over ethvert bidrag til OmniDB Monitoring Unit GitHub repo.