Mens du justerer postgresql.conf , har du måske bemærket, at der er en mulighed kaldet full_page_writes . Kommentaren ved siden af siger noget om delvis sideskrivning, og folk lader den generelt være indstillet til on – hvilket er en god ting, som jeg vil forklare senere i dette indlæg. Det er dog nyttigt at forstå, hvad helsideskrivninger gør, fordi indvirkningen på ydeevnen kan være ret betydelig.
I modsætning til mit tidligere indlæg om checkpoint tuning, er dette ikke en guide til hvordan man tuner serveren. Der er egentlig ikke meget, du kan justere, men jeg vil vise dig, hvordan nogle beslutninger på applikationsniveau (f.eks. valg af datatyper) kan interagere med helsideskrivninger.
Delvis skrivning / revet sider
Så hvad skriver helside om? Som kommentaren i postgresql.conf siger, at det er en måde at komme sig efter delvis sideskrivning - PostgreSQL bruger 8 kB sider (som standard), men andre dele af stakken bruger forskellige chunkstørrelser. Linux-filsystemer bruger typisk 4kB sider (det er muligt at bruge mindre sider, men 4kB er maks. på x86), og på hardwareniveau brugte de gamle drev 512B sektorer, mens nye enheder ofte skriver data i større bidder (ofte 4kB eller endda 8kB) .
Så når PostgreSQL skriver 8kB-siden, kan de andre lag af lagerstakken opdele dette i mindre bidder, administreret separat. Dette giver et problem med hensyn til skriveatomicitet. 8kB PostgreSQL-siden kan opdeles i to 4kB filsystemsider og derefter i 512B-sektorer. Hvad nu hvis serveren går ned (strømsvigt, kernefejl, …)?
Selvom serveren bruger et lagersystem, der er designet til at håndtere sådanne fejl (SSD'er med kondensatorer, RAID-controllere med batterier, …), opdeler kernen allerede dataene i 4kB-sider. Så det er muligt, at databasen skrev 8 kB dataside, men kun en del af det kom på disk før nedbruddet.
På dette tidspunkt tænker du nu sikkert, at det er præcis derfor, vi har transaktionslog (WAL), og du har ret! Så efter at have startet serveren, vil databasen læse WAL (siden det sidste afsluttede kontrolpunkt) og anvende ændringerne igen for at sikre, at datafilerne er komplette. Simpelt.
Men der er en hage - gendannelsen anvender ikke ændringerne blindt, den skal ofte læse datasiderne osv. Hvilket forudsætter, at siden ikke allerede er boret på en eller anden måde, for eksempel på grund af en delvis skrivning. Hvilket virker en smule selvmodsigende, for for at rette datakorruption antager vi, at der ikke er nogen datakorruption.
Helsideskrivning er en vej rundt om denne gåde - når du ændrer en side for første gang efter et kontrolpunkt, skrives hele siden ind i WAL. Dette garanterer, at den første WAL-record, der berører en side under gendannelse, indeholder hele siden, hvilket eliminerer behovet for at læse den – muligvis ødelagte – side fra datafilen.
Skriveforstærkning
Selvfølgelig er den negative konsekvens af dette øget WAL-størrelse - ændring af en enkelt byte på 8kB-siden vil logge hele ind i WAL. Helsideskrivningen sker kun ved den første skrivning efter et checkpoint, så at gøre checkpoints mindre hyppige er en måde at forbedre situationen på – typisk er der et kort "burst" af helsidesskrivninger efter et checkpoint, og så er relativt få helsideskrivninger indtil slutningen af et kontrolpunkt.
UUID vs. BIGSERIAL-nøgler
Men der er nogle uventede interaktioner med designbeslutninger truffet på applikationsniveau. Lad os antage, at vi har en simpel tabel med primær nøgle, enten en BIGSERIAL eller UUID , og vi indsætter data i det. Vil der være en forskel i mængden af genereret WAL (forudsat at vi indsætter det samme antal rækker)?
Det virker rimeligt at forvente, at begge tilfælde producerer omtrent den samme mængde WAL, men som de følgende diagrammer illustrerer, er der en enorm forskel i praksis.
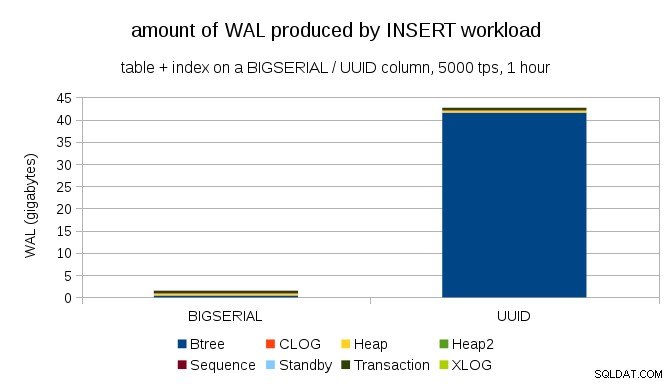
Dette viser mængden af WAL, der produceres i løbet af en 1-times benchmark, droslet til 5000 indsatser i sekundet. Med BIGSERIAL primær nøgle producerer ~2GB WAL, mens med UUID det er mere end 40 GB. Det er en ganske væsentlig forskel, og helt klart er det meste af WAL forbundet med indeksunderstøttelse af den primære nøgle. Lad os se som typer af WAL-poster.
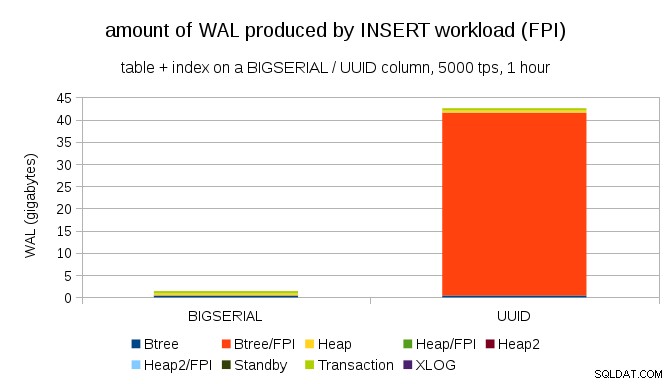
Det er klart, at langt størstedelen af optegnelserne er helsidesbilleder (FPI), dvs. resultatet af helsidesskrivninger. Men hvorfor sker det?
Dette skyldes selvfølgelig den iboende UUID tilfældighed. Med BIGSERIAL nye er sekventielle, og bliver derfor indsat på de samme bladsider i btree-indekset. Da kun den første ændring af en side udløser helsidesskrivning, er kun en lille brøkdel af WAL-posterne FPI'er. Med UUID det er selvfølgelig en helt anden sag – værdierne er slet ikke sekventielle, faktisk vil hver indsættelse sandsynligvis røre en helt ny bladindeksbladside (forudsat at indekset er stort nok).
Der er ikke meget databasen kan gøre - arbejdsbyrden er simpelthen tilfældig af natur, hvilket udløser mange helsidesskrivninger.
Det er ikke svært at få lignende skriveforstærkning selv med BIGSERIAL nøgler, selvfølgelig. Det kræver kun en anden arbejdsbyrde – for eksempel med UPDATE arbejdsbelastning, tilfældig opdatering af poster med ensartet fordeling, ser diagrammet således ud:
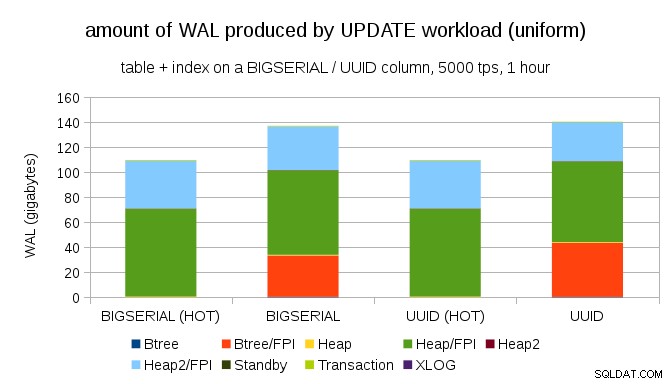
Pludselig er forskellene mellem datatyper væk - adgangen er tilfældig i begge tilfælde, hvilket resulterer i næsten nøjagtig samme mængde WAL produceret. En anden forskel er, at det meste af WAL er forbundet med "heap", dvs. tabeller, og ikke indekser. "HOT" sagerne blev designet til at tillade HOT UPDATE-optimering (dvs. opdatering uden at skulle røre et indeks), hvilket stort set eliminerer al indeksrelateret WAL-trafik.
Men du vil måske hævde, at de fleste applikationer ikke opdaterer hele datasættet. Normalt er kun en lille delmængde af data "aktiv" - folk får kun adgang til indlæg fra de sidste par dage på et diskussionsforum, uafklarede ordrer i en e-butik osv. Hvordan ændrer det resultaterne?
Heldigvis understøtter pgbench ikke-ensartede fordelinger, og for eksempel med eksponentiel fordeling, der berører 1 % delmængde af data ~25 % af tiden, ser diagrammet sådan ud:
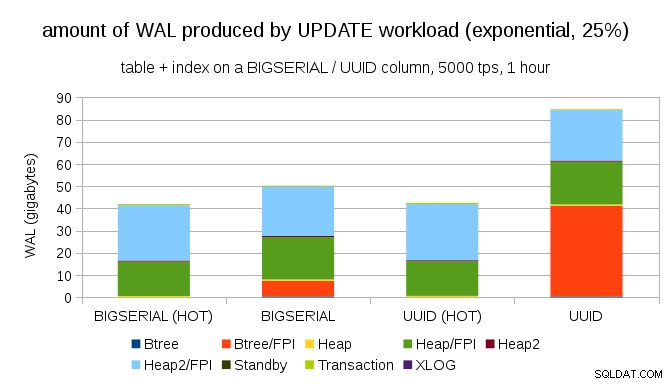
Og efter at have gjort fordelingen endnu mere skæv, ved at røre ved 1 %-delmængden ~75 % af tiden:
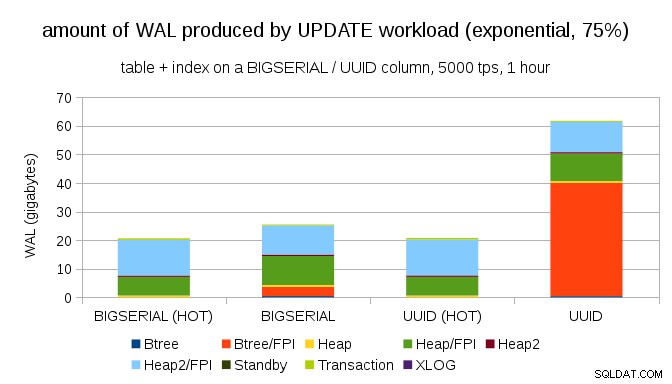
Dette viser igen, hvor stor forskel valget af datatyper kan gøre, og også vigtigheden af at tune til HOT opdateringer.
8 kB og 4 kB sider
Et interessant spørgsmål er, hvor meget WAL-trafik vi kan spare ved at bruge mindre sider i PostgreSQL (hvilket kræver kompilering af en tilpasset pakke). I bedste tilfælde kan det spare op til 50 % WAL, takket være kun at logge 4kB i stedet for 8kB sider. For arbejdsbyrden med ensartet fordelte OPDATERINGER ser det sådan ud:
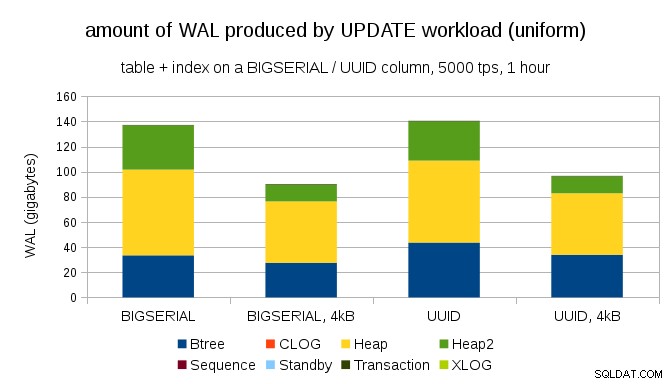
Så besparelsen er ikke ligefrem 50 %, men reduktionen fra ~140GB til ~90GB er stadig ret betydelig.
Har vi stadig brug for helsidesskrivninger?
Det kan virke som en latterlig efter at have forklaret faren ved delvise skrivninger, men måske kan deaktivering af helsideskrivning være en levedygtig mulighed, i det mindste i nogle tilfælde.
For det første spekulerer jeg på, om moderne Linux-filsystemer stadig er sårbare over for delvise skrivninger? Parameteren blev introduceret i PostgreSQL 8.1 udgivet i 2005, så måske nogle af de mange filsystemforbedringer, der er introduceret siden da, gør dette til et ikke-problem. Sandsynligvis ikke universelt for vilkårlige arbejdsbelastninger, men måske ville det være tilstrækkeligt at antage en yderligere betingelse (f.eks. brug af 4 kB sidestørrelse i PostgreSQL)? PostgreSQL overskriver heller aldrig kun en delmængde af siden på 8 kB – hele siden skrives altid ud.
Jeg har lavet en masse tests for nylig for at udløse en delvis skrivning, og det er endnu ikke lykkedes mig at forårsage et eneste tilfælde. Selvfølgelig er det ikke et rigtigt bevis på, at problemet ikke eksisterer. Men selvom det stadig er et problem, kan datakontrolsummer være tilstrækkelig beskyttelse (det løser ikke problemet, men vil i det mindste fortælle dig, at der er en ødelagt side).
For det andet er mange systemer i dag afhængige af streaming-replikeringsreplikaer – i stedet for at vente på, at serveren genstarter efter et hardwareproblem (som kan tage ret lang tid) og derefter bruge mere tid på at udføre gendannelse, skifter systemerne blot til en varm standby. Hvis databasen på den mislykkede primære fjernes (og derefter klones fra den nye primære), er delvis skrivning et ikke-problem.
Men jeg gætter på, at hvis vi begyndte at anbefale det, så "Jeg ved ikke, hvordan dataene blev ødelagt, jeg har lige sat full_page_writes=off på systemerne!" ville blive en af de mest almindelige sætninger lige før døden for DBA'er (sammen med "Jeg har set denne slange på reddit, den er ikke giftig.").
Oversigt
Der er ikke meget, du kan gøre for at tune helsidesskrivninger direkte. For de fleste arbejdsbelastninger sker de fleste helsidesskrivninger lige efter et kontrolpunkt og forsvinder derefter indtil det næste kontrolpunkt. Så det er vigtigt at indstille kontrolpunkter, så de ikke sker for ofte.
Nogle beslutninger på applikationsniveau kan øge tilfældigheden af skrivninger til tabeller og indekser - for eksempel er UUID-værdier i sagens natur tilfældige, hvilket gør selv simpel INSERT-arbejdsbelastning til tilfældige indeksopdateringer. Skemaet brugt i eksemplerne var ret trivielt – i praksis vil der være sekundære indekser, fremmednøgler osv. Men at bruge BIGSERIAL primære nøgler internt (og beholde UUID'en som surrogatnøgler) ville i det mindste reducere skriveforstærkningen.
Jeg er virkelig interesseret i diskussion om behovet for helsidesskrivninger på nuværende kerner / filsystemer. Desværre har jeg ikke fundet mange ressourcer, så hvis du har relevant information, så lad mig det vide.