Som vi for nylig har annonceret, har ClusterControl 1.7.4 en ny funktion kaldet Cluster-to-Cluster Replication. Det giver dig mulighed for at have en replikering kørende mellem to autonome klynger. For mere detaljeret information henvises til ovennævnte meddelelse.
Vi vil tage et kig på, hvordan man bruger denne nye funktion til en eksisterende PostgreSQL-klynge. Til denne opgave antager vi, at du har ClusterControl installeret, og at Master Cluster blev implementeret ved hjælp af det.
Krav til Master Cluster
Der er nogle krav til Master Cluster for at få det til at fungere:
- PostgreSQL 9.6 eller nyere.
- Der skal være en PostgreSQL-server med ClusterControl-rollen 'Master'.
- Når du konfigurerer slaveklyngen, skal administratoroplysningerne være identiske med masterklyngen.
Forberedelse af masterklyngen
Masterklyngen skal opfylde ovennævnte krav.
Angående det første krav, sørg for, at du bruger den korrekte PostgreSQL-version i Master Cluster og vælger det samme for Slave Cluster.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitHvis du har brug for at tildele masterrollen til en specifik node, kan du gøre det fra ClusterControl UI. Gå til ClusterControl -> Vælg Master Cluster -> Noder -> Vælg Node -> Node Actions -> Promote slave.
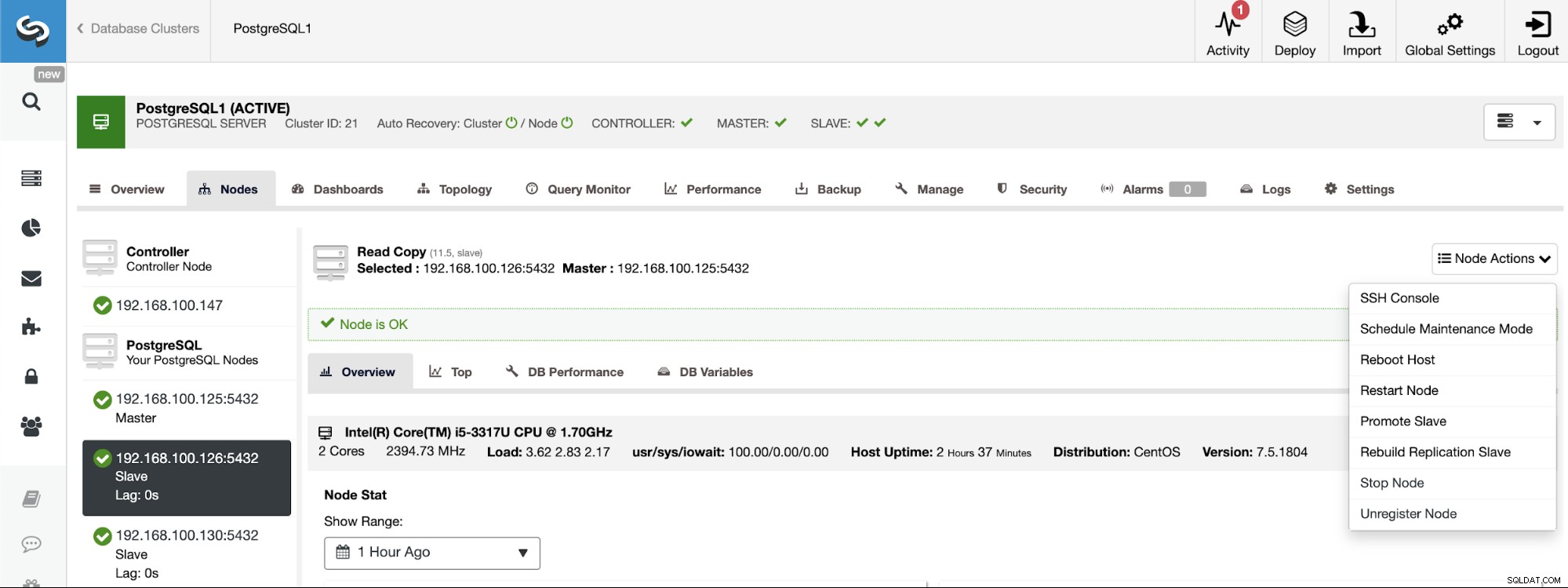
Og til sidst, under oprettelsen af slaveklyngen, skal du bruge den samme admin legitimationsoplysninger, som du i øjeblikket bruger i masterklyngen. Du vil se, hvor du kan tilføje det i det følgende afsnit.
Oprettelse af slaveklyngen fra ClusterControl UI
For at oprette en ny slaveklynge skal du gå til ClusterControl -> Vælg Cluster -> Cluster Actions -> Create Slave Cluster.
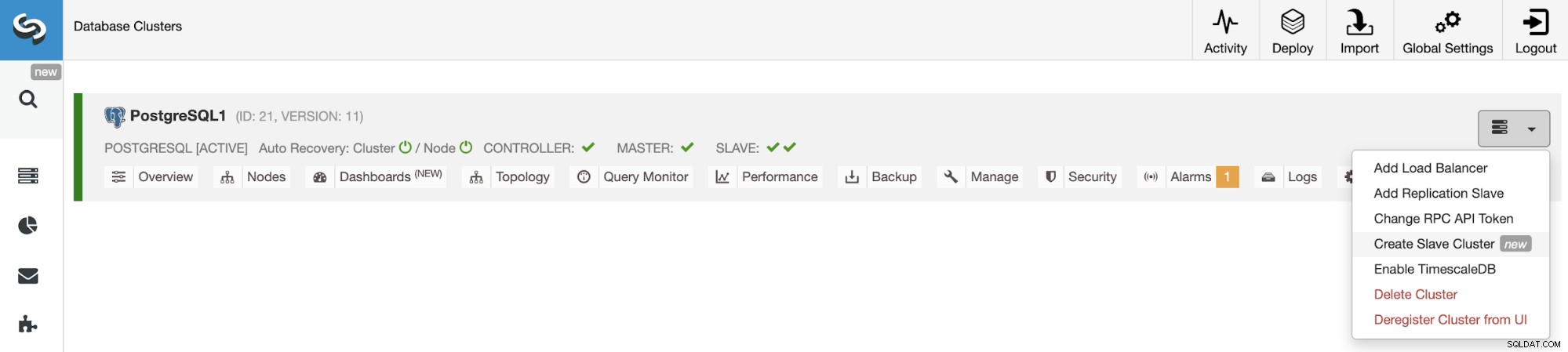
Slaveklyngen vil blive oprettet ved at streame data fra den aktuelle masterklynge.
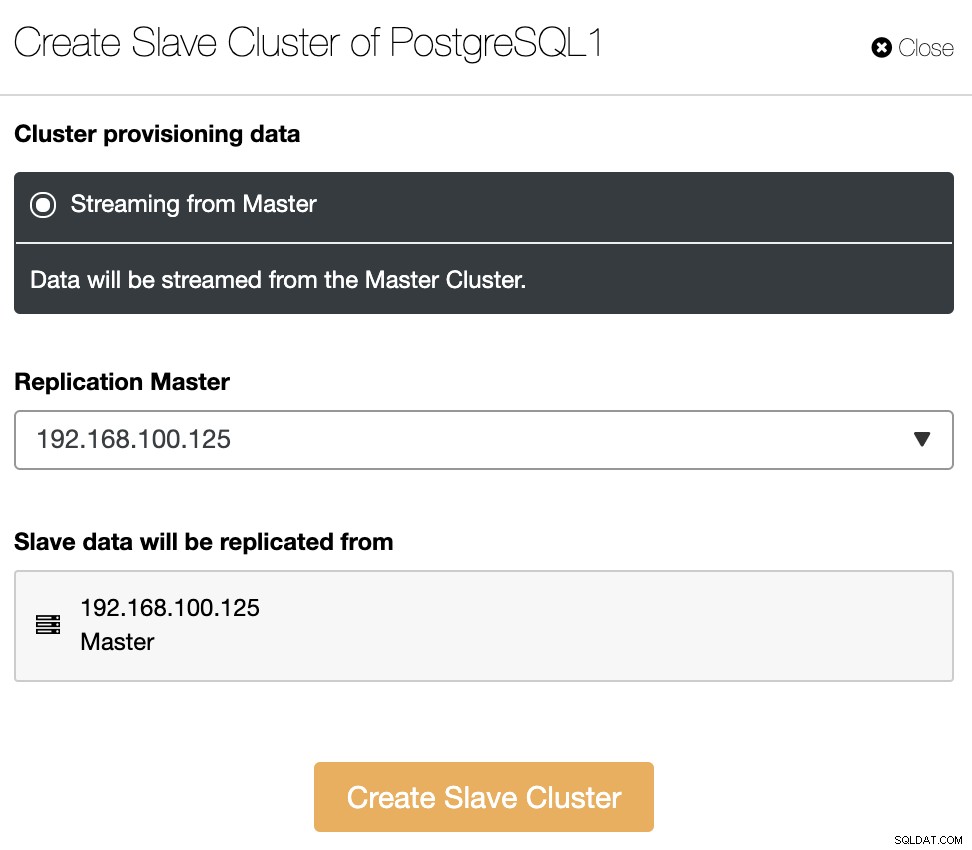
I dette afsnit skal du også vælge masterknudepunktet for den aktuelle klynge hvorfra dataene vil blive replikeret.
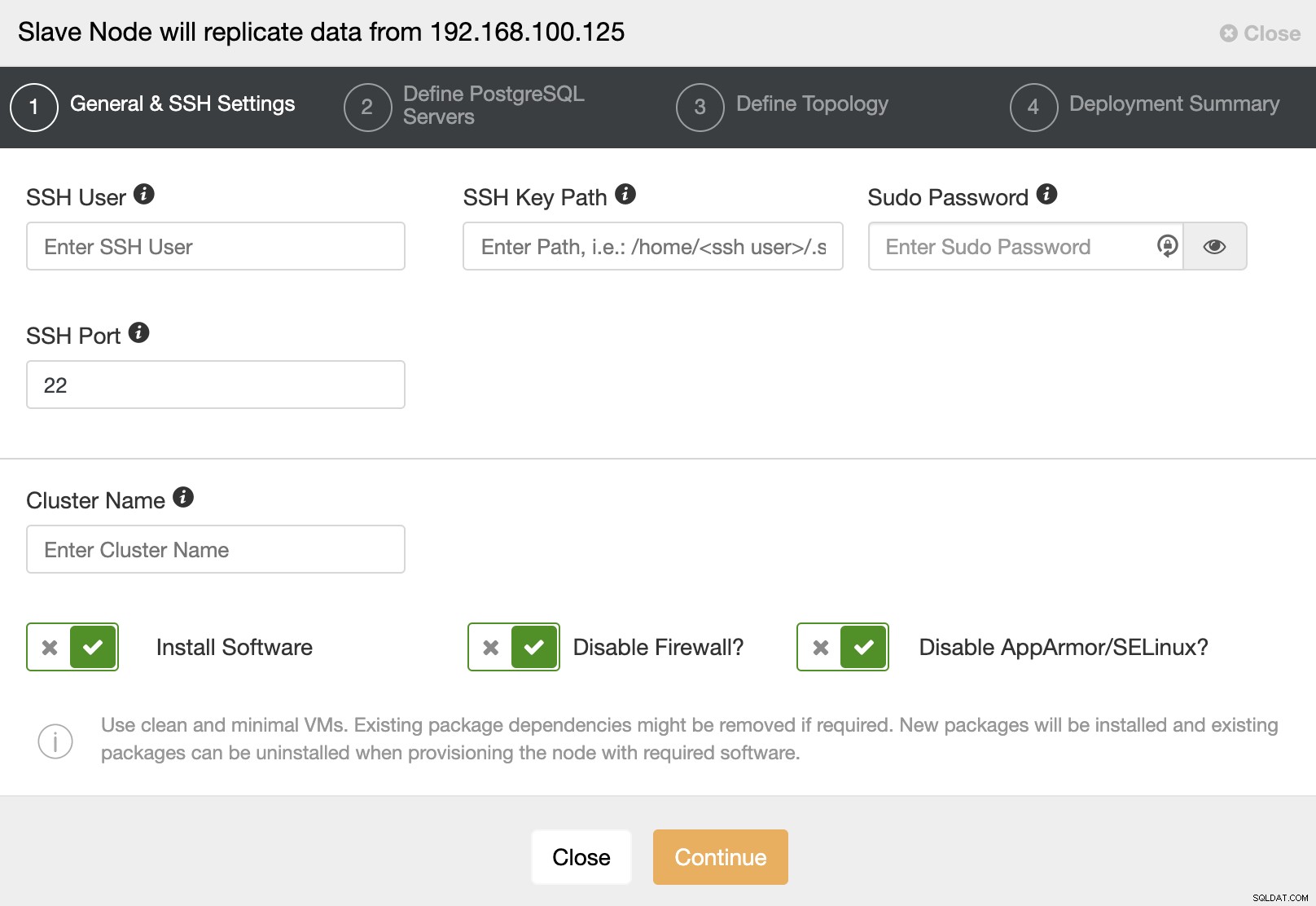
Når du går til næste trin, skal du angive Bruger, Nøgle eller Adgangskode og port for at forbinde med SSH til dine servere. Du skal også have et navn til din slaveklynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
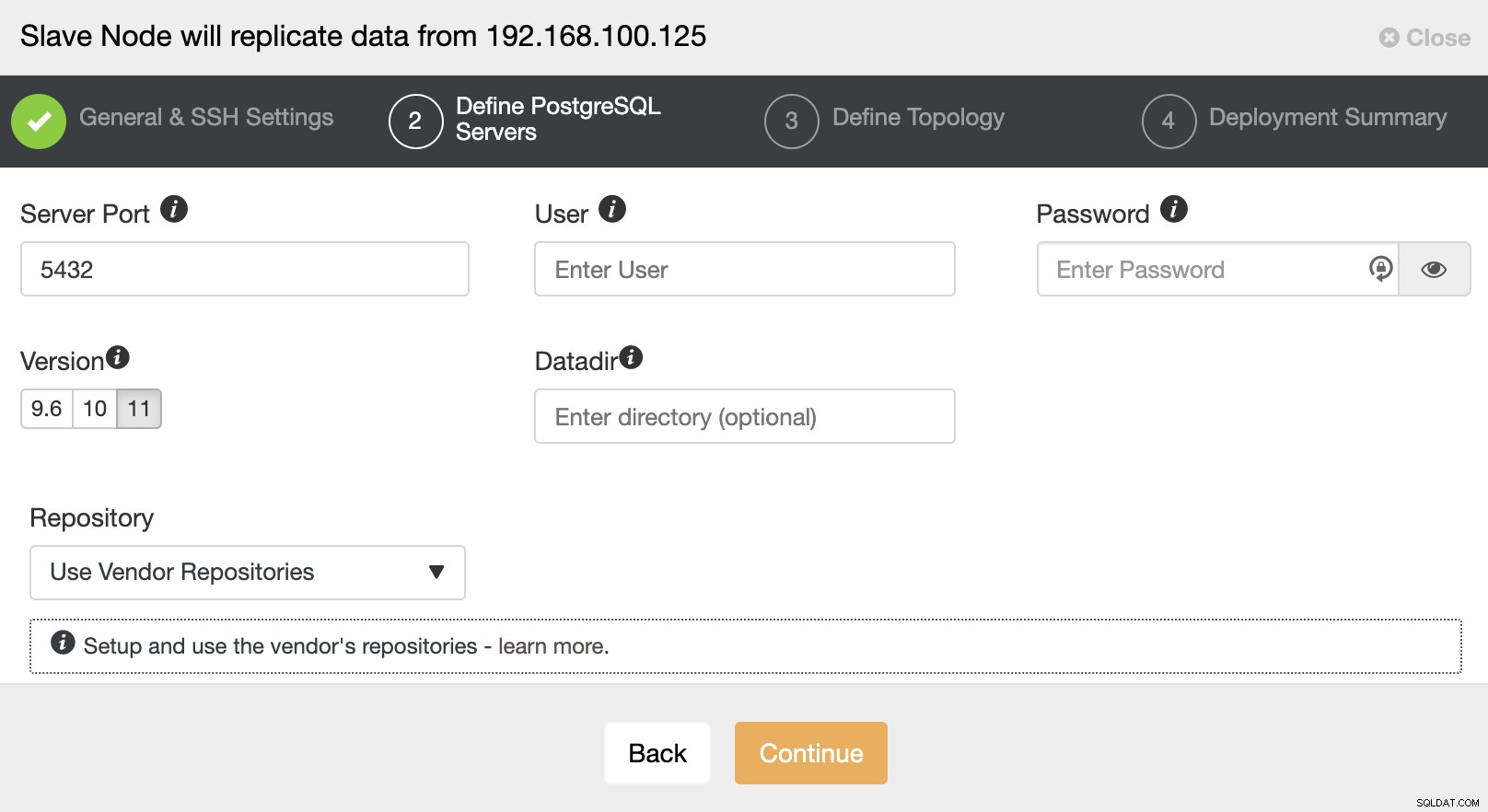
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaseversionen, datadir, port og administratorlegitimationsoplysninger. Da det vil bruge streamingreplikering, skal du sørge for at bruge den samme databaseversion, og som vi nævnte tidligere, skal legitimationsoplysningerne være de samme, som bruges af Master Cluster. Du kan også angive, hvilket lager der skal bruges.
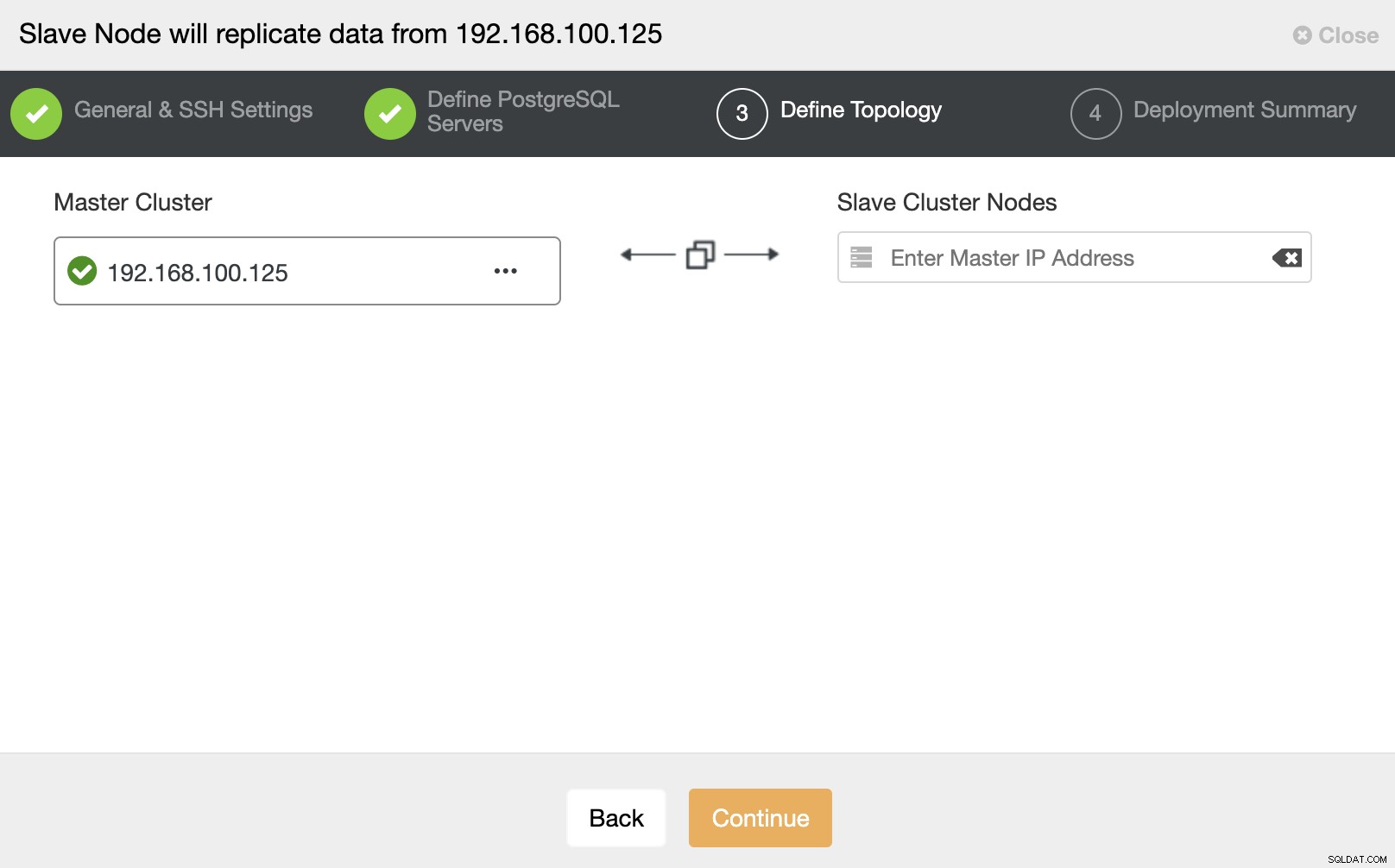
I dette trin skal du tilføje serveren til den nye slaveklynge . Til denne opgave kan du indtaste både IP-adresse eller værtsnavn for databasenoden.
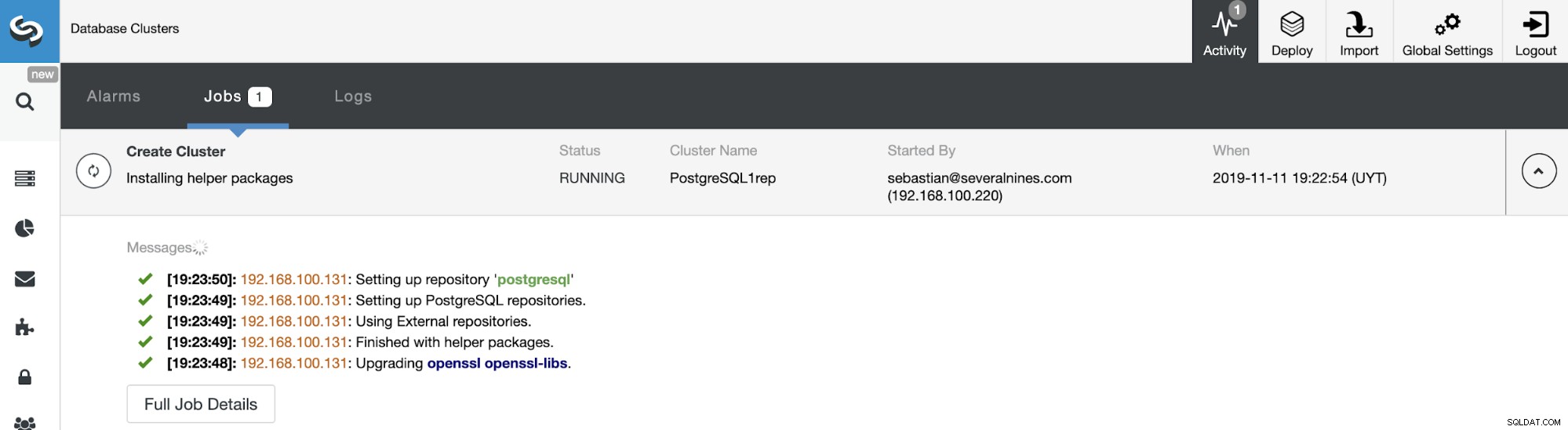
Du kan overvåge status for oprettelsen af din nye slaveklynge fra ClusterControl aktivitetsmonitor. Når opgaven er færdig, kan du se klyngen på hovedskærmen til ClusterControl.
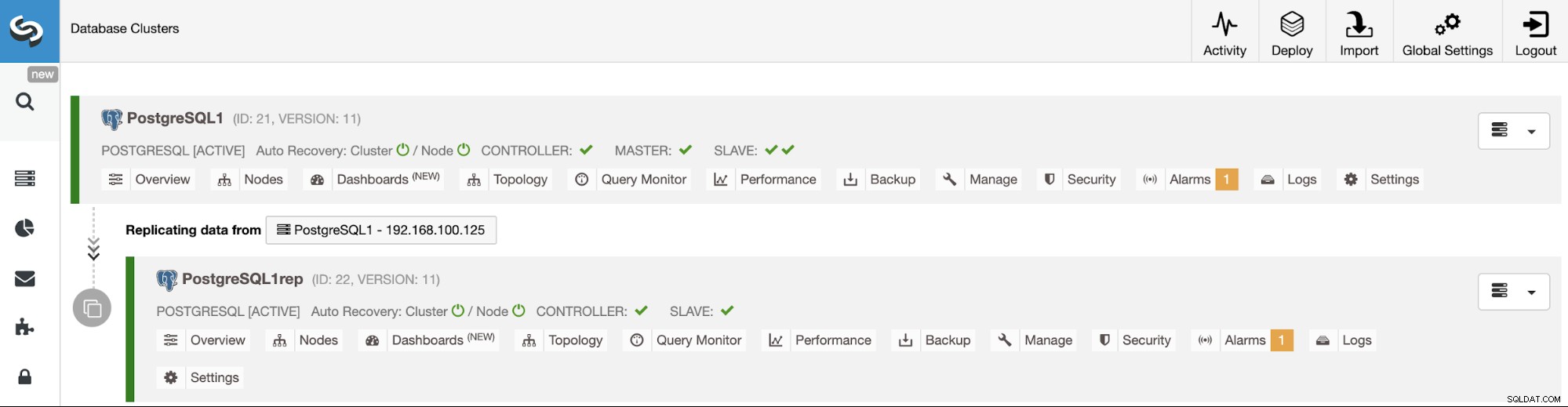
Administration af klynge-til-klynge-replikering ved hjælp af ClusterControl-brugergrænsefladen
Nu har du din klynge-til-klynge-replikering oppe at køre, og der er forskellige handlinger at udføre på denne topologi ved hjælp af ClusterControl.
Genopbygning af en slaveklynge
For at genopbygge en slaveklynge skal du gå til ClusterControl -> Vælg Slaveklynge -> Noder -> Vælg den node, der er forbundet til masterklyngen -> Nodehandlinger -> Genopbyg replikeringsslave.
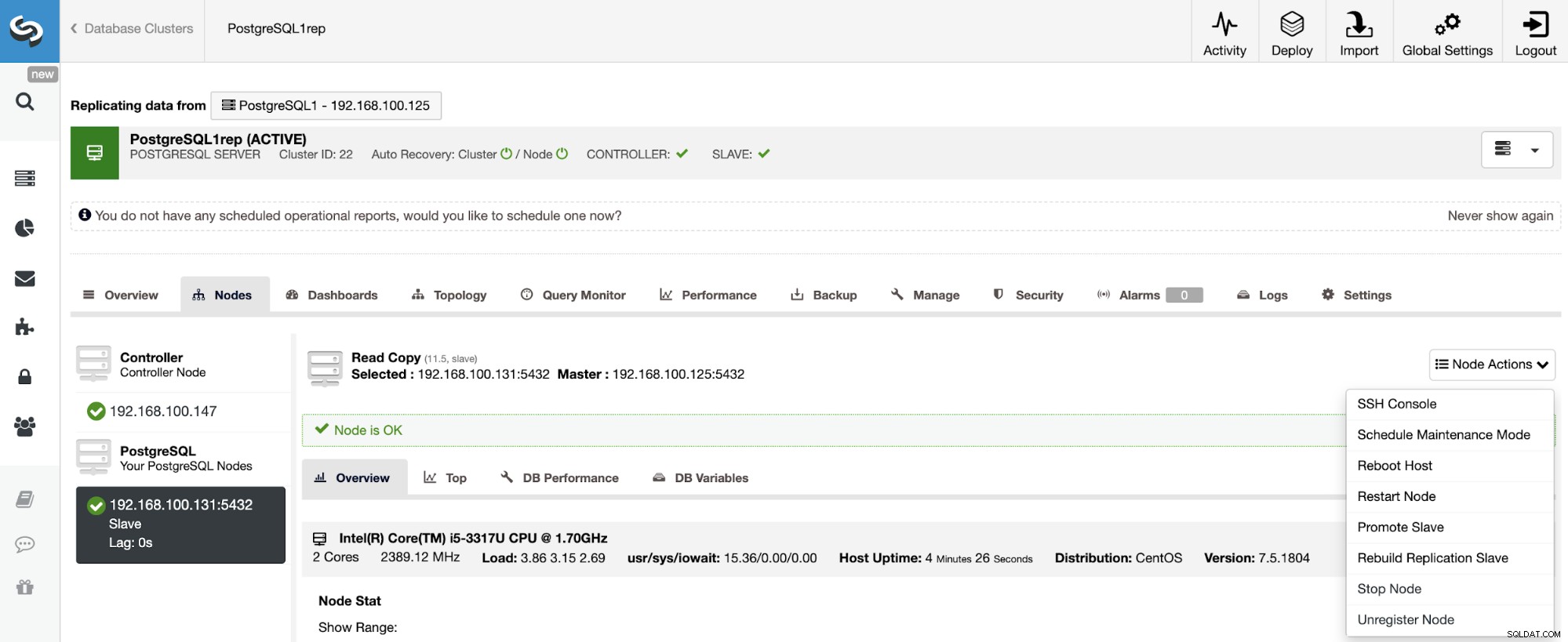
ClusterControl udfører følgende trin:
- Stop PostgreSQL Server
- Fjern indhold fra dets datadir
- Stream en sikkerhedskopi fra masteren til slaven ved hjælp af pg_basebackup
- Start slaven
Stop/start replikeringsslave
Stop og start replikering i PostgreSQL betyder pause og genoptag den, men vi bruger disse termer for at være i overensstemmelse med andre databaseteknologier, vi understøtter.
Denne funktion vil snart være tilgængelig til brug fra ClusterControl UI. Denne handling vil bruge funktionerne pg_wal_replay_pause og pg_wal_replay_resume PostgreSQL til at udføre denne opgave.
I mellemtiden kan du bruge en løsning til at stoppe og starte replikeringsslaven ved at stoppe og starte databasenoden på en nem måde ved hjælp af ClusterControl.
Gå til ClusterControl -> Vælg Slaveklynge -> Noder -> Vælg Node -> Node Actions -> Stop Node/Start Node. Denne handling vil stoppe/starte databasetjenesten direkte.
Håndtering af klynge-til-klynge-replikering ved hjælp af ClusterControl CLI
I det forrige afsnit kunne du se, hvordan du administrerer en Cluster-to-Cluster-replikering ved hjælp af ClusterControl-brugergrænsefladen. Lad os nu se, hvordan man gør det ved at bruge kommandolinjen.
Bemærk:Som vi nævnte i begyndelsen af denne blog, antager vi, at du har ClusterControl installeret, og at Master Cluster blev implementeret ved hjælp af det.
Opret slaveklyngen
Lad os først se en eksempelkommando til at oprette en slaveklynge ved at bruge ClusterControl CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logNu har du din oprettelsesslave-proces kørende, lad os se hver brugt parameter:
- Klynge:At liste og manipulere klynger.
- Opret:Opret og installer en ny klynge.
- Klyngenavn:Navnet på den nye slaveklynge.
- Klyngetype:Den type klynge, der skal installeres.
- Udbyder-version:Softwareversionen.
- Noder:Liste over de nye noder i slaveklyngen.
- Os-bruger:Brugernavnet til SSH-kommandoerne.
- Os-key-file:Nøglefilen, der skal bruges til SSH-forbindelse.
- Db-admin:Databaseadministratorens brugernavn.
- Db-admin-passwd:Adgangskoden til databaseadministratoren.
- Remote-cluster-id:Master Cluster ID for Cluster-to-Cluster-replikeringen.
- Log:Vent og overvåg jobmeddelelser.
Ved at bruge --log-flaget vil du være i stand til at se logfilerne i realtid:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Genopbygning af en slaveklynge
Du kan genopbygge en slaveklynge ved hjælp af følgende kommando:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logParametrene er:
- Replikering:Til at overvåge og kontrollere datareplikering.
- Stage:Fase/genopbygge en replikeringsslave.
- Master:Replikeringsmasteren i masterklyngen.
- Slave:Replikeringsslaven i slaveklyngen.
- Cluster-id:The Slave Cluster ID.
- Remote-cluster-id:Master Cluster ID.
- Log:Vent og overvåg jobmeddelelser.
Jobloggen skal ligne denne:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Stop/start replikeringsslave
Som vi nævnte i UI-afsnittet, betyder stop og start replikering i PostgreSQL pause og genoptag det, men vi bruger disse termer til at bevare paralleliteten med andre teknologier.
Du kan stoppe med at replikere dataene fra Master Cluster på denne måde:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logDu vil se dette:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().Og nu kan du starte det igen:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logSå du vil se:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Lad os nu tjekke de brugte parametre.
- Replikering:Til at overvåge og kontrollere datareplikering.
- Stop/Start:For at få slaven til at stoppe/begynde at replikere.
- Slave:Replikeringsslaveknuden.
- Klynge-id:ID'et for den klynge, hvori slaveknuden er.
- Log:Vent og overvåg jobmeddelelser.
Konklusion
Denne nye ClusterControl-funktion giver dig mulighed for hurtigt at opsætte replikering mellem forskellige PostgreSQL-klynger og administrere opsætningen på en nem og venlig måde. Severalnines udviklerteam arbejder på at forbedre denne funktion, så alle ideer eller forslag ville være meget velkomne.