Et af de primære krav til enhver database er at opnå skalerbarhed. Det kan kun opnås, hvis striden (låsningen) minimeres så meget som muligt, hvis den ikke fjernes samlet. Da læs/skriv/opdater/slet er nogle af de hyppigste operationer, der sker i databasen, så er det meget vigtigt for disse operationer at fortsætte samtidig uden at blive blokeret. For at opnå dette anvender de fleste af de store databaser en samtidighedsmodel kaldet Multi-Version Concurrency Control, hvilket reducerer stridigheder til et absolut minimumsniveau.
Hvad er MVCC
Multi Version Concurrency Control (her og frem MVCC) er en algoritme til at give fin samtidighedskontrol ved at vedligeholde flere versioner af det samme objekt, så LÆS- og SKRIV-handlingen ikke er i konflikt. Her betyder WRITE OPDATERING og SLET, da nyindsat post alligevel vil være beskyttet i henhold til isolationsniveau. Hver WRITE-operation producerer en ny version af objektet, og hver samtidig læseoperation læser en anden version af objektet afhængigt af isolationsniveauet. Siden læse og skrive begge opererer på forskellige versioner af det samme objekt, så ingen af disse operationer kræves for at låse fuldstændigt, og derfor kan begge fungere samtidigt. Det eneste tilfælde, hvor påstanden stadig kan eksistere, er, når to samtidige transaktioner forsøger at SKRIVE den samme post.
Det meste af den nuværende store database understøtter MVCC. Hensigten med denne algoritme er at vedligeholde flere versioner af det samme objekt, så implementeringen af MVCC adskiller sig kun fra database til database med hensyn til, hvordan flere versioner oprettes og vedligeholdes. Følgelig ændres tilsvarende databasedrift og lagring af data.
Den mest anerkendte tilgang til implementering af MVCC er den, der bruges af PostgreSQL og Firebird/Interbase, og en anden bruges af InnoDB og Oracle. I de efterfølgende afsnit vil vi diskutere i detaljer, hvordan det er blevet implementeret i PostgreSQL og InnoDB.
MVCC i PostgreSQL
For at understøtte flere versioner vedligeholder PostgreSQL yderligere felter for hvert objekt (Tuple i PostgreSQL-terminologi) som nævnt nedenfor:
- xmin – Transaktions-id for transaktionen, der indsatte eller opdaterede tuplen. I tilfælde af OPDATERING bliver en nyere version af tuplen tildelt dette transaktions-id.
- xmax – Transaktions-id for transaktionen, der slettede eller opdaterede tuplen. I tilfælde af OPDATERING får en aktuelt eksisterende version af tuple tildelt dette transaktions-id. På en nyoprettet tuple er standardværdien for dette felt null.
PostgreSQL gemmer alle data i et primært lager kaldet HEAP (side på som standardstørrelse 8KB). Al den nye tuple får xmin som en transaktion, der skabte den, og ældre version tuple (som blev opdateret eller slettet) tildeles xmax. Der er altid et link fra den ældre version til den nye version. Den ældre version tuple kan bruges til at genskabe tuple i tilfælde af rollback og til at læse en ældre version af en tuple by READ sætning afhængigt af isolationsniveauet.
Tænk på, at der er to tupler, T1 (med værdi 1) og T2 (med værdi 2) for en tabel, oprettelsen af nye rækker kan demonstreres i nedenstående 3 trin:
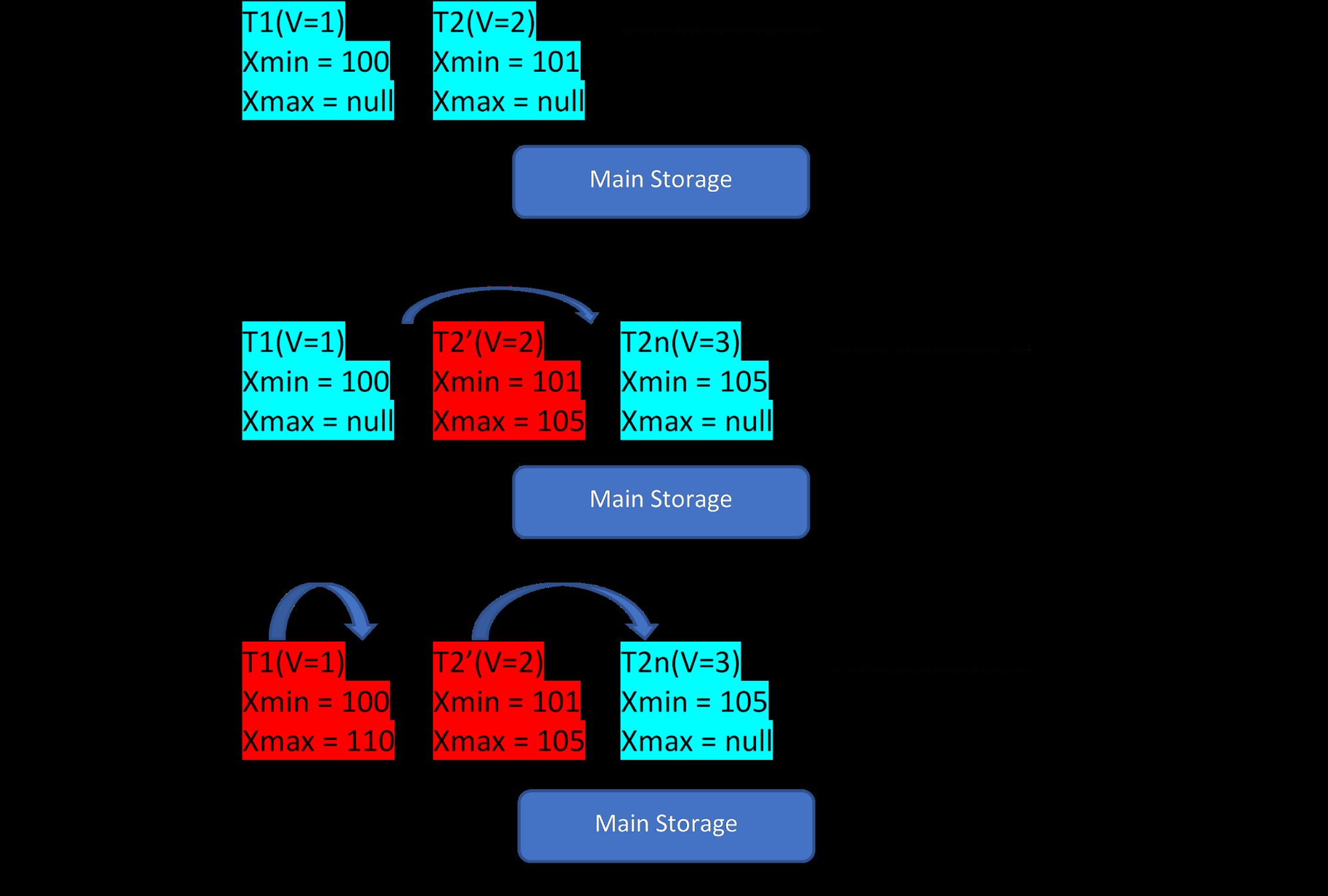 MVCC:Lagring af flere versioner i PostgreSQL
MVCC:Lagring af flere versioner i PostgreSQL Som det ses af billedet, er der i første omgang to tupler i databasen med værdierne 1 og 2.
I det andet trin bliver rækken T2 med værdi 2 opdateret med værdien 3. På dette tidspunkt oprettes en ny version med den nye værdi, og den bliver bare gemt som ved siden af den eksisterende tupel i det samme lagerområde . Inden da bliver den ældre version tildelt xmax og peger på seneste version tuple.
På samme måde, i det tredje trin, når rækken T1 med værdi 1 bliver slettet, bliver den eksisterende række virtuelt slettet (dvs. den har netop tildelt xmax med den aktuelle transaktion) på samme sted. Der oprettes ingen ny version til dette.
Lad os derefter se, hvordan hver operation opretter flere versioner, og hvordan transaktionsisolationsniveauet opretholdes uden at låse med nogle rigtige eksempler. I alle nedenstående eksempler bruges som standard "READ COMMITTED" isolation.
INDSÆT
Hver gang en post bliver indsat, vil den oprette en ny tuple, som bliver tilføjet til en af siderne, der hører til den tilsvarende tabel.
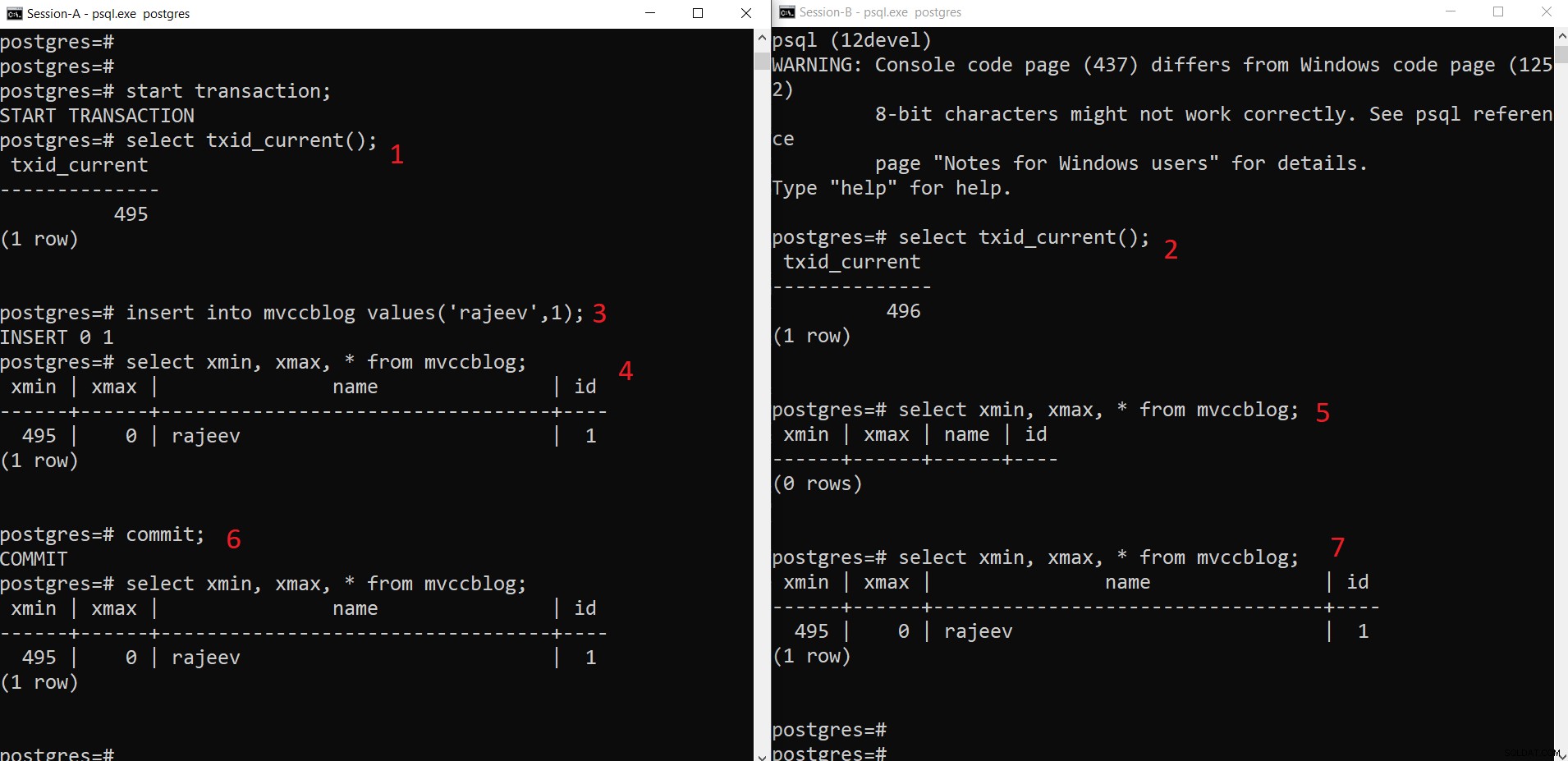 PostgreSQL samtidig INSERT operation
PostgreSQL samtidig INSERT operation Som vi kan se her trinvist:
- Session-A starter en transaktion og får transaktions-id 495.
- Session-B starter en transaktion og får transaktions-id 496.
- Session-A indsæt en ny tuple (gemmes i HEAP)
- Nu tilføjes den nye tuple med xmin indstillet til nuværende transaktions-ID 495.
- Men det samme er ikke synligt fra Session-B, da xmin (dvs. 495) stadig ikke er begået.
- Når du er forpligtet.
- Data er synlige for begge sessioner.
OPDATERING
PostgreSQL UPDATE er ikke "IN-PLACE" opdatering, dvs. den ændrer ikke det eksisterende objekt med den påkrævede nye værdi. I stedet opretter den en ny version af objektet. Så OPDATERING involverer i store træk nedenstående trin:
- Det markerer det aktuelle objekt som slettet.
- Derefter tilføjer den en ny version af objektet.
- Omdiriger den ældre version af objektet til en ny version.
Så selvom en række poster forbliver de samme, tager HEAP plads, som om der blev indsat en post mere.
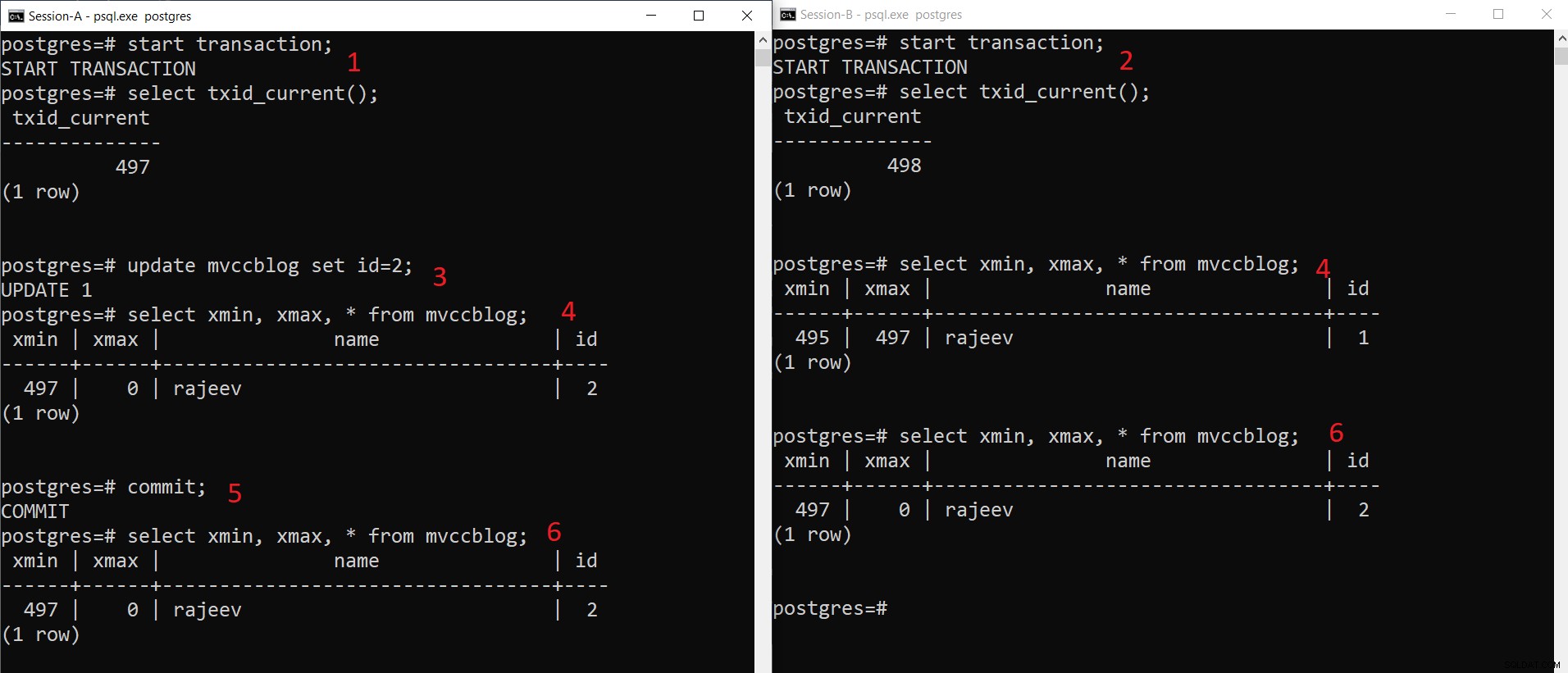 PostgreSQL samtidig INSERT operation
PostgreSQL samtidig INSERT operation Som vi kan se her trinvist:
- Session-A starter en transaktion og får transaktions-id 497.
- Session-B starter en transaktion og får transaktions-id 498.
- Session-A opdaterer den eksisterende registrering.
- Her ser Session-A én version af tuple (opdateret tuple), mens Session-B ser en anden version (ældre tuple men xmax sat til 497). Begge tuple-versioner bliver gemt i HEAP-lageret (selv den samme side afhængigt af ledig plads)
- Når Session-A forpligter transaktionen, udløber den ældre tupel, da xmax af den ældre tuple er begået.
- Nu ser begge sessioner den samme version af posten.
SLET
Slet er næsten som OPDATERING, bortset fra at det ikke behøver at tilføje en ny version. Det markerer bare det aktuelle objekt som SLETTET som forklaret i UPDATE-tilfældet.
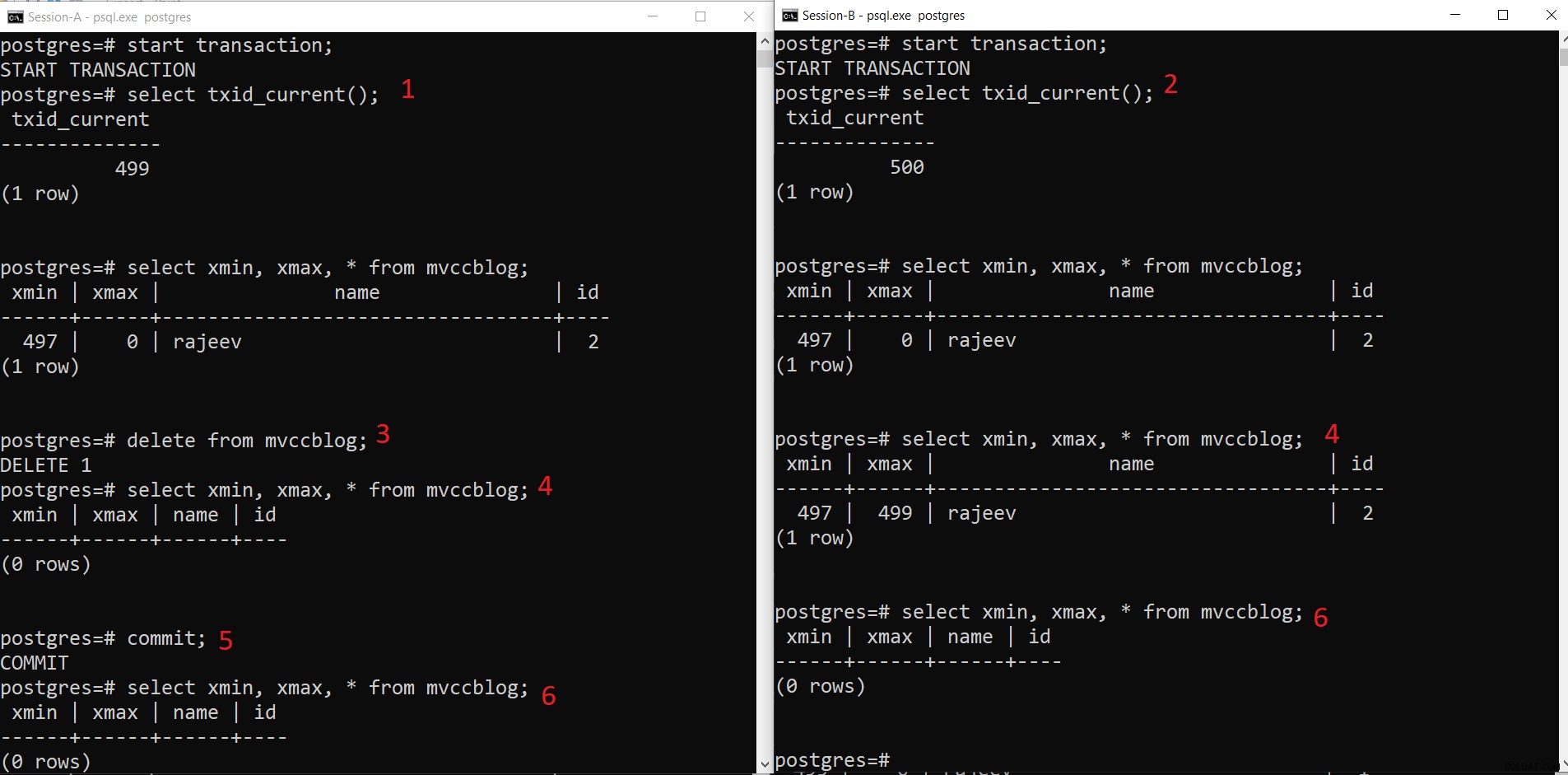 PostgreSQL samtidig DELETE-handling
PostgreSQL samtidig DELETE-handling - Session-A starter en transaktion og får transaktions-id 499.
- Session-B starter en transaktion og får transaktions-id 500.
- Session-A sletter den eksisterende post.
- Her ser session-A ingen tuple som slettet fra den aktuelle transaktion. Mens Session-B ser en ældre version af tuple (med xmax som 499; transaktionen, der slettede denne post).
- Når Session-A forpligter transaktionen, udløber den ældre tupel, da xmax af den ældre tuple er begået.
- Nu kan begge sessioner ikke se slettet tuple.
Som vi kan se, fjerner ingen af handlingerne den eksisterende version af objektet direkte, og hvor det er nødvendigt tilføjer det en ekstra version af objektet.
Lad os nu se, hvordan SELECT-forespørgsel udføres på en tuple med flere versioner:SELECT skal læse alle versioner af tuple, indtil den finder den passende tuple i henhold til isolationsniveau. Antag, at der var tuple T1, som blev opdateret og skabte ny version T1' og som igen skabte T1'' ved opdatering:
- SELECT-operationen vil gå gennem heap-lageret for denne tabel og kontrollere først T1. Hvis T1 xmax-transaktionen er begået, flyttes den til den næste version af denne tuple.
- Antag nu, at T1' tuple xmax også er begået, så flytter den igen til næste version af denne tuple.
- Til sidst finder den T1'' og ser, at xmax ikke er forpligtet (eller null), og T1'' xmin er synlig for den aktuelle transaktion pr. isolationsniveau. Til sidst vil den læse T1’’ tuple.
Som vi kan se, skal den gennemløbe alle 3 versioner af tupelen for at finde den passende synlige tuple, indtil udløbet tuple bliver slettet af skraldeopsamleren (VACUUM).
MVCC i InnoDB
For at understøtte flere versioner vedligeholder InnoDB yderligere felter for hver række som nævnt nedenfor:
- DB_TRX_ID:Transaktions-id for transaktionen, der indsatte eller opdaterede rækken.
- DB_ROLL_PTR:Den kaldes også rullemarkøren, og den peger på at fortryde logpost skrevet til tilbagerulningssegmentet (mere om dette næste).
Ligesom PostgreSQL opretter InnoDB også flere versioner af rækken som en del af al operation, men lagringen af den ældre version er anderledes.
I tilfælde af InnoDB opbevares den gamle version af den ændrede række i et separat tablespace/lager (kaldet fortryd segment). Så i modsætning til PostgreSQL beholder InnoDB kun den seneste version af rækker i hovedlagerområdet, og den ældre version beholdes i Fortryd-segmentet. Rækkeversioner fra fortryd-segmentet bruges til at fortryde handling i tilfælde af tilbagerulning og til at læse en ældre version af rækker ved hjælp af READ-sætning afhængigt af isolationsniveauet.
Tænk på, at der er to rækker, T1 (med værdi 1) og T2 (med værdi 2) for en tabel, oprettelsen af nye rækker kan demonstreres i nedenstående 3 trin:
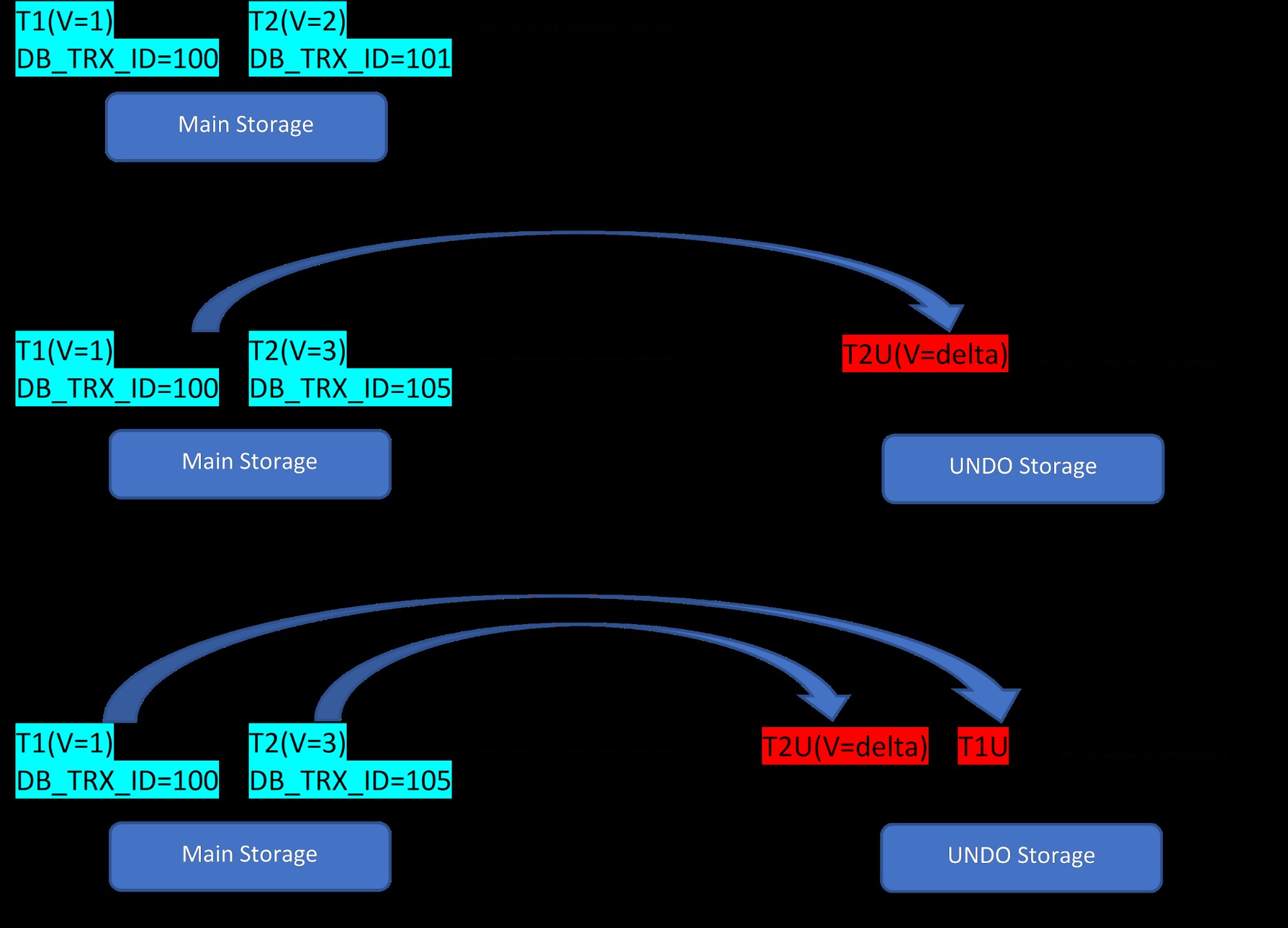 MVCC:Lagring af flere versioner i InnoDB
MVCC:Lagring af flere versioner i InnoDB Som det ses af figuren, er der i første omgang to rækker i databasen med værdierne 1 og 2.
I det andet trin bliver rækken T2 med værdi 2 opdateret med værdien 3. På dette tidspunkt oprettes en ny version med den nye værdi, og den erstatter den ældre version. Før det bliver den ældre version gemt i fortryd-segmentet (bemærk, at FORTRYD-segmentversionen kun har en deltaværdi). Bemærk også, at der er en pegepind fra den nye version til den ældre version i rollback-segmentet. Så i modsætning til PostgreSQL er InnoDB-opdatering "IN-PLACE".
På samme måde, i det tredje trin, når række T1 med værdi 1 bliver slettet, bliver den eksisterende række virtuelt slettet (dvs. den markerer bare en speciel bit i rækken) i hovedlagerområdet, og en ny version svarende til dette bliver tilføjet i segmentet Fortryd. Igen er der én rullemarkør fra hovedlageret til fortryd-segmentet.
Alle operationer opfører sig på samme måde som i tilfældet med PostgreSQL, når de ses udefra. Bare intern lagring af flere versioner er forskellig.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperMVCC:PostgreSQL vs InnoDB
Lad os nu analysere, hvad der er de største forskelle mellem PostgreSQL og InnoDB med hensyn til deres MVCC-implementering:
-
Størrelse af en ældre version
PostgreSQL opdaterer bare xmax på den ældre version af tuple, så størrelsen på den ældre version forbliver den samme til den tilsvarende indsatte post. Dette betyder, at hvis du har 3 versioner af en ældre tuple, vil de alle have samme størrelse (undtagen forskellen i faktisk datastørrelse, hvis nogen ved hver opdatering).
Hvorimod i tilfælde af InnoDB er objektversionen gemt i Fortryd-segmentet typisk mindre end den tilsvarende indsatte post. Dette skyldes, at kun de ændrede værdier (dvs. differential) skrives til UNDO-log.
-
INSERT operation
InnoDB skal skrive en ekstra post i UNDO-segmentet, selv for INSERT, mens PostgreSQL kun opretter en ny version i tilfælde af OPDATERING.
-
Gendannelse af en ældre version i tilfælde af tilbagerulning
PostgreSQL behøver ikke noget specifikt for at gendanne en ældre version i tilfælde af tilbagerulning. Husk, at den ældre version har xmax svarende til transaktionen, der opdaterede denne tuple. Så indtil dette transaktions-id bliver begået, anses det for at være levende tuple for et samtidig snapshot. Når transaktionen er tilbageført, vil den tilsvarende transaktion automatisk blive betragtet som levende for alle transaktioner, da det vil være en afbrudt transaktion.
Mens det i tilfælde af InnoDB er eksplicit påkrævet at genopbygge den ældre version af objektet, når tilbagerulningen sker.
-
Genvinder plads optaget af en ældre version
I tilfælde af PostgreSQL kan pladsen optaget af en ældre version kun betragtes som død, når der ikke er noget parallelt snapshot til at læse denne version. Når først den ældre version er død, kan VACUUM-operationen genvinde den plads, de optager. VACUUM kan udløses manuelt eller som en baggrundsopgave afhængigt af konfigurationen.
InnoDB UNDO-logfiler er primært opdelt i INSERT UNDO og UPDATE UNDO. Den første bliver kasseret, så snart den tilsvarende transaktion forpligtes. Den anden skal bevares, indtil den er parallel med ethvert andet snapshot. InnoDB har ikke eksplicit VACUUM-drift, men på en lignende linje har den asynkron PURGE for at kassere UNDO-logfiler, der kører som en baggrundsopgave.
-
Påvirkning af forsinket vakuum
Som diskuteret i et tidligere punkt, er der en enorm indvirkning af forsinket vakuum i tilfælde af PostgreSQL. Det får bordet til at begynde at blive oppustet og får lagerplads til at øges, selvom poster konstant slettes. Det kan også nå et punkt, hvor VAKUUM FULD skal udføres, hvilket er meget omkostningskrævende operationer.
-
Sekventiel scanning i tilfælde af oppustet bord
PostgreSQL sekventiel scanning skal gå gennem alle ældre versioner af et objekt, selvom de alle er døde (indtil de er fjernet ved hjælp af vakuum). Dette er det typiske og mest omtalte problem i PostgreSQL. Husk PostgreSQL gemmer alle versioner af en tuple i samme lager.
Hvorimod det i tilfælde af InnoDB ikke behøver at læse Fortryd post, medmindre det er påkrævet. Hvis alle fortryd-poster er døde, vil det kun være nok at læse alle de seneste versioner af objekterne igennem.
-
Indeks
PostgreSQL gemmer indeks i et separat lager, som holder ét link til faktiske data i HEAP. Så PostgreSQL skal også opdatere INDEX-delen, selvom der ikke var nogen ændring i INDEX. Selvom dette problem senere blev løst ved at implementere HOT (Heap Only Tuple) opdatering, men det har stadig den begrænsning, at hvis en ny heap tuple ikke kan anbringes på samme side, så falder den tilbage til normal OPDATERING.
InnoDB har ikke dette problem, da de bruger clustered index.
Konklusion
PostgreSQL MVCC har få ulemper, især med hensyn til oppustet lagerplads, hvis din arbejdsbyrde har hyppig UPDATE/DELETE. Så hvis du beslutter dig for at bruge PostgreSQL, bør du være meget omhyggelig med at konfigurere VACUUM klogt.
PostgreSQL-fællesskabet har også anerkendt dette som et stort problem, og de er allerede begyndt at arbejde på UNDO-baseret MVCC-tilgang (foreløbigt navn som ZHEAP), og vi vil muligvis se det samme i en fremtidig udgivelse.