PostgreSQL 11 blev frigivet den 10. oktober 2018 og efter planen, hvilket markerede 23-årsdagen for den stadig mere populære open source-database.
Mens en komplet liste over ændringer er tilgængelig i de sædvanlige Release Notes, er det værd at tjekke den fornyede Feature Matrix-side, der ligesom den officielle dokumentation har fået en makeover siden den første version, hvilket gør det lettere at få øje på ændringer, før du dykker ned i detaljerne .
For eksempel på siden Release Notes er "Kanalbinding til SCAM-godkendelse" begravet under kildekoden, mens matricen har den under sikkerhedsafsnittet. For de nysgerrige er her et skærmbillede af grænsefladen:
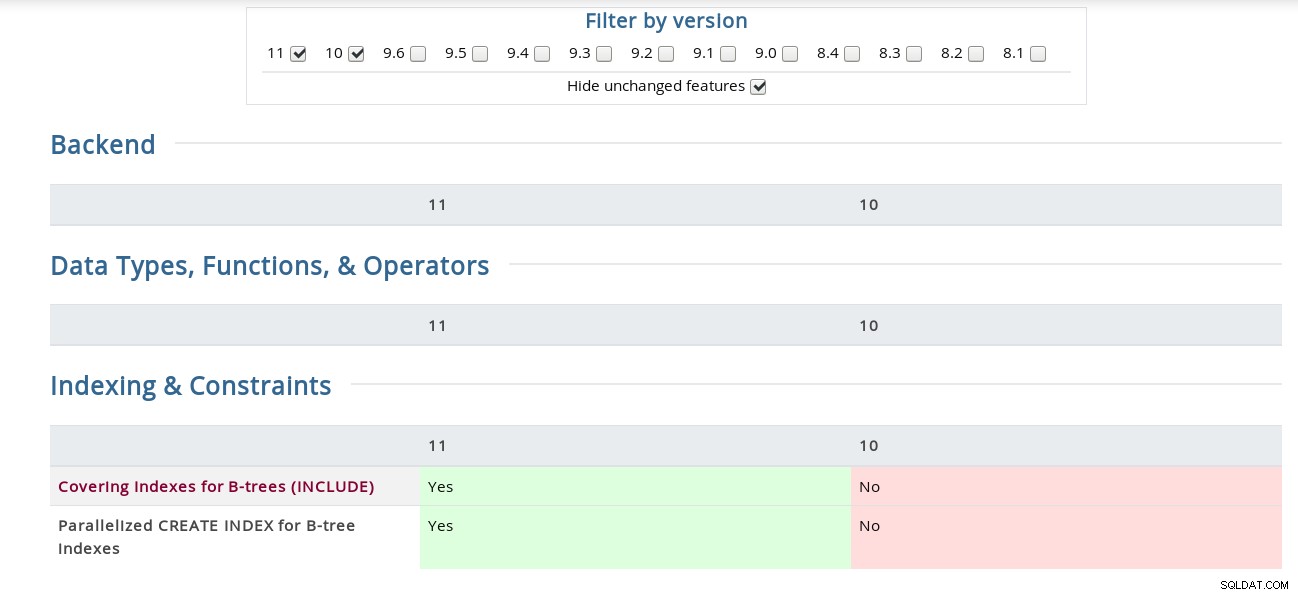 PostgreSQL-funktionsmatrix
PostgreSQL-funktionsmatrix Derudover er Bucardo Postgres Release Notes-siden, der er linket til ovenfor, praktisk på sin egen måde, hvilket gør det nemt at søge efter et søgeord på tværs af alle versioner.
Hvad er nyt? Med bogstaveligt talt hundredvis af ændringer vil jeg gennemgå de forskelle, der er angivet i Feature Matrix.
Dækkende indekser for B-træer (INKLUDERE)
CREATE INDEX modtog INCLUDE-sætningen, som tillader indekser at inkludere ikke-nøglekolonner . Dens anvendelsesmuligheder for hyppige identiske forespørgsler er godt beskrevet i Tom Lanes commit fra 22. november, som opdaterer udviklingsdokumentationen (hvilket betyder, at den nuværende PostgreSQL 11-dokumentation ikke har det endnu), så for den fulde tekst henvises til afsnit 11.9. Indeks-kun scanninger og dækker indekser i udviklingsversionen.
Paralleliseret CREATE INDEX for B-tree Indexes
Som antydet i navnet, er denne funktion kun implementeret for B-tree-indekserne, og fra Robert Haas' commit-log lærer vi, at implementeringen kan blive forfinet i fremtiden. Som bemærket fra CREATE INDEX-dokumentationen, mens både parallelle og samtidige indeksoprettelsesmetoder udnytter flere CPU'er, vil i tilfælde af CONCURRENT kun den første tabelscanning blive udført parallelt.
Relateret til denne nye funktion er konfigurationsparametrene maintenance_work_mem og maintenance_parallel_maintenance_workers .
Endelig kan antallet af parallelle arbejdere indstilles pr. tabel ved hjælp af kommandoen ALTER TABLE og angive en værdi for parallel_arbejdere .
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperJust-in-Time (JIT) kompilering til udtryksevaluering og tupledeformering
Med sit eget JIT-kapitel i dokumentationen er denne nye funktion afhængig af, at PostgreSQL er kompileret med LLVM-understøttelse (brug pg_config til at bekræfte).
Emnet om JIT i PostgreSQL er komplekst nok (se JIT README-referencen i dokumentationen) til at kræve en dedikeret blog, i mellemtiden er CitusData-bloggen om JIT en meget god læsning for interesserede til at dykke dybere ned i emnet.
Paralleliserede Hash Joins
Denne forbedring af ydeevnen til parallelle forespørgsler er resultatet af tilføjelsen af en delt hash-tabel, som, som Thomas Munro forklarer i sin Parallel Hash for PostgreSQL-blog, undgår at partitionere hashtabellen, forudsat at den passer i work_mem , hvilket indtil videre for PostgreSQL ser ud til at være en bedre løsning end partition-first-algoritmen. Den samme blog beskriver de PostgreSQL-arkitekturforhindringer, som forfatteren måtte overvinde i sin søgen efter at tilføje parallelisering til hash-forbindelser, der taler om kompleksiteten af det arbejde, der var påkrævet for at implementere denne funktion.
Standardpartition
Dette er en catch all-partition til at gemme rækker, der ikke matcher nogen anden defineret partition. I tilfælde, hvor en ny partition tilføjes, anbefales en CHECK-begrænsning for at undgå en scanning af standardpartitionen, som kan være langsom, når standardpartitionen indeholder et stort antal rækker.
Standardpartitionens adfærd er forklaret i dokumentationen til ALTER TABLE og CREATE TABLE.
Partitionering med en Hash-nøgle
Kaldes også hash-partitionering, og som påpeget i commit-meddelelsen, tillader funktionen partitionering af tabeller på en sådan måde, at partitioner vil indeholde et tilsvarende antal rækker. Dette opnås ved at give et modul, som i det mere simple scenarie anbefales at være lig med antallet af partitioner, og resten bør være forskellig for hver partition.
For flere detaljer og et eksempel se CREATE TABLE-dokumentationssiden.
Understøttelse af PRIMÆR NØGLE, UDENLANDSKE NØGLE, indekser og udløsere på opdelte tabeller
Tabelopdeling er allerede et stort skridt i at forbedre ydeevnen af store tabeller, og tilføjelsen af disse funktioner adresserer de begrænsninger, som partitionerede tabeller har haft siden PostgreSQL 10, hvor den moderne "deklarative partitionering" blev introduceret.
Arbejdet af Alvaro Herrera er i gang for at tillade fremmede nøgler at referere til primærnøgler, og er planlagt til den næste PostgreSQL major version 12.
OPDATERING på en partitionsnøgle
Som forklaret i patch-commit-loggen forhindrer denne opdatering PostgreSQL i at kaste en fejl, når en opdatering til partitionsnøglen ugyldiggør en række, og i stedet vil rækken blive flyttet til en passende partition.
Kanalbinding til SCRAM-godkendelse
Dette er en sikkerhedsforanstaltning, der sigter mod at forhindre man-in-the-middle-angreb i SASL-godkendelse og er grundigt beskrevet i forfatterens blog. Funktionen kræver minimum OpenSSL 1.0.2.
OPRET PROCEDURE og CALL-syntaks for SQL Stored Procedures
PostgreSQL har haft CREATE FUNCTION siden 1996 med version 1.0.1 funktioner kan dog ikke håndtere transaktioner. Som nævnt i dokumentationen er CREATE PROCEDURE-kommandoen ikke fuldt ud kompatibel med SQL-standarden.
Bemærk:Hold øje med en kommende blog, som dykker dybt ned i denne funktion
Konklusion
PostgreSQL 11 store opdateringer fokuserer på ydeevneforbedringer gennem parallel eksekvering, partitionering og Just-In-Time kompilering. Lagrede procedurer giver mulighed for fuld transaktionskontrol og kan skrives på en række PL-sprog.