Introduktion
Uanset databaseteknologi er det nødvendigt at have en overvågningsopsætning, både for at opdage problemer og tage handling, eller blot for at kende den aktuelle tilstand af vores systemer.
Til dette formål er der flere værktøjer, betalt og gratis. I denne blog vil vi fokusere på et særligt:Nagios Core.
Hvad er Nagios Core?
Nagios Core er et Open Source-system til overvågning af værter, netværk og tjenester. Det giver mulighed for at konfigurere advarsler og har forskellige tilstande for dem. Det tillader implementering af plugins, udviklet af fællesskabet, eller giver os endda mulighed for at konfigurere vores egne overvågningsscripts.
Hvordan installeres Nagios?
Den officielle dokumentation viser os, hvordan man installerer Nagios Core på CentOS- eller Ubuntu-systemer.
Lad os se et eksempel på de nødvendige trin til installationen på CentOS 7.
Pakke påkrævet
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzip Download Nagios Core, Nagios Plugins og NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/ nrpe-3.2.1/nrpe-3.2.1.tar.gz Tilføj Nagios-bruger og -gruppe
[eksempel@sqldat.com ~]# brugeradd nagios[eksempel@sqldat.com ~]# groupadd nagcmd[eksempel@sqldat.com ~]# brugermod -a -G nagcmd nagios[eksempel@sqldat.com ~]# usermod -a -G nagios,nagcmd apache Nagios-installation
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz[example@sqldat.com ~]# cd nagios-4.4.2[example@sqldat.com nagios-4.4 .2]# ./configure --with-command-group=nagcmd[example@sqldat.com nagios-4.4.2]# make all[example@sqldat.com nagios-4.4.2]# make install[example@sqldat .com nagios-4.4.2]# make install-init[example@sqldat.com nagios-4.4.2]# make install-config[example@sqldat.com nagios-4.4.2]# make install-commandmode[example@ sqldat.com nagios-4.4.2]# make install-webconf[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/[example@sqldat.com nagios -4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/ local/nagios/etc/nagios.cfg Nagios-plugin og NRPE-installation
[eksempel@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz[eksempel@sqldat.com ~]# cd nagios-plugins-2.2.1[eksempel@sqldat. com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios[example@sqldat.com nagios-plugins-2.2.1]# make[example@ sqldat.com nagios-plugins-2.2.1]# make install[example@sqldat.com ~]# yum install epel-release[example@sqldat.com ~]# yum install nagios-plugins-nrpe[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz[example@sqldat.com ~]# cd nrpe-3.2.1[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args[example@sqldat.com nrpe-3.2.1]# make all[example@sqldat.com nrpe-3.2.1]# make install-plugin Vi tilføjer følgende linje til slutningen af vores fil /usr/local/nagios/etc/objects/command.cfg for at bruge NRPE, når vi tjekker vores servere:
define command{ command_name check_nrpe command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$} Nagios starter
[example@sqldat.com nagios-4.4.2]# systemctl start nagios[example@sqldat.com nagios-4.4.2]# systemctl start httpd Webadgang
Vi opretter brugeren for at få adgang til webgrænsefladen, og vi kan gå ind på siden.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin https://IP_Address/nagios/
 Nagios Web Access
Nagios Web Access Hvordan konfigureres Nagios?
Nu hvor vi har vores Nagios installeret, kan vi fortsætte med konfigurationen. Til dette skal vi gå til den placering, der svarer til vores installation, i vores eksempel /usr/local/nagios/etc.
Der er flere forskellige konfigurationsfiler, som du skal oprette eller redigere, før du begynder at overvåge noget.
[example@sqldat.com osv.]# ls /usr/local/nagios/etccgi.cfg htpasswd.users nagios.cfg objects resource.cfg - cgi.cfg: CGI-konfigurationsfilen indeholder en række direktiver, der påvirker driften af CGI'erne. Den indeholder også en reference til hovedkonfigurationsfilen, så CGI'erne ved, hvordan du har konfigureret Nagios, og hvor dine objektdefinitioner er gemt.
- htpasswd.users: Denne fil indeholder de brugere, der er oprettet for at få adgang til Nagios-webgrænsefladen.
- nagios.cfg: Hovedkonfigurationsfilen indeholder en række direktiver, der påvirker, hvordan Nagios Core-dæmonen fungerer.
- objekter: Når du installerer Nagios, placeres flere eksempler på objektkonfigurationsfiler her. Du kan bruge disse eksempelfiler til at se, hvordan objektarv fungerer, og lære, hvordan du definerer dine egne objektdefinitioner. Objekter er alle de elementer, der er involveret i overvågnings- og notifikationslogikken.
- resource.cfg: Dette bruges til at angive en valgfri ressourcefil, der kan indeholde makrodefinitioner. Makroer giver dig mulighed for at referere til oplysninger om værter, tjenester og andre kilder i dine kommandoer.
Indenfor objekter kan vi finde skabeloner, som kan bruges ved oprettelse af nye objekter. For eksempel kan vi se, at der i vores fil /usr/local/nagios/etc/objects/templates.cfg er en skabelon kaldet linux-server, som vil blive brugt til at tilføje vores servere.
definer vært { navn linux-server; Navnet på denne værtsskabelon bruger generic-host; Denne skabelon arver andre værdier fra den generiske værtsskabelon check_period 24x7; Som standard kontrolleres Linux-værter døgnet rundt check_interval 5; Tjek værten aktivt hvert 5. minut. retry_interval 1; Planlæg genforsøg med værtstjek med 1 minuts intervaller max_check_attempts 10; Tjek hver Linux-vært 10 gange (maks.) check_command check-host-alive; Standardkommando til at kontrollere Linux-værter notification_period workhours; Linux-administratorer hader at blive vækket, så vi giver kun besked i løbet af dagen; Bemærk, at variabelen notification_period bliver tilsidesat fra; den værdi, der er nedarvet fra den generiske værtsskabelon! meddelelsesinterval 120; Send beskeder igen hver anden time notification_options d,u,r; Send kun meddelelser for specifikke værtsstater contact_groups admins; Meddelelser sendes til administratorerne som standard register 0; REGISTRER IKKE DENNE DEFINITION - DEN ER IKKE EN RIGTIG VÆRT, KUN EN SKABELON!} Ved at bruge denne skabelon vil vores værter arve konfigurationen uden at skulle angive dem én efter én på hver server, vi tilføjer.
Vi har også foruddefinerede kommandoer, kontakter og tidsperioder.
Kommandoerne vil blive brugt af Nagios til sine kontroller, og det er det, vi tilføjer i konfigurationsfilen på hver server for at overvåge den. For eksempel PING:
definer kommando { command_name check_ping command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5} Vi har mulighed for at oprette kontakter eller grupper og angive, hvilke advarsler jeg vil nå ud til hvilken person eller gruppe.
definer kontakt { contact_name nagiosadmin; Kort navn på bruger brug generisk-kontakt; Arv standardværdier fra generisk kontaktskabelon (defineret ovenfor) alias Nagios Admin; Fulde navn på brugerens e-mail example@sqldat.com; <<***** SKIFT DETTE TIL DIN E-MAILADRESSE ******} Til vores kontroller og advarsler kan vi konfigurere, i hvilke timer og dage vi ønsker at modtage dem. Hvis vi har en service, der ikke er kritisk, ønsker vi sandsynligvis ikke at vågne op ved daggry, så det ville være godt kun at alarmere i arbejdstiden for at undgå dette.
define timeperiod { name workhours timeperiod_name workhours alias Normal arbejdstid mandag 09:00-17:00 tirsdag 09:00-17:00 onsdag 09:00-17:00 torsdag 09:00-17:00 fredag 09:00-17:00 Lad os nu se, hvordan du tilføjer alarmer til vores Nagios.
Vi skal overvåge vores PostgreSQL-servere, så vi tilføjer dem først som værter i vores objektbibliotek. Vi vil oprette 3 nye filer:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/[example@sqldat.com objects]# vi postgres1.cfgdefine host { use linux-server; Navn på værtsskabelon, der skal bruges værtsnavn postgres1; Værtsnavn alias PostgreSQL1; Alias adresse 192.168.100.123; IP-adresse}[eksempel@sqldat.com objekter]# vi postgres2.cfgdefine vært { brug linux-server; Navn på værtsskabelon, der skal bruges værtsnavn postgres2; Værtsnavn alias PostgreSQL2; Alias adresse 192.168.100.124; IP-adresse}[eksempel@sqldat.com objekter]# vi postgres3.cfgdefine vært { brug linux-server; Navn på værtsskabelon, der skal bruges værtsnavn postgres3; Værtsnavn alias PostgreSQL3; Alias adresse 192.168.100.125; IP-adresse Så skal vi tilføje dem til filen nagios.cfg og her har vi 2 muligheder.
Tilføj vores værter (cfg-filer) én efter én ved hjælp af cfg_file-variablen (standardindstilling) eller tilføj alle de cfg-filer, som vi har inde i en mappe ved hjælp af cfg_dir-variablen.
Vi tilføjer filerne én efter én efter standardstrategien.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfgcfg_file=/usr/local/nagios/etc/objects/postgres2.cfgcfg_file=/usr/local/nagios/etc/objects/post .cfg Med dette har vi vores værter overvåget. Nu skal vi bare tilføje, hvilke tjenester vi vil overvåge. Til dette vil vi bruge nogle allerede definerede kontroller (check_ssh og check_ping), og vi vil tilføje nogle grundlæggende kontroller af operativsystemet, såsom load og diskplads, blandt andet ved hjælp af NRPE.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperHvad er NRPE?
Nagios Remote Plugin Executor. Dette værktøj giver os mulighed for at udføre Nagios-plugins på en ekstern vært på en så gennemsigtig måde som muligt.
For at bruge det, skal vi installere serveren i hver node, som vi ønsker at overvåge, og vores Nagios vil oprette forbindelse som en klient til hver enkelt af dem og udføre de tilsvarende plugin(s).
Hvordan installeres NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz[example@ sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar .gz[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz[example@sqldat.com ~]# cd nrpe-3.2.1[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args[example@sqldat.com nrpe-3.2.1]# make all[example@sqldat.com nrpe-3.2.1]# make install-groups-users[ eksempel@sqldat.com nrpe-3.2.1]# make install[example@sqldat.com nrpe-3.2.1]# make install-config[example@sqldat.com nrpe-3.2.1]# make install-init[eksempel @sqldat.com ~]# cd nagios-plugins-2.2.1[eksempel@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios[example@sqldat.com nagios-plugins-2.2.1]# make[example@sqldat.com nagios-plugins-2.2.1]# make install[example@sqldat.com nagios-plugins-2.2.1]# systemctl aktiver nrpe Derefter redigerer vi konfigurationsfilen /usr/local/nagios/etc/nrpe.cfg
server_address=allowed_hosts=127.0.0.1, Og vi genstarter NRPE-tjenesten:
[example@sqldat.com ~]# systemctl genstart nrpe Vi kan teste forbindelsen ved at køre følgende fra vores Nagios-server:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H NRPE v3.2.1 Hvordan overvåger man PostgreSQL?
Når du overvåger PostgreSQL, er der to hovedområder at tage hensyn til:operativsystem og databaser.
For operativsystemet har NRPE nogle grundlæggende kontroller konfigureret, såsom diskplads og load, blandt andre. Disse kontroller kan meget nemt aktiveres på følgende måde.
I vores noder redigerer vi filen /usr/local/nagios/etc/nrpe.cfg og går til, hvor følgende linjer er:
kommando[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Zcommand[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200 Navnene i firkantede parenteser er dem, vi vil bruge i vores Nagios-server til at aktivere disse kontroller.
I vores Nagios redigerer vi filerne for de 3 noder:
/usr/local/nagios/etc/objects/postgres1.cfg/usr/local/nagios/etc/objects/postgres2.cfg/usr/local/nagios/etc/objects/postgres3.cfg Vi tilføjer disse kontroller, som vi så tidligere, og efterlader vores filer som følger:
define host { use linux-server host_name postgres1 alias PostgreSQL1 address 192.168.100.123}define service { use generic-service host_name postgres1 service_description PING check_command check_ping!100.0,20%!500.0,60 generic-service host_name postgres1 service_description SSH check_command check_ssh}define service { use generic-service host_name postgres1 service_description Root Partition check_command check_nrpe!check_disk}define service { use generic-service host_name postgres1 service_description Total Processes brug check_zombie check_command -tjeneste værtsnavn postgres1 service_description Totale processer check_command check_nrpe!check_total_procs}define service { use generic-service host_name postgres1 service_description Current Load check_command check_nrpe!check_load}define service { use generic-service host_name postgres1 service_description check Current Users check_nrpe! Og vi genstarter nagios-tjenesten:
[example@sqldat.com ~]# systemctl start nagios På dette tidspunkt, hvis vi går til servicesektionen i webgrænsefladen på vores Nagios, skulle vi have noget i stil med følgende:
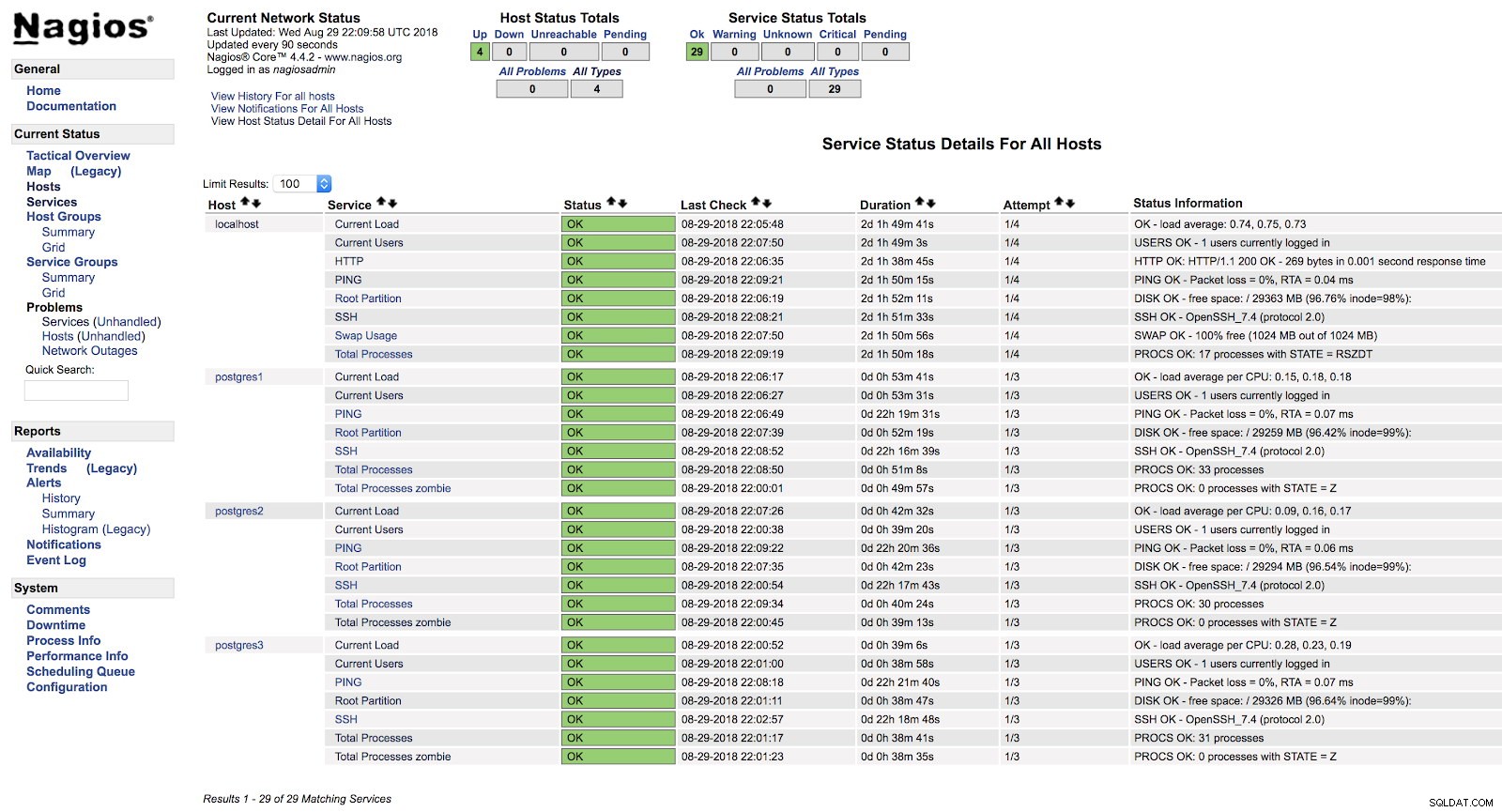 Nagios Host Alerts
Nagios Host Alerts På denne måde vil vi dække de grundlæggende kontroller af vores server på operativsystemniveau.
Vi har mange flere checks, som vi kan tilføje, og vi kan endda oprette vores egne checks (vi ser et eksempel senere).
Lad os nu se, hvordan vi overvåger vores PostgreSQL-databasemotor ved hjælp af to af de vigtigste plugins designet til denne opgave.
Check_postgres
Et af de mest populære plugins til at tjekke PostgreSQL er check_postgres fra Bucardo.
Lad os se, hvordan du installerer det, og hvordan du bruger det med vores PostgreSQL-database.
Pakker påkrævet
[example@sqldat.com ~]# yum install perl-devel Installation
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz[example@ sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl [example@sqldat.com ~]# cd /usr/local/nagios/libexec/[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinks Denne sidste kommando opretter links til at bruge alle funktionerne i denne kontrol, såsom check_postgres_connection, check_postgres_last_vacuum eller check_postgres_replication_slots blandt andre.
[example@sqldat.com libexec]# ls |grep postgrescheck_postgres.plcheck_postgres_archive_readycheck_postgres_autovac_freezecheck_postgres_backendscheck_postgres_bloatcheck_postgres_checkpointcheck_postgres_cluster_idcheck_postgres_commitratiocheck_postgres_connectioncheck_postgres_custom_querycheck_postgres_database_sizecheck_postgres_dbstatscheck_postgres_disabled_triggerscheck_postgres_disk_space… Vi tilføjer i vores NRPE-konfigurationsfil (/usr/local/nagios/etc/nrpe.cfg) linjen for at udføre den kontrol, vi vil bruge:
kommando[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c ='200 M'command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgrescommand[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 I vores eksempel tilføjede vi 4 grundlæggende checks for PostgreSQL. Vi vil overvåge Locks, Bloat, Connection og Backends.
I filen, der svarer til vores database på Nagios-serveren (/usr/local/nagios/etc/objects/postgres1.cfg), tilføjer vi følgende poster:
define service { use generic-service host_name postgres1 service_description PostgreSQL-låse check_command check_nrpe!check_postgres_locks}define service { use generic-service host_name postgres1 service_description PostgreSQL Bloat check_command check_nrpe!check_postgres-service_bloat PostgreSQL-forbindelse check_command check_nrpe!check_postgres_connection}define service { use generic-service host_name postgres1 service_description PostgreSQL Backends check_command check_nrpe!check_postgres_backends} Og efter at have genstartet begge tjenester (NRPE og Nagios) på begge servere, kan vi se vores advarsler konfigureret.
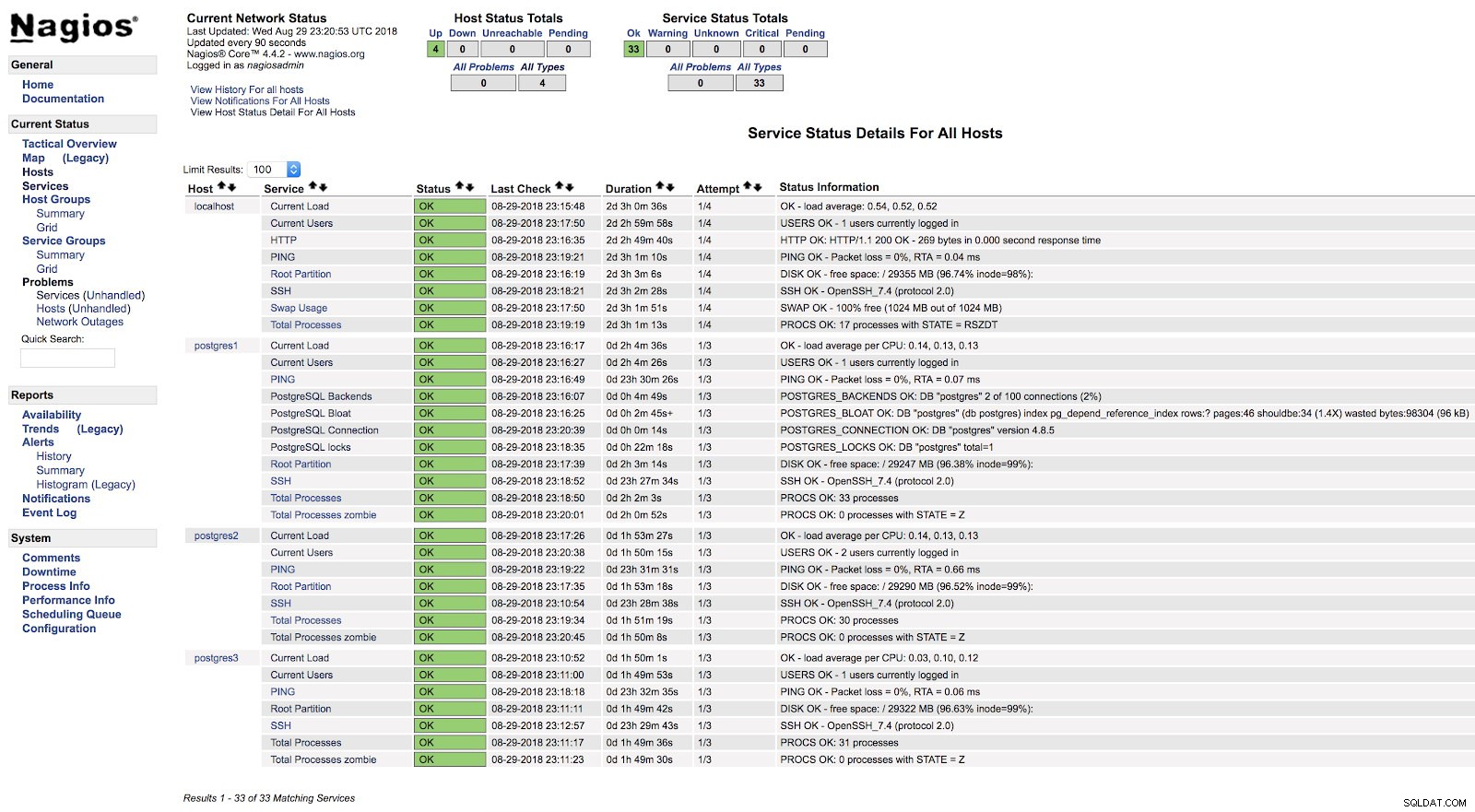 Nagios check_postgres-advarsler
Nagios check_postgres-advarsler I den officielle dokumentation for check_postgres-plugin'et kan du finde information om, hvad du ellers skal overvåge, og hvordan du gør det.
Check_pgactivity
Nu er det turen til check_pgactivity, også populær til overvågning af vores PostgreSQL-database.
Installation
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity[example@sqldat.com ~]# chown nagios.nagios/localcnagios/usr /check_pgactivity Vi tilføjer i vores NRPE-konfigurationsfil (/usr/local/nagios/etc/nrpe.cfg) linjen for at udføre den kontrol, vi vil bruge:
kommando[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connectioncommand[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexescommand[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 /kode> I vores eksempel vil vi tilføje 4 grundlæggende checks for PostgreSQL. Vi overvåger backends, forbindelse, ugyldige indekser og låse.
I filen, der svarer til vores database på Nagios-serveren (/usr/local/nagios/etc/objects/postgres2.cfg), tilføjer vi følgende poster:
define service { use generic-service; Navn på tjenesteskabelon, der skal bruges host_name postgres2 service_description PGActivity Backends check_command check_nrpe!check_pgactivity_backends}define service { use generic-service; Navn på tjenesteskabelon, der skal bruges host_name postgres2 service_description PGActivity Connection check_command check_nrpe!check_pgactivity_connection}define service { use generic-service; Navn på tjenesteskabelon, der skal bruges host_name postgres2 service_description PGActivity Indexes check_command check_nrpe!check_pgactivity_indexes}define service { use generic-service; Navn på tjenesteskabelon, der skal bruges host_name postgres2 service_description PGActivity Locks check_command check_nrpe!check_pgactivity_locks} Og efter at have genstartet begge tjenester (NRPE og Nagios) på begge servere, kan vi se vores advarsler konfigureret.
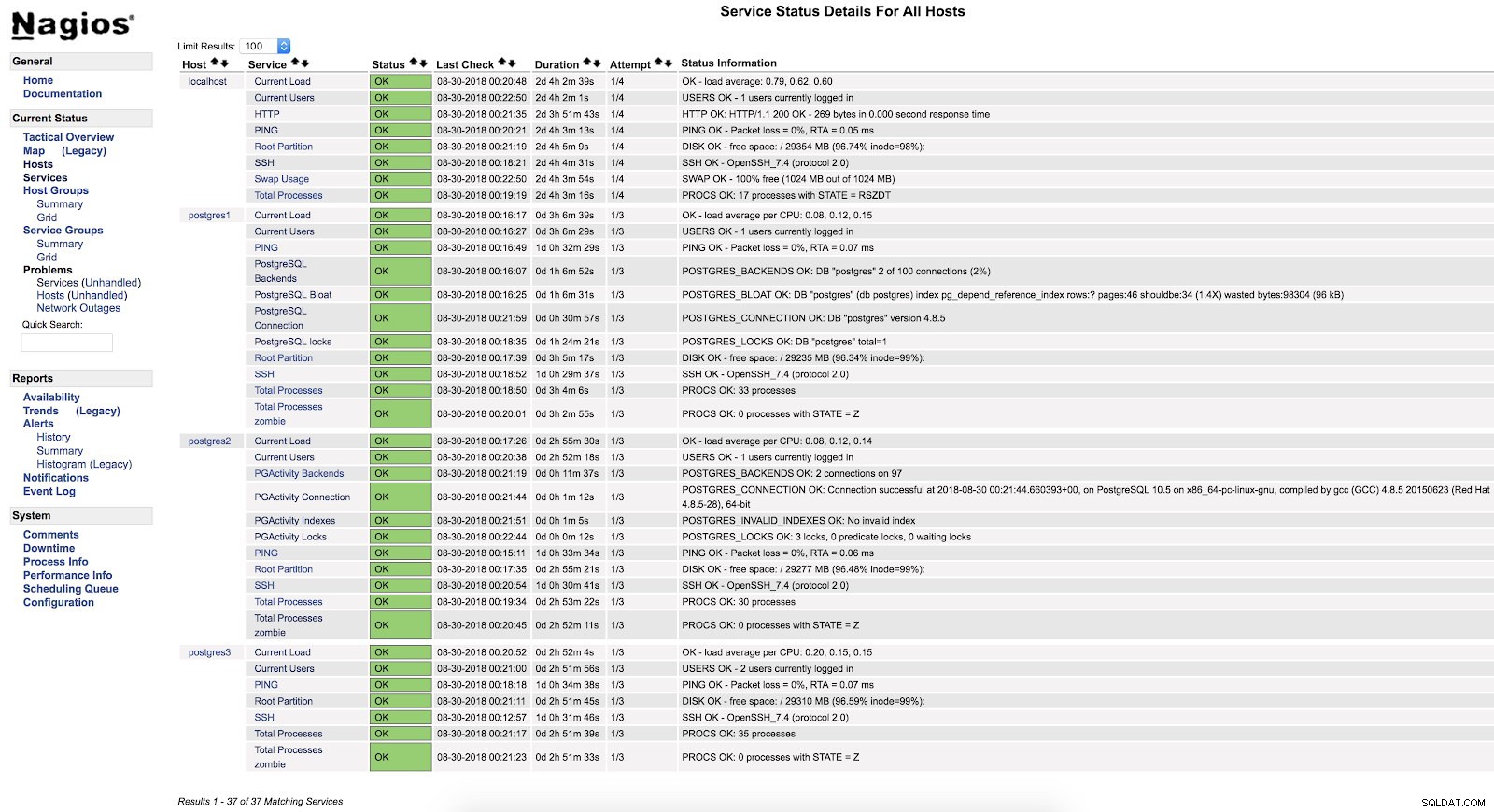 Nagios check_pgactivity-advarsler
Nagios check_pgactivity-advarsler Tjek fejllog
En af de vigtigste kontroller, eller den vigtigste, er at tjekke vores fejllog.
Her kan vi finde forskellige typer fejl som f.eks. FATAL eller deadlock, og det er et godt udgangspunkt for at analysere ethvert problem, vi har i vores database.
For at tjekke vores fejllog vil vi oprette vores eget overvågningsscript og integrere det i vores Nagios (dette er blot et eksempel, dette script vil være grundlæggende og har masser af plads til forbedringer).
Script
Vi vil oprette filen /usr/local/nagios/libexec/check_postgres_log.sh på vores PostgreSQL3-server.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh#!/bin/bash#VariablesLOG="/var/log/postgresql-$(dato +% a).log"CURRENT_DATE=$(dato +'%Y-%m-%d %H')ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)#StatesSTATE_CRITICAL=2STATE_OK=0#Checkif [ $FEJL -ne 0 ]; derefter ekko "CRITICAL - Check PostgreSQL Log File - $ERROR Error Fundet" exit $STATE_CRITICALelse ekko "OK - PostgreSQL uden fejl" exit $STATE_OKfi Det vigtige ved scriptet er at skabe de output, der svarer til hver tilstand korrekt. Disse output læses af Nagios, og hvert tal svarer til en tilstand:
0=OK1=WARNING2=CRITICAL3=UKENDT I vores eksempel vil vi kun bruge 2 tilstande, OK og KRITISK, da vi kun er interesserede i at vide, om der er fejl af typen FATAL i vores fejllog i den aktuelle time.
Teksten, som vi bruger før vores exit, vil blive vist af webgrænsefladen på vores Nagios, så det skal være så tydeligt som muligt at bruge dette som en guide til problemet.
Når vi har afsluttet vores overvågningsscript, vil vi fortsætte med at give det udførelsestilladelser, tildele det til brugeren nagios og tilføje det til vores databaseserver NRPE såvel som til vores Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/ libexec/check_postgres_log.sh[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfgcommand[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh[example@sqldat.com ]# vi /usr/local/nagios/etc/objects/postgres3.cfgdefine service { use generic-service; Navn på tjenesteskabelon, der skal bruges værtsnavn postgres3 service_description PostgreSQL LOG check_command check_nrpe!check_postgres_log} Genstart NRPE og Nagios. Så kan vi se vores check i Nagios-grænsefladen:
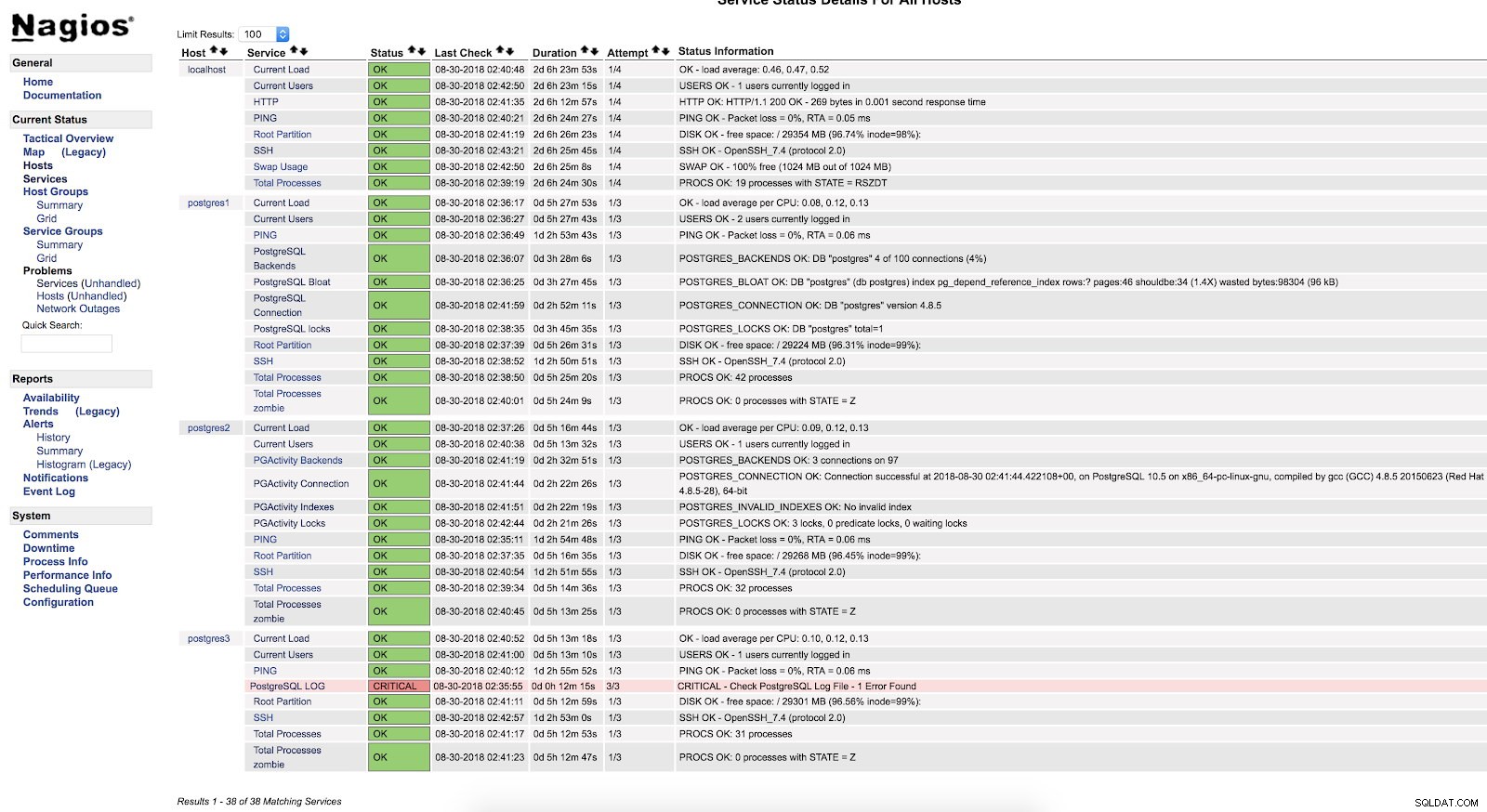 Nagios Script Alerts
Nagios Script Alerts Som vi kan se, er det i en KRITISK tilstand, så hvis vi går til loggen, kan vi se følgende:
2018-08-30 02:29:49.531 UTC [22162] FATAL:Peer-godkendelse mislykkedes for brugeren "postgres"2018-08-30 02:29:49.531 UTC [22162] DETAIL:pg_forbindelse matchede. conf linje 83:"local all all peer" For mere information om, hvad vi kan overvåge i vores PostgreSQL-database, anbefaler jeg, at du tjekker vores præstations- og overvågningsblogs eller dette Postgres Performance-webinar.
Sikkerhed og ydeevne
Når vi konfigurerer enhver overvågning, enten ved hjælp af plugins eller vores eget script, skal vi være meget forsigtige med 2 meget vigtige ting - sikkerhed og ydeevne.
Når vi tildeler de nødvendige tilladelser til overvågning, skal vi være så restriktive som muligt, begrænse adgangen kun lokalt eller fra vores overvågningsserver, bruge sikre nøgler, kryptere trafik, så forbindelsen tillader det minimum, der er nødvendigt for, at overvågningen fungerer.
Med hensyn til ydeevne er overvågning nødvendig, men det er også nødvendigt at bruge det sikkert til vores systemer.
Vi skal være forsigtige med ikke at generere urimelig høj diskadgang eller køre forespørgsler, der påvirker vores databases ydeevne negativt.
Hvis vi har mange transaktioner i sekundet, der genererer gigabyte af logfiler, og vi bliver ved med at lede efter fejl løbende, er det nok ikke det bedste for vores database. Så vi skal holde en balance mellem, hvad vi overvåger, hvor ofte og indvirkningen på ydeevnen.
Konklusion
Der er flere måder at implementere overvågning eller konfigurere den på. Vi kan komme til at gøre det så komplekst eller så enkelt, som vi ønsker. Formålet med denne blog var at introducere dig i overvågningen af PostgreSQL ved hjælp af et af de mest brugte open source-værktøjer. Vi har også set, at konfigurationen er meget fleksibel og kan skræddersyes til forskellige behov.
Og glem ikke, at vi altid kan stole på fællesskabet, så jeg efterlader nogle links, der kunne være til stor hjælp.
Supportforum:https://support.nagios.com/forum/
Kendte problemer:https://github.com/NagiosEnterprises/nagioscore/issues
Nagios-plugins:https://exchange.nagios.org/directory/Plugins
Nagios-plugin til ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol