Kendskab til replikering er et must for enhver, der administrerer databaser. Det er et emne, som du sikkert har set igen og igen, men aldrig bliver gammelt. I denne blog vil vi gennemgå en lille smule af historien om PostgreSQLs indbyggede replikeringsfunktioner og dykke dybt ned i, hvordan streamingreplikering fungerer.
Når vi taler om replikering, vil vi tale meget om WAL'er. Så lad os hurtigt gennemgå lidt om fremskrivningslogfiler.
Write-Ahead Log (WAL)
En Write-Ahead-log er en standardmetode til at sikre dataintegritet, og den er automatisk aktiveret som standard.
WAL'erne er REDO-logfilerne i PostgreSQL. Men hvad er REDO logs egentlig?
REDO-logfiler indeholder alle ændringer, der er foretaget i databasen, og de bruges til replikering, gendannelse, online backup og punkt-i-tidsgendannelse (PITR). Eventuelle ændringer, der ikke er blevet anvendt på datasiderne, kan laves om fra REDO-logfilerne.
Brug af WAL resulterer i et betydeligt reduceret antal diskskrivninger, fordi kun logfilen skal skylles til disken for at garantere, at en transaktion er begået, snarere end hver datafil, der ændres af transaktionen.
En WAL-post vil specificere ændringerne i dataene, bit for bit. Hver WAL-post vil blive tilføjet til en WAL-fil. Indsættelsespositionen er et Log Sequence Number (LSN), en byteforskydning i logfilerne, der stiger med hver ny post.
WAL'erne er gemt i mappen pg_wal (eller pg_xlog i PostgreSQL-versioner <10) under databiblioteket. Disse filer har en standardstørrelse på 16MB (du kan ændre størrelsen ved at ændre --with-wal-segsize-konfigurationsindstillingen, når du bygger serveren). De har et unikt trinvis navn i følgende format:"00000001 00000000 00000000".
Antallet af WAL-filer indeholdt i pg_wal vil afhænge af den værdi, der er tildelt parameteren checkpoint_segments (eller min_wal_size og max_wal_size, afhængigt af versionen) i postgresql.conf-konfigurationsfilen.
En parameter, som du skal konfigurere, når du konfigurerer alle dine PostgreSQL-installationer, er wal_level. wal_level bestemmer, hvor meget information der skrives til WAL. Standardværdien er minimal, hvilket kun skriver den information, der er nødvendig for at komme sig efter et nedbrud eller øjeblikkelig nedlukning. Arkiv tilføjer logning påkrævet til WAL-arkivering; hot_standby tilføjer yderligere information, der er nødvendig for at køre skrivebeskyttede forespørgsler på en standby-server; logical tilføjer information, der er nødvendig for at understøtte logisk afkodning. Denne parameter kræver en genstart, så det kan være svært at ændre på kørende produktionsdatabaser, hvis du har glemt det.
For yderligere information kan du tjekke den officielle dokumentation her eller her. Nu hvor vi har dækket WAL, lad os gennemgå historien om replikering i PostgreSQL.
Historie om replikering i PostgreSQL
Den første replikeringsmetode (varm standby), som PostgreSQL implementerede (version 8.2, tilbage i 2006) var baseret på logforsendelsesmetoden.
Dette betyder, at WAL-posterne flyttes direkte fra en databaseserver til en anden for at blive anvendt. Vi kan sige, at det er en kontinuerlig PITR.
PostgreSQL implementerer filbaseret logforsendelse ved at overføre WAL-poster én fil (WAL-segment) ad gangen.
Denne replikeringsimplementering har ulempen:hvis der er en større fejl på de primære servere, vil transaktioner, der endnu ikke er afsendt, gå tabt. Så der er et vindue til tab af data (du kan justere dette ved at bruge parameteren archive_timeout, som kan indstilles til så lavt som et par sekunder. Men en så lav indstilling vil øge den nødvendige båndbredde til filforsendelse betydeligt).
Vi kan repræsentere denne filbaserede logforsendelsesmetode med billedet nedenfor:
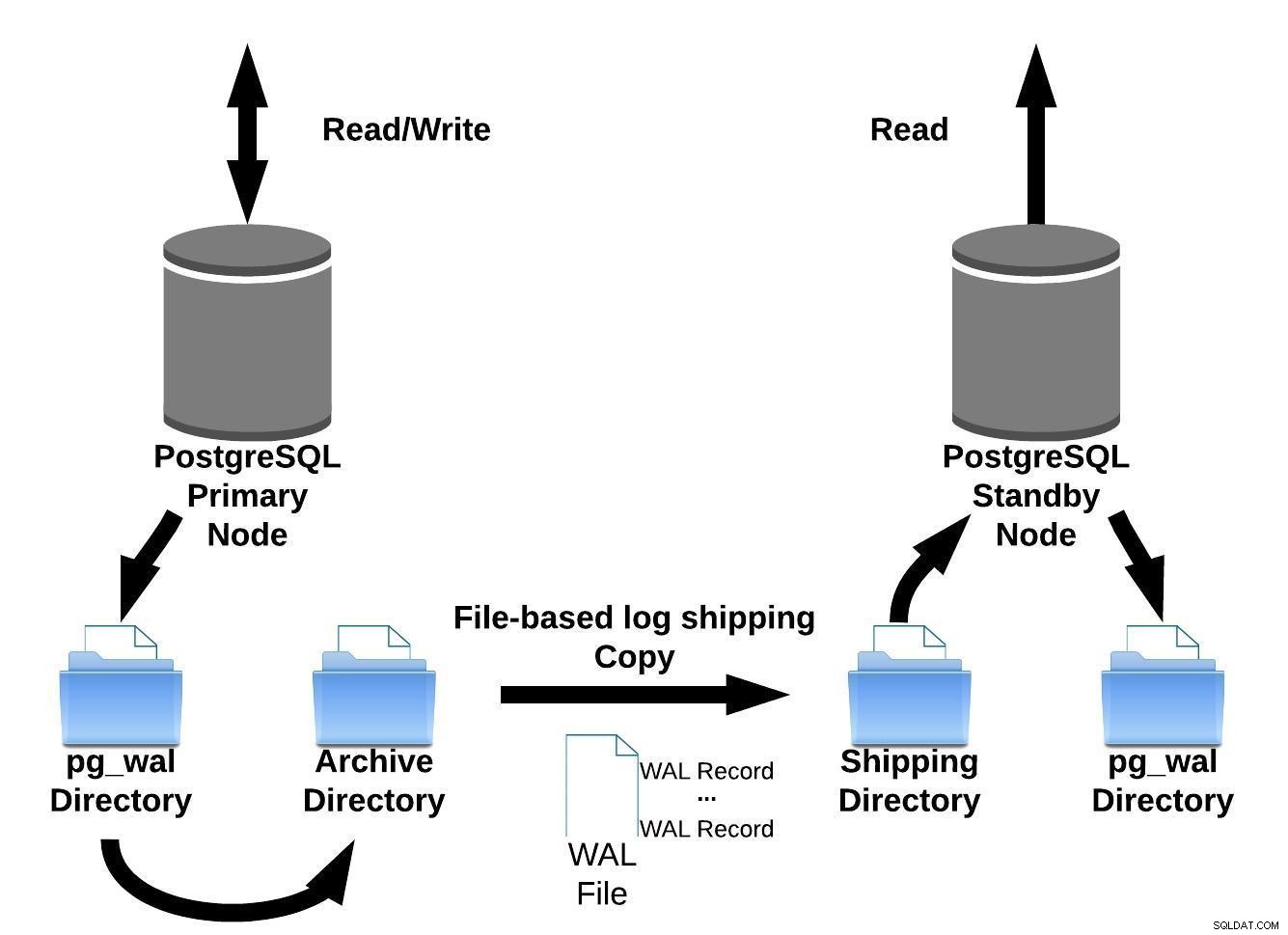 PostgreSQL-filbaseret logforsendelse
PostgreSQL-filbaseret logforsendelseDerefter i version 9.0 (tilbage i 2010) ), blev streaming-replikering introduceret.
Streaming-replikering giver dig mulighed for at holde dig mere opdateret, end det er muligt med filbaseret logforsendelse. Dette fungerer ved at overføre WAL-poster (en WAL-fil er sammensat af WAL-poster) på farten (record-baseret logforsendelse) mellem en primær server og en eller flere standby-servere uden at vente på, at WAL-filen bliver udfyldt.
I praksis vil en proces kaldet WAL-modtager, der kører på standby-serveren, oprette forbindelse til den primære server ved hjælp af en TCP/IP-forbindelse. I den primære server findes en anden proces, kaldet WAL-afsender, og den er ansvarlig for at sende WAL-registre til standby-serveren, efterhånden som de sker.
Følgende diagram repræsenterer streamingreplikering:
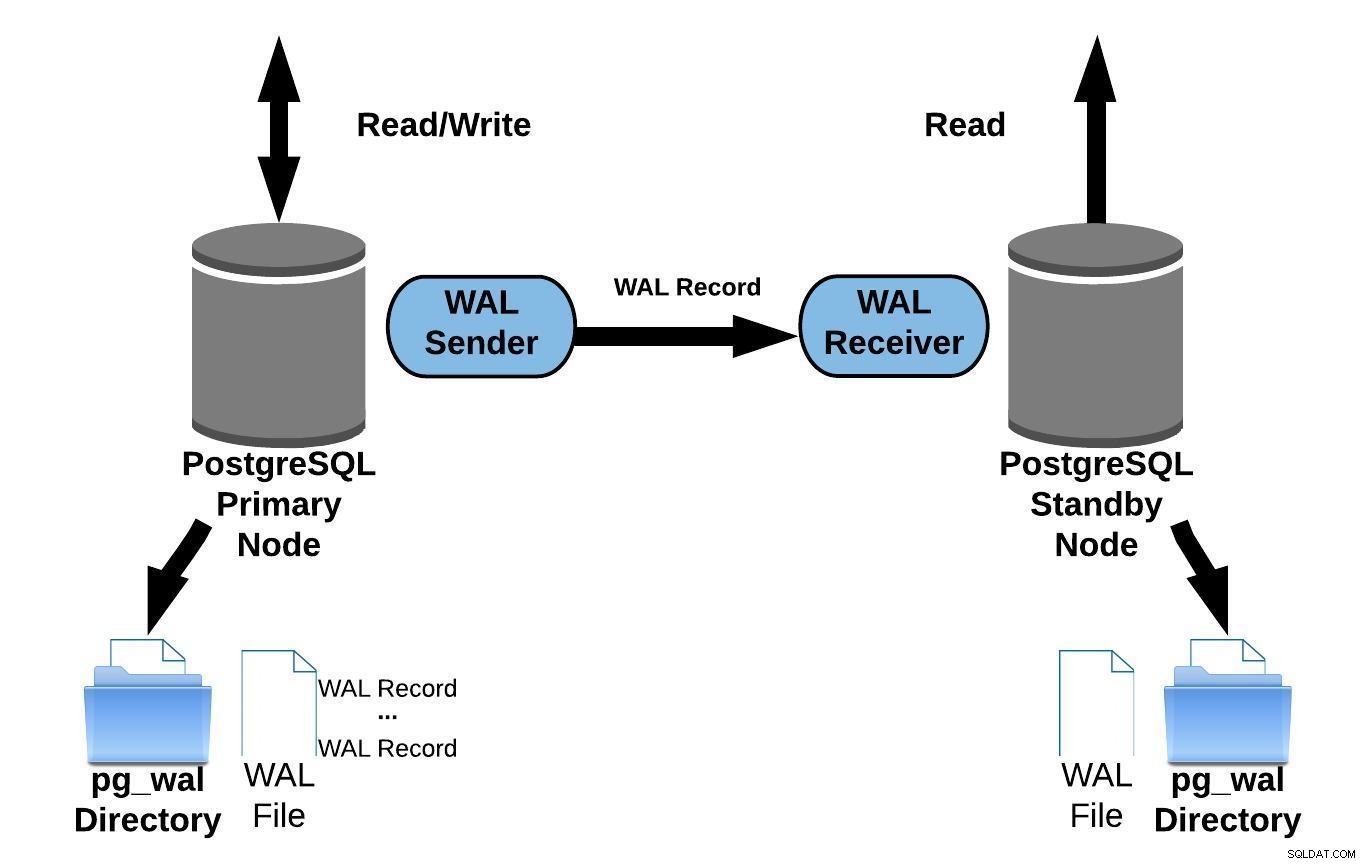 PostgreSQL Streaming-replikering
PostgreSQL Streaming-replikeringNår du ser på diagrammet ovenfor, undrer du dig måske over, hvad der sker når kommunikationen mellem WAL-afsenderen og WAL-modtageren fejler?
Når du konfigurerer streamingreplikering, har du mulighed for at aktivere WAL-arkivering.
Dette trin er ikke obligatorisk, men er ekstremt vigtigt for en robust replikeringsopsætning. Det er nødvendigt at undgå, at hovedserveren genbruger gamle WAL-filer, som endnu ikke er blevet anvendt på standby-serveren. Hvis dette sker, bliver du nødt til at genskabe replikaen fra bunden.
Når du konfigurerer replikering med kontinuerlig arkivering, starter det fra en sikkerhedskopi. For at nå den synkroniserede tilstand med den primære, skal den anvende alle de ændringer, der er hostet i WAL, der skete efter sikkerhedskopieringen. Under denne proces vil standby først gendanne alle de tilgængelige WAL på arkivplaceringen (gøres ved at kalde restore_command). Restore_command vil mislykkes, når den når den sidst arkiverede WAL-record, så derefter vil standbyen kigge på pg_wal-mappen for at se, om ændringen eksisterer der (dette virker for at undgå datatab, når de primære servere går ned og nogle ændringer, der allerede er blevet flyttet og anvendt på replikaen er endnu ikke blevet arkiveret).
Hvis det mislykkes, og den anmodede post ikke findes der, vil den begynde at kommunikere med den primære server via streamingreplikering.
Når streamingreplikering mislykkes, vil den gå tilbage til trin 1 og gendanner posterne fra arkivet igen. Denne sløjfe af genforsøg fra arkivet, pg_wal og via streaming-replikering fortsætter, indtil serveren stopper, eller failover udløses af en triggerfil.
Følgende diagram repræsenterer en streaming-replikeringskonfiguration med kontinuerlig arkivering:
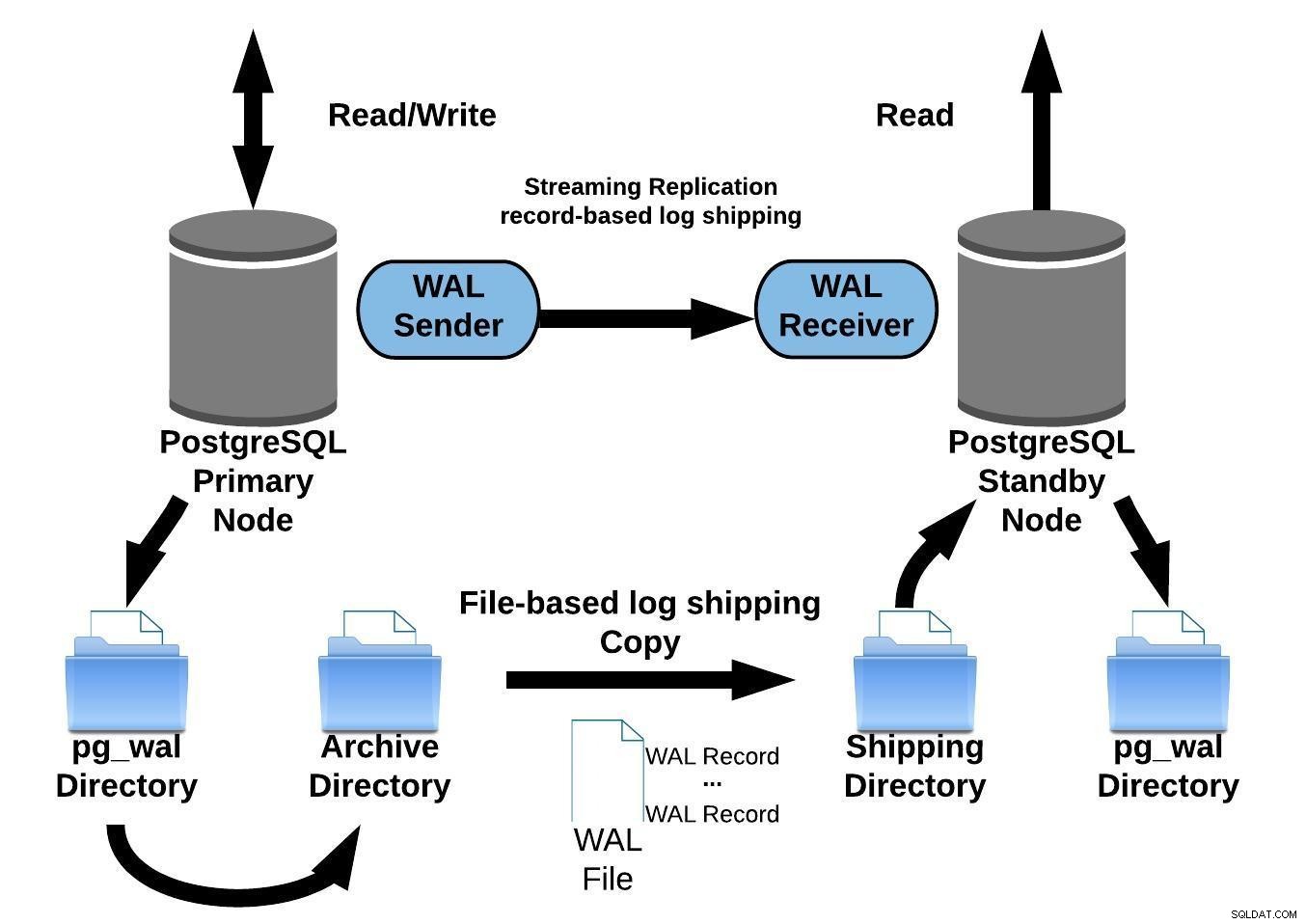 PostgreSQL streaming replikering med kontinuerlig arkivering
PostgreSQL streaming replikering med kontinuerlig arkiveringStreaming replikering er asynkron som standard, så kl. ethvert givet øjeblik, kan du have nogle transaktioner, der kan forpligtes til den primære server og endnu ikke replikeres til standby-serveren. Dette indebærer et vist potentielt datatab.
Men denne forsinkelse mellem commit og virkningen af ændringerne i replikaen formodes at være virkelig lille (nogle millisekunder), naturligvis forudsat at replikaserveren er kraftig nok til at følge med belastningen.
I tilfælde, hvor selv risikoen for mindre datatab ikke er acceptabel, introducerede version 9.1 funktionen til synkron replikering.
I synkron replikering venter hver commit af en skrivetransaktion, indtil der modtages bekræftelse på, at commit er skrevet til skrive-ahead-log på disken på både den primære server og standby-serveren.
Denne metode minimerer muligheden for tab af data; for at det kan ske, skal du have både den primære og standbyen til at fejle samtidigt.
Den åbenlyse ulempe ved denne konfiguration er, at responstiden for hver skrivetransaktion øges, da den skal vente, indtil alle parter har svaret. Så tidspunktet for en commit er som minimum rundrejsen mellem den primære og replikaen. Skrivebeskyttede transaktioner vil ikke blive påvirket af dette.
For at konfigurere synkron replikering skal du angive et application_name i primary_conninfo for gendannelsen for hver standby server.conf fil:primary_conninfo ='...aplication_name=standbyX' .
Du skal også angive listen over de standby-servere, der vil deltage i den synkrone replikering:synchronous_standby_name ='standbyX,standbyY'.
Du kan konfigurere en eller flere synkrone servere, og denne parameter specificerer også hvilken metode (FØRST og ALLE) til at vælge synkrone standbyer blandt de anførte. For mere information om opsætning af synkron replikeringstilstand, tjek denne blog. Det er også muligt at opsætte synkron replikering ved implementering via ClusterControl.
Når du har konfigureret din replikering, og den er oppe og køre, skal du implementere overvågning
Overvågning af PostgreSQL-replikering
Visningen pg_stat_replication på masterserveren har en masse relevant information:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00 Lad os se dette i detaljer:
-
pid:Proces-id for walsender-processen.
-
usesysid:OID for bruger, som bruges til streaming replikering.
-
brugsnavn:Navn på bruger, der bruges til streamingreplikering.
-
application_name:Programnavn forbundet til master.
-
client_addr:Adresse på standby-/streamingreplikering.
-
client_hostname:Værtsnavn på standby.
-
client_port:TCP-portnummer, hvorpå standby kommunikerer med WAL-afsender.
-
backend_start:Starttidspunkt, når SR sluttede til Primary.
-
tilstand:Aktuel WAL-afsendertilstand, dvs. streaming.
-
sent_lsn:Sidste transaktionsplacering sendt til standby.
-
write_lsn:Sidste transaktion skrevet på disk i standby.
-
flush_lsn:Sidste transaktionsskyl på disk i standby.
-
replay_lsn:Sidste transaktionsflush på disk i standby.
-
sync_priority:Prioritet for standbyserver valgt som synkron standby.
-
sync_state:Synkroniser standbytilstand (er den asynkron eller synkron).
Du kan også se WAL-afsender-/modtagerprocesserne, der kører på serverne.
Afsender (primær node):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0 Modtager (standby node):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0 En måde at kontrollere, hvor opdateret din replikering er, er ved at kontrollere mængden af WAL-poster, der er genereret på den primære server, men endnu ikke anvendt på standby-serveren.
Primær:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row) Standby:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row) Du kan bruge følgende forespørgsel i standby-noden for at få forsinkelsen i sekunder:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row) Og du kan også se den sidst modtagne besked:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row) Overvågning af PostgreSQL-replikering med ClusterControl
For at overvåge din PostgreSQL-klynge kan du bruge ClusterControl, som giver dig mulighed for at overvåge og udføre adskillige yderligere administrationsopgaver såsom implementering, sikkerhedskopiering, udskalering og mere.
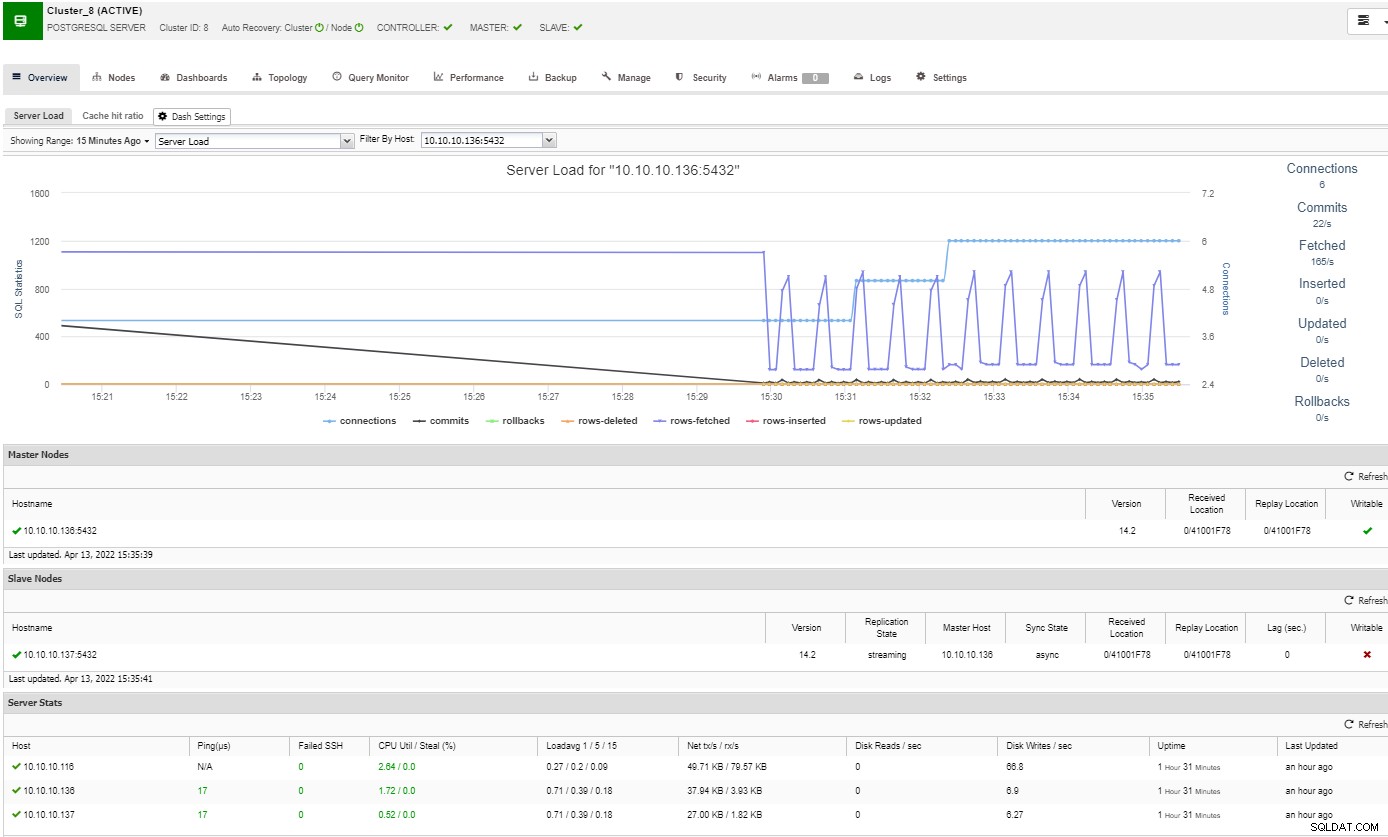
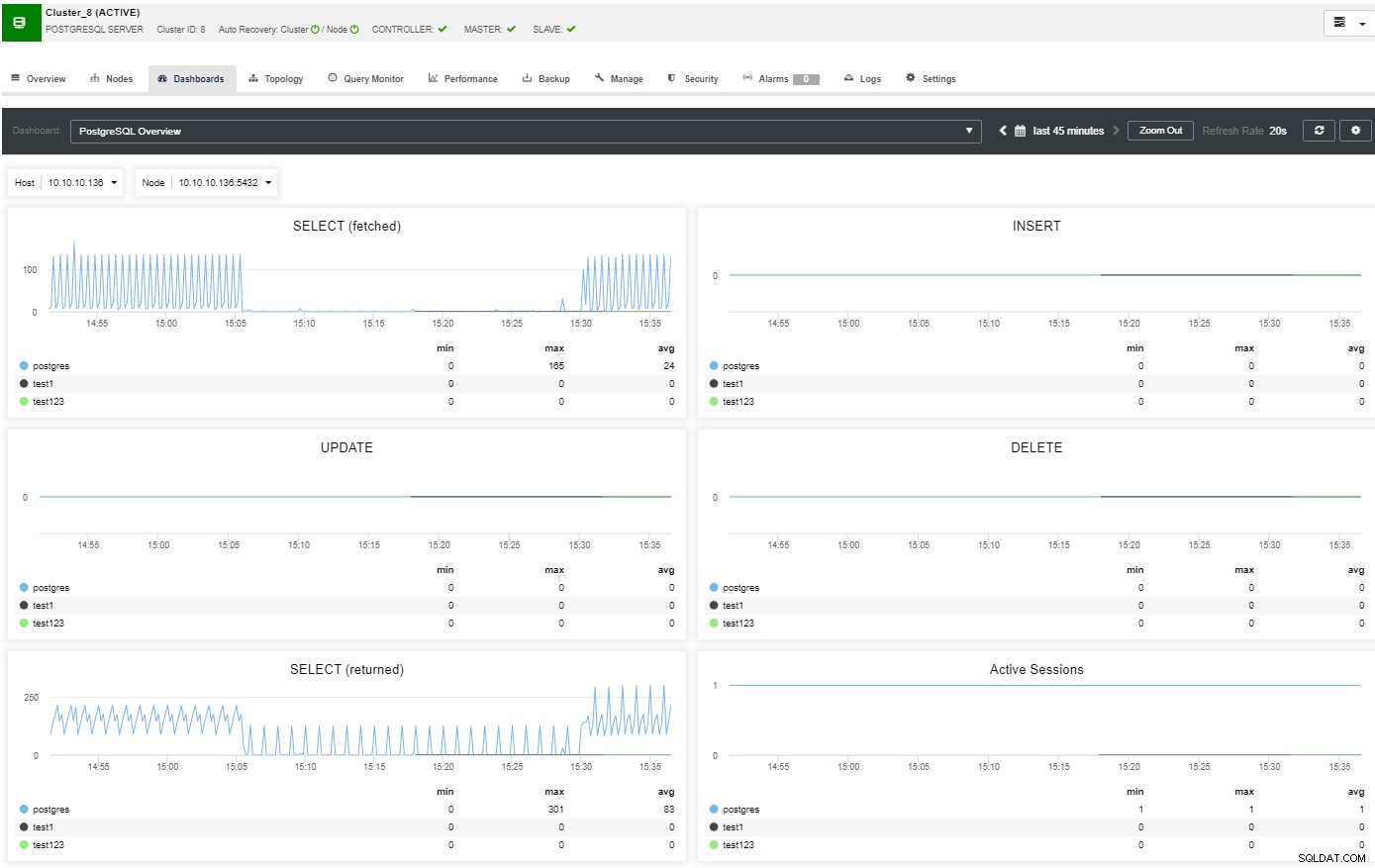
I oversigtssektionen vil du have det fulde billede af din databaseklynges nuværende status. For at se flere detaljer kan du få adgang til dashboardsektionen, hvor du vil se masser af nyttige oplysninger opdelt i forskellige grafer.
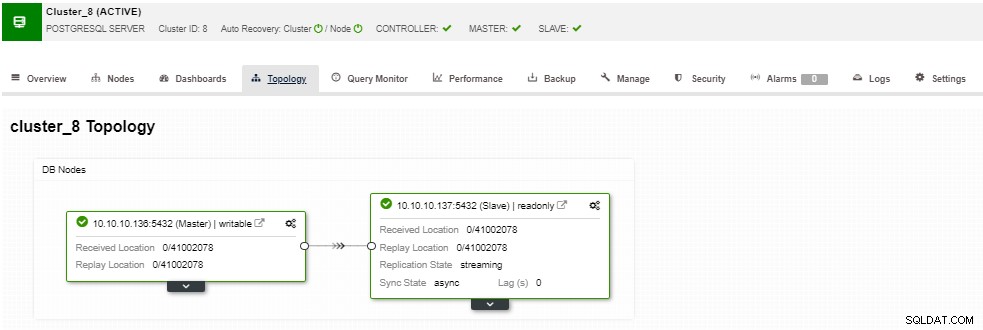
I topologisektionen kan du se din aktuelle topologi i en bruger- venlig måde, og du kan også udføre forskellige opgaver over noderne ved at bruge knappen Node Action.
Streaming-replikering er baseret på at sende WAL-posterne og anvende dem på standby server, det dikterer hvilke bytes der skal tilføjes eller ændres i hvilken fil. Som et resultat heraf er standby-serveren faktisk en bit-for-bit kopi af den primære server. Der er dog nogle velkendte begrænsninger her:
-
Du kan ikke replikere til en anden version eller arkitektur.
-
Du kan ikke ændre noget på standby-serveren.
-
Du har ikke meget granularitet i, hvad du replikerer.
Så for at overvinde disse begrænsninger har PostgreSQL 10 tilføjet understøttelse af logisk replikering
Logisk replikering
Logisk replikering vil også bruge informationen i WAL-filen, men den vil afkode den til logiske ændringer. I stedet for at vide, hvilken byte der er ændret, vil den vide præcist, hvilke data der er blevet indsat i hvilken tabel.
Den er baseret på en "publicer" og "abonner"-model med en eller flere abonnenter, der abonnerer på en eller flere publikationer på en udgivernode, der ser sådan ud:
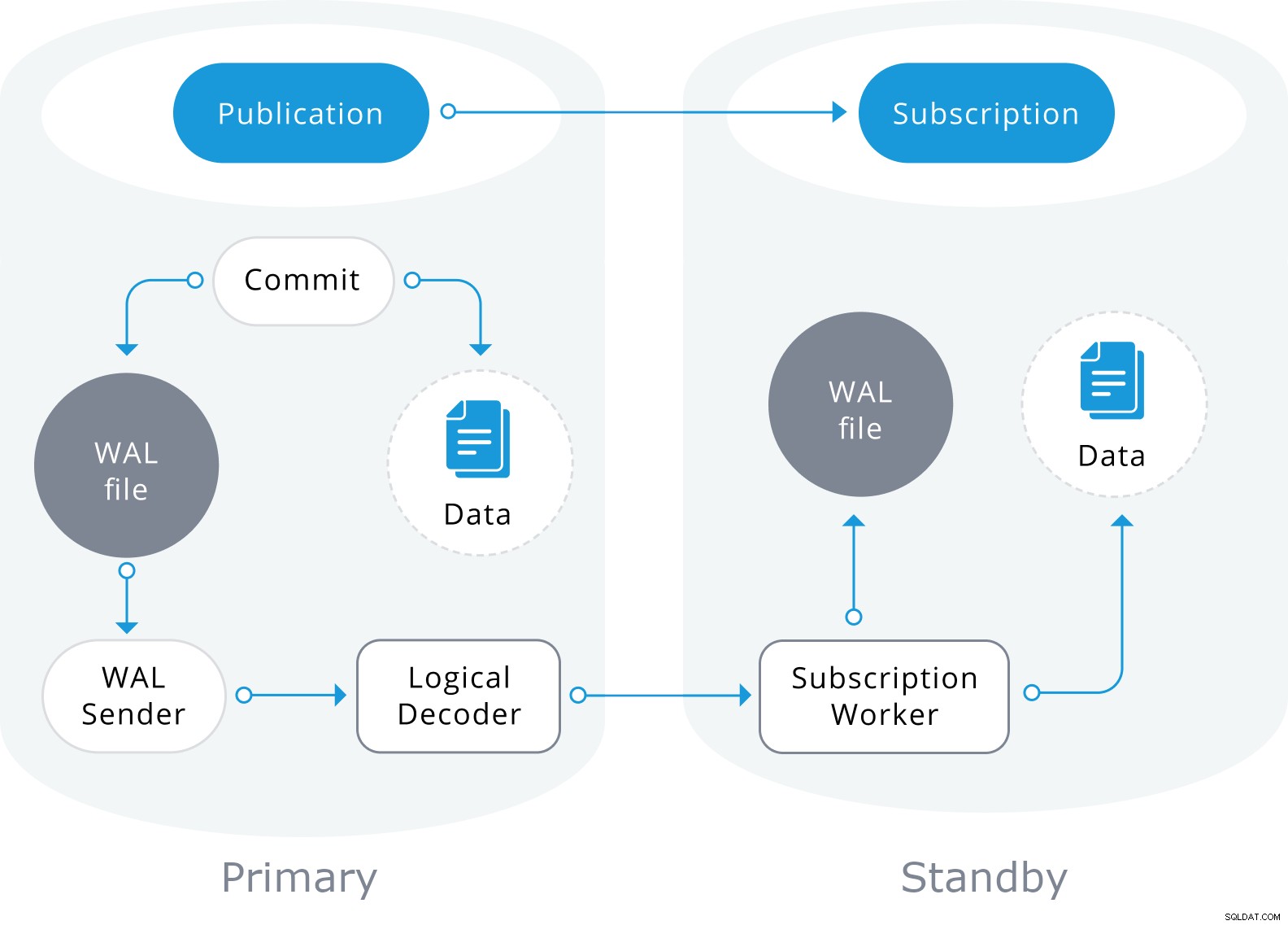
Afslutning
Med streaming-replikering kan du kontinuerligt sende og anvende WAL-poster til dine standby-servere, hvilket sikrer, at oplysninger, der er opdateret på den primære server, overføres til standby-serveren i realtid, så begge kan forblive synkroniserede .
ClusterControl gør det nemt at opsætte streamingreplikering, og du kan evaluere det gratis i 30 dage.
Hvis du vil lære mere om logisk replikering i PostgreSQL, skal du sørge for at tjekke denne oversigt over logisk replikering og dette indlæg om bedste praksis for PostgreSQL-replikering.
For flere tips og bedste fremgangsmåder til at administrere din open source-baserede database, følg os på Twitter og LinkedIn og abonner på vores nyhedsbrev for regelmæssige opdateringer.