Den del, jeg altid har fundet forvirrende, er startomkostningerne vs. samlede omkostninger. Jeg Googler dette hver gang jeg glemmer det, hvilket bringer mig tilbage hertil, hvilket ikke forklarer forskellen, og det er derfor, jeg skriver dette svar. Dette er, hvad jeg har hentet fra Postgres EXPLAIN dokumentation, forklaret som jeg forstår det.
Her er et eksempel fra en applikation, der administrerer et forum:
EXPLAIN SELECT * FROM post LIMIT 50;
Limit (cost=0.00..3.39 rows=50 width=422)
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
Her er den grafiske forklaring fra PgAdmin:

(Når du bruger PgAdmin, kan du pege med musen på en komponent for at læse omkostningsdetaljerne.)
Udgiften er repræsenteret som en tupel, f.eks. prisen på LIMIT er cost=0.00..3.39 og omkostningerne ved sekventiel scanning af post er cost=0.00..15629.12 . Det første tal i tuplen er startomkostningerne og det andet tal er de samlede omkostninger . Fordi jeg brugte EXPLAIN og ikke EXPLAIN ANALYZE , disse omkostninger er skøn, ikke faktiske mål.
- Opstartsomkostninger er et tricky koncept. Det repræsenterer ikke kun mængden af tid, før den komponent starter . Det repræsenterer mængden af tid mellem det tidspunkt, hvor komponenten begynder at udføre (indlæsning af data), og når komponenten udsender sin første række .
- Samlede omkostninger er hele udførelsestiden for komponenten, fra den begynder at læse data til den er færdig med at skrive sit output.
Som en komplikation inkluderer hver "forælder" nodes omkostninger omkostningerne til dens underordnede noder. I tekstgengivelsen er træet repræsenteret ved indrykning, f.eks. LIMIT er en overordnet node og Seq Scan er dets barn. I PgAdmin-repræsentationen peger pilene fra barn til forælder - retningen af datastrømmen - hvilket kan være kontraintuitivt, hvis du er fortrolig med grafteori.
Dokumentationen siger, at omkostningerne er inklusive alle underordnede noder, men bemærk, at de samlede omkostninger for den overordnede 3.39 er meget mindre end den samlede pris for dets underordnede 15629.12 . Samlede omkostninger er ikke inklusive, fordi en komponent som LIMIT behøver ikke at behandle hele inputtet. Se EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2; eksempel i Postgres EXPLAIN dokumentation.
I eksemplet ovenfor er opstartstiden nul for begge komponenter, fordi ingen af komponenterne skal udføre nogen behandling, før den begynder at skrive rækker:en sekventiel scanning læser den første række i tabellen og udsender den. LIMIT læser dens første række og udsender den derefter.
Hvornår skal en komponent bearbejde en masse, før den kan begynde at udlæse rækker? Der er mange mulige årsager, men lad os se på et klart eksempel. Her er den samme forespørgsel fra før, men den indeholder nu en ORDER BY klausul:
EXPLAIN SELECT * FROM post ORDER BY body LIMIT 50;
Limit (cost=23283.24..23283.37 rows=50 width=422)
-> Sort (cost=23283.24..23859.27 rows=230412 width=422)
Sort Key: body
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
Og grafisk:
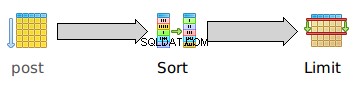
Igen, den sekventielle scanning på post har ingen startomkostninger:den begynder at udskrive rækker med det samme. Men den slags har en betydelig opstartsomkostning 23283.24 fordi den skal sortere hele tabellen, før den kan udskrive en enkelt række . De samlede omkostninger af typen 23859.27 er kun lidt højere end opstartsomkostningerne, hvilket afspejler det faktum, at når hele datasættet er blevet sorteret, kan de sorterede data udsendes meget hurtigt.
Bemærk, at starttiden for LIMIT 23283.24 er nøjagtigt lig med opstartstiden af slagsen. Dette er ikke fordi LIMIT selv har en høj opstartstid. Den har faktisk nul opstartstid i sig selv, men EXPLAIN opruller alle de underordnede omkostninger for hver forælder, så LIMIT opstartstid inkluderer summen af opstartstiderne for dets børn.
Denne sammenlægning af omkostninger kan gøre det vanskeligt at forstå udførelsesomkostningerne for hver enkelt komponent. For eksempel vores LIMIT har nul opstartstid, men det er ikke indlysende ved første øjekast. Af denne grund har flere andre personer linket til explain.depesz.com, et værktøj skabt af Hubert Lubaczewski (a.k.a. depesz), som hjælper med at forstå EXPLAIN ved blandt andet at trække børneomkostninger fra forældreomkostninger. Han nævner nogle andre kompleksiteter i et kort blogindlæg om sit værktøj.