Nå, at analysere spredningen af SARS-CoV-2 coronavirus var ikke min drømmeanvendelse . Men baseret på svarene på Ferry Djajas Tracking Coronavirus COVID-19 nær realtid med SAP HANA XSA-artikel besluttede jeg også at tilføje mine to grossy.
[Opdateret den 20-03-30 med de ændrede links til kildedataene; og det nye kortoutput baseret på den nye datagranularitet. Tak Douglas Maltby for din kommentar!]
I sit blogindlæg brugte Ferry JavaScript i SAP HANA XSA til at trække data fra CSV-filer, der opdateres dagligt af Johns Hopkins University.
Jeg vil gerne vise dig, hvordan du kan trække og indlæse disse filer i SAP HANA ved hjælp af nogle få linjer kode takket være SAP HANA Python Client API for Machine Learning (hana_ml pakke).
Nogle mennesker var forvirrede med visualiseringen på kortet i slutningen - bemærk venligst, at denne artikel fokuserer på teknisk brug, der forbinder forskellige komponenter, ikke på at udføre dyb analyse af coronavirus-data.
Hent Python-miljøet, f.eks. Jupyter
Jeg vil bruge Jupyter i Docker-beholderen til det. Tag et kig på mit tidligere indlæg Understanding containers (del 05):delte filer mellem værten og containere, hvis du ikke er bekendt med, hvordan man starter det. Du kan også udføre de samme trin nedenfor fra et hvilket som helst andet Python-miljø.
Så jeg har min container myjupyter01 løb. Jeg er forbundet til Jupyter UI som beskrevet i den forrige blog.
Installer hana_ml
Jupyter-billedet, jeg brugte fra Docker Hub-registret, var jupyter/minimal-notebook . Den indeholder allerede nogle populære databehandlingspakker, såsom pandas .
Men derudover skal jeg installere hana_ml , som - i sin nuværende version 1.0.8 - er tilgængelig på PyPI-lageret:https://pypi.org/project/hana-ml/.
Kommandoen til at køre installationen er python -m pip install hana_ml , men fordi jeg kører det fra Jupyter notebook med Python3-kernen, skal jeg køre det med ! i begyndelsen:
!python -m pip install hana_ml
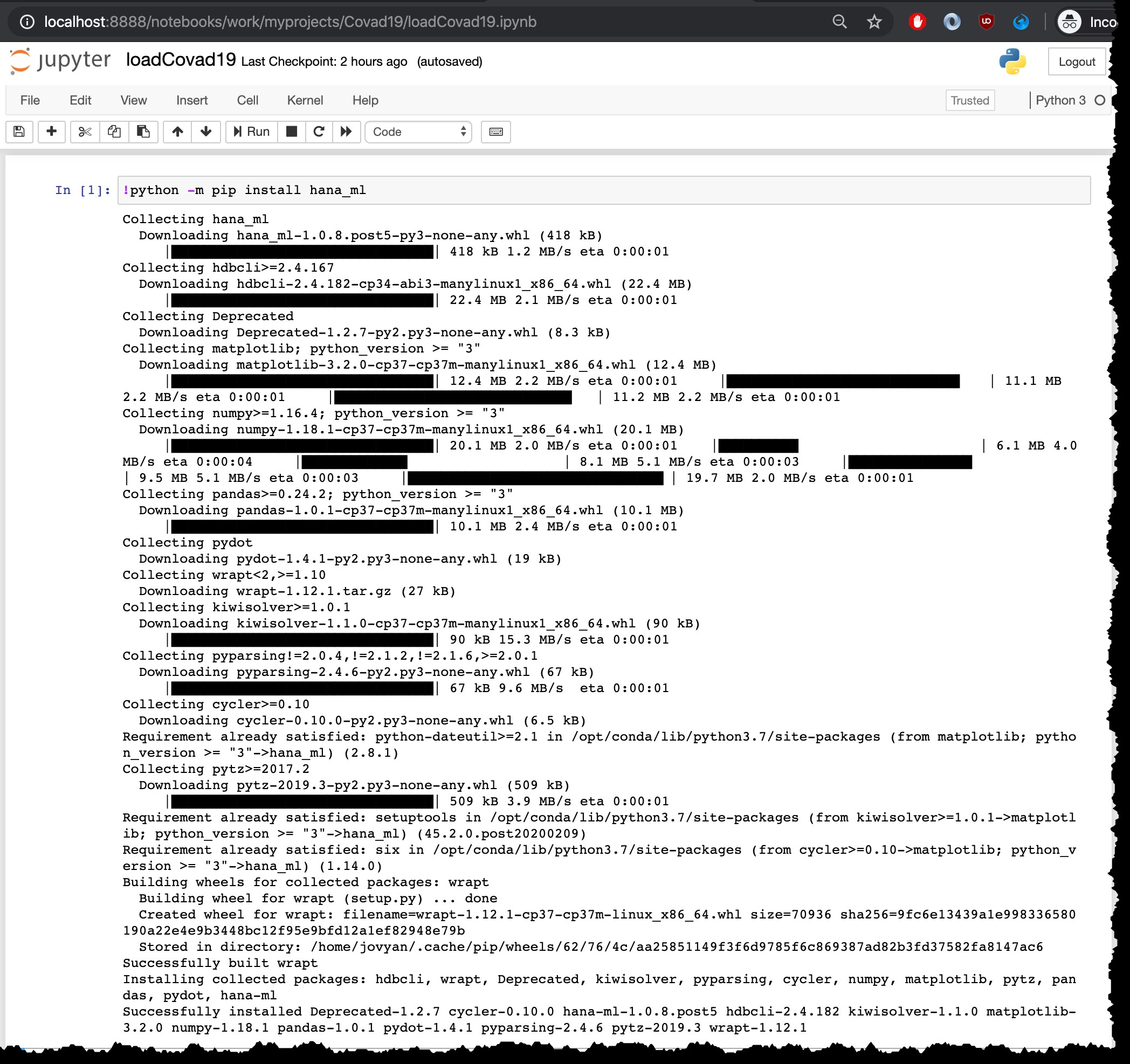
Dette installationstrin skal naturligvis kun udføres én gang. Ingen grund til at køre den igen i samme beholder, f.eks. når du genindlæser de nyeste filer.
Brug pandas at importere filer med data
Lad os importere de samme tre filer (confirmed , deaths , recovered ) fra https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series som Ferry brugte i sit eksempel.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
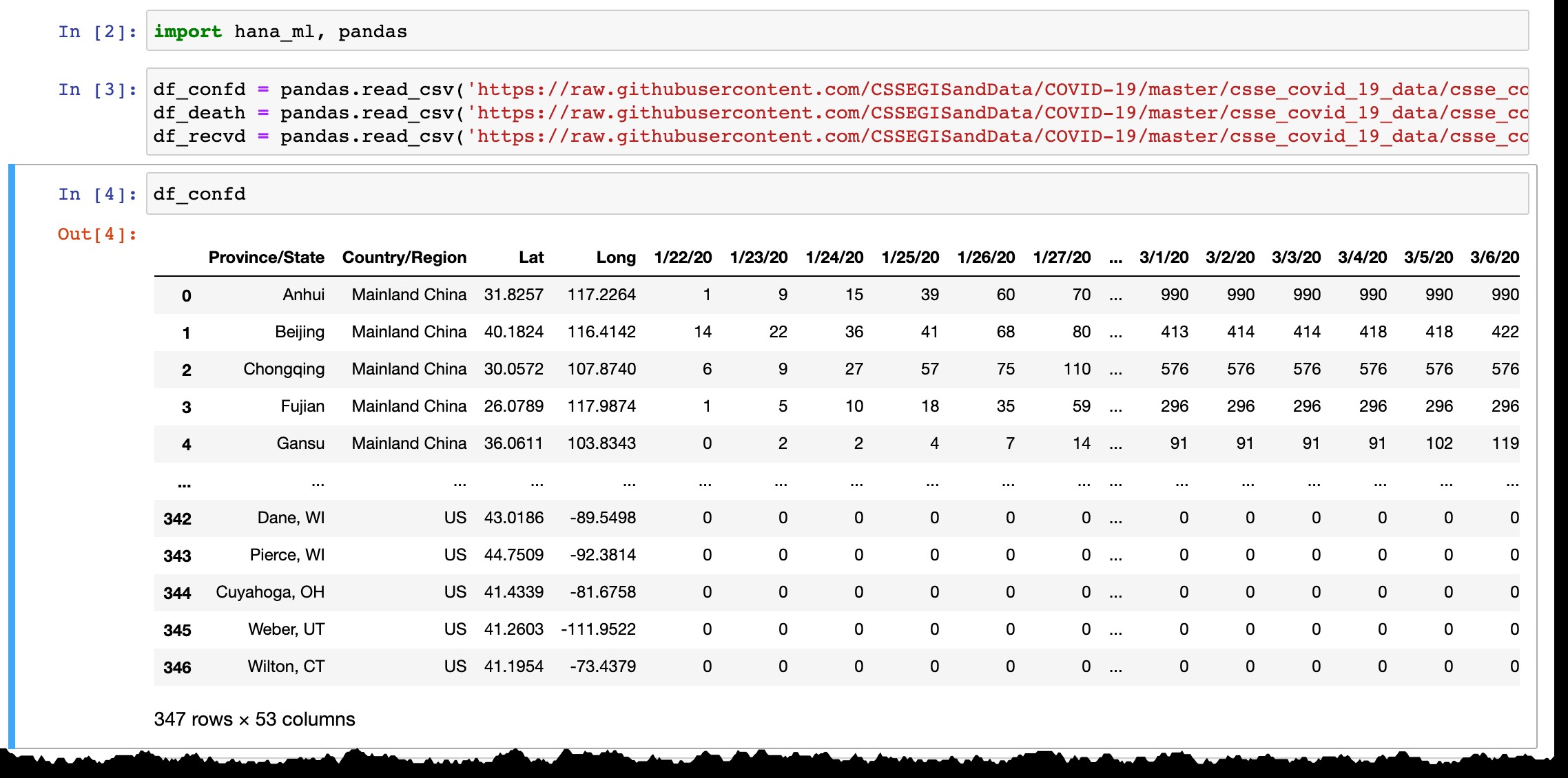
Som du kan se fra forhåndsvisningen af Pandas-datarammen, viser den kun lande eller provinser med bekræftede tilfælde, og hver dag tilføjes den nye kolonne med de seneste data fra den foregående dag. Linjer tilføjes, når de første tilfælde er bekræftet i den nye region.
Brug pandas for at omformatere datarammen
Inden du fortsætter dataene i SAP HANA, lad os:
- Fjern alle datokolonner undtagen den sidste,
- Omdøb den sidste kolonne fra den faktiske dato (som dagens
3/10/20tilConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
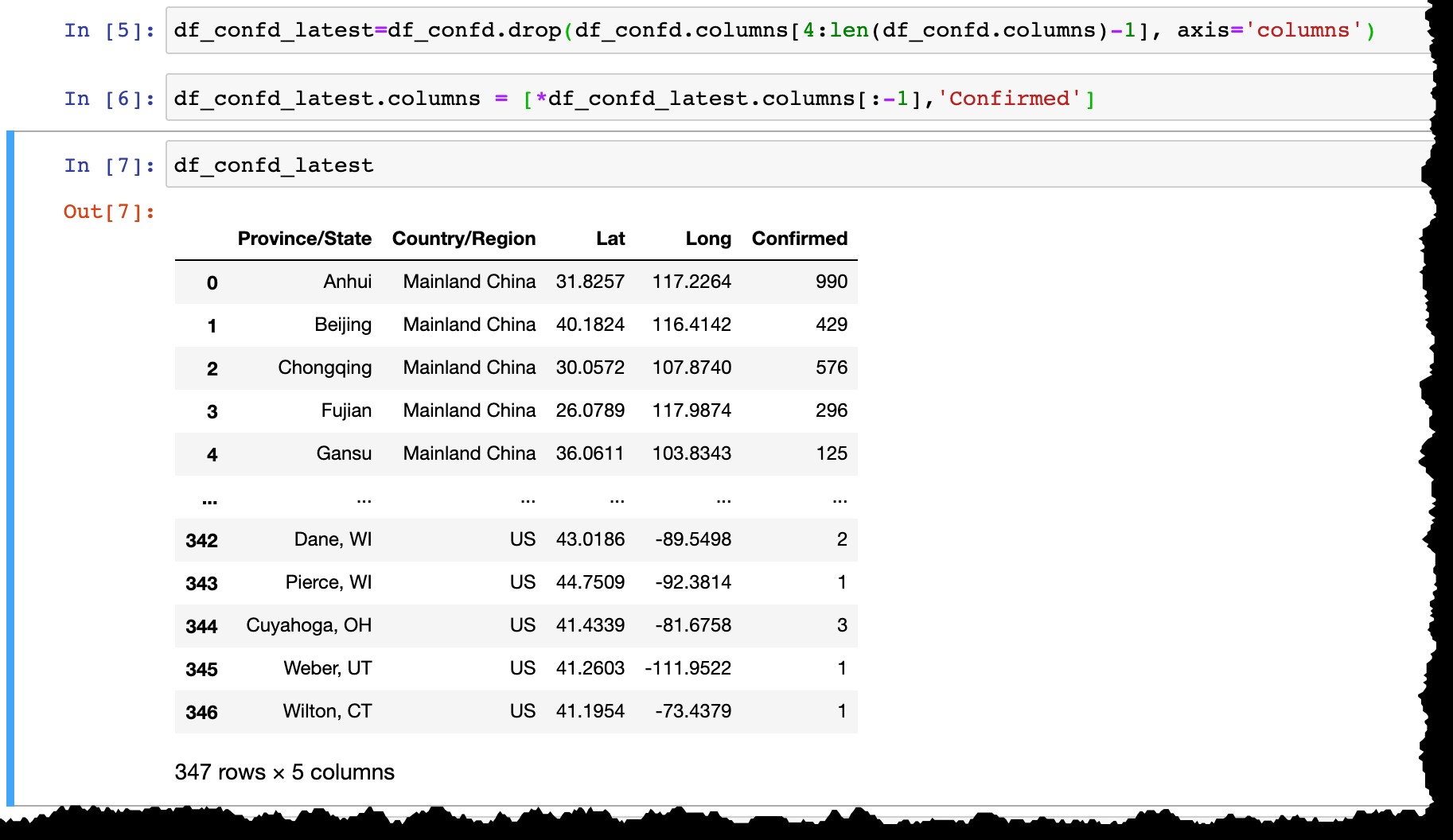
Brug hana_ml for at bevare data i SAP HANA-tabel
Lad mig nu oprette forbindelse til min instans af SAP HANA Express med brugeren hanaml der allerede findes der...
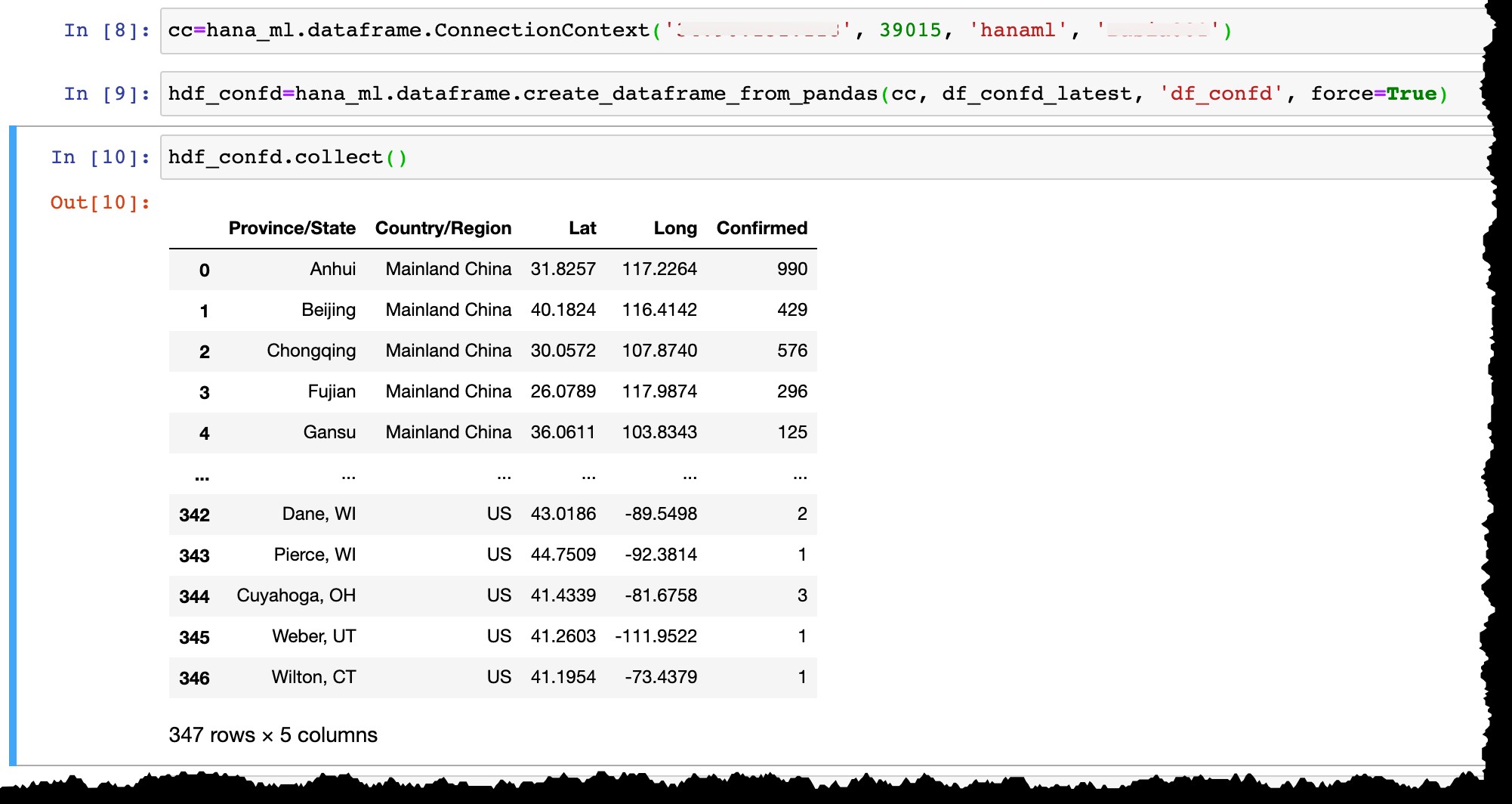
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…og konverter Pandas-datarammen df_confd_latest ind i en HANA-dataramme hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Når HANA-datarammen er oprettet:
- Der oprettes en fysisk kolonnetabel i HANA, og data fra Pandas dataramme indsættes der,
- HANA-dataramme
hdf_confdi Python gemmer ingen data på din bærbare computer, men peger kun på en tabelHANAML.df_confdi SAP HANA-serverhukommelsen, og alle Python-handlinger på HANA-datarammen udføres fysisk i HANA db uden at flytte data mellem serveren og en klient, - For at vise resultatet af enhver handling skal vi anvende
collect()metode til at konvertere HANA-dataramme til Pandas (og som et resultat at bringe data fra HANA db-server til den lokale klient).
Brug DBeaver til at kontrollere data i SAP HANA...
Du husker måske, at jeg allerede brugte DBeaver - det gratis databaseværktøj, der understøtter SAP HANA - i mit tidligere indlæg "GeoArt med SAP HANA og DBeaver".
Jeg bruger det nu igen, og jeg kan faktisk finde tabellen df_confd i skemaet HANAML med alle data fra kilde-Pandas-datarammen.
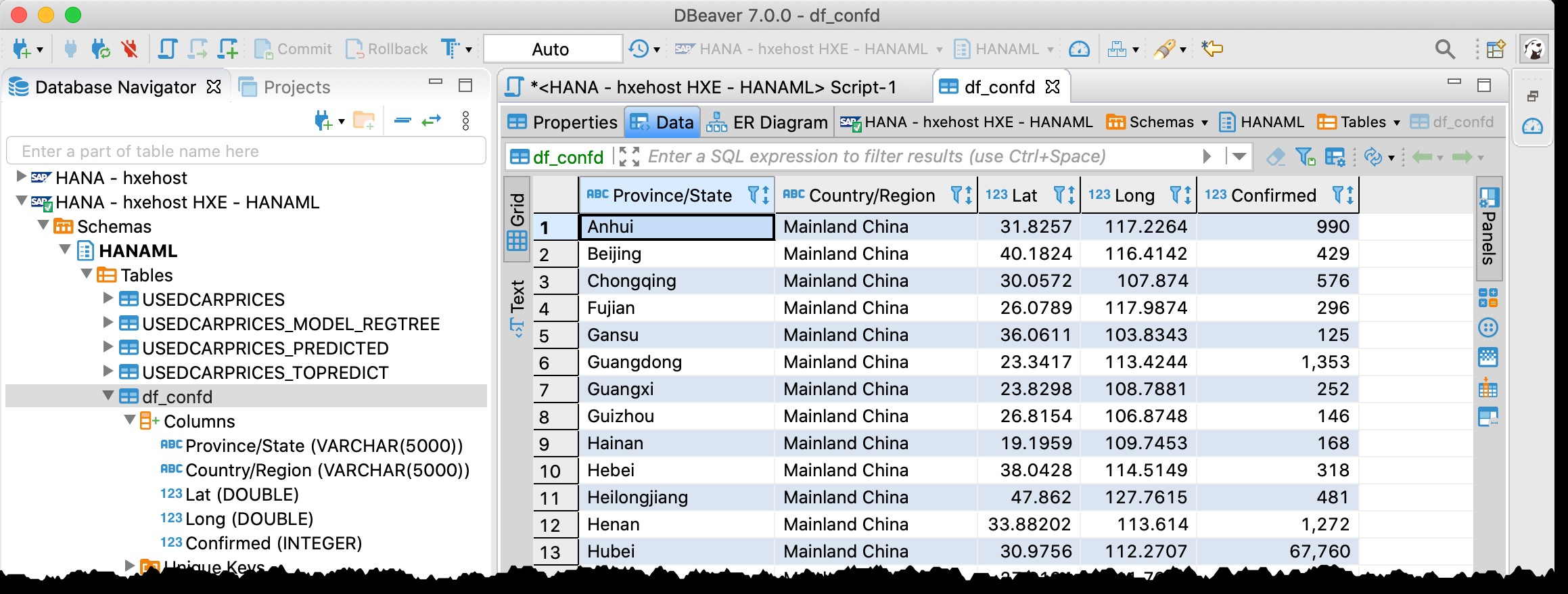
...og lav en rumlig forhåndsvisning
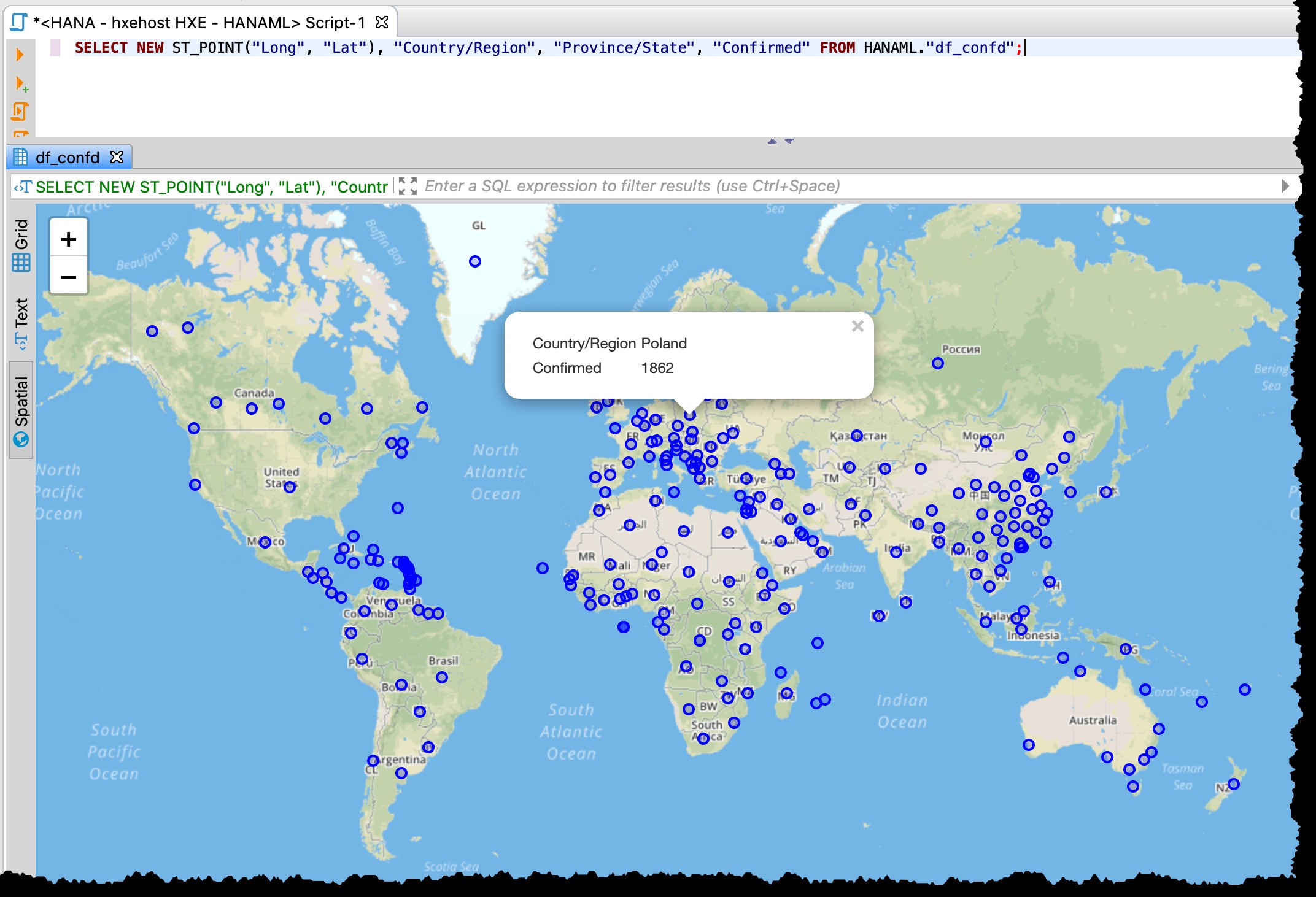
Da tabellen indeholder bredde- og længdegradskolonner, kan jeg visualisere berørte lande/stater direkte fra DBeaver med følgende SQL ved hjælp af forhåndsvisning af geodata.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Jeg var nødt til at ændre kortprojektionen til EPSG:4326 for at få disse punkter på kortet. Og DBeaver viser mig resten af registreringsdataene, når jeg klikker på et punkt.
[Nedenfor er det gamle skærmbillede fra 2020-03-11, som også demonstrerer den forskellige granularitet af f.eks. Amerikanske data brugt på det tidspunkt]
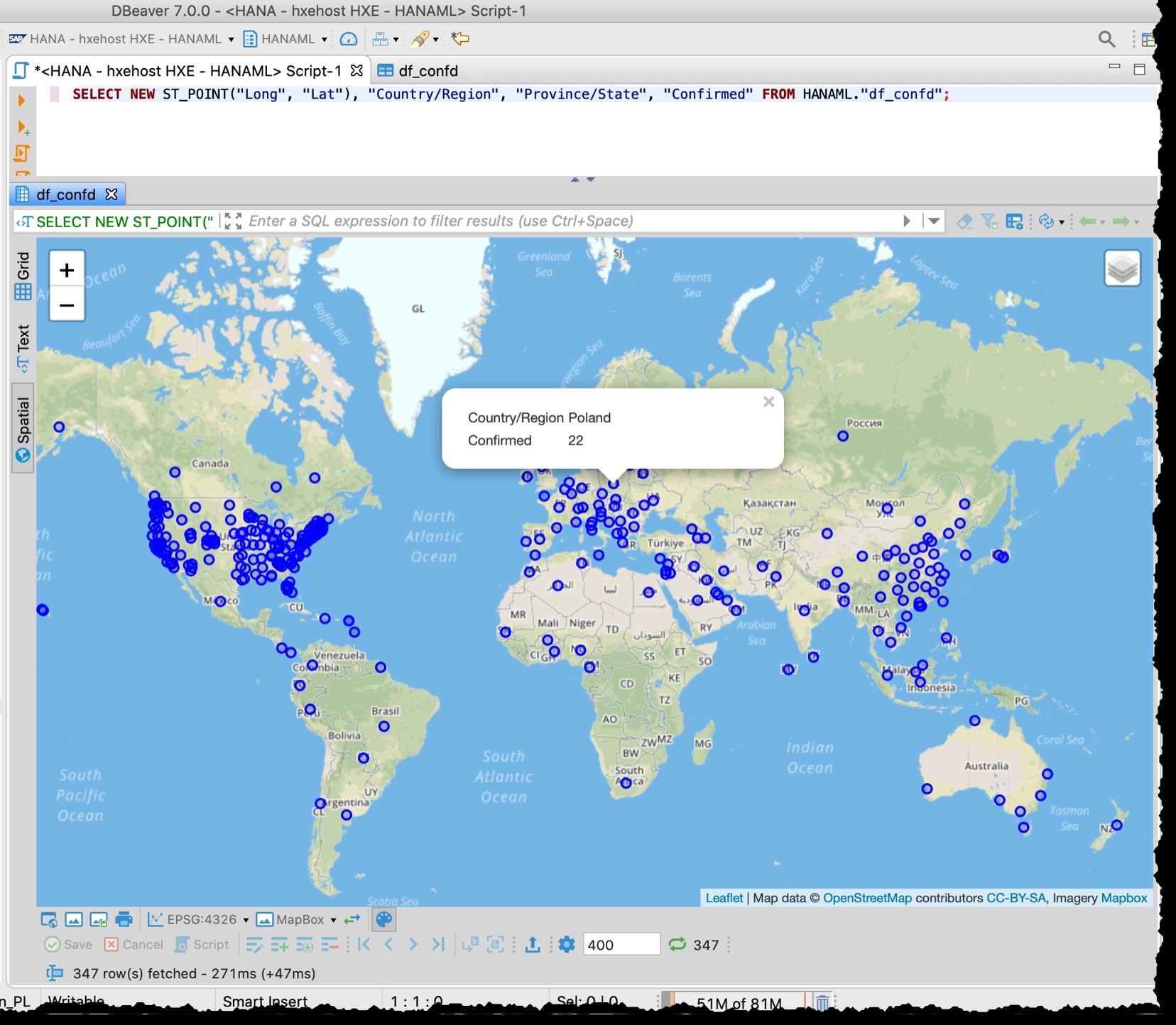
DBeaver spatial preview er ikke et komplet geospatialt visuelt udforskningsværktøj. Alligevel er det godt nok til at se berørte lande/regioner (afhængigt af granulariteten i kildefilerne).
Hvis du er interesseret i at lære mere om hana_ml …
… så vil jeg klart anbefale at tjekke Hands-On Tutorial:Machine Learning push-down til SAP HANA med Python af Andreas Forster.
HANA ML er en del af det nye "Advanced Analytics with SAP HANA"-emne for CodeJam-begivenheder. På grund af coronavirus-situationen måtte vi desværre aflyse den første arrangeret af Jakob Flaman i Bern i denne måned. En anden er arrangeret af Ewelina Pękała den 27. maj i Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Forhåbentlig bliver situationen normal på det tidspunkt, og vi behøver heller ikke at annullere denne.