Du bruger MongoDB til at gemme ID'et. Det er en stat. Generering af ID er en funktion. Du bruger Mongodb til at generere ID'et, når mongodb-processen tager argumenter for funktionen og returnerer det genererede ID. Det er ikke det, du laver. Du bruger nodejs til at generere ID'et.
Antallet af tråde, eller rettere hændelsesløkker er kritisk, da det definerer arkitekturen, men på begge måder behøver du ikke transaktioner. Transaktioner i mongodb bliver kaldt "multi-dokument transaktioner" præcis for at fremhæve, at de er beregnet til konsekvent opdatering af flere dokumenter på én gang. Det allerførste afsnit af https://docs.mongodb.com/manual/core/transactions / advarer dig om, at hvis du opdaterer et enkelt dokument, er der ikke plads til transaktioner.
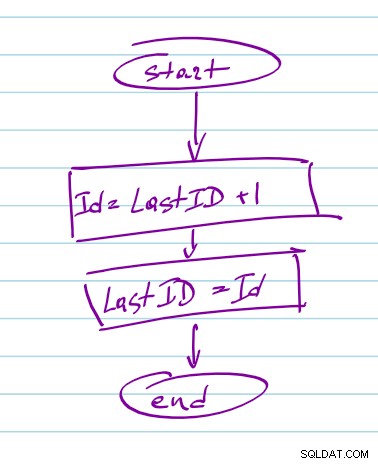
En enkelt trådet applikation kræver ikke nogen synkronisering. Du kan pålideligt læse det senest genererede ID ved start og garantere, at ID'et er unikt i nodejs-processen. Hvis du udelukker mongodb og andre I/O fra generationsfunktionen, vil du gøre den synkron, så du kan opretholde ID'ets tilstand i nodejs-processen og garantere dens unikke karakter. Når den først er genereret, kan du blive ved i db'en asynkront. I værste fald kan du have et hul i de sekventielle numre, men ingen dubletter.
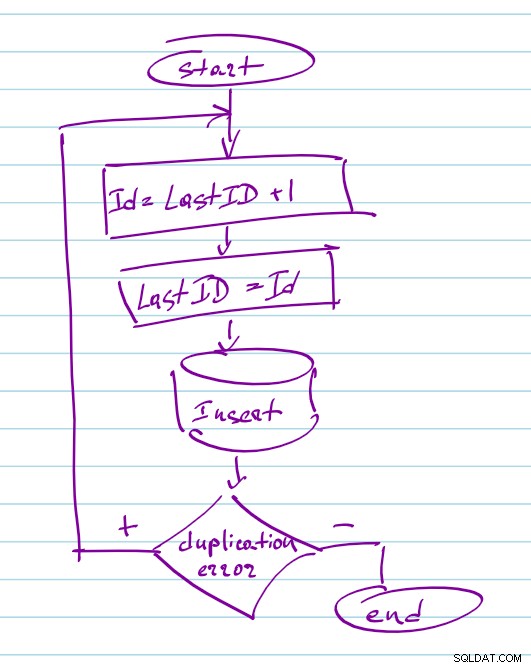
Hvis der er en mindste chance for, at du muligvis skal skalere op til mere end 1 nodejs-proces for at håndtere flere samtidige anmodninger eller tilføje en anden vært for redundans i fremtiden, bliver du nødt til at synkronisere generering af ID'et, og du kan anvende Mongodb unikke indekser til at. Funktionen i sig selv ændrer ikke meget, du genererer stadig ID'et som i en enkelt-trådet arkitektur, men tilføjer et ekstra trin for at gemme ID'et til mongo. Dokumentet skal have et unikt indeks på ID-feltet, så i tilfælde af samtidige opdateringer vil en af forespørgslerne med succes tilføje dokumentet, og en anden vil mislykkes med "E11000 duplicate key error". Du fanger sådanne fejl på nodejs side og gentager funktionen igen og vælger det næste tal: