Da du bruger foråret. Du kan bruge MultipartFile for at hente filen i din controller og derefter bruge Binary af org.bson at gemme fil til MongoDB , Hvis din billedstørrelse <16 MB (hvis billedstørrelse> 16 MB kan du bruge GridFs
).
Du skal kun tilføje én afhængighed til dit projekt - spring-data-mongoDB
Lad os tage et eksempel på en brugersamling, der ser sådan ud:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Her kan du se Binary image som repræsenterer din billedfil.
Opret nu et lager for denne brugersamling ved hjælp af MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Opret en controller til demoformål. Brug @RequestParam MultipartFile file for at hente filen til din controller, hent bytes fra filen og sæt den til brugerobjekt user.setImage(new Binary(file.getBytes())); komplet eksempel er nedenfor:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Start serveren og tryk på slutpunktet som vist i nedenstående postmand-skærmbillede
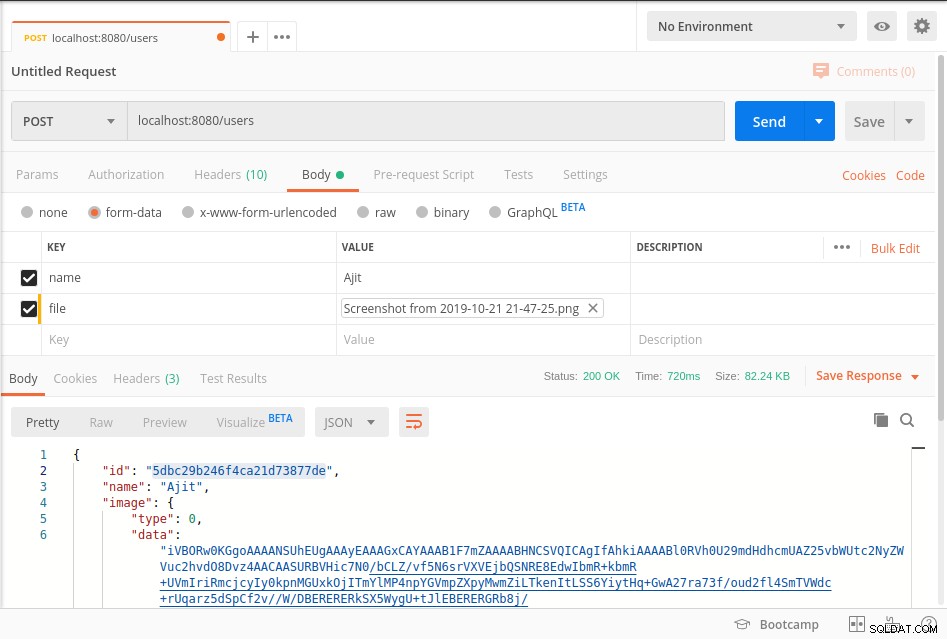
Dine data gemmes i mongoDb i BinData format og for at få data fra databasen henvises til getImage metode til ovenstående kode.
EDIT:
Spørgsmålsstilleren bruger tess4j bibliotek til at udtrække tekst fra billede og doOCR er en metode i dette bibliotek. Jeg har fulgt disse trin for at udtrække tekst fra billedet i mit spring boot-program.
-
Installer
tesseract-ocrind i dit system:sudo apt-get install tesseract-ocr -
Download
eng.traineddatatræningsdata fra https://github.com/tesseract-ocr/tessdata og flyt den til projektets rodmappe. -
Tilføj nedenstående afhængighed til dit projekt:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Tilføj nedenstående kode til eksisterende projekt:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}