MongoDB accepterer og giver adgang til data i Javascript Object Notation-formatet (JSON), hvilket gør det perfekt, når de håndterer JavaScript-baserede REST-tjenester (Representational State Transfer). I dette indlæg tager vi et kig på sideinddeling ved hjælp af MongoDB og stilladser en simpel Express/Mongojs-applikation ved hjælp af slush-mongo. Derefter bruger vi skip() og limit() for at hente de nødvendige poster fra et sæt data.
Paginering er en af de enkleste måder at øge brugervenlighed på, når man har at gøre med gennemsnitlige til store datasæt.
- Opdel alle data i x poster pr. side for at få (samlede poster/x) sider.
- Dernæst viser vi en paginering med antallet af sider.
- Når brugeren klikker på sidenummeret, søger og henter vi kun sættet af poster for den pågældende visning.
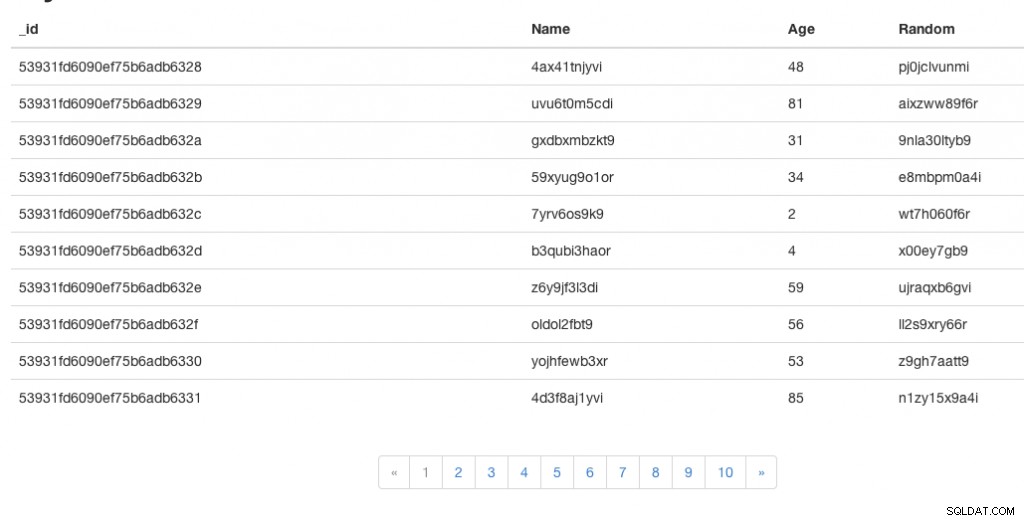
Du kan finde en live demo af appen her og den komplette kode for denne app her.
Opsæt pagineringsprojektet
Opret en ny mappe med navnet mongoDBPagination. Åbn terminal/prompt her. Dernæst installerer vi gulp , slush og slush-mongo moduler. Kør:
$ [sudo] npm i -g gulp slush slush-mongo
Når dette er gjort, skal du køre:
$ slush mongo
Du vil blive stillet et par spørgsmål, og du kan besvare det som følger:
[?] Which MongoDB project would you like to generate? Mongojs/Express [?] What is the name of your app? mongoDBPagination [?] Database Name: myDb [?] Database Host: localhost [?] Database User: [?] Database Password: [?] Database Port: 27017 [?] Will you be using heroku? (Y/n) n
Dette vil stilladsere en simpel Express/Mongojs-app til os. Når installationen er færdig, kør:
$ gulp
Åbn derefter https://localhost:3000 i din yndlingsbrowser, og du bør se en tabel med en liste over ruter, der er konfigureret i applikationen. Dette bekræfter, at du har installeret alt korrekt.
Opret en testdatabase
Dernæst opretter vi en ny samling med navnet 'testData ' og udfyld derefter nogle testdata i det. Derefter viser vi disse data i en pagineret tabel. Åbn en ny terminal/prompt og kør:
$ mongo
Vælg derefter din database ved at køre:
use myDb
Kopier derefter uddraget nedenfor og indsæt det i mongo-skallen og tryk retur:
for(var i = 1; i <= 999; i++) {
db.testData.insert({
name: Math.random()
.toString(36)
.substring(7),
age: Math.floor(Math.random() * 99),
random: Math.random()
.toString(36)
.substring(7)
});
}
Dette genererer 999 prøveposter med nogle tilfældige data. En prøvepost vil se sådan ud:
{
"_id":"5392a63c90ad2574612b953b",
"name": "j3oasl40a4i",
"age": 73,
"random": "vm2pk1sv2t9"
}
Disse data vil blive pagineret i vores applikation.
Konfigurer databasen
Da vi tilføjede en ny samling, er vi nødt til at opdatere vores Mongojs DB-konfiguration for at læse fra 'testData '.
Åbn mongoDBPagination/config/db.js og opdater linje 17 fra:
var db = mongojs(uristring, ['posts']);
til:
var db = mongojs(uristring, ['posts', 'testData']);
Byg sideinddelingens slutpunkt
Nu bygger vi vores serverkode ved at oprette et REST-slutpunkt, hvor klienten vil fortælle os, hvilke data den ønsker.
Søgelogik
Logikken for paginering er ret enkel. Vores databasesamling består af poster, og vi ønsker kun at hente og vise nogle få ved et givet tilfælde. Dette er mere en UX-ting for at holde sidens indlæsningstid på et minimum. Nøgleparametrene for enhver sideinddelingskode ville være:
-
Samlede rekorder
Det samlede antal poster i DB.
-
Størrelse
Størrelse på hvert sæt poster, som klienten ønsker at vise.
-
Side
Siden, som dataene skal hentes for.
Lad os sige, at klienten vil have 10 poster fra den første side, den vil anmode om:
{
page : 1,
size : 10
}
Serveren vil fortolke dette som – klienten har brug for 10 poster, der starter fra indeks 0 (side :1).
For at hente dataene fra tredje side vil klienten anmode om:
{
page : 3,
size : 10
}
Nu vil serveren fortolke som – klienten har brug for 10 poster, der starter fra indeks 20 (side – 1 * størrelse).
Så ser vi på ovenstående mønster, kan vi konkludere, at hvis sideværdien er 1, begynder vi at hente dataene fra post 0, og hvis sideværdien er større end 1, begynder vi at hente data fra side gange størrelse ( side*størrelse).
MongoDB-understøttelse
Vi har nu en forståelse af pagineringslogikken, men hvordan formidler vi det samme til MongoDB?
MongoDB giver os 2 metoder til at opnå dette
-
spring over
Når forespørgslen er afsluttet, vil MongoDB flytte markøren til værdien spring over.
-
grænse
Når MongoDB begynder at udfylde poster, vil den kun indsamle grænsen antal poster.
Simpelt ikke? Vi bruger disse to metoder sammen med find() for at hente posterne.
Fortsæt udvikling
Lad os nu oprette en ny fil med navnet paginator.js inde i mongoDBPagination/ruter mappe, hvor vi konfigurerer vores pagineringsslutpunkt. Åbn paginator.js og tilføj nedenstående kode:
module.exports = function (app) {
var db = require('../config/db')
api = {};
api.testData = function (req, res) {
var page = parseInt(req.query.page),
size = parseInt(req.query.size),
skip = page > 0 ? ((page - 1) * size) : 0;
db.testData.find(null, null, {
skip: skip,
limit: size
}, function (err, data) {
if(err) {
res.json(500, err);
}
else {
res.json({
data: data
});
}
});
};
app.get('/api/testData', api.testData);
};
- Linje 6-7: Vi får sidenummeret og sidestørrelsen fra anmodningsparametrene.
- Linje 8: Vi konfigurerer spring værdi.
- Linje 10: Vi forespørger i DB'en ved hjælp af find-metoden og sender null som de første 2 argumenter for at opfylde metodesignaturen for find() .
I det tredje argument af find-metoden passerer vi filterkriteriet, og når resultaterne kommer tilbage, svarer vi med en JSON.
For at teste dette skal du sørge for, at din server kører og navigere til:
https://localhost:3000/api/testdata?page=1&size=2
Du bør se de første to poster i samlingen, og du kan ændre værdierne for side og størrelse for at se forskellige resultater.
Byg klienten
Vi bygger nu den klient, der skal implementere pagineringen ved hjælp af Bootstrap-tabeller til at vise dataene og bootpag-plugin til at håndtere personsøgeren.
Først vil vi installere Bootstrap. Kør:
$ bower install bootstrap
Dernæst vil vi downloade jquery.bootpag.min.js herfra til public/js folder. Opdater views/index.html som:
<!DOCTYPE html>
<html>
<head>
<title><%= siteName %></title>
<link rel="stylesheet" href="/css/style.css">
<link rel="stylesheet" href="/bower_components/bootstrap/dist/css/bootstrap.min.css">
</head>
<body>
<div class="navbar navbar-inverse navbar-fixed-top" role="navigation">
<div class="container">
<div class="navbar-header">
<a class="navbar-brand" href="javascript:"><%= siteName %></a>
</div>
</div>
</div>
<div class="container">
<h1>My Data</h1>
<table class="table">
<thead>
<tr>
<th>_id</th>
<th>Name</th>
<th>Age</th>
<th>Random</th>
</tr>
</thead>
<tbody>
<!-- we will populate this dyanmically -->
</tbody>
</table>
<div id="pager" class="text-center"></div>
<input type="hidden" value="<%= totalRecords %>" id="totalRecords">
<input type="hidden" value="<%= size %>" id="size">
</div>
<script type="text/javascript" src="bower_components/jquery/dist/jquery.min.js"></script>
<script type="text/javascript" src="/js/jquery.bootpag.min.js"></script>
<script type="text/javascript" src="/js/script.js"></script>
</body>
</html>
Og til sidst skriver vi logikken for at udfylde tabellen. Åbn js/script.js og udfyld det som:
// init bootpag
$('#pager').bootpag({
total: Math.ceil($("#totalRecords").val()/$("#size").val()),
page : 1,
maxVisible : 10,
href: "#page-{{number}}",
}).on("page", function(event, /* page number here */ num) {
populateTable(num);
});
var template = "<tr><td>_id</td><td>name</td><td>age</td><td>random</td>";
var populateTable = function (page) {
var html = '';
$.getJSON('/api/testdata?page='+page+'&size='+ $("#size").val(), function(data){
data = data.data;
for (var i = 0; i < data.length; i++) {
var d = data[i];
html += template.replace('_id', d._id)
.replace('name', d.name)
.replace('age', d.age)
.replace('random', d.random);
};
$('table tbody').html(html);
});
};
// load first page data
populateTable(1);
Naviger nu til:
https://localhost:3000
Du skulle nu se tabellen og personsøger-komponenten. Du kan klikke gennem sidetallene for at gennemse dataene.
Simpelt og nemt! Håber du har en idé om, hvordan man implementerer paginering ved hjælp af MongoDB.
Du kan finde koden til denne app her.
Se vores andet blogindlæg - Hurtig personsøgning med MongoDB
for flere detaljer om ydeevnen på personsøgningsoperationen
Tak fordi du læste med. Kommenter.
@arvindr21