MongoDB er en NoSQL-database, der understøtter en lang række inputdatasætkilder. Det er i stand til at gemme data i fleksible JSON-lignende dokumenter, hvilket betyder, at felter eller metadata kan variere fra dokument til dokument, og datastrukturen kan ændres over tid. Dokumentmodellen gør dataene nemme at arbejde med ved at tilknytte objekterne i applikationskoden. MongoDB er også kendt som en distribueret database i sin kerne, så høj tilgængelighed, horisontal skalering og geografisk distribution er indbygget og nem at bruge. Den kommer med evnen til problemfrit at ændre parametre til modeltræning. Data Scientists kan nemt fusionere struktureringen af data med denne modelgenerering.
Hvad er Machine Learning?
Machine Learning er videnskaben om at få computere til at lære og agere som mennesker gør og forbedre deres læring over tid på en selvstændig måde. Læringsprocessen begynder med observationer eller data, såsom eksempler, direkte erfaring eller instruktion, for at lede efter mønstre i data og træffe bedre beslutninger i fremtiden baseret på de eksempler, vi giver. Det primære mål er at lade computerne lære automatisk uden menneskelig indgriben eller hjælp og justere handlinger i overensstemmelse hermed.
En rig programmerings- og forespørgselsmodel
MongoDB tilbyder både native drivere og certificerede connectors til udviklere og dataforskere, der bygger maskinlæringsmodeller med data fra MongoDB. PyMongo er et fantastisk bibliotek til at indlejre MongoDB-syntaks i Python-kode. Vi kan importere alle funktioner og metoder i MongoDB for at bruge dem i vores maskinlæringskode. Det er en fantastisk teknik til at få flersproget funktionalitet i en enkelt kode. Den yderligere fordel er, at du kan bruge de væsentlige funktioner i disse programmeringssprog til at skabe en effektiv applikation.
MongoDB-forespørgselssproget med rige sekundære indekser gør det muligt for udviklere at bygge applikationer, der kan forespørge og analysere data i flere dimensioner. Data kan tilgås med enkelte nøgler, områder, tekstsøgning, grafer og geospatiale forespørgsler gennem komplekse sammenlægninger og MapReduce-job, der returnerer svar på millisekunder.
For at parallelisere databehandling på tværs af en distribueret databaseklynge, leverer MongoDB aggregeringspipelinen og MapReduce. MongoDB-aggregeringspipelinen er modelleret efter konceptet med databehandlingspipelines. Dokumenter kommer ind i en flertrins pipeline, der transformerer dokumenterne til et aggregeret resultat ved hjælp af native operationer, der udføres i MongoDB. De mest grundlæggende pipeline-stadier giver filtre, der fungerer som forespørgsler og dokumenttransformationer, der ændrer outputdokumentets form. Andre pipeline-operationer giver værktøjer til at gruppere og sortere dokumenter efter specifikke felter samt værktøjer til at aggregere indholdet af arrays, herunder arrays af dokumenter. Derudover kan pipseline-stadier bruge operatører til opgaver som at beregne gennemsnittet eller standardafvigelser på tværs af samlinger af dokumenter og manipulere strenge. MongoDB leverer også indbyggede MapReduce-operationer i databasen ved at bruge tilpassede JavaScript-funktioner til at udføre kortet og reducere stadier.
Ud over dens oprindelige forespørgselsramme tilbyder MongoDB også en højtydende forbindelse til Apache Spark. Konnektoren afslører alle Sparks biblioteker, inklusive Python, R, Scala og Java. MongoDB-data materialiseres som DataFrames og Datasæt til analyse med maskinlæring, grafer, streaming og SQL API'er.
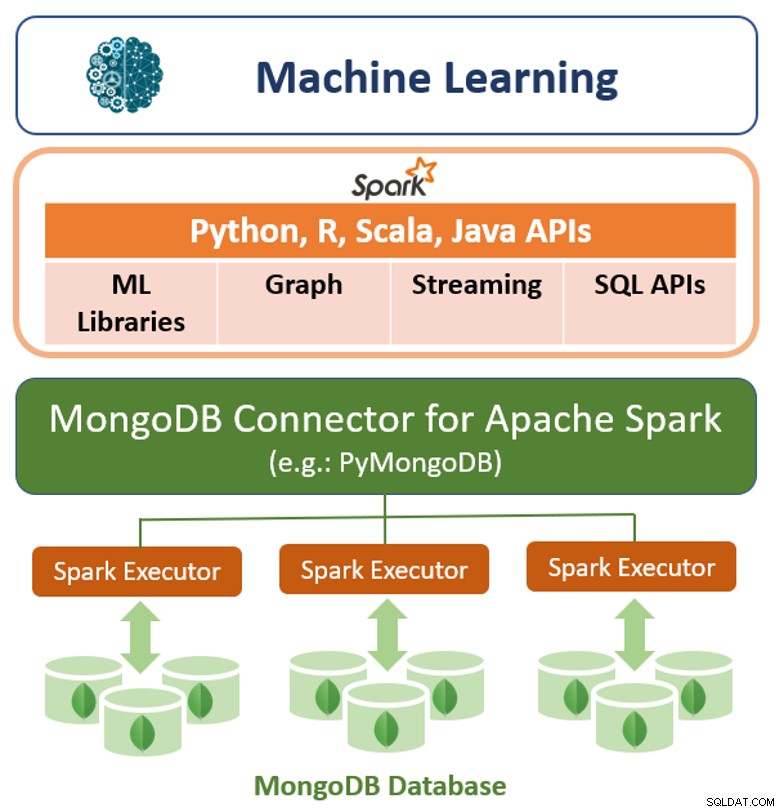
MongoDB Connector til Apache Spark kan drage fordel af MongoDBs aggregeringspipeline og sekundære indekser til kun at udtrække, filtrere og behandle den række af data, det har brug for - for eksempel at analysere alle kunder, der befinder sig i en bestemt geografi. Dette er meget forskelligt fra simple NoSQL-datalagre, der ikke understøtter hverken sekundære indekser eller aggregeringer i databasen. I disse tilfælde skal Spark udtrække alle data baseret på en simpel primærnøgle, selvom kun en delmængde af disse data er påkrævet til Spark-processen. Dette betyder mere behandlingsomkostninger, mere hardware og længere tid til indsigt for datavidenskabsfolk og ingeniører. For at maksimere ydeevnen på tværs af store, distribuerede datasæt kan MongoDB Connector til Apache Spark samlokalisere Resilient Distributed Datasets (RDD'er) med MongoDB-kildenoden og derved minimere databevægelser på tværs af klyngen og reducere latens.
Ydeevne, skalerbarhed og redundans
Modeltræningstiden kan reduceres ved at bygge maskinlæringsplatformen oven på et effektivt og skalerbart databaselag. MongoDB tilbyder en række innovationer for at maksimere gennemløbet og minimere latens for maskinlæringsarbejdsbelastninger:
- WiredTiger er kendt som standardlagringsmotoren til MongoDB, udviklet af arkitekterne bag Berkeley DB, den mest udbredte indlejrede datastyringssoftware i verden. WiredTiger skalerer på moderne multi-core arkitekturer. Ved at bruge en række programmeringsteknikker, såsom hazard pointers, låsefri algoritmer, hurtig låsning og meddelelsesoverførsel, maksimerer WiredTiger beregningsarbejde pr. CPU-kerne og clock-cyklus. For at minimere on-disk overhead og I/O bruger WiredTiger kompakte filformater og lagerkomprimering.
- For de mest latensfølsomme maskinlæringsapplikationer kan MongoDB konfigureres med In-Memory-lagringsmotoren. Baseret på WiredTiger giver denne lagringsmaskine brugerne fordelene ved in-memory computing uden at bytte den rige forespørgselsfleksibilitet, realtidsanalyse og skalerbar kapacitet fra konventionelle diskbaserede databaser væk.
- For at parallelisere modeltræning og skalere inputdatasæt ud over en enkelt node, bruger MongoDB en teknik kaldet sharding, som distribuerer behandling og data på tværs af klynger af råvarehardware. MongoDB-sharding er fuldt elastisk og rebalancerer automatisk data på tværs af klyngen, efterhånden som inputdatasættet vokser, eller når noder tilføjes og fjernes.
- Inden for en MongoDB-klynge distribueres data fra hvert shard automatisk til flere replikaer, der hostes på separate noder. MongoDB replikasæt giver redundans til at gendanne træningsdata i tilfælde af en fejl, hvilket reducerer overhead af checkpointing.
MongoDB's Tunable Consistency
MongoDB er som standard stærkt konsistent, hvilket gør det muligt for maskinlæringsapplikationer straks at læse, hvad der er blevet skrevet til databasen, og dermed undgå udviklerkompleksiteten, der pålægges af til sidst konsistente systemer. Stærk konsistens vil give de mest nøjagtige resultater for maskinlæringsalgoritmer; i nogle scenarier er det dog acceptabelt at handle konsistens mod specifikke præstationsmål ved at distribuere forespørgsler på tværs af en klynge af MongoDB sekundære replikasætmedlemmer.
Fleksibel datamodel i MongoDB
MongoDBs dokumentdatamodel gør det nemt for udviklere og dataforskere at gemme og aggregere data af enhver form for struktur inde i databasen uden at give afkald på sofistikerede valideringsregler til at styre datakvaliteten. Skemaet kan ændres dynamisk uden en nedetid for en applikation eller database, der skyldes kostbare skemaændringer eller redesign, som relationelle databasesystemer har pådraget sig.
At gemme modeller i en database og indlæse dem ved hjælp af python er også en nem og meget påkrævet metode. At vælge MongoDB er også en fordel, da det er en open source dokumentdatabase og også en førende NoSQL-database. MongoDB fungerer også som en forbindelse til apache spark-distribueret framework.
MongoDBs dynamiske natur
MongoDBs dynamiske natur gør det muligt at bruge det i databasemanipulationsopgaver ved udvikling af Machine Learning-applikationer. Det er en meget effektiv og nem måde at udføre en analyse af datasæt og databaser på. Resultatet af analysen kan bruges til træning af maskinlæringsmodeller. Det er blevet anbefalet, at dataanalytikere og Machine Learning-programmører får mestring i MongoDB og anvender det i mange forskellige applikationer. MongoDB's Aggregation-ramme bruges til datavidenskabelige arbejdsgange til at udføre dataanalyse for adskillige applikationer.
Konklusion
MongoDB tilbyder flere forskellige muligheder såsom:fleksibel datamodel, rig programmering, datamodel, forespørgselsmodel og dens tunbare konsistens, der gør træning og brug af maskinlæringsalgoritmer meget nemmere end med traditionelle relationelle databaser. At køre MongoDB som backend-databasen vil muliggøre lagring og berigelse af maskinlæringsdata giver mulighed for vedholdenhed og øget effektivitet.