ClusterControl er programmeret med en række gendannelsesalgoritmer til automatisk at reagere på forskellige typer almindelige fejl, der påvirker dine databasesystemer. Den forstår forskellige typer databasetopologier og databaserelateret processtyring for at hjælpe dig med at bestemme den bedste måde at gendanne klyngen på. På en måde forbedrer ClusterControl din databases tilgængelighed.
Nogle topologimanagere dækker kun klyngendannelse som MHA, Orchestrator og mysqlfailover, men du skal selv håndtere nodegendannelsen. ClusterControl understøtter gendannelse på både klynge- og nodeniveau.
Konfigurationsindstillinger
Der er to gendannelseskomponenter, der understøttes af ClusterControl, nemlig:
- Klynge - Forsøg på at genoprette en klynge til en driftstilstand
- Node - Forsøg på at genoprette en node til en driftstilstand
Disse to komponenter er de vigtigste ting for at sikre, at servicetilgængeligheden er så høj som muligt. Hvis du allerede har en topologimanager oven på ClusterControl, kan du deaktivere automatisk gendannelsesfunktion og lade en anden topologimanager håndtere det for dig. Du har alle muligheder med ClusterControl.
Den automatiske gendannelsesfunktion kan aktiveres og deaktiveres med en simpel ON/OFF-knap, og den virker til klynge- eller nodegendannelse. De grønne ikoner betyder aktiveret og røde ikoner betyder deaktiveret. Følgende skærmbillede viser, hvor du kan finde det i databaseklyngelisten:
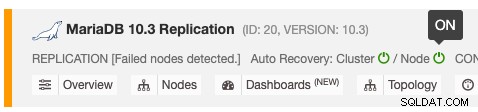
Der er 3 ClusterControl-parametre, der kan bruges til at kontrollere gendannelsesadfærden. Alle parametre er som standard sand (indstillet med boolesk heltal 0 eller 1):
- enable_autorecovery - Aktiver klynge- og nodegendannelse. Denne parameter er supersættet af enable_cluster_recovery og enable_node_recovery. Hvis den er indstillet til 0, vil delsættets parametre blive slået fra.
- enable_cluster_recovery - ClusterControl udfører klyngendannelse, hvis den er aktiveret.
- enable_node_recovery - ClusterControl udfører nodegendannelse, hvis den er aktiveret.
Klyngendannelse dækker gendannelsesforsøg på at hente hele klyngetopologien frem. For eksempel skal en master-slave-replikation have mindst én master i live på et givet tidspunkt, uanset antallet af tilgængelige slave(r). ClusterControl forsøger at korrigere topologien mindst én gang for replikeringsklynger, men uendeligt for multi-master replikering som NDB Cluster og Galera Cluster.
Nodegendannelse dækker problemer med nodegendannelse, som hvis en node blev stoppet uden ClusterControl-viden, f.eks. via systemstopkommando fra SSH-konsollen eller ved at blive dræbt af OOM-processen.
Nodegendannelse
ClusterControl er i stand til at gendanne en databasenode i tilfælde af periodisk fejl ved at overvåge processen og forbindelsen til databasenoderne. For processen fungerer den på samme måde som systemd, hvor den vil sørge for, at MySQL-tjenesten er startet og kører, medmindre du med vilje stoppede den via ClusterControl UI.
Hvis noden kommer online igen, etablerer ClusterControl en forbindelse tilbage til databasenoden og udfører de nødvendige handlinger. Det følgende er, hvad ClusterControl ville gøre for at gendanne en node:
- Den vil vente på, at systemd/chkconfig/init starter de overvågede tjenester/processer i 30 sekunder
- Hvis de overvågede tjenester/processer stadig er nede, vil ClusterControl forsøge at starte databasetjenesten automatisk.
- Hvis ClusterControl ikke er i stand til at gendanne de overvågede tjenester/processer, udløses en alarm.
Bemærk, at hvis en databasenedlukning initieres af brugeren, vil ClusterControl ikke forsøge at gendanne den bestemte node. Det forventer, at brugeren starter det igen via ClusterControl UI ved at gå til Node -> Node Actions -> Start Node eller bruge OS-kommandoen eksplicit.
Gendannelsen inkluderer alle databaserelaterede tjenester som ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus-eksportører og garbd. Særlig opmærksomhed til Prometheus-eksportører, hvor ClusterControl bruger et program kaldet "daemon" til at dæmonisere eksportørprocessen. ClusterControl vil forsøge at oprette forbindelse til eksportørens lytteport for sundhedstjek og verifikation. Det anbefales derfor at åbne eksportportene fra ClusterControl og Prometheus-serveren for at sikre, at der ikke er falsk alarm under gendannelse.
Klyngendannelse
ClusterControl forstår databasetopologien og følger bedste praksis for at udføre gendannelsen. For en databaseklynge, der kommer med indbygget fejltolerance som Galera Cluster, NDB Cluster og MongoDB Replicaset, udføres failover-processen automatisk af databaseserveren via kvorumberegning, hjerteslag og rolleskift (hvis nogen). ClusterControl overvåger processen og foretager nødvendige justeringer af visualiseringen, f.eks. at afspejle ændringerne under topologivisning og justere overvågnings- og administrationskomponenten for den nye rolle, f.eks. ny primær node i et replikasæt.
For databaseteknologier, der ikke har indbygget fejltolerance med automatisk gendannelse som MySQL/MariaDB-replikering og PostgreSQL/TimescaleDB Streaming-replikering, udfører ClusterControl gendannelsesprocedurerne ved at følge de bedste fremgangsmåder, som leveres af database leverandør. Hvis gendannelsen mislykkes, er brugerindgriben påkrævet, og du vil selvfølgelig få en alarmmeddelelse herom.
I en blandet/hybrid topologi, for eksempel en asynkron slave, der er knyttet til en Galera Cluster eller NDB Cluster, vil noden blive gendannet af ClusterControl, hvis klyngendannelse er aktiveret.
Klyngendannelse gælder ikke for selvstændige MySQL-servere. Det anbefales dog at aktivere både node- og klyngendannelser for denne klyngetype i ClusterControl-brugergrænsefladen.
MySQL/MariaDB-replikering
ClusterControl understøtter gendannelse af følgende MySQL/MariaDB-replikeringsopsætning:
- Master-slave med MySQL GTID
- Master-slave med MariaDB GTID
- Master-slave med uden GTID (både MySQL og MariaDB)
- Master-master med MySQL GTID
- Master-master med MariaDB GTID
- Asynkron slave knyttet til en Galera-klynge
ClusterControl respekterer følgende parametre, når der udføres klyngendannelse:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replikeringsstop_ved_fejl
For flere detaljer om hver af parametrene, se dokumentationssiden.
ClusterControl vil adlyde følgende regler ved overvågning og styring af en master-slave-replikering:
- Alle noder vil blive startet med read_only=ON og super_read_only=ON (uanset deres rolle).
- Kun én master (read_only=OFF) har tilladelse til at fungere på et givet tidspunkt.
- Stol på MySQL-variablen report_host til at kortlægge topologien.
- Hvis der er to eller flere noder, der har read_only=OFF ad gangen, vil ClusterControl automatisk sætte read_only=ON på begge mastere for at beskytte dem mod utilsigtet skrivning. Brugerindgreb er påkrævet for at vælge den faktiske master ved at deaktivere skrivebeskyttet. Gå til Noder -> Nodehandlinger -> Deaktiver skrivebeskyttet.
Hvis den aktive master går ned, vil ClusterControl forsøge at udføre master-failoveren i følgende rækkefølge:
- Efter 3 sekunders manglende tilgængelighed vil ClusterControl slå en alarm.
- Tjek slavetilgængeligheden, mindst én af slaverne skal kunne nås af ClusterControl.
- Vælg slaven som kandidat til at blive mester.
- ClusterControl vil beregne sandsynligheden for fejlagtige transaktioner, hvis GTID er aktiveret.
- Hvis der ikke opdages en fejltransaktion, vil den valgte blive forfremmet som den nye master.
- Opret og tildel replikeringsbruger, der skal bruges af slaver.
- Skift mester for alle slaver, der pegede på den gamle mester til den nyligt forfremmede mester.
- Start slave og aktiver skrivebeskyttet.
- Skyl logfiler på alle noder.
- Hvis slavepromoveringen mislykkes, vil ClusterControl afbryde gendannelsesjobbet. Brugerindgreb eller en genstart af cmon-tjenesten er påkrævet for at udløse gendannelsesjobbet igen.
- Når gammel master er tilgængelig igen, startes den som skrivebeskyttet og vil ikke være en del af replikeringen. Brugerindgriben er påkrævet.
Samtidig vil følgende alarmer blive udløst:
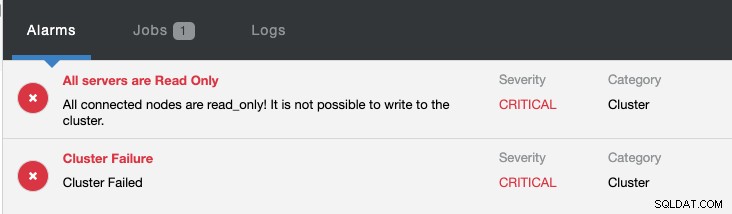
Se Introduktion til Failover for MySQL-replikering - 101-bloggen og Automatisk Failover af MySQL-replikering - Nyt i ClusterControl 1.4 for at få yderligere oplysninger om, hvordan du konfigurerer og administrerer MySQL-replikeringsfailover med ClusterControl.
PostgreSQL/TimescaleDB Streaming Replikering
ClusterControl understøtter gendannelse af følgende PostgreSQL-replikeringsopsætning:
- PostgreSQL-streamingreplikering
- TimescaleDB Streaming Replication
ClusterControl respekterer følgende parametre, når der udføres klyngendannelse:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
For flere detaljer om hver af parametrene, se dokumentationssiden.
ClusterControl vil adlyde følgende regler for styring og overvågning af en PostgreSQL-streaming-replikeringsopsætning:
- wal_level er indstillet til "replika" (eller "hot_standby" afhængigt af PostgreSQL-versionen).
- Variable archive_mode er sat til TIL på masteren.
- Indstil filen recovery.conf på slaveknuderne, som gør noden til en varm standby med skrivebeskyttet aktiveret.
Hvis den aktive master går ned, vil ClusterControl forsøge at udføre klyngendannelsen i følgende rækkefølge:
- Efter 10 sekunders utilgængelighed som master, vil ClusterControl udløse en alarm.
- Efter 10 sekunders yndefuld ventetimeout vil ClusterControl starte master failover-jobbet.
- Sample replayLocation og receiveLocation på alle tilgængelige noder for at bestemme den mest avancerede node.
- Promover den mest avancerede node som den nye master.
- Stop slaver.
- Bekræft synkroniseringstilstanden med pg_rewind.
- Genstarter slaver med den nye master.
- Hvis slavepromoveringen mislykkes, vil ClusterControl afbryde gendannelsesjobbet. Brugerindgreb eller en genstart af cmon-tjenesten er påkrævet for at udløse gendannelsesjobbet igen.
- Når gammel master er tilgængelig igen, vil den blive tvunget til at lukke ned og vil ikke være en del af replikeringen. Brugerindgriben er påkrævet. Se længere nede.
Når den gamle master kommer online igen, hvis PostgreSQL-tjenesten kører, vil ClusterControl tvinge nedlukning af PostgreSQL-tjenesten. Dette er for at beskytte serveren mod utilsigtet skrivning, da den ville blive startet uden en gendannelsesfil (recovery.conf), hvilket betyder, at den ville være skrivbar. Du skal forvente, at følgende linjer vises i postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL blev startet, efter at serveren igen var online omkring kl. 05:06:10, men ClusterControl udfører en hurtig nedlukning 17 sekunder derefter omkring kl. 05:06:27. Hvis dette er noget, du ikke ønsker, at det skal være, kan du deaktivere nodegendannelse for denne klynge et øjeblik.
Tjek Automatisk Failover af Postgres-replikering og Failover for PostgreSQL-replikering 101 for at få yderligere oplysninger om, hvordan du konfigurerer og administrerer PostgreSQL-replikeringsfailover med ClusterControl.
Konklusion
ClusterControl automatisk gendannelse forstår databaseklyngetopologi og er i stand til at gendanne en ned- eller degraderet klynge til en fuldt operationel klynge, hvilket vil forbedre databasetjenestens oppetid enormt. Prøv ClusterControl nu og opnå dine nire i SLA og databasetilgængelighed. Kender du ikke dine niere? Tjek denne seje nines lommeregner.