I de to foregående blogindlæg dækkede vi både implementering af de fire typer klynge/replikering (MySQL/Galera, MySQL-replikering, MongoDB &PostgreSQL) og styring/overvågning af dine eksisterende databaser og klynger. Så efter at have læst disse to første blogindlæg var du i stand til at tilføje dine 20 eksisterende replikeringsopsætninger til ClusterControl, udvide dem og desuden implementere to nye Galera-klynger, mens du gjorde en masse andre ting. Eller måske har du implementeret MongoDB- og/eller PostgreSQL-systemer. Så nu, hvordan holder du dem sunde?
Det er præcis, hvad dette blogindlæg handler om:hvordan man udnytter ClusterControl-ydelsesovervågning og rådgiverfunktionalitet til at holde dine MySQL-, MongoDB- og/eller PostgreSQL-databaser og -klynger sunde. Så hvordan gøres dette i ClusterControl?
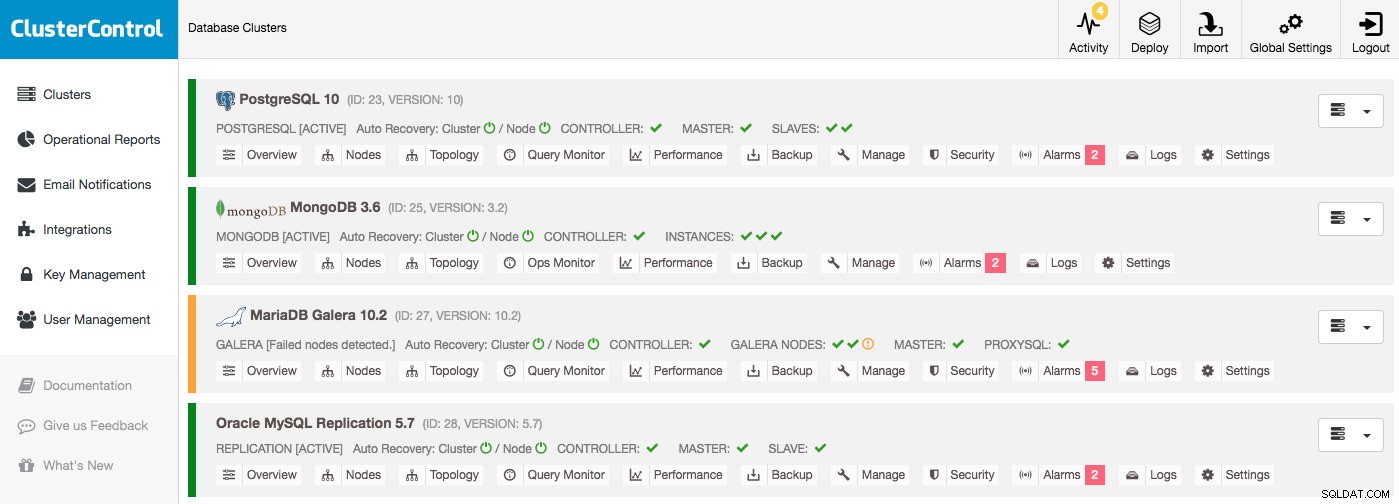
Databaseklyngeliste
Den vigtigste information kan allerede findes i klyngelisten:Så længe der ikke er nogen alarmer, og ingen værter er vist nede, fungerer alt fint. Der slås alarm, hvis en bestemt betingelse er opfyldt, f.eks. værten bytter, og gør dig opmærksom på det problem, du bør undersøge. Det betyder, at alarmer ikke kun udløses under et udfald, men også for at give dig mulighed for proaktivt at administrere dine databaser.
Antag, at du ville logge ind på ClusterControl og se en klyngeliste som denne, vil du helt sikkert have noget at undersøge:en knude er for eksempel nede i Galera-klyngen, og hver klynge har forskellige alarmer:
Når du klikker på en af alarmerne, kommer du til en detaljeret side om alle alarmer i klyngen. Alarmdetaljerne vil forklare problemet og i de fleste tilfælde også rådgive om handlingen for at løse problemet.
Du kan opsætte dine egne alarmer ved at oprette brugerdefinerede udtryk, men det er blevet forældet til fordel for vores nye Developer Studio, der giver dig mulighed for at skrive tilpassede Javascripts og udføre disse som rådgivere. Vi vender tilbage til dette emne senere i dette indlæg.
Klyngeoversigt - Dashboards
Når vi åbner klyngeoversigten, kan vi med det samme se de vigtigste performance-metrics for klyngen i fanerne. Denne oversigt kan variere fra klyngetype, da Galera f.eks. har andre præstationsmålinger at se end traditionelle MySQL, PostgreSQL eller MongoDB.
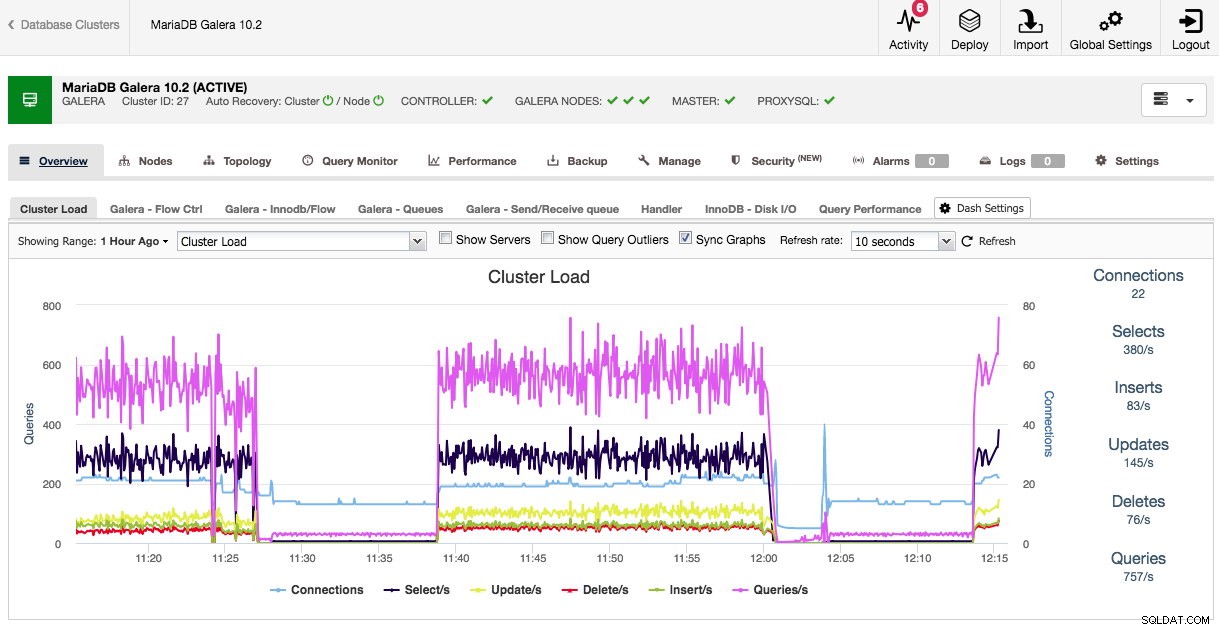
Både standardoversigten og de forudvalgte faner kan tilpasses. Ved at klikke på Oversigt -> Dash-indstillinger du får en dialog, der giver dig mulighed for at definere dashboardet:
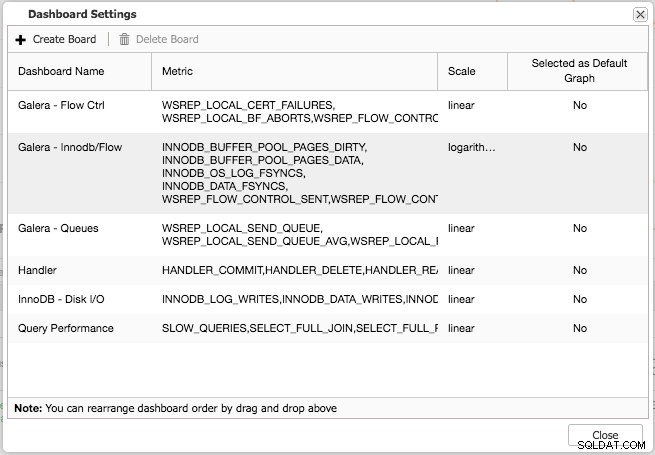
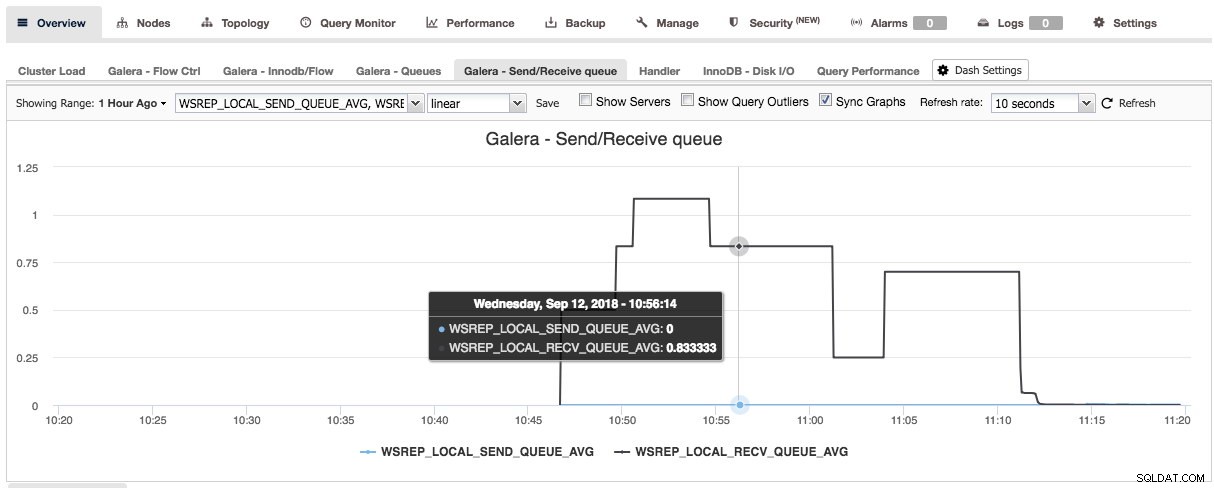
Ved at trykke på plustegnet kan du tilføje og definere dine egne metrics for at tegne dashboardet. I vores tilfælde vil vi definere et nyt dashboard med Galera-specifikke sende- og modtagekøgennemsnit:
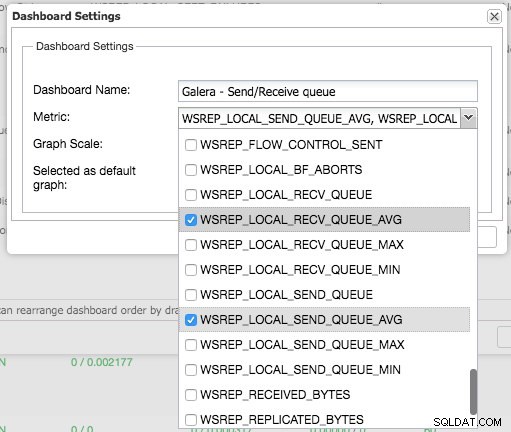
Dette nye dashboard skulle give os et godt indblik i den gennemsnitlige kølængde for vores Galera-klynge.
Når du har trykket på Gem, bliver det nye dashboard tilgængeligt for denne klynge:
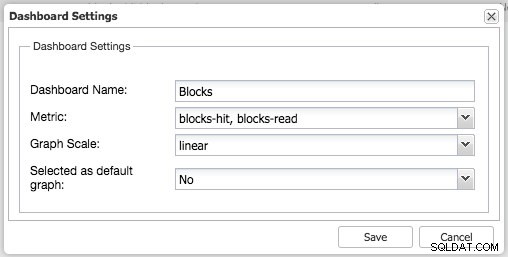
På samme måde kan du også gøre dette for PostgreSQL, for eksempel kan vi overvåge de delte blokke, der er ramt versus de læste blokke:
Så som du kan se, er det relativt nemt at tilpasse dit eget (standard) dashboard.
Klyngeoversigt - Query Monitor
Forespørgselsmonitor-fanen er tilgængelig for både MySQL- og PostgreSQL-baserede opsætninger og består af tre dashboards:Topforespørgsler, Kørende forespørgsler og Forespørgsels-outliers.
I dashboardet Running Queries finder du alle aktuelle forespørgsler, der kører. Dette svarer grundlæggende til SHOW FULL PROCESSLIST-sætningen i MySQL-databasen.
Topforespørgsler og Outliers for forespørgsler er begge afhængige af input fra den langsomme forespørgselslog eller Performance Schema. Det anbefales altid at bruge Performance Schema og vil blive brugt automatisk, hvis det er aktiveret. Ellers vil ClusterControl bruge MySQL langsomme forespørgselslog til at fange de kørende forespørgsler. For at forhindre, at ClusterControl bliver for påtrængende, og den langsomme forespørgselslog bliver for stor, prøver ClusterControl den langsomme forespørgselslog ved at slå den til og fra. Denne sløjfe er som standard indstillet til 1 sekunds optagelse og long_query_time er indstillet til 0,5 sekunder. Hvis du ønsker at ændre disse indstillinger for din klynge, kan du ændre dette via Indstillinger -> Forespørgselsovervågning .
Topforespørgsler vil, som navnet siger, vise de topforespørgsler, der blev samplet. Du kan sortere dem i forskellige kolonner:f.eks. frekvens, gennemsnitlig udførelsestid, samlet udførelsestid eller standardafvigelsestid:
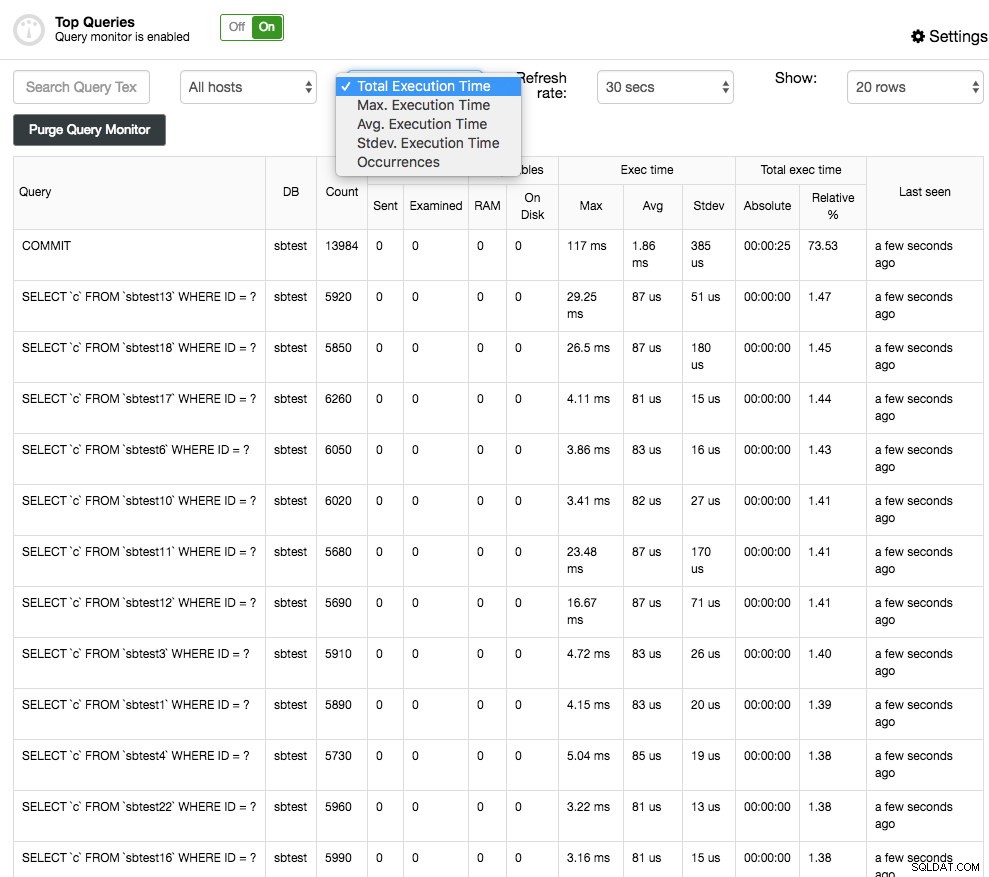
Du kan få flere detaljer om forespørgslen ved at vælge den, og dette vil præsentere forespørgselsudførelsesplanen (hvis tilgængelig) og optimeringstip/rådgivninger. Outliers for forespørgsler ligner de øverste forespørgsler, men giver dig derefter mulighed for at filtrere forespørgslerne pr. vært og sammenligne dem i tide.
Klyngeoversigt - Operationer
I lighed med PostgreSQL- og MySQL-systemerne har MongoDB-klyngerne operationsoversigten og ligner MySQL's Running Queries. Denne oversigt svarer til at udstede kommandoen db.currentOp() i MongoDB.
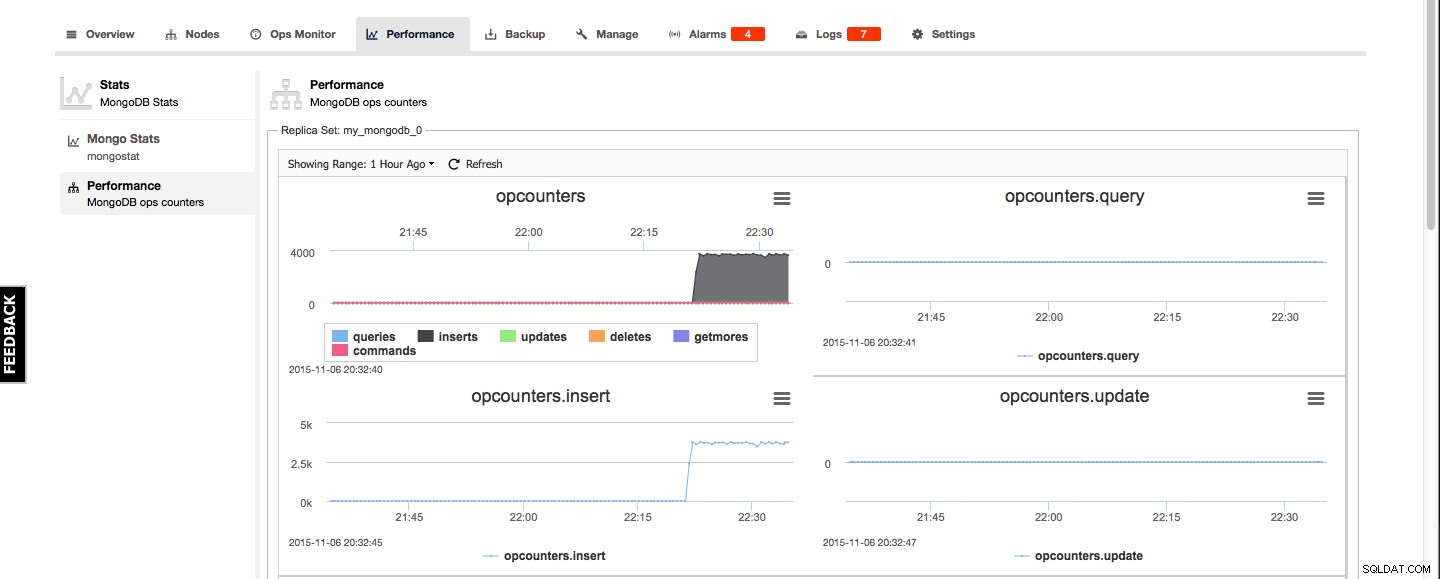
Klyngeoversigt - ydeevne
MySQL/Galera
Fanen Performance er sandsynligvis det bedste sted at finde den overordnede ydeevne og sundhed for dine klynger. For MySQL og Galera består den af en oversigtsside, rådgiverne, status-/variableoversigter, skemaanalysatoren og transaktionsloggen.
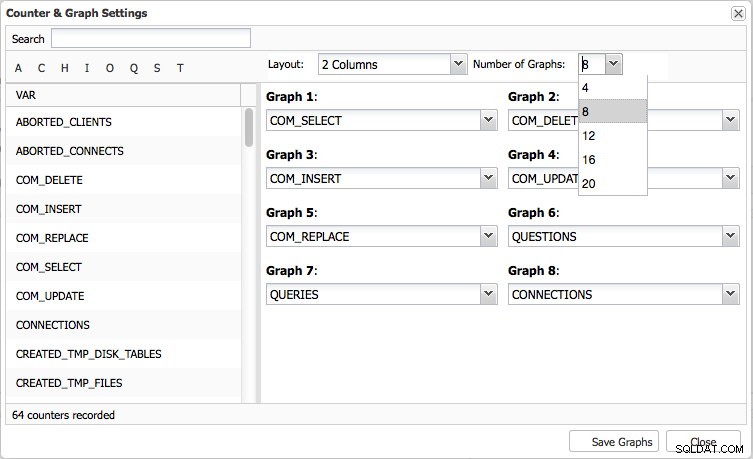
Oversigtssiden giver dig en grafoversigt over de vigtigste målinger i din klynge. Dette er naturligvis forskelligt pr. klyngetype. Otte metrics er blevet indstillet som standard, men du kan nemt indstille dine egne - op til 20 grafer, hvis det er nødvendigt:
Rådgiverne er en af nøglefunktionerne i ClusterControl:Rådgiverne er scriptede checks, der kan køres efter behov. Rådgiverne kan vurdere næsten enhver kendt kendsgerning om værten og/eller klyngen og give deres mening om værtens og/eller klyngens helbred og kan endda give råd om, hvordan du løser problemer eller forbedrer dine værter!
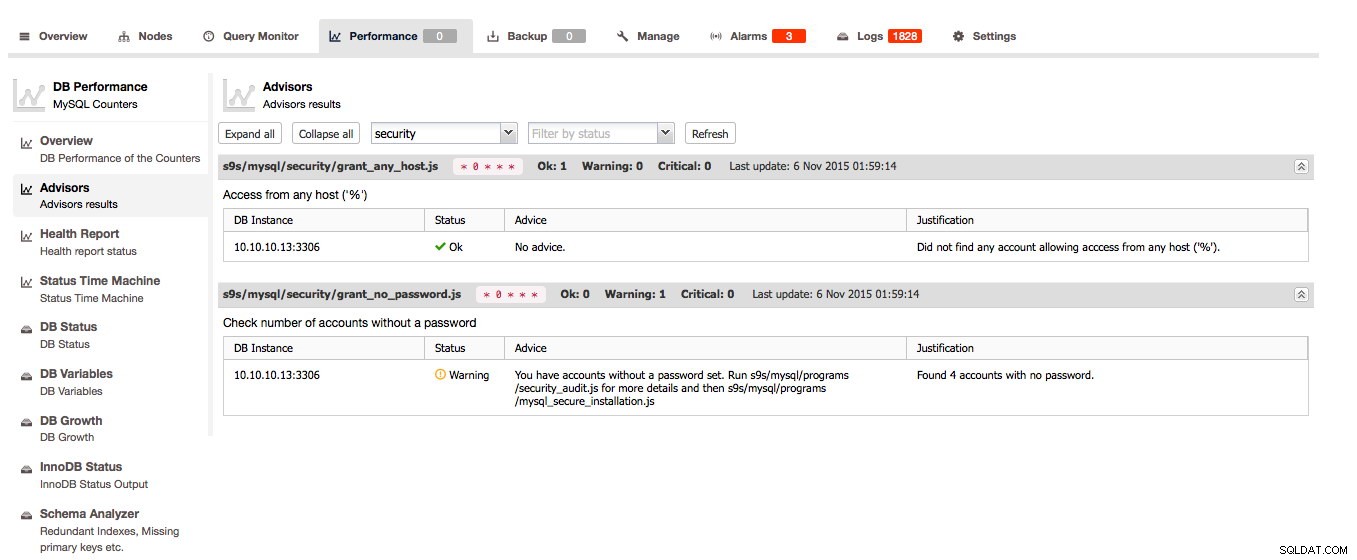
Den bedste del er endnu ikke kommet:du kan oprette dine egne checks i Developer Studio (ClusterControl -> Administrer -> Developer Studio ), kør dem med jævne mellemrum og brug dem igen i sektionen Rådgivere. Vi bloggede om denne nye funktion tidligere i år.
Vi springer over status-/variableoversigten over MySQL og Galera over, da dette er nyttigt som reference, men ikke til dette blogindlæg:det er godt nok, at du ved, at det er her.
Antag nu, at din database vokser, men du vil vide, hvor hurtigt den voksede i den seneste uge. Du kan faktisk holde styr på væksten af både data og indeksstørrelser lige fra ClusterControl:
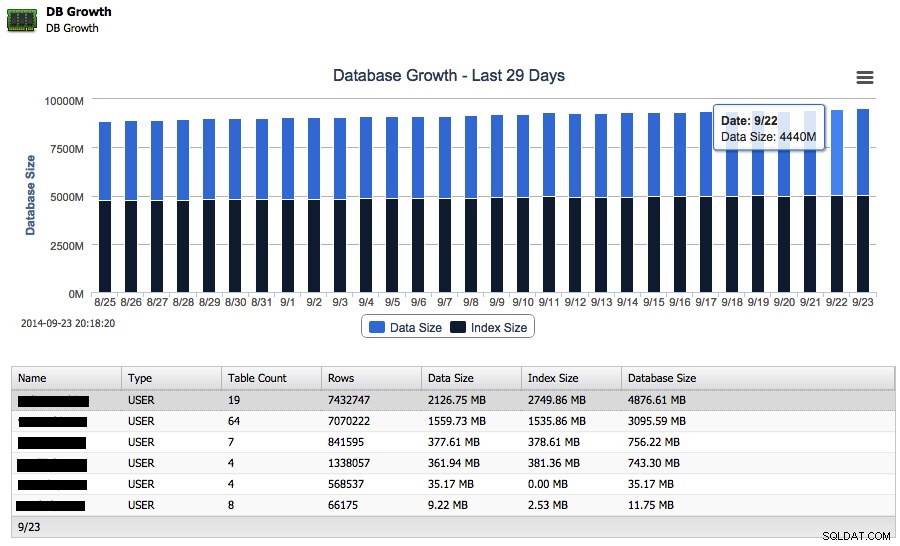
Og ved siden af den samlede vækst på disk kan den også rapportere de 25 største skemaer tilbage.
En anden vigtig funktion er Schema Analyzer i ClusterControl:
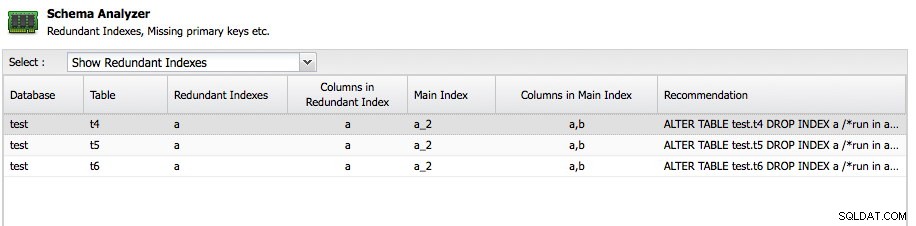
ClusterControl vil analysere dine skemaer og lede efter redundante indekser, MyISAM-tabeller og tabeller uden en primær nøgle. Det er selvfølgelig helt op til dig at holde en tabel uden en primær nøgle, fordi en eller anden applikation måske har oprettet det på denne måde, men i det mindste er det fantastisk at få råd her gratis. Schema Analyzer anbefaler endda den nødvendige ALTER-sætning for at løse problemet.
PostgreSQL
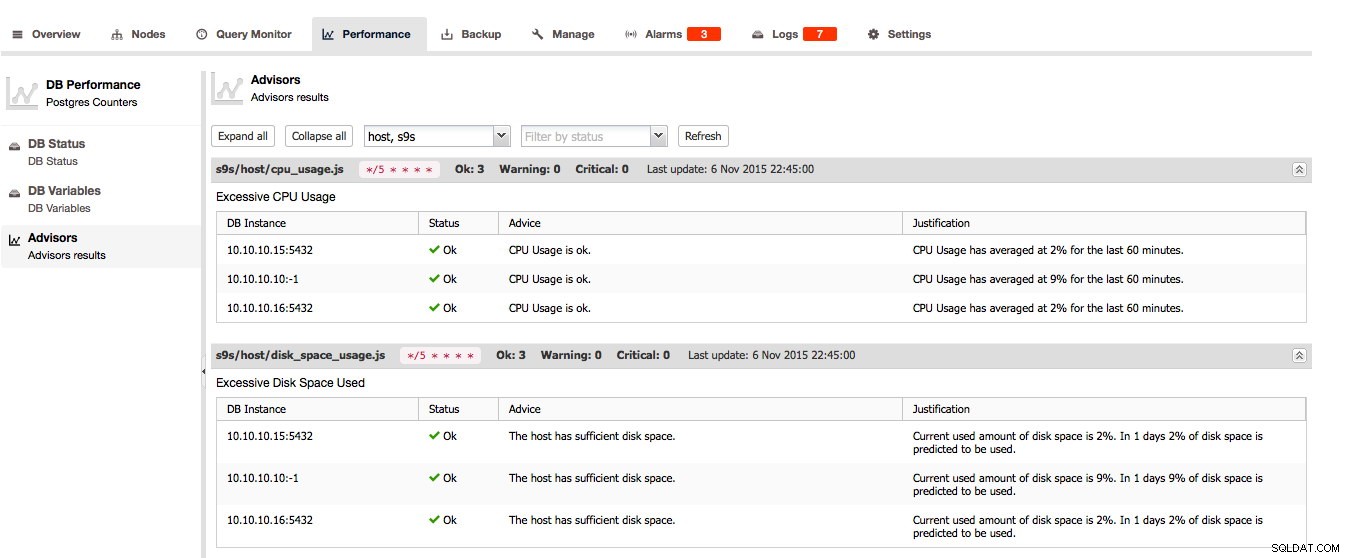
For PostgreSQL kan Advisors, DB Status og DB Variables findes her:
MongoDB
For MongoDB kan Mongo-statistikker og præstationsoversigt findes under fanen Performance. Mongo-statistikken er en oversigt over outputtet fra mongostat, og præstationsoversigten giver et godt grafisk overblik over MongoDB-optællerne:
Sidste tanker
Vi viste dig, hvordan du holder øje med de vigtigste overvågnings- og sundhedstjekfunktioner i ClusterControl. Dette er naturligvis kun begyndelsen på rejsen, da vi snart vil starte endnu en blogserie om Developer Studio-funktionerne, og hvordan du kan foretage de fleste af dine egne checks. Husk også, at vores support til MongoDB og PostgreSQL ikke er så omfattende som vores MySQL-værktøjssæt, men vi forbedrer løbende dette.
Du kan spørge dig selv, hvorfor vi har sprunget over præstationsovervågning og sundhedstjek af HAProxy, ProxySQL og MaxScale. Det gjorde vi bevidst, da blogserien kun dækkede implementeringer af klynger indtil nu og ikke implementeringen af HA-komponenter. Så det er emnet, vi vil dække næste gang.