Effektiviteten af en database afhænger ikke kun af finjustering af de mest kritiske parametre, men går også videre til passende datapræsentation i de relaterede samlinger. For nylig arbejdede jeg på et projekt, der udviklede en social chat-applikation, og efter et par dages test bemærkede vi en vis forsinkelse, når vi hentede data fra databasen. Vi havde ikke så mange brugere, så vi udelukkede, at databaseparametrene skulle justeres og fokuserede på vores forespørgsler for at finde årsagen.
Til vores overraskelse indså vi, at vores datastrukturering ikke var helt passende, da vi havde mere end 1 læseanmodning om at hente nogle specifikke oplysninger.
Den konceptuelle model for, hvordan applikationssektioner sættes på plads, afhænger i høj grad af databasesamlingens struktur. Hvis du f.eks. logger ind på en social app, føres data ind i de forskellige sektioner i henhold til applikationsdesignet som afbildet fra databasepræsentationen.
I en nøddeskal, for en veldesignet database, er skemastruktur og samlingsrelationer vigtige ting i retning af dens forbedrede hastighed og integritet, som vi vil se i de følgende afsnit.
Vi vil diskutere de faktorer, du bør overveje, når du modellerer dine data.
Hvad er datamodellering
Datamodellering er generelt en analyse af dataelementer i en database, og hvor relaterede de er til andre objekter i den pågældende database.
I MongoDB for eksempel kan vi have en brugersamling og en profilsamling. Brugersamlingen viser navne på brugere for en given applikation, mens profilsamlingen fanger profilindstillingerne for hver bruger.
I datamodellering skal vi designe et forhold til at forbinde hver bruger til den korrespondentprofil. I en nøddeskal er datamodellering det grundlæggende trin i databasedesign udover at danne arkitekturgrundlaget for objektorienteret programmering. Det giver også et fingerpeg om, hvordan den fysiske applikation vil se ud under udviklingen. En applikation-database integrationsarkitektur kan illustreres som nedenfor.
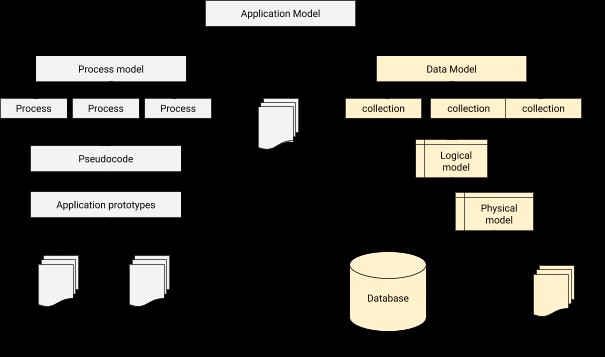
Processen med datamodellering i MongoDB
Datamodellering kommer med forbedret databaseydeevne, men på bekostning af nogle overvejelser, som omfatter:
- Datahentningsmønstre
- Afbalancering af applikationens behov såsom:forespørgsler, opdateringer og databehandling
- Ydeevnefunktioner for den valgte databasemotor
- Den iboende struktur af selve dataene
MongoDB-dokumentstruktur
Dokumenter i MongoDB spiller en stor rolle i beslutningen om, hvilken teknik der skal anvendes for et givet datasæt. Der er generelt to forhold mellem data, som er:
- Indlejrede data
- Referencedata
Indlejrede data
I dette tilfælde gemmes relaterede data i et enkelt dokument enten som en feltværdi eller en matrix i selve dokumentet. Den største fordel ved denne tilgang er, at data denormaliseres og derfor giver mulighed for at manipulere de relaterede data i en enkelt databaseoperation. Følgelig forbedrer dette hastigheden, hvormed CRUD-operationer udføres, og der kræves derfor færre forespørgsler. Lad os overveje et eksempel på et dokument nedenfor:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}I dette sæt af data har vi en elev med hans navn og nogle andre yderligere oplysninger. Indstillinger-feltet er blevet integreret med et objekt, og yderligere er placeLocation-feltet også indlejret med et objekt med bredde- og længdegradskonfigurationer. Alle data for denne elev er indeholdt i et enkelt dokument. Hvis vi skal hente alle informationer for denne elev, kører vi bare:
db.students.findOne({StudentName : "George Beckonn"})Styrker ved indlejring
- Øget dataadgangshastighed:For en forbedret adgangshastighed til data er indlejring den bedste mulighed, da en enkelt forespørgselsoperation kan manipulere data i det angivne dokument med blot et enkelt databaseopslag.
- Reduceret datainkonsistens:Hvis noget går galt under drift (f.eks. en netværksafbrydelse eller strømsvigt), kan kun et par antal dokumenter blive påvirket, da kriterierne ofte vælger et enkelt dokument.
- Reducerede CRUD-operationer. Det vil sige, at læseoperationerne faktisk vil overstige antallet af skrivninger. Desuden er det muligt at opdatere relaterede data i en enkelt atomisk skriveoperation. Dvs. for ovenstående data kan vi opdatere telefonnummeret og også øge afstanden med denne enkelt handling:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Svagheder ved indlejring
- Begrænset dokumentstørrelse. Alle dokumenter i MongoDB er begrænset til BSON-størrelsen på 16 megabyte. Derfor bør den samlede dokumentstørrelse sammen med indlejrede data ikke overskride denne grænse. Ellers kan data for nogle lagermotorer såsom MMAPv1 vokse ud og resultere i datafragmentering som følge af forringet skriveydeevne.
- Dataduplikering:Flere kopier af de samme data gør det sværere at forespørge på de replikerede data, og det kan tage længere tid at filtrere indlejrede dokumenter, hvilket overgår kernefordelen ved indlejring.
Priknotation
Punktnotationen er den identificerende funktion for indlejrede data i programmeringsdelen. Det bruges til at få adgang til elementer i et indlejret felt eller et array. I eksempeldataene ovenfor kan vi returnere oplysninger om den studerende, hvis placering er "Ambassade", med denne forespørgsel ved hjælp af punktnotationen.
db.users.find({'Settings.location': 'Embassy'})Referencedata
Dataforholdet i dette tilfælde er, at de relaterede data er gemt i forskellige dokumenter, men der udstedes et referencelink til disse relaterede dokumenter. For eksempeldataene ovenfor kan vi rekonstruere dem på en sådan måde, at:
Brugerdokument
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Indstillingsdokument
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Der er 2 forskellige dokumenter, men de er forbundet med den samme værdi for felterne _id og id. Datamodellen er således normaliseret. For at vi skal kunne få adgang til oplysninger fra et relateret dokument, skal vi stille yderligere forespørgsler, og det resulterer derfor i øget eksekveringstid. For eksempel, hvis vi ønsker at opdatere ParentPhone og de relaterede afstandsindstillinger, vil vi have mindst 3 forespørgsler, dvs.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Styrker ved henvisning
- Datakonsistens. For hvert dokument opretholdes en kanonisk formular, hvorfor chancerne for datainkonsistens er ret lave.
- Forbedret dataintegritet. På grund af normalisering er det nemt at opdatere data uanset operationens varighed og derfor sikre korrekte data for hvert dokument uden at skabe forvirring.
- Forbedret cacheudnyttelse. Kanoniske dokumenter, der tilgås ofte, gemmes i cachen i stedet for for indlejrede dokumenter, som tilgås et par gange.
- Effektiv hardwareudnyttelse. I modsætning til indlejring, som kan resultere i, at dokumentet vokser ud, fremmer referencer ikke dokumentvækst, hvilket reducerer disk- og RAM-brug.
- Forbedret fleksibilitet, især med et stort sæt underdokumenter.
- Hurtigere skrivning.
Svagheder ved henvisning
- Flere opslag:Da vi skal kigge i en række dokumenter, der matcher kriterierne, er der øget læsetid ved hentning fra disk. Desuden kan dette resultere i cache-misser.
- Der udsendes mange forespørgsler for at opnå en vis operation, og derfor kræver normaliserede datamodeller flere rundrejser til serveren for at fuldføre en specifik operation.
Datanormalisering
Datanormalisering refererer til at omstrukturere en database i overensstemmelse med nogle normale former for at forbedre dataintegriteten og reducere hændelser med dataredundans.
Datamodellering drejer sig om 2 store normaliseringsteknikker, nemlig:
-
Normaliserede datamodeller
Som anvendt i referencedata opdeler normalisering data i flere samlinger med referencer mellem de nye samlinger. En enkelt dokumentopdatering vil blive udstedt til den anden samling og anvendt i overensstemmelse hermed på det matchende dokument. Dette giver en effektiv dataopdateringsrepræsentation og bruges almindeligvis til data, der ændres ret ofte.
-
Denormaliserede datamodeller
Data indeholder indlejrede dokumenter, hvilket gør læseoperationer ret effektive. Det er dog forbundet med mere diskpladsforbrug og også vanskeligheder med at holde synkroniseringen. Denormaliseringskonceptet kan godt anvendes på underdokumenter, hvis data ikke ændres ret ofte.
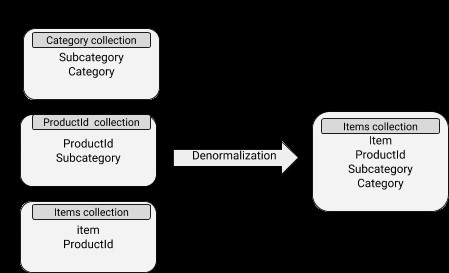
MongoDB-skema
Et skema er grundlæggende et skitseret skelet af felter og datatype, som hvert felt skal indeholde for et givet sæt data. I betragtning af SQL-synspunktet er alle rækker designet til at have de samme kolonner, og hver kolonne skal indeholde den definerede datatype. Men i MongoDB har vi som standard et fleksibelt skema, som ikke har samme overensstemmelse for alle dokumenter.
Fleksibelt skema
Et fleksibelt skema i MongoDB definerer, at dokumenterne ikke nødvendigvis behøver at have samme felter eller datatype, for et felt kan variere på tværs af dokumenter i en samling. Kernefordelen ved dette koncept er, at man kan tilføje nye felter, fjerne eksisterende eller ændre feltværdierne til en ny type og dermed opdatere dokumentet til en ny struktur.
For eksempel kan vi have disse 2 dokumenter i samme samling:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}I det første dokument har vi et aldersfelt, mens der i det andet dokument ikke er noget aldersfelt. Yderligere er datatypen for ParentPhone-feltet et tal, hvorimod det i det andet dokument er sat til false, som er en boolesk type.
Skema-fleksibilitet letter tilknytning af dokumenter til et objekt, og hvert dokument kan matche datafelter for den repræsenterede enhed.
Stivt skema
Så meget som vi har sagt, at disse dokumenter kan adskille sig fra hinanden, kan du nogle gange beslutte dig for at oprette et stift skema. Et stift skema vil definere, at alle dokumenter i en samling vil dele den samme struktur, og dette vil give dig en bedre chance for at indstille nogle dokumentvalideringsregler som en måde at forbedre dataintegriteten under indsættelses- og opdateringsoperationer.
Skemadatatyper
Når du bruger nogle serverdrivere til MongoDB, såsom mongoose, er der nogle datatyper, som giver dig mulighed for at foretage datavalidering. De grundlæggende datatyper er:
- String
- Nummer
- Boolesk
- Dato
- Buffer
- ObjectId
- Array
- Blandet
- Decimal128
- Kort
Tag et kig på eksempelskemaet nedenfor
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Eksempel på use case
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Skemavalidering
Så meget som du kan foretage datavalidering fra applikationssiden, er det altid god praksis også at udføre valideringen fra serverenden. Vi opnår dette ved at anvende skemavalideringsreglerne.
Disse regler anvendes under indsættelse og opdatering. De erklæres normalt på opkrævningsbasis under oprettelsesprocessen. Du kan dog også tilføje dokumentvalideringsreglerne til en eksisterende samling ved hjælp af kommandoen collMod med valideringsmuligheder, men disse regler anvendes ikke på de eksisterende dokumenter, før når en opdatering blev anvendt på dem.
På samme måde, når du opretter en ny samling ved hjælp af kommandoen db.createCollection(), kan du udstede valideringsmuligheden. Tag et kig på dette eksempel, når du opretter en samling til elever. Fra version 3.6 understøtter MongoDB JSON Schema validering, så alt hvad du behøver er at bruge $jsonSchema operatoren.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})I dette skemadesign, hvis vi forsøger at indsætte et nyt dokument som:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Tilbagekaldsfunktionen returnerer nedenstående fejl på grund af nogle overtrådte valideringsregler, såsom at den leverede årsværdi ikke er inden for de angivne grænser.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Yderligere kan du tilføje forespørgselsudtryk til din valideringsindstilling ved hjælp af forespørgselsoperatorer undtagen $where, $text, near og $nearSphere, dvs.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Skemavalideringsniveauer
Som tidligere nævnt udstedes der normalt validering til skriveoperationerne.
Validering kan dog også anvendes på allerede eksisterende dokumenter.
Der er 3 valideringsniveauer:
- Streng:dette er standard MongoDB-valideringsniveauet, og det anvender valideringsregler på alle inserts og opdateringer.
- Moderat:Valideringsreglerne anvendes kun under indsættelser, opdateringer og på allerede eksisterende dokumenter, der opfylder valideringskriterierne.
- Fra:Dette niveau indstiller valideringsreglerne for et givet skema til null, hvorfor der ikke vil blive foretaget nogen validering af dokumenterne.
Eksempel:
Lad os indsætte dataene nedenfor i en klientsamling.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Hvis vi anvender det moderate valideringsniveau ved hjælp af:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Valideringsreglerne vil kun blive anvendt på dokumentet med _id på 1, da det vil matche alle kriterierne.
For det andet dokument, da valideringsreglerne ikke er opfyldt med de udstedte kriterier, vil dokumentet ikke blive valideret.
Skemavalideringshandlinger
Efter at have foretaget validering på dokumenter, kan der være nogle, der kan overtræde valideringsreglerne. Der er altid behov for at give en handling, når dette sker.
MongoDB giver to handlinger, der kan udstedes til de dokumenter, der ikke overholder valideringsreglerne:
- Fejl:Dette er standard MongoDB-handlingen, som afviser enhver indsættelse eller opdatering, hvis den overtræder valideringskriterierne.
-
Advarsel:Denne handling vil registrere overtrædelsen i MongoDB-loggen, men gør det muligt at fuldføre indsættelses- eller opdateringshandlingen. For eksempel:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Hvis vi forsøger at indsætte et dokument som dette:
db.students.insert( { name: "Amanda", status: "Updated" } );Gpa'en mangler uanset, at det er et obligatorisk felt i skemadesignet, men da valideringshandlingen er sat til at advare, vil dokumentet blive gemt, og en fejlmeddelelse vil blive registreret i MongoDB-loggen.