ClusterControl 1.6 kommer med strammere integration med AWS, Azure og Google Cloud, så det nu er muligt at lancere nye instanser og implementere MySQL, MariaDB, MongoDB og PostgreSQL direkte fra ClusterControl-brugergrænsefladen. I denne blog vil vi vise dig, hvordan du implementerer en klynge på Amazon Web Services.
Bemærk, at denne nye funktion kræver to moduler kaldet clustercontrol-cloud og clustercontrol-clud . Førstnævnte er en hjælpedæmon, som udvider CMON-kapaciteten til cloud-kommunikation, mens sidstnævnte er en filhåndteringsklient til at uploade og downloade filer på cloud-instanser. Begge pakker er afhængigheder af clustercontrol UI-pakken, som vil blive installeret automatisk, hvis de ikke eksisterer. Se komponentdokumentationssiden for detaljer.
Cloud-legitimationsoplysninger
ClusterControl giver dig mulighed for at gemme og administrere dine cloud-legitimationsoplysninger under Integrationer (sidemenu) -> Cloud Providers:
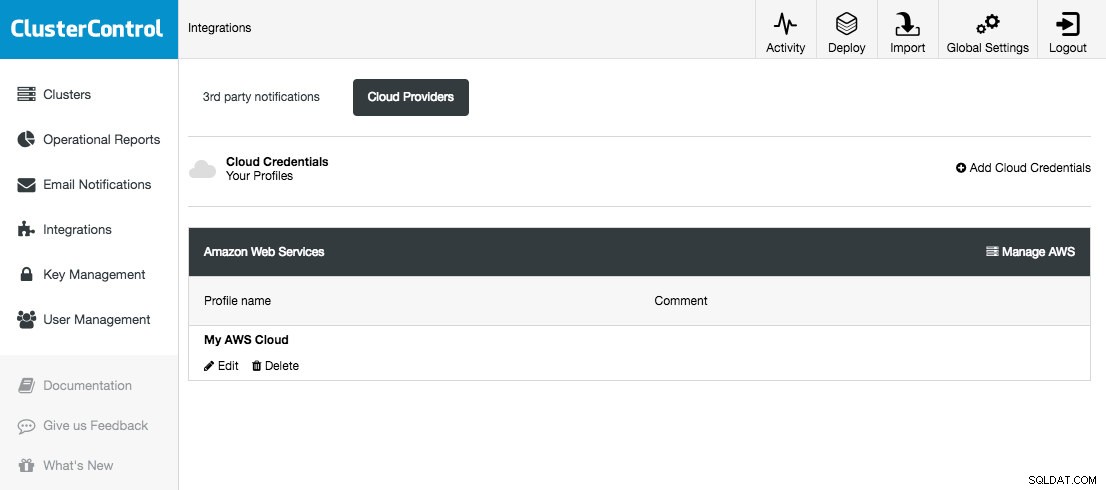
De understøttede cloudplatforme i denne udgivelse er Amazon Web Services, Google Cloud Platform og Microsoft Azure. På denne side kan du tilføje nye cloud-legitimationsoplysninger, administrere eksisterende og også oprette forbindelse til din cloud-platform for at administrere ressourcer.
De legitimationsoplysninger, der er sat op her, kan bruges til at:
- Administrer skyressourcer
- Implementer databaser i skyen
- Upload backup til skylageret
Det følgende er, hvad du ville se, hvis du klikkede på knappen "Administrer AWS":
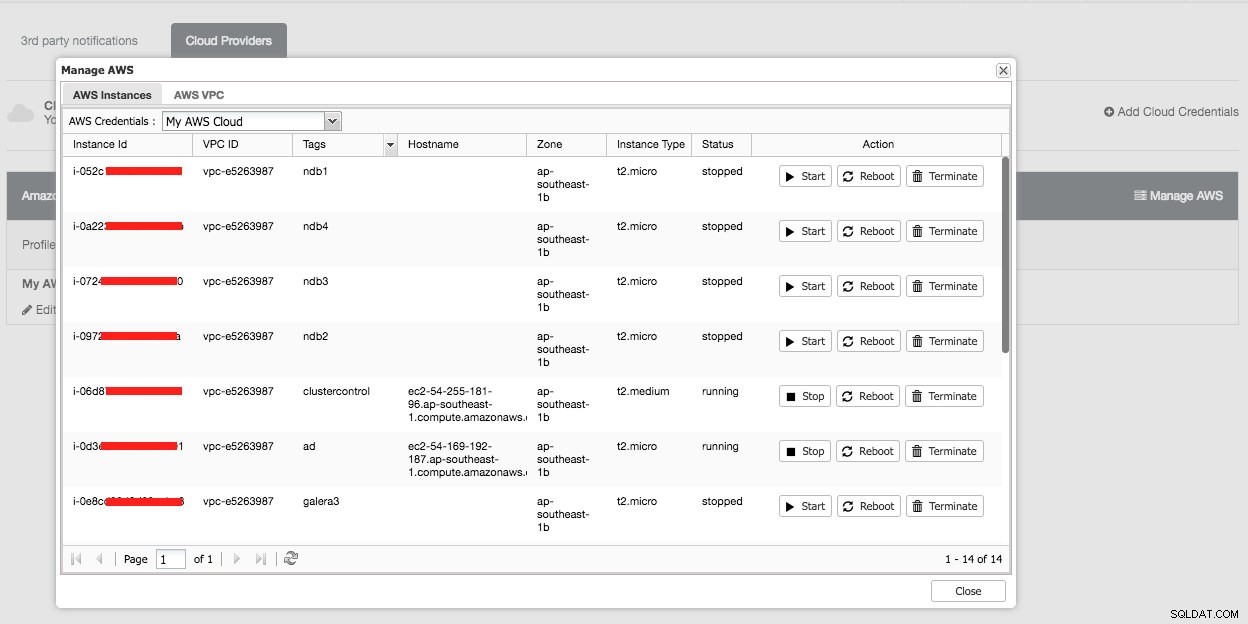
Du kan udføre simple administrationsopgaver på dine cloud-instanser. Du kan også kontrollere VPC-indstillingerne under fanen "AWS VPC", som vist på følgende skærmbillede:
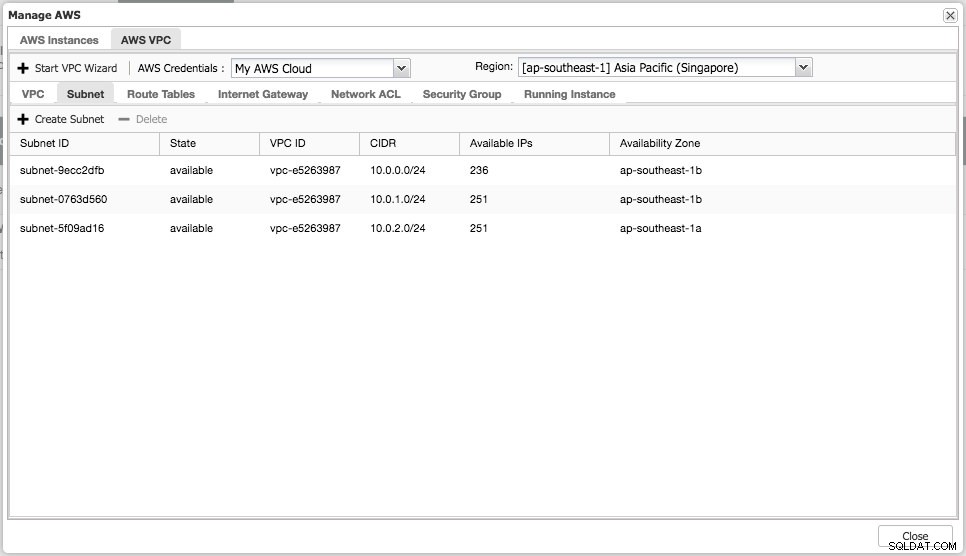
Ovenstående funktioner er nyttige som reference, især når du forbereder dine cloud-forekomster, før du starter databaseimplementeringerne.
Databaseimplementering i skyen
I tidligere versioner af ClusterControl ville databaseimplementering i skyen blive behandlet på samme måde som implementering på standardværter, hvor du skulle oprette cloud-forekomsterne på forhånd og derefter angive instansdetaljerne og legitimationsoplysningerne i guiden "Deploy Database Cluster". Implementeringsproceduren var uvidende om nogen ekstra funktionalitet og fleksibilitet i cloudmiljøet, såsom dynamisk IP- og værtsnavnallokering, NAT-ed offentlig IP-adresse, lagerelasticitet, virtuel privat cloud-netværkskonfiguration og så videre.
Med version 1.6 skal du blot levere cloud-legitimationsoplysningerne, som kan administreres via "Cloud Providers"-grænsefladen og følge "Deploy in the Cloud"-implementeringsguiden. Fra ClusterControl UI, klik på Deploy, og du vil blive præsenteret for følgende muligheder:
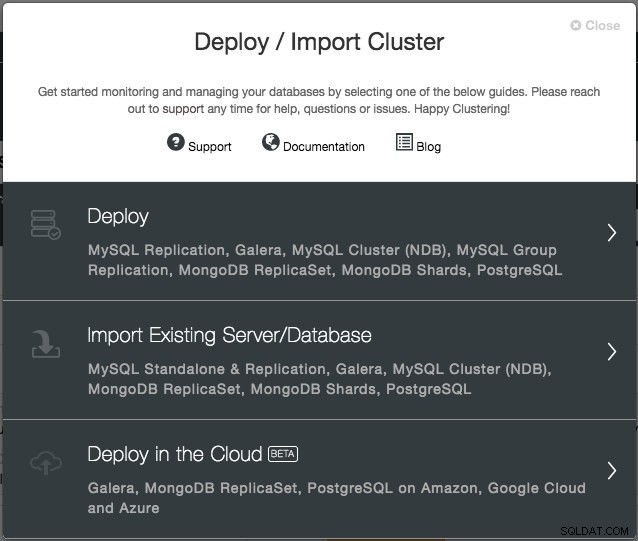
I øjeblikket er de understøttede cloud-udbydere de tre store spillere - Amazon Web Service (AWS), Google Cloud og Microsoft Azure. Vi vil integrere flere udbydere i den fremtidige udgivelse.
På den første side vil du blive præsenteret for mulighederne for klyngedetaljer:
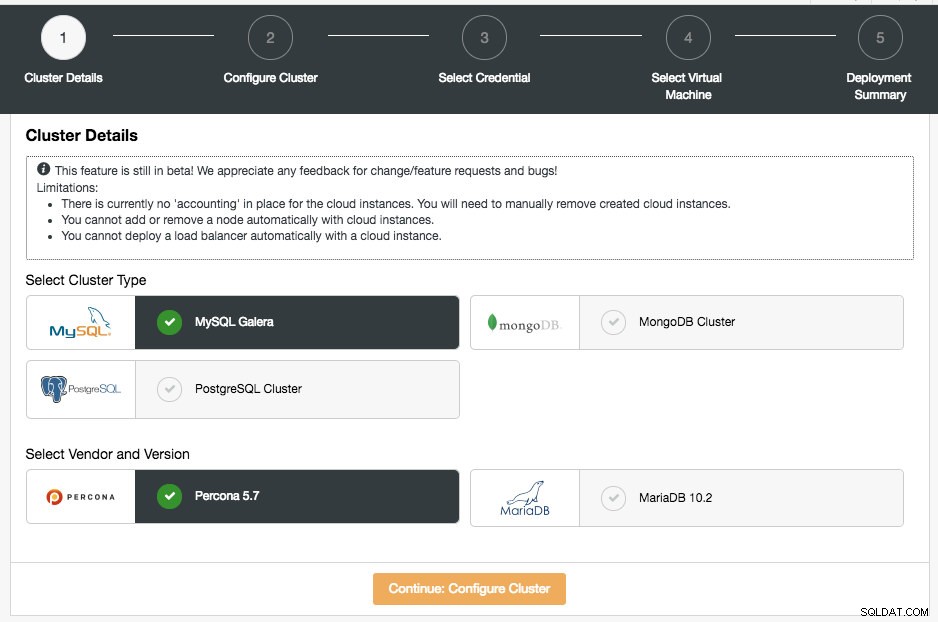
I dette afsnit skal du vælge den understøttede klyngetype, MySQL Galera Cluster, MongoDB Replica Set eller PostgreSQL Streaming Replication. Det næste trin er at vælge den understøttede leverandør for den valgte klyngetype. I øjeblikket understøttes følgende leverandører og versioner:
- MySQL Galera Cluster - Percona XtraDB Cluster 5.7, MariaDB 10.2
- MongoDB Cluster - MongoDB 3.4 af MongoDB, Inc og Percona Server til MongoDB 3.4 af Percona (kun replikasæt).
- PostgreSQL-klynge - PostgreSQL 10.0 (kun streamingreplikering).
I næste trin vil du blive præsenteret for følgende dialogboks:
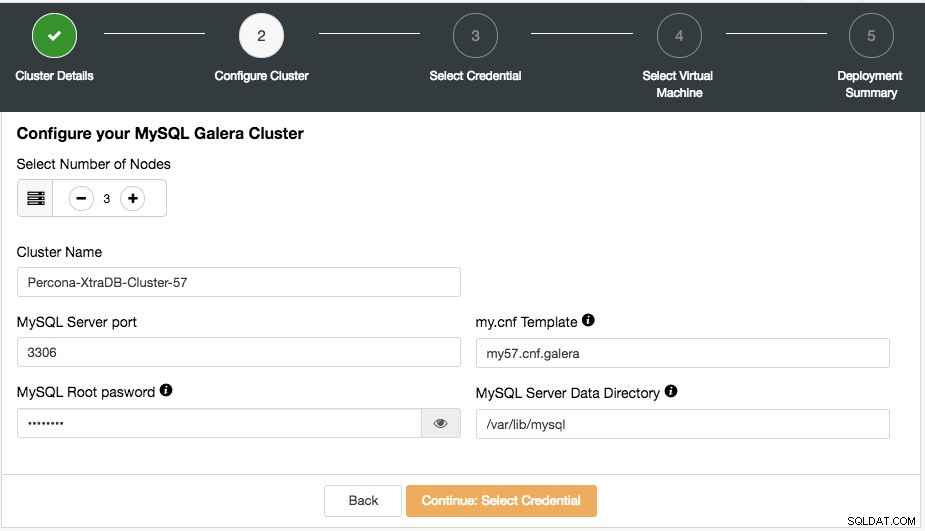
Her kan du konfigurere den valgte klyngetype i overensstemmelse hermed. Vælg antallet af noder. Klyngenavnet vil blive brugt som instanstagget, så du nemt kan genkende denne implementering i din cloududbyders dashboard. Der er ikke tilladt mellemrum i klyngenavnet. My.cnf Template er skabelonkonfigurationsfilen, som ClusterControl vil bruge til at implementere klyngen. Det skal være placeret under /usr/share/cmon/templates på ClusterControl-værten. Resten af felterne er ret selvforklarende.
Den næste dialog er at vælge cloud-legitimationsoplysningerne:
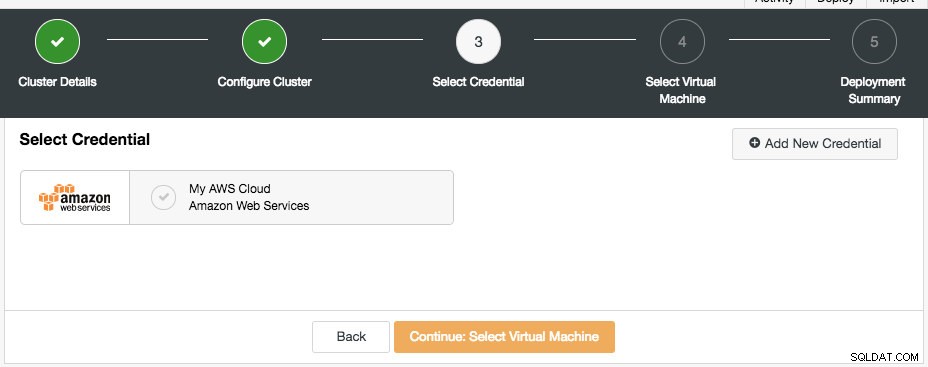
Du kan vælge de eksisterende cloud-legitimationsoplysninger eller oprette en ny ved at klikke på knappen "Tilføj ny legitimation". Det næste trin er at vælge den virtuelle maskine-konfiguration:
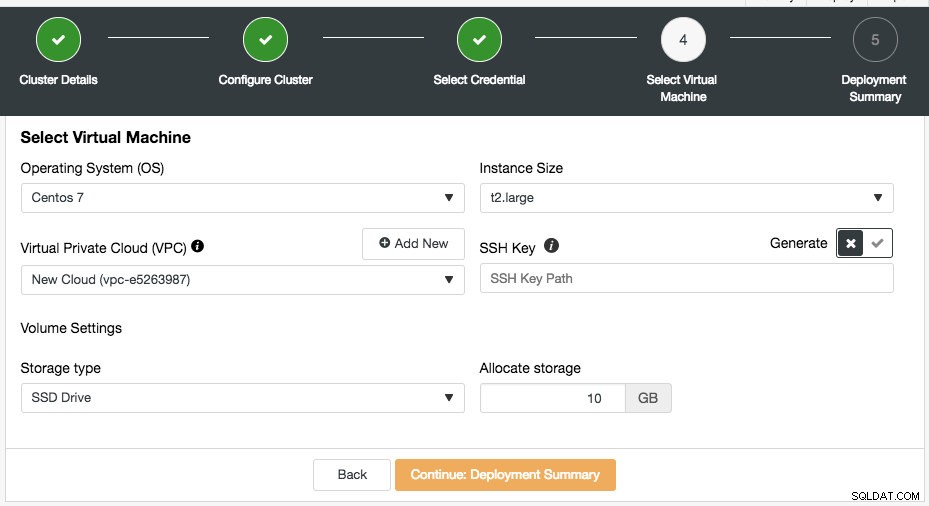
De fleste af indstillingerne i dette trin udfyldes dynamisk fra cloud-udbyderen af de valgte legitimationsoplysninger. Du kan konfigurere operativsystemet, instansstørrelse, VPC-indstilling, lagertype og størrelse og også angive SSH-nøglens placering på ClusterControl-værten. Du kan også lade ClusterControl generere en ny nøgle specifikt til disse forekomster. Når du klikker på knappen "Tilføj ny" ud for Virtual Private Cloud, vil du blive præsenteret for en formular til at oprette en ny VPC:
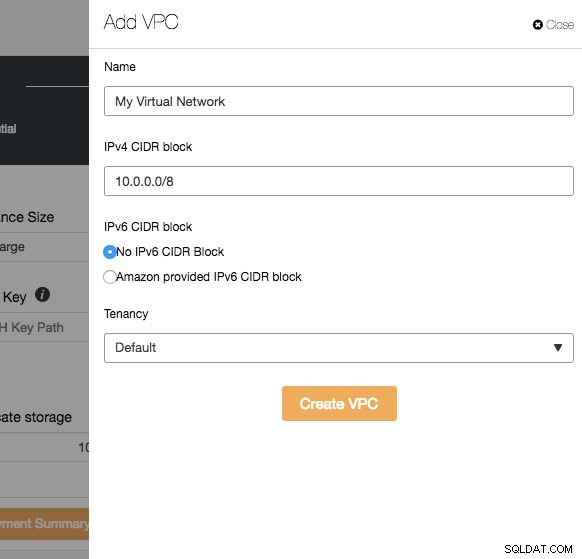
VPC er en logisk netværksinfrastruktur, du har inden for din cloud-platform. Du kan konfigurere din VPC ved at ændre dens IP-adresseområde, oprette undernet, konfigurere rutetabeller, netværksgateways og sikkerhedsindstillinger. Det anbefales at implementere din databaseinfrastruktur i dette netværk til isolering, sikkerhed og routingkontrol.
Når du opretter en ny VPC, skal du angive VPC-navnet og IPv4-adresseblokken med undernet. Vælg derefter, om IPv6 skal være en del af netværket og lejemuligheden. Du kan derefter bruge dette virtuelle netværk til din databaseinfrastruktur.
Det sidste trin er implementeringsoversigten:
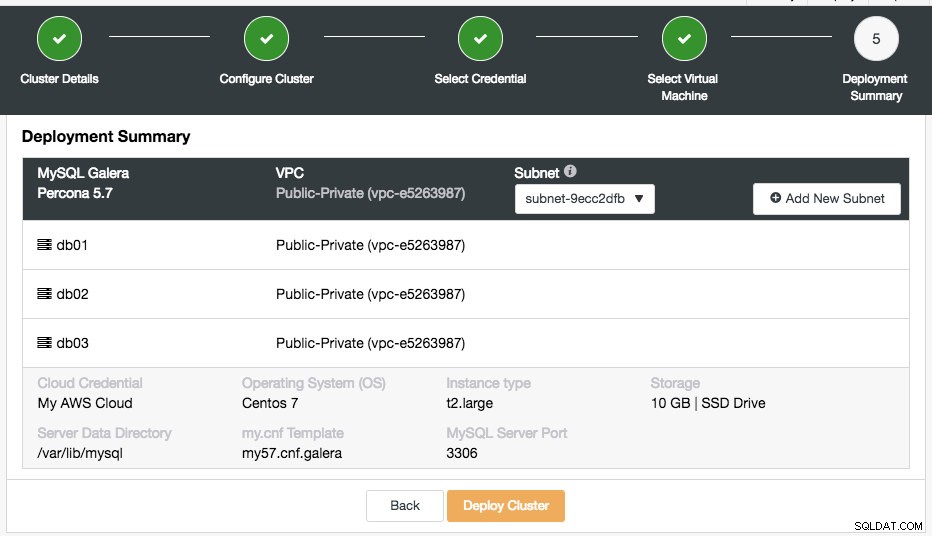
I dette trin skal du vælge hvilket undernet under det valgte virtuelle netværk, som du vil have databasen til at køre på. Bemærk, at det valgte undernet SKAL have automatisk tildeling af offentlig IPv4-adresse aktiveret. Du kan også oprette et nyt undernet under denne VPC ved at klikke på knappen "Tilføj nyt undernet". Bekræft, om alt er korrekt, og tryk på knappen "Deploy Cluster" for at starte implementeringen.
Du kan derefter overvåge fremskridtene ved at klikke på Aktivitet -> Jobs -> Opret klynge -> Fuld jobdetaljer:
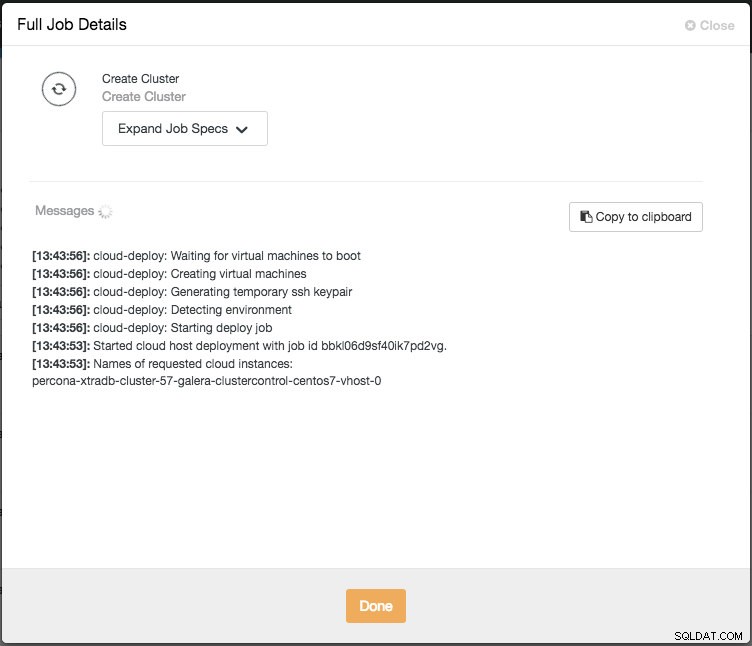
Afhængigt af forbindelserne kan det tage 10 til 20 minutter at fuldføre. Når du er færdig, vil du se en ny databaseklynge opført under ClusterControl-dashboardet. For PostgreSQL-streaming-replikeringsklynge skal du muligvis kende master- og slave-IP-adresserne, når implementeringen er fuldført. Du skal blot gå til fanen Noder, og du vil se de offentlige og private IP-adresser på nodelisten til venstre:
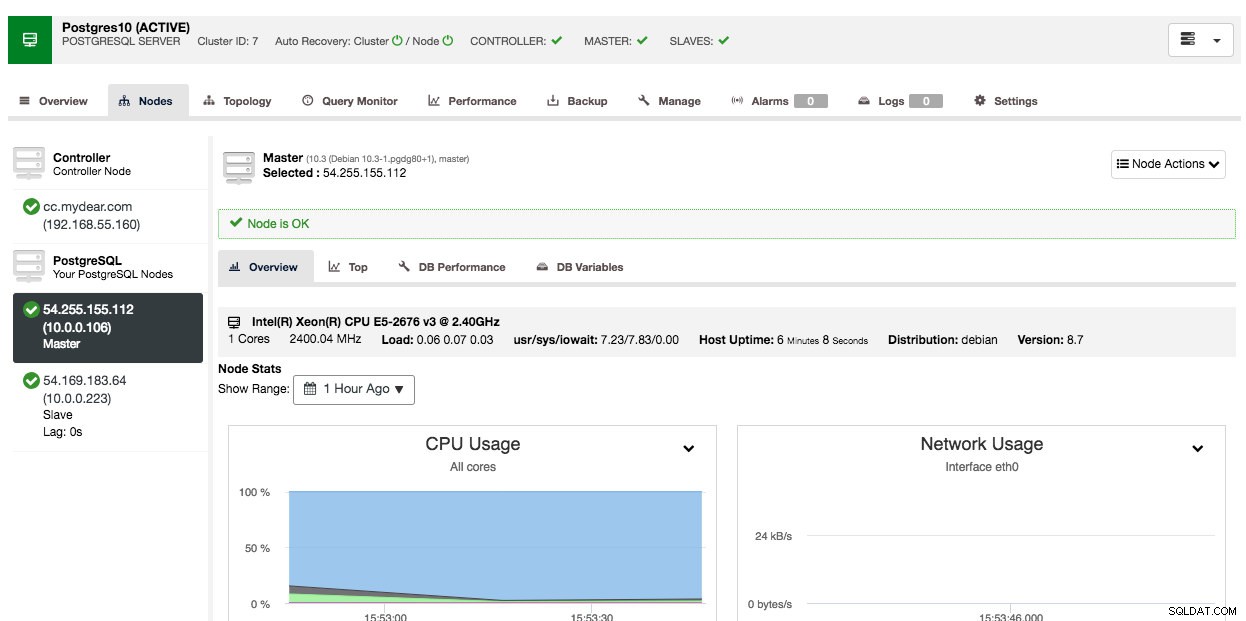
Din databaseklynge er nu implementeret og kører på AWS.
I øjeblikket fungerer opskaleringen på samme måde som standardværten, hvor du skal oprette en cloud-instans manuelt på forhånd og angive værten under ClusterControl -> vælg klyngen -> Tilføj node.
Under hætten udfører implementeringsprocessen følgende:
- Opret cloud-forekomster
- Konfigurer sikkerhedsgrupper og netværk
- Bekræft SSH-forbindelsen fra ClusterControl til alle oprettede forekomster
- Implementer database på hver forekomst
- Konfigurer klynge- eller replikeringslinks
- Registrer implementeringen i ClusterControl
Bemærk, at denne funktion stadig er i beta. Ikke desto mindre kan du bruge denne funktion til at fremskynde dit udviklings- og testmiljø ved at kontrollere og administrere databaseklyngen i forskellige cloud-udbydere fra en enkelt brugergrænseflade.
Sikkerhedskopiering af database i skyen
Denne funktion har eksisteret siden ClusterControl 1.5.0, og nu har vi tilføjet understøttelse af Azure Cloud Storage. Det betyder, at du nu kan uploade og downloade den oprettede backup på alle tre store cloud-udbydere (AWS, GCP og Azure). Uploadprocessen sker lige efter, at sikkerhedskopien er oprettet (hvis du skifter til "Upload sikkerhedskopi til skyen"), eller du kan manuelt klikke på skyikonknappen på backuplisten:
Du kan derefter downloade og gendanne sikkerhedskopier fra skyen, i tilfælde af at du mister dit lokale backuplager, eller hvis du har brug for at reducere det lokale forbrug af diskplads til dine sikkerhedskopier.
Nuværende begrænsninger
Der er nogle kendte begrænsninger for cloud-implementeringsfunktionen, som angivet nedenfor:
- Der er i øjeblikket intet "regnskab" på plads for cloud-forekomsterne. Du bliver nødt til manuelt at fjerne cloud-forekomsterne, hvis du fjerner en databaseklynge.
- Du kan ikke tilføje eller fjerne en node automatisk med cloud-forekomster.
- Du kan ikke implementere en belastningsbalancer automatisk med en cloud-instans.
Vi har grundigt testet funktionen i mange miljøer og opsætninger, men der er altid hjørnesager, som vi måske er gået glip af. For mere information, se venligst ændringsloggen.
God fornøjelse med at klynge sammen i skyen!