Forbedring af systemets ydeevne, især for computerstrukturer, kræver en proces for at få et godt overblik over ydeevnen. Denne proces kaldes generelt overvågning. Overvågning er en væsentlig del af databasestyring, og de detaljerede ydelsesoplysninger for din MongoDB vil ikke kun hjælpe dig med at måle dens funktionelle tilstand; men giv også et fingerpeg om uregelmæssigheder, hvilket er nyttigt, når du laver vedligeholdelse. Det er vigtigt at identificere usædvanlig adfærd og rette op på dem, før de eskalerer til mere alvorlige fejl.
Nogle af de typer fejl, der kan opstå, er...
- Forsinkelse eller opbremsning
- Utilstrækkelige ressourcer
- Systemproblemer
Overvågning er ofte centreret om at analysere målinger. Nogle af de nøglemålinger, du ønsker at overvåge, inkluderer...
- Databasens ydeevne
- Udnyttelse af ressourcer (CPU-brug, tilgængelig hukommelse og netværksbrug)
- Nyde tilbageslag
- Mætning og begrænsning af ressourcerne
- Gennemstrømsoperationer
I denne blog vil vi i detaljer diskutere disse målinger og se på tilgængelige værktøjer fra MongoDB (såsom hjælpeprogrammer og kommandoer). Vi vil også se på andre softwareværktøjer såsom Pandora, FMS Open Source og Robo 3T. For enkelhedens skyld vil vi bruge Robo 3T-softwaren i denne artikel til at demonstrere metrikken.
Databasens ydeevne
Den første og vigtigste ting at tjekke på en database er dens generelle ydeevne, for eksempel om serveren er aktiv eller ej. Hvis du kører denne kommando db.serverStatus() på en database i Robo 3T, vil du blive præsenteret for denne information, der viser din servers tilstand.
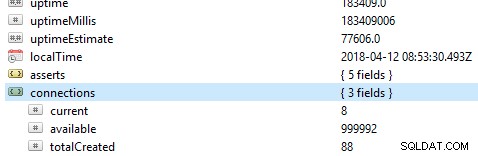

Replikasæt
Replica-sæt er en gruppe af mongod-processer, der opretholder det samme datasæt. Hvis du bruger replikasæt, især i produktionstilstand, vil operationslogfiler danne grundlag for replikeringsprocessen. Alle skriveoperationer spores ved hjælp af noder, det vil sige en primær node og en sekundær node, som lagrer en samling af begrænset størrelse. På den primære knude påføres og behandles skriveoperationerne. Men hvis den primære node fejler, før de kopieres til operationslogfilerne, foretages den sekundære skrivning, men i dette tilfælde bliver dataene muligvis ikke replikeret.
Nøglemålinger at holde øje med...
Replikeringsforsinkelse
Dette definerer, hvor langt den sekundære knude er bag den primære knude. En optimal tilstand kræver, at afstanden er så lille som muligt. På et normalt operativsystem estimeres denne forsinkelse til at være 0. Hvis kløften er for stor, vil dataintegriteten blive kompromitteret, når den sekundære node er forfremmet til primær. I dette tilfælde kan du indstille en tærskel, for eksempel 1 minut, og hvis den overskrides, indstilles en advarsel. Almindelige årsager til bred replikationsforsinkelse omfatter...
- Shards, der kan have en utilstrækkelig skrivekapacitet, hvilket ofte er forbundet med ressourcemætning.
- Den sekundære node leverer data med en langsommere hastighed end den primære node.
- Noder kan også på en eller anden måde være forhindret i at kommunikere, muligvis på grund af et dårligt netværk.
- Operationer på den primære node kan også være langsommere og blokerer derved replikering. Hvis dette sker, kan du køre følgende kommandoer:
- db.getProfilingLevel():hvis du får en værdi på 0, så er dine db-operationer optimale.
Hvis værdien er 1, svarer det til langsomme operationer, som følgelig kan skyldes langsomme forespørgsler. - db.getProfilingStatus():i dette tilfælde tjekker vi værdien af slowms, som standard er den 100ms. Hvis værdien er større end dette, kan du have tunge skriveoperationer på de primære eller utilstrækkelige ressourcer på den sekundære. For at løse dette kan du skalere den sekundære, så den har lige så mange ressourcer som den primære.
- db.getProfilingLevel():hvis du får en værdi på 0, så er dine db-operationer optimale.
Markører
Hvis du laver en læseanmodning, f.eks. find, vil du blive forsynet med en cursor, som er en pegepind til datasættet for resultatet. Hvis du kører denne kommando db.serverStatus() og navigerer til metrics-objektet og derefter markøren, vil du se dette...

I dette tilfælde blev cursor.timeOut-egenskaben opdateret trinvist til 9, fordi der var 9 forbindelser, der døde uden at lukke markøren. Konsekvensen er, at den forbliver åben på serveren og dermed forbruge hukommelse, medmindre den høstes af standard MongoDB-indstillingen. En advarsel til dig bør være at identificere ikke-aktive markører og høste dem af for at spare på hukommelsen. Du kan også undgå ikke-timeout-markører, fordi de ofte holder på ressourcer, og derved sænke den interne systemydelse. Dette kan opnås ved at indstille værdien af egenskaben cursor.open.noTimeout til en værdi på 0.
Journalist
I betragtning af WiredTiger Storage Engine, før data optages, bliver de først skrevet til diskfilerne. Dette kaldes journalføring. Journalføring sikrer tilgængeligheden og holdbarheden af data om en fejlbegivenhed, hvorfra en retablering kan udføres.
Til gendannelsesformål bruger vi ofte checkpoints (især for WiredTiger-lagersystemet) til at gendanne fra det sidste checkpoint. Men hvis MongoDB lukker ned uventet, bruger vi journaliseringsteknikken til at gendanne data, der blev behandlet eller leveret efter det sidste kontrolpunkt.
Journalering bør ikke slås fra i det første tilfælde, da det kun tager 60 sekunder at oprette et nyt kontrolpunkt. Hvis der opstår en fejl, kan MongoDB derfor afspille journalen igen for at gendanne tabte data inden for disse sekunder.
Journalføring indsnævrer generelt tidsintervallet, fra data overføres til hukommelsen, til det er holdbart på disken. storage.journal objektet har en egenskab, der beskriver commiting-frekvensen, det vil sige commitIntervalMs, som ofte er sat til en værdi på 100ms for WiredTiger. At indstille den til en lavere værdi vil forbedre hyppig optagelse af skrivninger og dermed reducere tilfælde af datatab.
Låseydelse
Dette kan være forårsaget af flere læse- og skriveanmodninger fra mange klienter. Når dette sker, er der behov for at bevare konsistensen og undgå skrivekonflikter. For at opnå dette bruger MongoDB multi-granularity-locking, som tillader låseoperationer at forekomme på forskellige niveauer, såsom globalt, database- eller samlingsniveau.
Hvis du har dårlige skemadesignmønstre, vil du være sårbar over for låse, der holdes i lang tid. Dette opleves ofte, når man laver to eller flere forskellige skriveoperationer til et enkelt dokument i samme samling, med en konsekvens af at blokere hinanden. Til WiredTiger-lagringsmotoren kan vi bruge billetsystemet, hvor læse- eller skriveanmodninger kommer fra noget som en kø eller tråd.
Som standard er det samtidige antal læse- og skriveoperationer defineret af parametrene wiredTigerConcurrentWriteTransactions og wiredTigerConcurrentReadTransactions, som begge er indstillet til en værdi på 128.
Hvis du skalerer denne værdi for højt, vil du ende med at blive begrænset af CPU-ressourcer. For at øge gennemstrømningsoperationerne vil det være tilrådeligt at skalere vandret ved at give flere skår.
Severalnines Bliv en MongoDB DBA - Bring MongoDB to ProductionFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere MongoDBDownload gratisBrug af ressourcer
Dette beskriver generelt brugen af tilgængelige ressourcer såsom CPU-kapacitet/behandlingshastighed og RAM. Ydeevnen, især for CPU'en, kan ændre sig drastisk i overensstemmelse med usædvanlige trafikbelastninger. Ting at tjekke efter inkluderer...
- Antal forbindelser
- Opbevaring
- Cache
Antal forbindelser
Hvis antallet af forbindelser er højere end hvad databasesystemet kan håndtere, vil der være en del kø. Følgelig vil dette overvælde databasens ydeevne og få din opsætning til at køre langsomt. Dette nummer kan resultere i driverproblemer eller endda komplikationer med din applikation.
Hvis du overvåger et bestemt antal forbindelser i en periode og derefter bemærker, at denne værdi har toppet, er det altid en god praksis at indstille en advarsel, hvis forbindelsen overstiger dette antal.
Hvis tallet bliver for højt, kan du skalere op for at imødekomme denne stigning. For at gøre dette skal du kende antallet af tilgængelige forbindelser inden for en given periode, ellers, hvis de tilgængelige forbindelser ikke er nok, vil anmodninger ikke blive behandlet rettidigt.
Som standard giver MongoDB understøttelse af op til 1 million forbindelser. Med din overvågning skal du altid sikre dig, at de nuværende forbindelser aldrig kommer for tæt på denne værdi. Du kan kontrollere værdien i forbindelsesobjektet.

Lagring
Hver række og datapost i MongoDB omtales som et dokument. Dokumentdata er i BSON-format. På en given database, hvis du kører kommandoen db.stats(), vil du blive præsenteret for disse data.
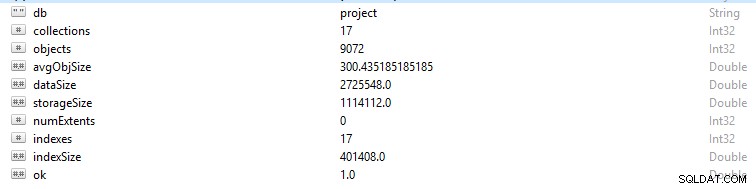
- StorageSize definerer størrelsen af alle dataomfang i databasen.
- IndexSize angiver størrelsen af alle indekser, der er oprettet i den pågældende database.
- dataSize er et mål for den samlede plads, som dokumenterne i databasen tager.
Du kan nogle gange se en ændring i hukommelsen, især hvis mange data er blevet slettet. I dette tilfælde bør du konfigurere en advarsel for at sikre, at den ikke skyldes ondsindet aktivitet.
Nogle gange kan den samlede lagerstørrelse skyde op, mens databasetrafikgrafen er konstant, og i dette tilfælde bør du kontrollere din applikation eller databasestruktur for at undgå dubletter, hvis det ikke er nødvendigt.
Ligesom den generelle hukommelse på en computer, har MongoDB også caches, hvori aktive data midlertidigt gemmes. Imidlertid kan en operation anmode om data, som ikke er i denne aktive hukommelse, og derfor foretage en anmodning fra hoveddisklageret. Denne anmodning eller situation omtales som sidefejl. Anmodninger om sidefejl kommer med en begrænsning af at tage længere tid at udføre og kan være skadelige, når de forekommer ofte. For at undgå dette scenarie skal du sikre dig, at størrelsen på din RAM altid er nok til at imødekomme de datasæt, du arbejder med. Du bør også sikre dig, at du ikke har nogen skemaredundans eller unødvendige indekser.
Cache
Cache er et midlertidigt datalagerelement for ofte tilgåede data. I WiredTiger bruges filsystemets cache og storage engine cache ofte. Sørg altid for, at dit arbejdssæt ikke buler ud over den tilgængelige cache, ellers vil sidefejlene stige i antal, hvilket forårsager nogle præstationsproblemer.
På et tidspunkt kan du beslutte at ændre dine hyppige handlinger, men ændringerne afspejles nogle gange ikke i cachen. Disse umodificerede data omtales som "Beskidte data". Det eksisterer, fordi det endnu ikke er blevet tømt til disk. Der vil opstå flaskehalse, hvis mængden af "Dirty Data" vokser til en gennemsnitlig værdi defineret ved langsom skrivning til disken. Tilføjelse af flere shards vil hjælpe med at reducere dette antal.
CPU-udnyttelse
Ukorrekt indeksering, dårlig skemastruktur og uvenligt designede forespørgsler vil kræve mere CPU-opmærksomhed og vil derfor naturligvis øge dens udnyttelse.
Throughput Operations
At få nok information om disse operationer kan i vid udstrækning gøre det muligt for en at undgå følgemæssige tilbageslag såsom fejl, mætning af ressourcer og funktionelle komplikationer.
Du bør altid notere dig antallet af læse- og skriveoperationer til databasen, det vil sige et overblik over klyngens aktiviteter. At kende antallet af operationer, der genereres for anmodningerne, vil gøre det muligt for dig at beregne den belastning, som databasen forventes at håndtere. Belastningen kan derefter håndteres enten ved at opskalere din database eller udskalere; afhængig af hvilken type ressourcer du har. Dette giver dig mulighed for nemt at måle kvotientforholdet, som anmodningerne akkumuleres i, til den hastighed, hvormed de behandles. Desuden kan du optimere dine forespørgsler på passende vis for at forbedre ydeevnen.
For at kontrollere antallet af læse- og skriveoperationer skal du køre denne kommando db.serverStatus(), og derefter navigere til objektet locks.global, værdien for egenskaben r repræsenterer antallet af læseanmodninger og w antallet af skrivninger.
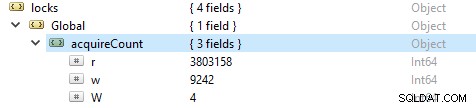
Oftere er læseoperationerne mere end skriveoperationerne. Aktive klient-metrics rapporteres under globalLock.
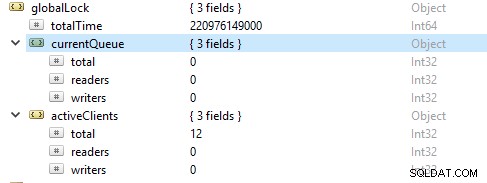
Mætning og begrænsning af ressourcer
Nogle gange kan databasen ikke holde trit med skrive- og læsehastigheden, som portrætteret af et stigende antal forespørgsler i kø. I dette tilfælde skal du skalere din database op ved at levere flere shards for at gøre det muligt for MongoDB at adressere anmodningerne hurtigt nok.
Nyde tilbageslag
MongoDB-logfiler giver altid et generelt overblik over returnerede assert-undtagelser. Dette resultat vil give dig et fingerpeg om de mulige årsager til fejl. Hvis du kører kommandoen, db.serverStatus(), inkluderer nogle af de fejlmeddelelser, du vil bemærke:

- Almindelige påstande:Disse er et resultat af en driftsfejl. For eksempel i et skema, hvis en strengværdi er angivet til et heltalsfelt, hvilket resulterer i fejllæsning af BSON-dokumentet.
- Advarsel hævder:Disse er ofte advarsler om et eller andet problem, men de har ikke den store indflydelse på dets funktion. For eksempel når du opgraderer din MongoDB, kan du blive advaret ved hjælp af forældede funktioner.
- Besked hævder:de er et resultat af interne serverundtagelser såsom langsomt netværk, eller hvis serveren ikke er aktiv.
- Bruger hævder:ligesom almindelige påstande opstår disse fejl, når en kommando udføres, men de returneres ofte til klienten. For eksempel hvis der er dublerede nøgler, utilstrækkelig diskplads eller ingen adgang til at skrive ind i databasen. Du vil vælge at tjekke din ansøgning for at rette disse fejl.