Dette blogindlæg er en fortsættelse af den forrige del 1, hvor vi har dækket det grundlæggende i SNMP-integration med ClusterControl.
I dette blogindlæg vil vi fokusere på SNMP-fælder og alarmering. SNMP-fælder er de hyppigst anvendte advarselsmeddelelser, der sendes fra en ekstern SNMP-aktiveret enhed (en agent) til en central opsamler, "SNMP-manageren". I tilfælde af ClusterControl kan en fælde være en alarm, efter at den kritiske alarm for en klynge ikke er 0, hvilket indikerer, at der sker noget slemt.
Som vist i det forrige blogindlæg har vi med henblik på dette proof-of-concept to definitioner af SNMP-fælde-meddelelser:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Meddelelserne (eller fælderne) er criticalAlarmNotification og criticalAlarmNotificationEnded. Begge notifikationshændelser kan bruges til at signalere vores Nagios-tjeneste, uanset om klyngen aktivt har kritiske alarmer eller ej. I Nagios er betegnelsen for dette passiv kontrol, hvorved Nagios ikke forsøger at afgøre, om værten/tjenesten er NED eller UÅNGELIG. Vi vil også konfigurere de aktive kontroller, hvor kontroller initieres af kontrollogikken i Nagios-dæmonen ved at bruge tjenestedefinitionen til også at overvåge de kritiske/advarselsalarmer, der rapporteres af vores klynge.
Bemærk, at dette blogindlæg kræver, at Severalnines MIB- og SNMP-agenten er konfigureret korrekt som vist i den første del af denne blogserie.
Installation af Nagios Core
Nagios Core er den gratis version af Nagios-overvågningspakken. Først og fremmest skal vi installere det og alle nødvendige pakker, efterfulgt af Nagios plugins, snmptrapd og snmptt. Bemærk, at instruktionerne i dette blogindlæg forudsætter, at alle noder kører på CentOS 7.
Installer de nødvendige pakker for at køre Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlOpret en nagios-bruger og nagcmd-gruppe for at tillade, at de eksterne kommandoer kan udføres via webgrænsefladen, tilføj nagios- og apache-brugeren til at være en del af nagcmd-gruppen:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheDownload den seneste version af Nagios Core herfra, kompilér og installer den:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstaller Nagios-webkonfigurationen:
$ make install-webconfInstaller eventuelt Nagios-eksfolieringstemaet (eller du kan holde dig til standardtemaet):
$ make install-exfoliationOpret en brugerkonto (nagiosadmin) til at logge ind på Nagios-webgrænsefladen. Husk adgangskoden, som du tildeler denne bruger:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminGenstart Apache-webserveren for at få de nye indstillinger til at træde i kraft:
$ systemctl restart httpd
$ systemctl enable httpdDownload Nagios-plugins herfra, kompilér og installer det:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installBekræft standard Nagios-konfigurationsfilerne:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosÅbn browseren og gå til https://{IPaddress}/nagios, og du skulle se en grundlæggende HTTP-godkendelse dukker op, hvor du skal angive brugernavnet som nagiosadmin med din valgte adgangskode oprettet tidligere.
Tilføjelse af ClusterControl-server til Nagios
Opret en Nagios-værtsdefinitionsfil til ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgOg tilføj følgende linjer:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Nogle forklaringer:
-
I den første sektion definerer vi vores vært med værtsnavnet og adressen på ClusterControl-serveren.
-
Servicesektionerne, hvor vi sætter vores servicedefinitioner til at blive overvåget af Nagios. De første to fortæller grundlæggende, at tjenesten skal kontrollere SNMP-outputtet for et bestemt objekt-id. Den første service handler om den kritiske alarm, derfor tilføjer vi -c0 i check_snmp kommandoen for at indikere, at det skal være en kritisk alarm i Nagios, hvis værdien går ud over 0. Mens vi for advarselsalarmerne vil indikere det med en advarsel, hvis værdien er 1 og højere.
-
Den sidste servicedefinition handler om de SNMP-fælder, som vi ville forvente kommer fra ClusterControl-serveren, hvis den kritiske alarm hævet er højere end 0. Dette afsnit vil bruge snmp_trap_template-definitionen, som vist i næste trin.
Konfigurer snmp_trap_template ved at tilføje følgende linjer i /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Inkluder ClusterControl-konfigurationsfilen i Nagios ved at tilføje følgende linje i
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgKør en konfigurationskontrol før flyvning:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgSørg for, at du får følgende linje i slutningen af outputtet:
"Things look okay - No serious problems were detected during the pre-flight check"Genstart Nagios for at indlæse ændringen:
$ systemctl restart nagiosHvis vi nu ser på Nagios-siden under Service-sektionen (menuen til venstre), vil vi se noget som dette:
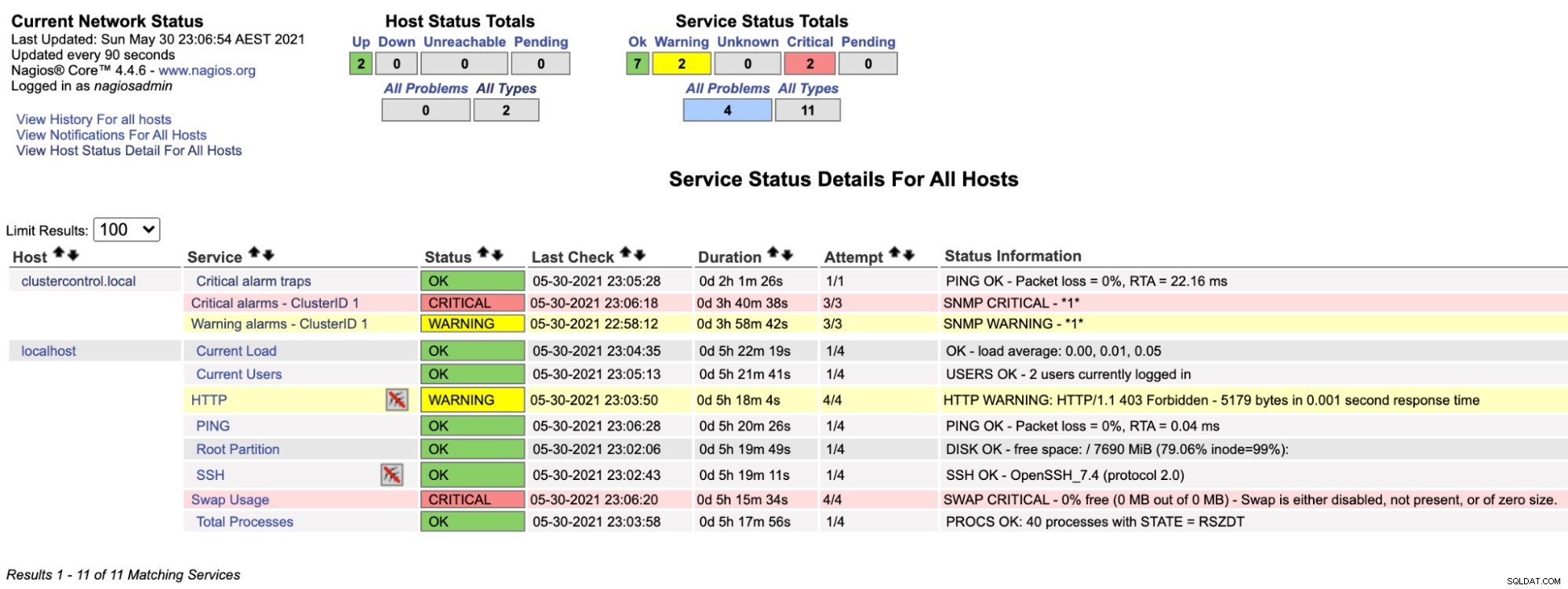
Bemærk, at rækken "Kritiske alarmer - ClusterID 1" bliver rød, hvis den kritiske alarmværdi, der rapporteres af ClusterControl, er større end 0, mens "Advarselsalarmer - ClusterID 1" er gul, hvilket indikerer, at der er udløst en advarselsalarm. Hvis der ikke sker noget interessant, vil du se, at alt er grønt for clustercontrol.local.
Konfiguration af Nagios til at modtage en fælde
Fælder sendes af eksterne enheder til Nagios-serveren, dette kaldes en passiv kontrol. Ideelt set ved vi ikke, hvornår en fælde vil blive sendt, da det afhænger af, at den afsendende enhed beslutter, at den vil sende en fælde. For eksempel med en UPS (batteri backup), så snart enheden mister strømmen, vil den sende en fælde for at sige "hej, jeg mistede strømmen". På denne måde informeres Nagios med det samme.
For at modtage SNMP-fælder skal vi konfigurere Nagios-serveren med følgende ting:
-
snmptrapd (SNMP trap-modtagerdæmon)
-
snmptt (SNMP Trap Translator, fældehåndteringsdæmonen)
Når snmptrapd'en har modtaget en fælde, sender den den til snmptt, hvor vi konfigurerer den til at opdatere Nagios-systemet, og derefter sender Nagios advarslen i henhold til kontaktgruppekonfigurationen.
Installer EPEL-lageret efterfulgt af de nødvendige pakker:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogKonfigurer SNMP trap-dæmonen på /etc/snmp/snmptrapd.conf og indstil følgende linjer:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerOvenstående betyder ganske enkelt, at fælder modtaget af snmptrapd-dæmonen vil blive videregivet til /usr/sbin/snmptthandler.
Tilføj SEVERALNINES-CLUSTERCONTROL-MIB.txt til /usr/share/snmp/mibs ved at oprette /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtOpret /etc/snmp/snmp.conf (bemærk uden "d") og tilføj vores tilpassede MIB der:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBStart snmptrapd-tjenesten:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdDernæst skal vi konfigurere følgende konfigurationslinjer inde i /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDBemærk, at vi aktiverede net_snmp_perl-modulet og har tilføjet en anden konfigurationssti, /etc/snmp/snmptt-cc.conf inde i snmptt.ini. Vi skal definere ClusterControl snmptt-begivenheder her, så de kan videregives til Nagios. Opret en ny fil på /etc/snmp/snmptt-cc.conf og tilføj følgende linjer:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCNogle forklaringer:
-
Vi har to fælder defineret - criticalAlarmNotification og criticalAlarmNotificationEnded.
-
CriticalAlarmNotification rejser simpelthen en kritisk alarm og sender den til "Kritiske alarmfælder"-tjenesten defineret i Nagios. $aA betyder at returnere trap-agentens IP-adresse. Værdien 2 er kontrolresultatværdien, som i dette tilfælde er kritisk (0=OK, 1=ADVARSEL, 2=KRITISK, 3=UKENDT).
-
The criticalAlarmNotificationEnded rejser simpelthen en OK-advarsel og sender den til "Kritiske alarmfælder"-tjenesten for at annullere forrige fælde, efter at alt er tilbage til det normale. $aA betyder at returnere trap-agentens IP-adresse. Værdien 0 er kontrolresultatværdien, som i dette tilfælde er OK. For flere detaljer om strengerstatninger, der genkendes af snmptt, se denne artikel under afsnittet "FORMAT".
-
Du kan bruge snmpttconvertmib til at generere snmptt-hændelseshåndteringsfil for en bestemt MIB.
Bemærk, at hændelseshandlerstien som standard ikke leveres af Nagios Core. Derfor er vi nødt til at kopiere denne eventhandler-mappe fra Nagios-kilden under bidragsmappen, som vist nedenfor:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersVi skal også tildele snmptt-gruppen som en del af nagcmd-gruppen, så den kan udføre nagios.cmd inde i submit_check_result-scriptet:
$ usermod -a -G nagcmd snmpttStart snmptt-tjenesten:
$ systemctl start snmptt
$ systemctl enable snmpttSNMP Manager (Nagios-serveren) er nu klar til at acceptere og behandle vores indgående SNMP-fælder.
Sender en fælde fra ClusterControl-serveren
Antag at man ønsker at sende en SNMP-fælde til SNMP-manageren, 192.168.10.11 (Nagios-server), fordi det samlede antal kritiske alarmer har nået 2 for klynge-ID 1, ville man køre følgende kommando på ClusterControl-serveren (klientsiden), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Eller i OID-format (anbefalet):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Hvor, .1.3.6.1.4.1.57397.1.1.3.1 er lig med criticalAlarmNotification trap-hændelse, og de efterfølgende OID'er er repræsentationer af henholdsvis det samlede antal aktuelle kritiske alarmer og klynge-id'et .
På Nagios-serveren bør du bemærke, at trap-tjenesten er blevet rød:
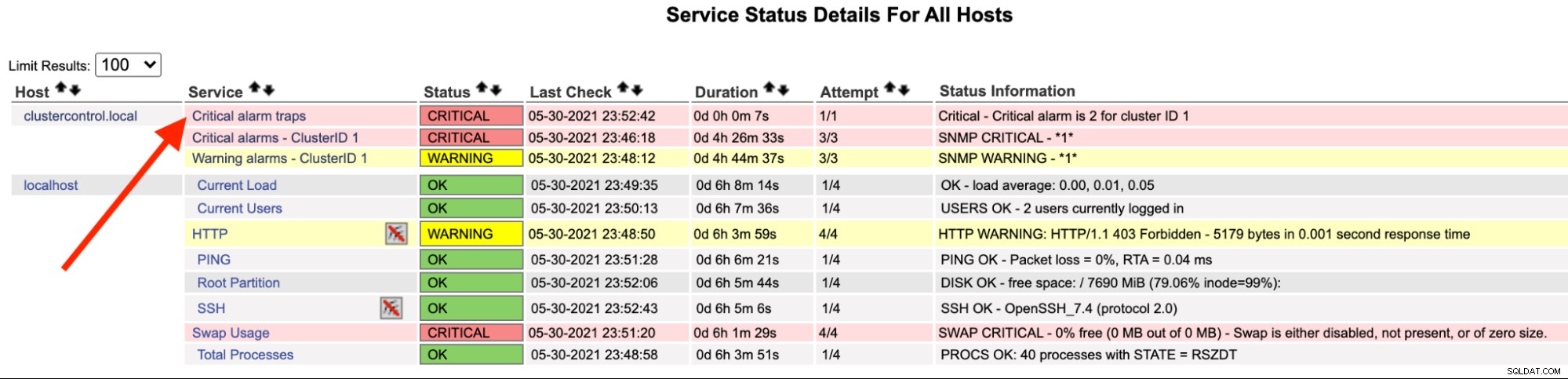
Du kan også se det i /var/log/messages på følgende linje:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Når alarmen er løst, for at sende en normal fælde, kan vi udføre følgende kommando:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Hvor, .1.3.6.1.4.1.57397.1.1.3.2 er lig med criticalAlarmNotificationEnded hændelse, og de efterfølgende OID'er er repræsentationer af det samlede antal aktuelle kritiske alarmer (skal være 0 i dette tilfælde ) og henholdsvis klynge-id'et.
På Nagios-serveren bør du bemærke, at trap-tjenesten er tilbage til grøn:
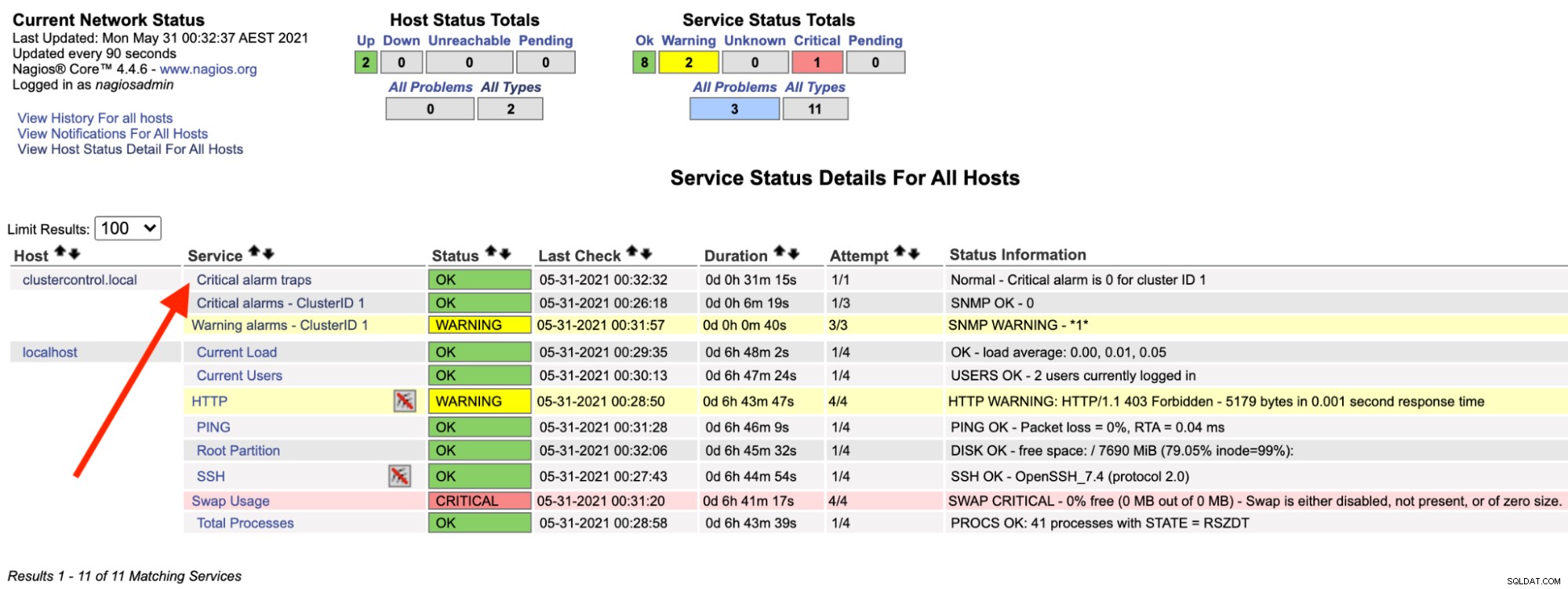
Ovenstående kan automatiseres med et simpelt bash-script:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneFor at køre scriptet i baggrunden skal du blot gøre:
$ bash alarmtrapper.bash &På dette tidspunkt burde vi være i stand til at se Nagios' "Kritiske alarmfælder"-tjeneste i aktion, hvis der er en fejl i vores klynge automatisk.
Sidste tanker
I denne blogserie har vi vist et proof-of-concept om, hvordan ClusterControl kan konfigureres til overvågning, generering/bearbejdning af fælder og alarmering ved hjælp af SNMP-protokol. Dette markerer også begyndelsen på vores rejse for at inkorporere SNMP i vores fremtidige udgivelser. Hold dig opdateret, da vi vil bringe flere opdateringer om denne spændende funktion.