I denne MongoDB Tutorial skal vi udforske de unikke funktioner i MongoDB. Vi har studeret en grundlæggende forståelse af hvad er MongoDB . Vores mål i denne artikel er at lære MongoDB-funktioner at mestre i det.
Så lad os diskutere MongoDB-funktioner i detaljer.

Lær MongoDB-funktioner | MongoDB Tutorial for begyndere
MongoDB-funktioner
Som en NoSQL-database har MongoDB så mange fantastiske funktioner. Disse fantastiske funktioner gør denne teknologi meget unik og attraktiv. Disse funktioner gør også MongoDB meget anvendelig og populær.
Lad os diskutere nogle MongoDB-funktioner, som vil hjælpe os med at arbejde med det.
- Ad hoc-forespørgsler
- Skema-mindre database
- Dokumentorienteret
- Indeksering
- Replikering
- Aggregation
- GridFS
- Sharding
- Høj ydeevne
i. Ad hoc-forespørgsler
Generelt, når vi designer et skema for en database, ved vi ikke på forhånd om de forespørgsler, vi vil udføre. Ad-hoc-forespørgsler er de forespørgsler, der ikke er kendt under strukturering af databasen.
Så MongoDB giver ad-hoc-forespørgselssupport, hvilket gør det så specielt i dette tilfælde. Ad hoc-forespørgsler opdateres i realtid, hvilket fører til en forbedring af ydeevnen.
ii. Skema-mindre database
I MongoDB indeholder en samling forskellige dokumenter. Det har intet skema, så det kan have mange felter, indhold og størrelse, der er anderledes end et andet dokument i samme samling. Dette er grunden til, at MongoDB viser fleksibilitet i håndteringen af databaserne.
iii. Dokumentorienteret
MongoDB er en dokumentorienteret database, som i sig selv er en fantastisk funktion. I relationsdatabaserne er der tabeller og rækker til arrangementer af dataene. Hver række har et specifikt nr. af kolonner og disse kan gemme en bestemt type data.
Her kommer fleksibiliteten i NoSQL, hvor der er felter i stedet for tabeller og rækker. Der er forskellige dokumenter, som kan gemme forskellige typer data. Der findes samlinger af lignende dokumenter. Hvert dokument har et unikt nøgle-id eller objekt-id, som både kan være bruger- eller systemdefineret.

MongoDB-funktioner – Dokumentorienteret
iv. Indeksering
Indeksering er meget vigtig for at forbedre ydelsen af søgeforespørgsler. Når vi løbende udfører søgninger i et dokument, bør vi indeksere de felter, der matcher vores søgekriterier.
I MongoDB kan vi indeksere ethvert felt, der er indekseret med primære og sekundære indekser. MongoDB-indeksering gør forespørgselssøgninger hurtigere og forbedrer ydeevnen.
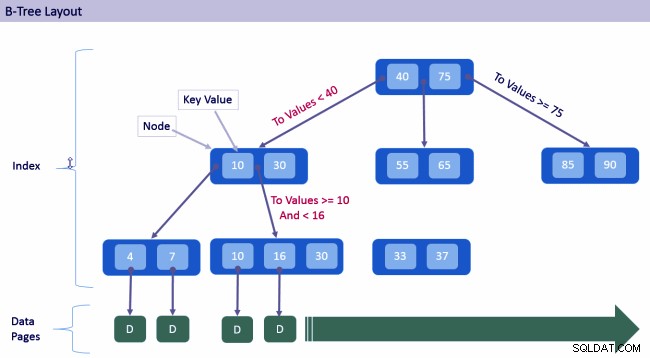
MongoDB-funktioner – Indeksering
v. Replikering
Når det kommer til redundans, er replikering det værktøj, som MongoDB bruger. Denne funktion distribuerer data til flere maskiner. Det kan have primære noder og deres et eller flere replikasæt. Grundlæggende gør replikering klar til uforudsete begivenheder.
Når den primære knude af nogle årsager er nede, bliver den sekundære knude primær for forekomsten. Dette sparer vores tid til vedligeholdelse og gør driften smidig.
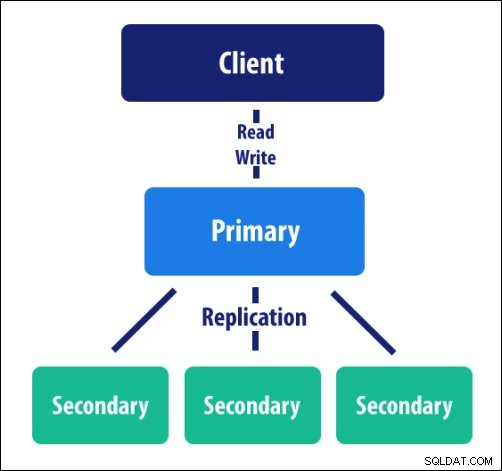
MongoDB-funktioner – Replikering
vi. Aggregation
MongoDB har en aggregeringsramme for effektiv brugervenlighed. Vi kan batchbehandle data og få et enkelt resultat, selv efter at have udført forskellige operationer på gruppedataene.
Aggregeringspipeline, kort-reducerende funktion og aggregeringsmetoder til enkelt formål er de tre måder at tilvejebringe en aggregeringsramme på. Vi vil se dem i detaljer i yderligere artikler.

MongoDB-funktioner – Aggregation
vii. GridFS
GridFS er en funktion til lagring og hentning af filer. For filer større end 16 MB er denne funktion meget nyttig. GridFS opdeler et dokument i dele kaldet chunks og gemmer dem i et separat dokument. Disse bidder har en standardstørrelse på 255 kB undtagen den sidste chunk.
Når vi forespørger GridFS for en fil, samler den alle bidder efter behov.
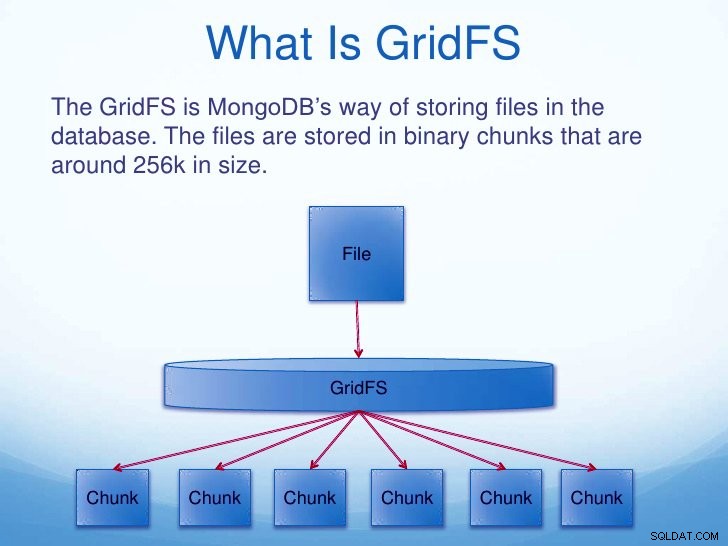
MongoDB-funktioner – GridFS
viii. Sharding
Grundlæggende kommer begrebet sharding, når vi skal håndtere større datasæt. Disse enorme data kan forårsage nogle problemer, når der kommer en forespørgsel til dem. Denne funktion hjælper med at distribuere disse problematiske data til flere MongoDB-instanser.
Samlingerne i MongoDB, som har en større størrelse, er fordelt i flere samlinger. Disse samlinger kaldes "skår". Shards implementeres af klynger.
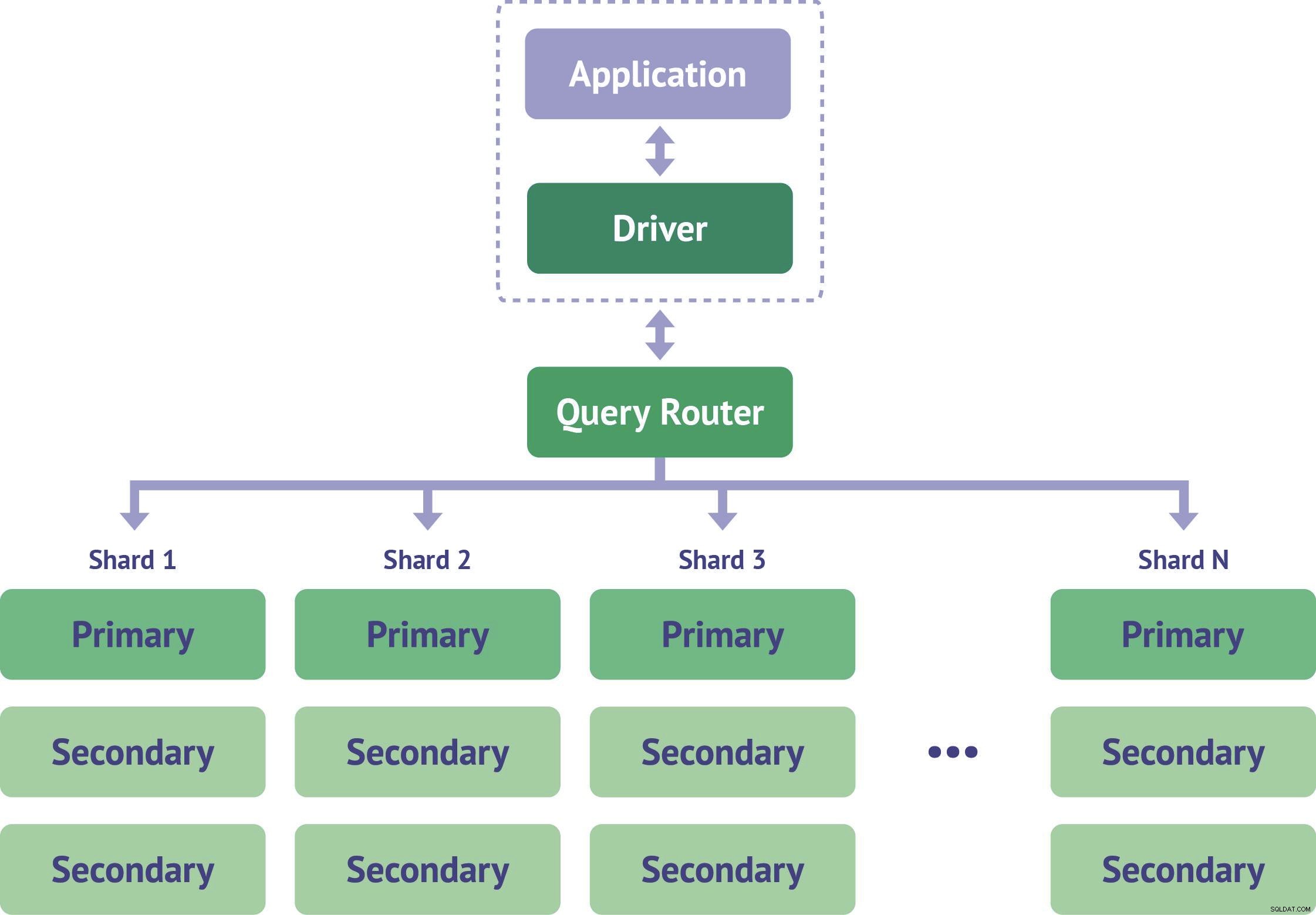
MongoDB-funktioner – Sharding
ix. Høj ydeevne
MongoDB er en open source-database med høj ydeevne. Dette viser høj tilgængelighed og skalerbarhed. Det har hurtigere forespørgselssvar på grund af indeksering og replikering. Dette gør det til et bedre valg til big data og realtidsapplikationer.
Så det hele handlede om MongoDB Features Tutorial. Håber du kan lide vores forklaring.
Konklusion
Derfor har vi diskuteret alle de vigtige MongoDB funktioner høj ydeevne, Sharding, GridFS, aggregation, replikering, indeksering, dokumentorienteret, skemafri database og ad-hoc-forespørgsler.
Også hvordan de bruges i dagens verden. Vi vil sefordele og begrænsninger ved MongoDB i yderligere MongoDB Tutorial.
Desuden, hvis du har spørgsmål, er du velkommen til at spørge i en kommentarsektion.