I denne artikel skal vi bygge en skraber til en faktisk freelance gig, hvor klienten ønsker et Python-program til at skrabe data fra Stack Overflow for at få fat i nye spørgsmål (spørgsmålstitel og URL). Skrabede data skal derefter gemmes i MongoDB. Det er værd at bemærke, at Stack Overflow har en API, som kan bruges til at få adgang til den nøjagtige samme data. Kunden ville dog have en skraber, så en skraber er, hvad han fik.
Gratis bonus: Klik her for at downloade et Python + MongoDB-projektskelet med fuld kildekode, der viser dig, hvordan du får adgang til MongoDB fra Python.
Opdateringer:
- 01/03/2014 - Refaktorerede edderkoppen. Tak, @kissgyorgy.
- 18/02/2015 - Tilføjet del 2.
- 09/06/2015 - Opdateret til den seneste version af Scrapy og PyMongo - hej!
Som altid skal du sørge for at gennemgå webstedets vilkår for brug/service og respektere robots.txt fil, før du starter et skrabearbejde. Sørg for at overholde etisk skrabningspraksis ved ikke at oversvømme webstedet med adskillige anmodninger i løbet af kort tid. Behandle ethvert websted, du skraber, som om det var dit eget .
Installation
Vi har brug for Scrapy-biblioteket (v1.0.3) sammen med PyMongo (v3.0.3) til lagring af data i MongoDB. Du skal også installere MongoDB (ikke dækket).
Scrapy
Hvis du kører OSX eller en variant af Linux, skal du installere Scrapy med pip (med din virtualenv aktiveret):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Hvis du er på Windows-maskine, skal du manuelt installere en række afhængigheder. Se venligst den officielle dokumentation for detaljerede instruktioner samt denne Youtube-video, som jeg har oprettet.
Når Scrapy er konfigureret, skal du bekræfte din installation ved at køre denne kommando i Python-skallen:
>>>>>> import scrapy
>>>
Hvis du ikke får en fejl, er du klar!
PyMongo
Installer derefter PyMongo med pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Nu kan vi begynde at bygge crawleren.
Scrapy-projekt
Lad os starte et nyt Scrapy-projekt:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Dette opretter en række filer og mapper, der inkluderer en grundlæggende kedelplade, så du hurtigt kan komme i gang:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Angiv data
items.py fil bruges til at definere lager "containere" for de data, som vi planlægger at skrabe.
StackItem() klasse arver fra Item (docs), som grundlæggende har en række foruddefinerede objekter, som Scrapy allerede har bygget til os:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Lad os tilføje nogle ting, som vi faktisk ønsker at samle. For hvert spørgsmål skal klienten have titlen og URL'en. Så opdater items.py sådan:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Opret edderkoppen
Opret en fil kaldet stack_spider.py i mappen "edderkopper". Det er her magien sker – f.eks. hvor vi fortæller Scrapy, hvordan man finder den nøjagtige data, vi leder efter. Som du kan forestille dig, er dette specifikt til hver enkelt webside, som du ønsker at skrabe.
Start med at definere en klasse, der arver fra Scrapys Spider og derefter tilføje attributter efter behov:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
De første par variabler er selvforklarende (docs):
navndefinerer navnet på edderkoppen.allowed_domainsindeholder basis-URL'erne for de tilladte domæner, som edderkoppen kan gennemgå.start-urlser en liste over URL'er, som edderkoppen kan begynde at kravle fra. Alle efterfølgende URL'er starter fra de data, som edderkoppen downloader fra URL'erne istart_urls.
XPath-vælgere
Dernæst bruger Scrapy XPath-vælgere til at udtrække data fra et websted. Med andre ord kan vi vælge visse dele af HTML-dataene baseret på en given XPath. Som det står i Scrapys dokumentation, "XPath er et sprog til at vælge noder i XML-dokumenter, som også kan bruges med HTML."
Du kan nemt finde en bestemt Xpath ved hjælp af Chromes udviklerværktøjer. Du skal blot inspicere et specifikt HTML-element, kopiere XPath, og derefter justere (efter behov):
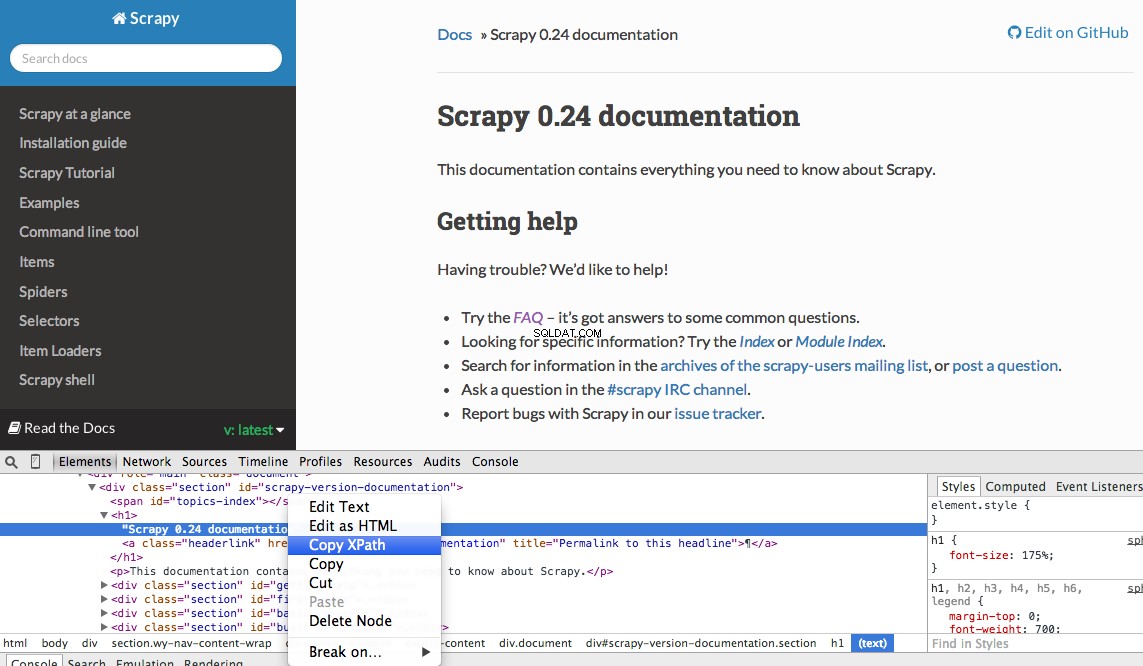
Udviklerværktøjer giver dig også mulighed for at teste XPath-vælgere i JavaScript-konsollen ved at bruge $x - dvs. $x("//img") :
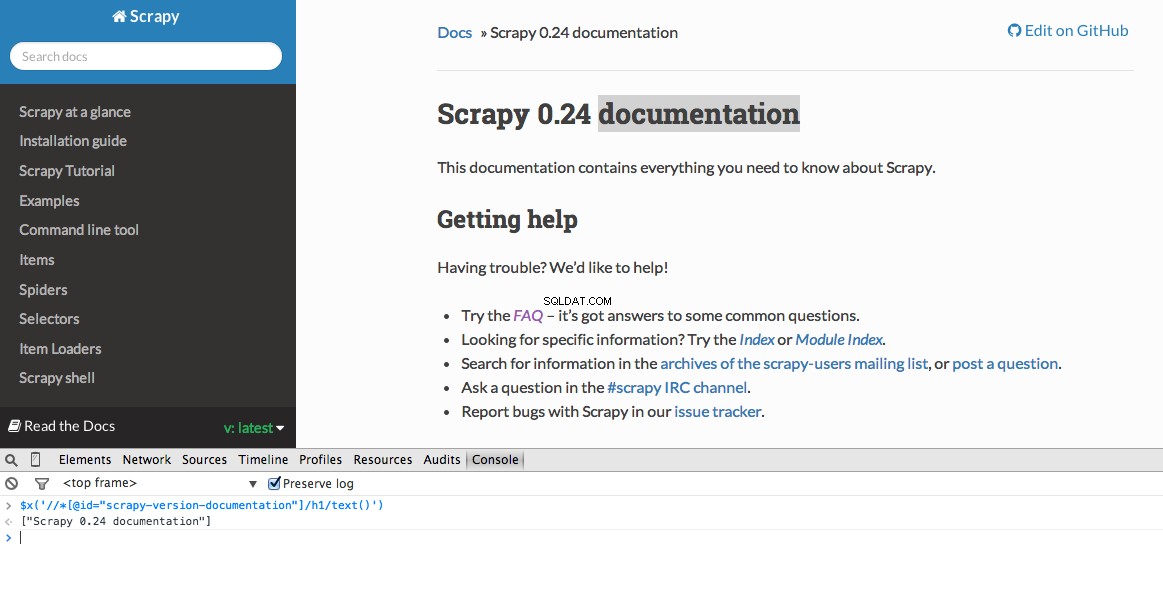
Igen fortæller vi stort set Scrapy, hvor man skal begynde at lede efter information baseret på en defineret XPath. Lad os navigere til Stack Overflow-webstedet i Chrome og finde XPath-vælgerne.
Højreklik på det første spørgsmål og vælg "Inspicer element":
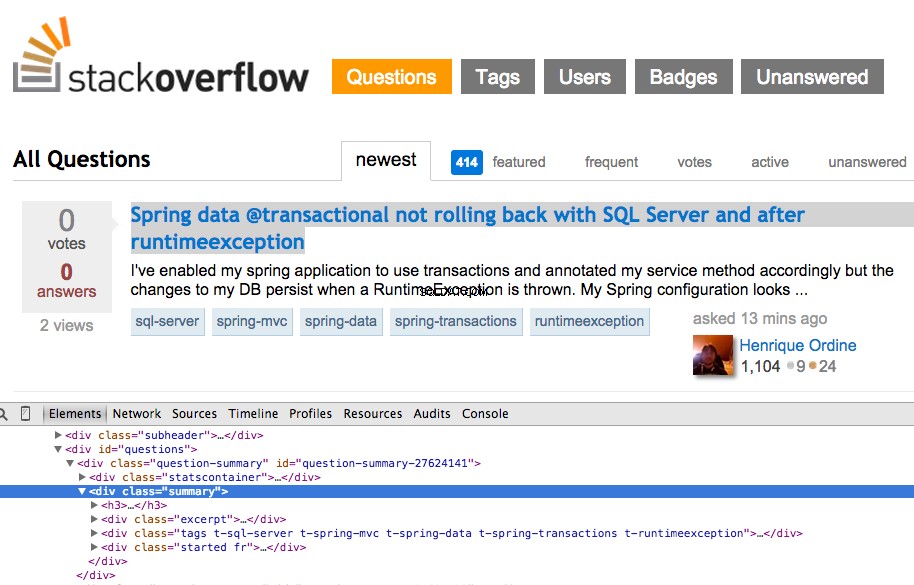
Grib nu XPath til
Som du kan se, vælger den bare den en spørgsmål. Så vi er nødt til at ændre XPath'en for at få fat i alle spørgsmål. Nogle ideer? Det er enkelt:
Bemærk, hvordan vi ikke bruger det faktiske XPath-output fra Chrome Developer Tools. I de fleste tilfælde er output kun en hjælpsom side, som generelt peger dig i den rigtige retning for at finde den fungerende XPath.
Lad os nu opdatere stack_spider.py script:
Vi mangler stadig at parse og skrabe de data, vi ønsker, som falder inden for
Sammen med Scrapy-stacksporingen bør du se 50 spørgsmålstitler og URL'er udskrevet. Du kan gengive output til en JSON-fil med denne lille kommando:
Vi har nu implementeret vores Spider baseret på vores data, som vi søger. Nu skal vi gemme de skrabet data i MongoDB.
Hver gang en vare returneres, ønsker vi at validere dataene og derefter tilføje dem til en Mongo-samling.
Det første trin er at oprette den database, som vi planlægger at bruge til at gemme alle vores crawlede data. Åbn settings.py og angiv pipelinen og tilføj databaseindstillingerne:
Vi har konfigureret vores edderkop til at crawle og parse HTML, og vi har konfigureret vores databaseindstillinger. Nu skal vi forbinde de to sammen gennem en pipeline i pipelines.py .
Opret forbindelse til databasen
Lad os først definere en metode til faktisk at oprette forbindelse til databasen:
Her opretter vi en klasse,
Behandle dataene
Dernæst skal vi definere en metode til at behandle de parsede data:
Vi etablerer en forbindelse til databasen, pakker dataene ud og gemmer dem derefter i databasen. Nu kan vi teste igen!
Kør igen følgende kommando i "stack"-mappen:
BEMÆRK :Sørg for at du har Mongo-dæmonen -
Hurra! Vi har med succes gemt vores crawlede data i databasen:
Dette er et ret simpelt eksempel på at bruge Scrapy til at gennemgå og skrabe en webside. Selve freelanceprojektet krævede, at scriptet fulgte pagineringslinkene og skrabe hver side ved hjælp af
Brug for hjælp? Start med dette script, som er næsten færdigt. Se så del 2 for at få den fulde løsning!
Gratis bonus: Klik her for at downloade et Python + MongoDB-projektskelet med fuld kildekode, der viser dig, hvordan du får adgang til MongoDB fra Python.
Du kan downloade hele kildekoden fra Github-lageret. Kommenter nedenfor med spørgsmål. Tak fordi du læste med!//*[@id="question-summary-27624141"]/div[2] , og test det derefter i JavaScript-konsollen: 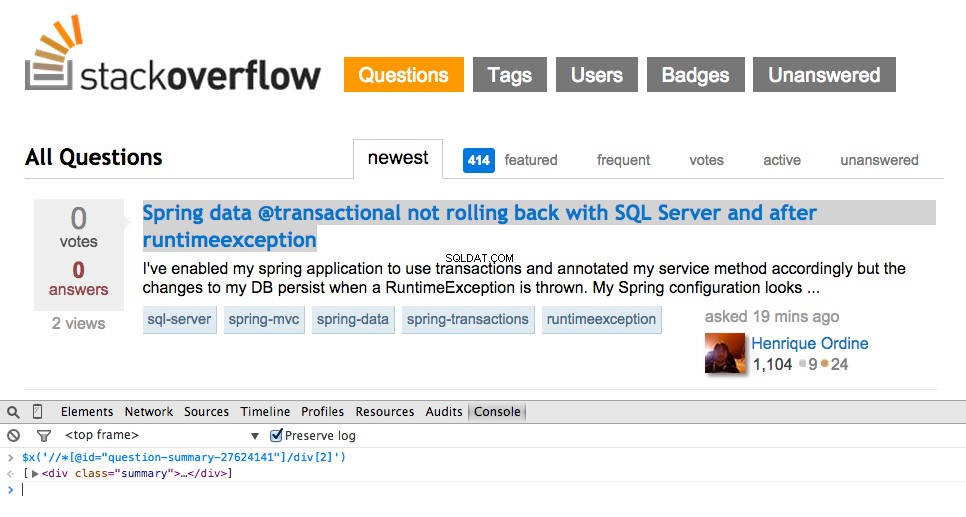
//div[@class="summary"]/h3 . Hvad betyder det? Grundlæggende siger denne XPath:Gentag alle elementer, der er børn af en resumé . Test denne XPath i JavaScript-konsollen. from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Udtræk dataene
. Igen, opdater stack_spider.py sådan:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
$ scrapy crawl stack -o items.json -t json
Gem dataene i MongoDB
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Pipeline Management
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
MongoDBpipeline() , og vi har en konstruktørfunktion til at initialisere klassen ved at definere Mongo-indstillingerne og derefter oprette forbindelse til databasen.import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Test
$ scrapy crawl stack
mongod - kører i et andet terminalvindue.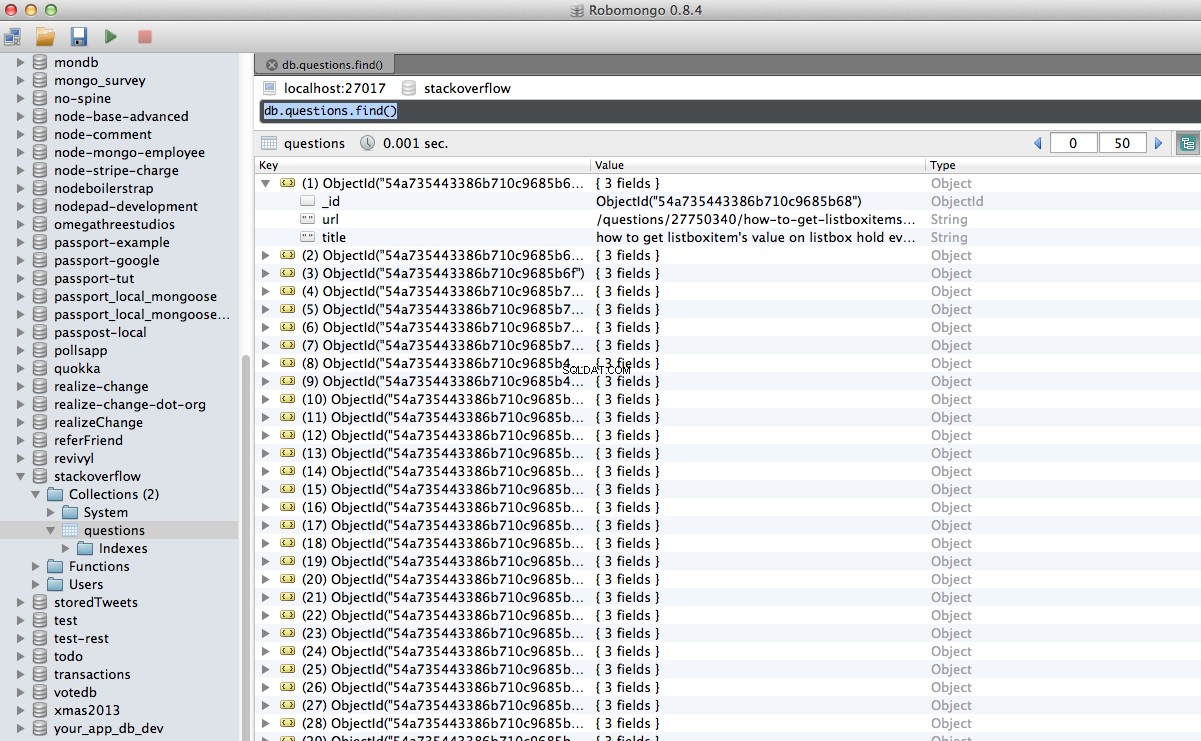
Konklusion
CrawlSpider (docs), hvilket er super nemt at implementere. Prøv at implementere dette på egen hånd, og efterlad en kommentar nedenfor med linket til Github-lageret for en hurtig kodegennemgang.