Når det kommer til at analysere hukommelsesforbruget i en Redis-instans, er der masser af gratis og open source-værktøjer på markedet sammen med en række betalte produkter. Nogle af de mest populære er Jacks (af alle brancher berømmelse), men hvis du leder efter en dybere analyse af dine hukommelsesproblemer, er du måske bedre stillet med et af de mere målrettede og mindre kendte værktøjer.
I dette indlæg har vi samlet en liste over de 6 bedste gratis værktøjer, vi fandt mest nyttige til at analysere hukommelsesbrug af vores Redis-forekomster:
- Redis Memory Analyzer (RMA)
- Redis Sampler
- RDB-værktøjer
- Redis-Audit
- Redis Toolkit
- Høst
1) Redis Memory Analyzer

Redis Memory Analyzer (RMA) er en af de mest omfattende FOSS-hukommelsesanalysatorer, der er tilgængelige for Redis. Det understøtter tre forskellige niveauer af detaljer:
- Global – Oversigt over oplysninger om hukommelsesbrug.
- Scanner – Hukommelsesbrugsoplysninger på højeste niveau af nøglerum/præfiksniveau – med andre ord bruges det korteste almindelige præfiks.
- RAM – Laveste niveau nøglerum/præfiks – med andre ord bruges det længste fælles præfiks.
Hver tilstand har sine egne anvendelser - du kan få yderligere detaljer i RMA ReadMe.

RMA – Global tilstand
I den globale tilstand giver RMA nogle statistikker på højt niveau, såsom antallet af nøgler, systemhukommelse, størrelse på beboersæt, størrelse på tasterum osv. En unik funktion er " keyspace overhead", som er den hukommelse, der bruges af Redis-systemet til at gemme keyspace-relateret information, som f.eks. pointere til listedatastrukturerne.
RMA – Scanner Mode

I scannertilstand får vi et overblik over vores tasterum. Det giver navneområderne på højt niveau (så a:b:1 og a:c:1 er slået sammen som en:*), sammen med typerne af dets elementer og procentdelen af hukommelse, der forbruges af det navneområde. Det er nyttigt at starte med disse oplysninger og derefter bruge "RAM"-adfærden kombineret med navnerumsmønsteret til at lave en detaljeret analyse.
RMA – RAM-tilstand
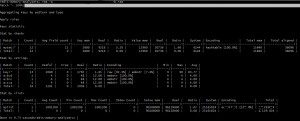
I RAM-tilstanden får vi hukommelsesforbrug på keyspace-niveau, som leveret af de fleste andre FOSS-hukommelsesanalysatorer. Så her tages a:b:1 og a:c:1 separat som a:b:* og a:c:*, og vi får detaljerede oplysninger om brugt hukommelse, faktisk datastørrelse, overhead, kodning, min og max TTL , osv. Dette hjælper med at lokalisere de største memory-hoggers i vores system.
Desværre er dette værktøj ikke altid opdateret (den sidste commit på GitHub er mere end et år siden). Alligevel er dette en af de bedste, vi fandt til detaljeret analyse.
RMA installation og brug:
RMA kræver, at Python og PIP er installeret på systemet (begge er tilgængelige for alle større OS'er). Når de er installeret, kan du udføre en enkelt kommando for at installere RDB-værktøjerne – `pip install rma`
Det er ret nemt at bruge fra kommandolinjen. Syntaksen er `rma [-s HOST] [-p PORT] [-a PASSWORD] [-d DB] [-m mønster-til-match] [-l antal-nøgler-til-scanning] [-b ADFÆRD] [-t kommasepareret-liste-over-datatyper-til-scanning]`
RMA-fordele:
- Fungerer i realtid.
- Bruger scanningskommandoen til at gå gennem databasen, og derfor er ydeevnepåvirkningen begrænset, og analysen er meget nøjagtig.
- Veldokumenteret – det er nemt at finde brugseksempler.
- Understøtter robuste tilpasnings- og filtreringsmuligheder, inklusive kun at analysere specifikke datatyper, eller kun tage i betragtning nøgler, der matcher et bestemt mønster).
- Kan give detaljer på forskellige niveauer – navnerum, nøgler eller globale værdier.
- Unik blandt alle de værktøjer, vi reviderede, ved at den viser datastrukturen overhead (det vil sige, hvor meget hukommelse der bruges til at gemme intern Redis-information, såsom pointere for en listedatatype ).
RMA Ulemper:
- Understøtter ikke probabilistisk stikprøve. Lineær scanning af databasen kan være meget langsom for store databaser; der er mulighed for at stoppe scanningen, når et bestemt antal nøgler returneres for at forbedre ydeevnen.
- Der er mange detaljer i outputtet; selvom det er nyttigt for eksperter, tjener det måske kun til at forvirre begyndere.
2) Redis Sampler

Redis Sampler er et meget kraftfuldt værktøj, der kan give dyb indsigt i hukommelsesbrugen af en Redis-instans. Det vedligeholdes af antirez, udvikleren bag Redis, og den dybe viden om Redis viser sig i dette værktøj. Værktøjet opdateres ikke særlig ofte – men der er alligevel ikke mange problemer rapporteret.

Redis Sampler laver en probabilistisk scanning af databasen og rapporterer følgende information:
- Den procentvise fordeling af nøgler mellem forskellige datatyper – baseret på antallet af nøgler i stedet for størrelsen af objekter.
- De største nøgler af typen streng, baseret på strlen, og den procentdel af hukommelse, de bruger.
- For alle andre datatyper beregnes de største nøgler og vises som to separate lister:en baseret på objektets størrelse og en anden baseret på antallet af elementer i objekt.
- For hver datatype viser den også en "Power of 2-fordeling". Dette er virkelig nyttigt til at forstå størrelsesfordelingen inden for en datatype. Outputtet beskriver grundlæggende, hvor stor en procentdel af nøgler af en given type, der er af størrelse i området> 2^x og <=2^x+1.
Installation og brug af Redis Sampler:
Dette er et enkelt Ruby-script. Det kræver, at Ruby allerede er installeret. Du skal også have 'rubygems' og 'redis' ædelstene for at blive installeret. Brugen er ret ligetil - fra kommandolinjen, udfør `./redis-sampler.rb `
Fordele ved Redis Sampler:
- Meget enkel at bruge – ingen muligheder for at undersøge og forstå.
- Oputtet er let at forstå, selv for nybegyndere, men har nok information til meget detaljerede analyser af en Redis-instans af eksperter. Afsnittene er tydeligt afgrænsede og nemme at filtrere fra.
- Virker på alle Redis-versioner.
- Bruger ikke nogen privilegerede kommandoer som DEBUG OBJECT, så det kan bruges på ethvert system, inklusive Amazons ElastiCache.
- Den bruger datatypespecifikke længdekommandoer til at identificere datastørrelsen, så det rapporterede forbrug påvirkes ikke af serialisering.
- Fungerer på live-data. Selvom anbefalingen er at køre på loopback-grænseflade, understøtter den sampling af fjernsystemer.
Redis Sampler Ulemper:
- Hvis prøvestørrelsen er indstillet højere end databasekardinalitet, vil den stadig bruge TILFÆLDIGT TØSTER frem for SCAN.
- Ingen bundle eller Docker-billede tilgængelig. Du skal manuelt installere afhængigheder (selvom på den lyse side er der kun 2 afhængigheder).
- Rapporterer datastørrelsen, som ikke nøjagtigt matcher den plads, der er optaget på RAM på grund af datastrukturens lagringsomkostninger.
- Fungerer ikke direkte, hvis din Redis-instans kræver godkendelse. Du skal ændre scriptet for at tage et kodeord; i enkleste form kan du søge efter:
redis =Redis.new(:host => ARGV[0], :port => ARGV[1].to_i, :db => ARGV[2].to_i)
og ændre det til:
redis =Redis.new(:host => ARGV[0], :port => ARGV[1].to_i, :db => ARGV[2].to_i, :adgangskode => "tilføj-din-adgangskode-her")
3) RDB-værktøjer

RDB-værktøjer er en meget nyttig pakke af værktøjer til enhver seriøs Redis-administrator. Der er et værktøj til næsten alle use-cases, vi kunne tænke på, men i dette indlæg vil vi udelukkende koncentrere os om hukommelsesanalyseværktøjet.
Selvom det ikke er nær så omfattende som RMA eller Redis Sampler, giver RDB Tools 3 vigtige oplysninger:

1) Alle nøgler, hvor værdien har (serialiseret) størrelse større end B bytes [B specificeret af bruger].

2) De største N nøgler [N angivet af brugeren].

3) Størrelse på en bestemt nøgle:denne læses live fra databasen.
Denne suite har mange aktive bidragydere på GitHub og opdateres ret ofte. RDB Tools er også veldokumenteret på internettet. Vedligeholderen sripathikrishnan er velkendt i Redis-samfundet for de mange værktøjer, han har leveret gennem årene.
RDB-værktøjer Installation og brug:
RDB-værktøjer kræver, at Python og PIP er installeret på systemet (begge er tilgængelige for alle større OS'er). Når de er installeret, kan du udføre en enkelt kommando for at installere RDB-værktøjerne - `pip install rdbtools python-lz`
Brugen er ret ligetil:
- For at få 200 største nøgler:rdb -c memory /var/redis/6379/dump.rdb –largest 200 -f memory.csv
- For at få alle nøgler større end 128 bytes:rdb -c memory /var/redis/6379/dump.rdb –bytes 128 -f memory.csv
- For at få størrelsen på en nøgle:redis-memory-for-key -s localhost -p 6379 -a mypassword person:1
RDB Tools Fordele:
- Udlæser en CSV-fil, som kan bruges med andre FOSS-værktøjer til nemt at skabe datavisualiseringer, og som også kan importeres til RDBMS-er for at køre analyser.
- Meget veldokumenteret.
- Understøtter tilpasnings- og filtreringsmuligheder, så du kan få mere nyttige rapporter.
RDB Tools Ulemper:
- Deres analyse virker ikke på live data; du skal tage en RDB-dump. Som følge heraf er rapporteret hukommelsesforbrug den serialiserede hukommelse, som ikke er nøjagtig det samme som hukommelse optaget på RAM.
- Den har ikke nogen indbygget understøttelse af gruppering, så den kan ikke finde de største navnerum.
4) Redis-Audit

Redis-Audit er et probabilistisk værktøj, der er nyttigt til at få et hurtigt overblik over dit hukommelsesforbrug. Den udsender nyttige oplysninger om nøglegrupper, såsom samlet hukommelsesforbrug, maksimal TTL i gruppen, gennemsnitlig sidste adgangstid, procentdelen af nøgler i gruppen, der udløber, osv. Dette er det perfekte værktøj, hvis du har brug for at finde mest muligt hukommelse- hogging nøglegruppe i din applikation.

Redis-Audit installation og brug:
Du skal have Ruby og Bundle allerede installeret. Når det er installeret, kan du enten klone Redis-Audit-depotet til en mappe eller downloade zip-filen og udpakke den til en mappe. Kør `bundle install` fra den mappe for at fuldføre installationen.
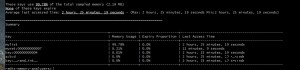
Brugen er ret ligetil:fra kommandolinjen, kør ` redis-audit.rb værtsnavn [port] [adgangskode] [dbnum] [sample_size]`

Redis-Audit Pros:
- Giver dig mulighed for at definere dit eget regex til gruppering af nøglerum/præfiks.
- Virker på alle Redis-versioner.
- Hvis prøvestørrelsen er større end det faktiske antal nøgler, gennemgår den alle nøgler. På bagsiden bruger denne operation tasterne * i stedet for scanning – muligvis blokerer andre operationer.
Redis-Audit Ulemper:
- Bruger kommandoen DEBUG OBJECT (ikke tilgængelig i ElastiCache); som et resultat, rapporterer den om serialiseret størrelse – som adskiller sig fra den faktiske størrelse optaget på RAM.
- Oputtet er ikke særlig nemt at parse hurtigt, da det ikke er opstillet i tabelform.
5) Redis Toolkit

Redis Toolkit er en bare-bones-overvågningsløsning, der kan bruges til at analysere to nøglemålinger:hitrate og hukommelsesforbrug. Projektet opdateres med jævne mellemrum for fejlrettelser, men har ikke fællesskabsstøtten til nogle af de mere berømte værktøjer.
Installation og brug af Redis Toolkit:

Du skal have Docker installeret på dit system. Derefter skal du klone GitHub-lageret (eller downloade som zip og udpakke til en mappe). Fra den mappe er installationen lige så enkel som at udføre `./redis-toolkit install`.
Brugen er udelukkende via kommandolinje, gennem en række simple kommandoer.
- Sådan begynder du at overvåge hit-rate:./redis-toolkit monitor
- Sådan rapporterer du hitrate:./redis-toolkit rapport -navn NAVN -type hitrate
- Sådan stopper du med at overvåge hit-rate:./redis-toolkit stop
- Sådan oprettes dumpfilen på det lokale system:./redis-toolkit dump
- Sådan rapporterer du hukommelsesbrug:./redis-toolkit report -type memory -name NAME
Redis Toolkit Pros:
- Let-at-forståeligt interface, der giver dig de præcise oplysninger, du har brug for.
- Kan gruppere præfikser til det niveau, der er nyttigt for dig (så hvis du vælger a:b:1 og a:c:1, tælles de som a:* eller separat) .
- Virker på alle Redis-versioner; kræver ikke adgang til privilegerede kommandoer som DEBUG OBJECT.
- Veldokumenteret.
Redis Toolkit Ulemper:
- Hukommelsesanalysen er ikke live; da det virker på den serialiserede dump, vil det rapporterede hukommelsesforbrug ikke være lig med det faktiske RAM-forbrug.
- Der skal oprettes et dump på den computer, hvor Redis Toolkit kører. Hvis du har en ekstern Redis-instans, kan dette tage et stykke tid.
- Overvågning af hitfrekvensen bruger MONITOR-kommandoen til at fange alle kommandoer, der er kørt på serveren. Dette kan forringe ydeevnen og er en mulig sikkerhedsrisiko i produktionen.
- Hitfrekvensen beregnes som |GET| / (|GET| + |SET|). Så hvis en værdi ændres ofte, vil dens hitrate være lavere, selvom der aldrig har været en faktisk cache-miss.
6) Høst

Dette er et probabilistisk stikprøveværktøj, der kan bruges til at identificere de 10 største navnerum/præfikser i form af antallet af nøgler. Det er et af de nyeste værktøjer og har ikke set meget trækkraft på GitHub. Men hvis du er en Redis-novice, der ønsker at identificere, hvilken slags applikationsdata der tilstopper din instans, kan du ikke få noget enklere end Harvest.
Høstinstallation og -brug:
Dette kan downloades som et Docker-billede. Når billedet er klar, kan du køre værktøjet ved at bruge kommandoen 'docker run –link redis:redis -it –rm 31z4/harvest redis://redis-URL' fra CLI.
Fordele ved høst:
- Fungerer på live-data.
- Bruger kommandoen 'hukommelsesbrug' til at få oplysninger om størrelse; derfor:
- Giver nøjagtige størrelsesoplysninger (i stedet for serialiseret størrelse).
- Kræver ikke adgang til kommandoen DEBUG OBJECT.
- Dine navnerum behøver ikke være:(kolon) afgrænset. Harvest identificerer almindelige præfikser i stedet for at være afhængige af regex-baseret navnerumsgenkendelse.
Høst Ulemper:
- Det er en one-trick pony – svært at tilpasse den til enhver anden brugssituation.
- Værktøjet virker kun med Redis v4.0 og nyere.
- Minimal dokumentation.
Begrænsninger af gratis værktøj
Selvom vi fandt disse værktøjer meget nyttige til at fejlsøge vores Redis-forekomsters hukommelsesproblemer, bør du være opmærksom på begrænsningerne ved disse gratis værktøjer.
De betalte værktøjer har næsten altid en form for datavisualisering, som ikke er tilgængelig direkte med nogen af de værktøjer, vi reviderede. Det bedste, du får, er et CSV-output, som du kan bruge andre FOSS-værktøjer til at visualisere, og mange værktøjer har ikke engang den mulighed. Det giver en stejl indlæringskurve, især for nybegyndere Redis-brugere. Hvis du sandsynligvis vil lave hukommelsesanalyse ofte, kan det være umagen værd at se på betalte værktøjer, der giver god visualisering.
En anden begrænsning er muligheden for at gemme historisk information. I overensstemmelse med den generelle *nix-filosofi om at lave små værktøjer, der kun gør én ting, men gør det godt, begiver værktøjerne sig sjældent ind i overvågningsrummet. Ikke engang en graf over hukommelsesforbrug over tid, og mange kan ikke engang analysere live-data.
Bundlinjen
Et enkelt værktøj vil sandsynligvis ikke være tilstrækkeligt til alle dine behov, men de er ret gode våben at have i dit arsenal, parret med overvågningsmulighederne leveret af DBaaS-løsninger som ScaleGrids hosting for Redis™*! For at lære mere om de fantastiske værktøjer, der er tilgængelige med vores fuldt administrerede hostingtjenester til Redis™, kan du se vores ScaleGrid-funktioner til Redis™ efter plan side.
