Dette blogindlæg vil præsentere et simpelt "hej verden" slags eksempel på, hvordan man får data, der er gemt i S3, indekseret og serveret af en Apache Solr-tjeneste, der hostes i en Data Discovery and Exploration-klynge i CDP. For de nysgerrige:DDE er en forud-templeteret Solr-optimeret klyngeimplementeringsmulighed i CDP og for nylig udgivet i tech preview . Vi vil kun dække AWS- og S3-miljøer i denne blog. Azure- og ADLS-implementeringsmuligheder er også tilgængelige i teknisk forhåndsvisning, men vil blive dækket i et fremtidigt blogindlæg.
Vi vil afbilde det enkleste scenarie for at gøre det nemt at komme i gang. Der er selvfølgelig mere avancerede datapipeline-opsætninger og mere rige skemaer mulige, men dette er et godt udgangspunkt for en nybegynder.
Forudsætninger:
- Du har allerede en CDP-konto og har superbruger- eller administratorrettigheder til det miljø, hvor du planlægger at oprette denne tjeneste.
Hvis du ikke har en CDP AWS-konto, bedes du kontakte din foretrukne Cloudera-repræsentant eller tilmelde dig en CDP-prøveversion her. - Du har miljøer og identiteter kortlagt og konfigureret. Mere eksplicit er alt hvad du behøver at have kortlægningen af CDP-brugeren til en AWS-rolle, som giver adgang til den specifikke s3-bucket du vil læse fra (og skrive til).
- Du har allerede indstillet en adgangskode til arbejdsbelastning (FreeIPA).
- Du har en DDE-klynge kørende. Du kan også finde mere information om brug af skabeloner i CDP Data Hub her.
- Du har CLI-adgang til den klynge.
- SSH-porten er åben på AWS som for din IP-adresse. Du kan få den offentlige IP-adresse for en af Solr-knuderne i Datahub-klyngedetaljerne. Lær her, hvordan du SSH til en AWS-klynge.
- Du har en logfil i en S3-bøtte, der er tilgængelig for din bruger (
/sample.log i dette eksempel). Hvis du ikke har en, er her et link til den, vi brugte.
Arbejdsgang
De følgende afsnit vil lede dig gennem trinene for at få data indekseret ved hjælp af Crunch Indexer Tool, der kommer ud af æsken med DDE.

Opret en samling til at holde dit indeks
I HUE er der en indeksdesigner; så længe DDE er i Tech Preview, vil den dog være under rekonstruktion og anbefales ikke på nuværende tidspunkt. Men prøv det, når DDE går GA, og lad os vide, hvad du synes.
Indtil videre kan du oprette dit Solr-skema og konfigurationer ved hjælp af CLI-værktøjet 'solrctl'. Opret en konfiguration kaldet 'my-own-logs-config' og en samling kaldet 'my-own-logs'. Dette kræver, at du har CLI-adgang.
1. SSH til en af arbejderknuderne i din klynge.
2. kinit som bruger med tilladelse til at oprette samlingskonfigurationen:
kinit
3. Sørg for, at SOLR_ZK_ENSEMBLE miljøvariablen er sat i /etc/solr/conf/solr-env.sh. Gem dens værdi, da dette vil være nødvendigt i yderligere trin.
Tryk på Enter, og skriv din arbejdsbyrde (FreeIPA) adgangskode.
For eksempel:
cat /etc/solr/conf/solr-env.sh
Forventet output:
eksporter SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Dette indstilles automatisk på værter med en Solr Server- eller Gateway-rolle i Cloudera Manager.
4. For at generere konfigurationsfiler til samlingen skal du køre følgende kommando:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate er en af standardskabelonerne, der leveres med Solr i CDP, men da den er en skabelon, er den uforanderlig. I forbindelse med denne arbejdsgang skal du kopiere den og dermed lave en ny, der kan ændres (det er, hvad indstillingen uforanderlig=falsk gør). Dette giver dig en fleksibel, skemafri konfiguration. At skabe et veldesignet skema er noget, der er værd at investere designtid i, men det er ikke nødvendigt til udforskende brug. Af denne grund er det uden for rammerne af dette blogindlæg. I et faktisk produktionsmiljø anbefaler vi dog kraftigt brugen af veldesignede skemaer – og vi er glade for at yde eksperthjælp, hvis det er nødvendigt!
5. Opret en ny samling ved hjælp af følgende kommando:
solrctl-samling --opret mine-egne-logfiler -s 1 -c mine-egne-logfiler-config
Dette opretter "my-own-logs"-samlingen baseret på "my-own-logs-config"-samlingskonfigurationen på ét shard.
6. For at validere, at samlingen er blevet oprettet, kan du navigere til Solr Admin UI. Samlingen for "mine-egne-logfiler" vil være tilgængelig via rullemenuen i venstre navigation.

Indeksér dine data
Her beskriver vi ved hjælp af et simpelt eksempel, hvordan man konfigurerer og kører det indbyggede Crunch Indexer Tool til hurtigt at indeksere data i S3 og tjene gennem Solr i DDE. Da sikring af klyngen kan bruge CM Auto TLS, Knox, Kerberos og Ranger, kan "Spark submit" være afhængig af aspekter, der ikke er dækket af dette indlæg.
Indeksering af data fra S3 er præcis det samme som indeksering fra HDFS.
Udfør disse trin på Yarn worker node (omtalt som "Yarnworker" på Management Console webUI).
1. SSH til den dedikerede Yarn-arbejderknude i DDE-klyngen som en Solr-administratorbruger.
For at finde ud af IP-adressen på Yarn-arbejderknuden skal du klikke på Hardware fanen på siden med klyngedetaljer, og rul derefter til "Yarnworker"-knuden.

2. Gå til din ressourcemappe (eller opret en, hvis du ikke allerede har den:
cd
Brug administratorbrugerens hjemmemappe som ressourcemappe (
3. Tilpas din bruger:
kinit
Tryk på Enter, og skriv din arbejdsbyrde (FreeIPA) adgangskode.
4. Kør følgende curl-kommando, og erstatte
curl --negotiate -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --insecure> tokenFile.txt
5. Opret en Morphline-konfigurationsfil til Crunch Indexer Tool, read-log-morphline.conf i dette eksempel. Erstat
SOLR_LOCATOR :{ # Navn på solr-samlingens samling :my-own-logs #zk ensemble zkHost :
6. Opret en log4j.properties-fil til logkonfiguration:
log4j.rootLogger=INFO, A1# A1 er indstillet til at være en ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 bruger PatternLayout.log4j.appender.A1.layout=org.apache.log4j .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Tjek, om den fil, du vil læse, findes på S3 (hvis du ikke har en, her er et link til den, vi brugte til dette simple eksempel:
aws s3 ls s3://
8. Kør kommandoen spark-submit:
Erstat pladsholdere i og med de værdier, du har indstillet.
eksporter myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunchexport myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunchexport myDriverJar=$(find $myDriverJarDir maxdepth 1 -navn 'search-crunch-*.jar' ! -navn '*-job.jar' ! -navn '*-sources.jar')export myDependencyJarFiles=$(find $myDependencyJarDir -navn '*.jar' | sort | tr '\n' ',' | head -c -1)export myDependencyJarPaths=$(find $myDependencyJarDir -navn '*.jar' | sort | tr '\n' ':' | head -c -1) eksport myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "export myResourcesDir="
Hvis du støder på en lignende besked, kan du se bort fra den:
WARN metadata.Hive:Kunne ikke registrere alle functions.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportException
9. Gå til Resource Manager for at overvåge udførelsen af kommandoen.

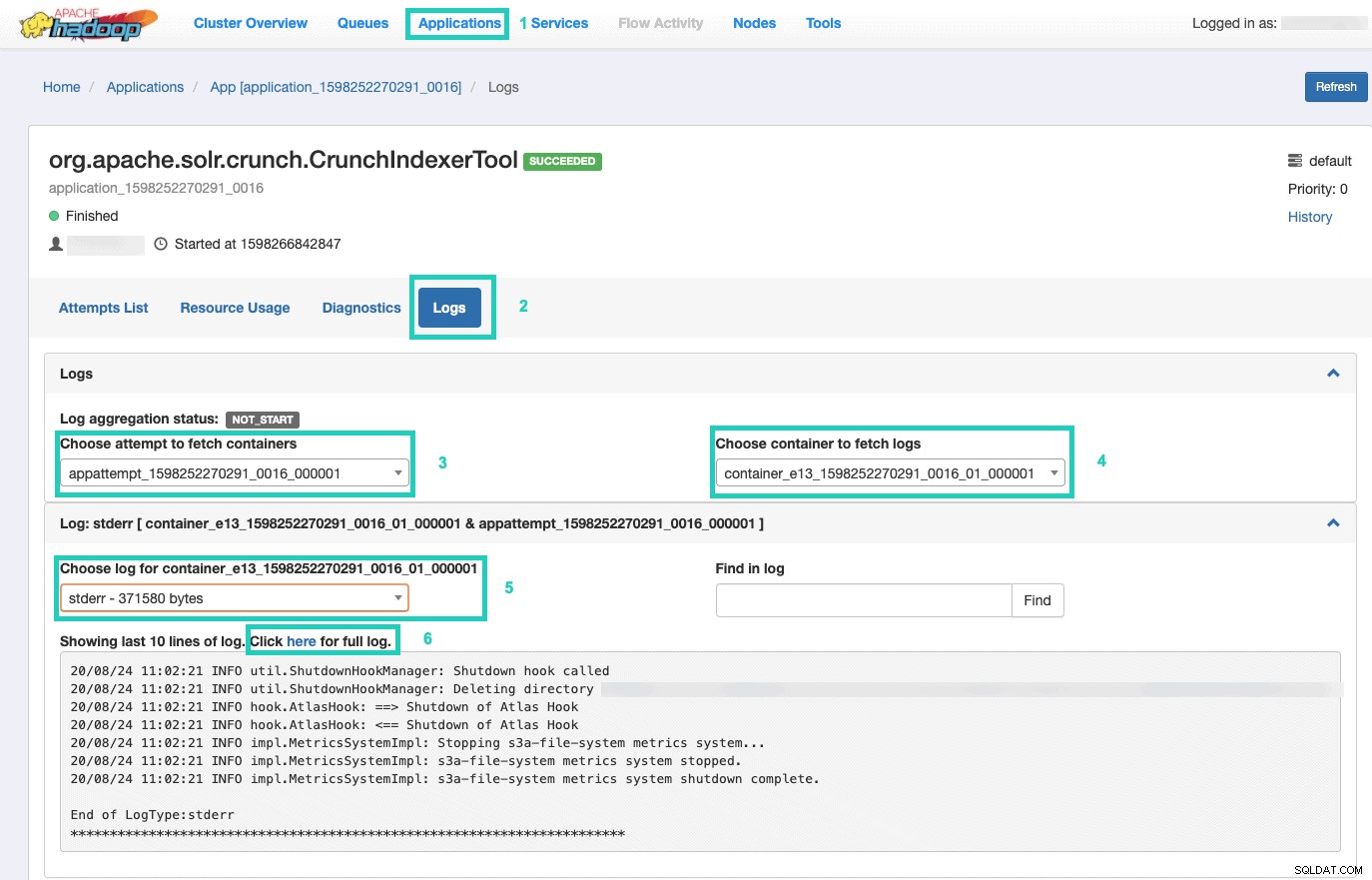
Når du er der, skal du vælge Applikationer fanen > Klik på Applikations-id af det programforsøg, du vil overvåge > Vælg Logfiler> Vælg forsøg på at hente containere> Vælg container for at hente logfiler> Vælg log for container> Vælg stderr log> Klik på Klik her for fuld log .
Vis dit indeks
Du har mange muligheder for at vise de søgbare indekserede data til slutbrugere. Du kan bygge din egen rige applikation baseret på Solrs rige API'er (meget almindelig). Du kan forbinde dit foretrukne tredjepartsværktøj, såsom Qlik, Tableau osv. over deres certificerede Solr-forbindelser. Du kan bruge Hues enkle solr-dashboard til at bygge prototypeapplikationer.
For at gøre det sidste:
1. Gå til Hue.

2. I dashboardvisningen skal du navigere til den valgte indeksfil (f.eks. den, du lige har oprettet).
3. Begynd at trække og slippe forskellige dashboard-elementer, og vælg felterne fra indekset for at udfylde dataene for det visuelle billede.
En hurtig instruktionsvideo til dashboard fra fortiden kan findes her til inspiration.
Vi vil efterlade et dybere dyk til et fremtidigt blogindlæg.
Oversigt
Vi håber, du har lært meget af dette blogindlæg om, hvordan du får data i S3 indekseret af Solr i en DDE ved hjælp af Crunch Indexer Tool. Selvfølgelig er der mange andre måder (Spark i Data Engineering-oplevelsen, Nifi i Data Flow-oplevelsen, Kafka i Stream Management-oplevelsen og så videre), men dem vil blive dækket i fremtidige blogindlæg. Vi håber, at du har stor succes med din fortsatte rejse med at bygge kraftfulde indsigtsapplikationer, der involverer tekst og andre ustrukturerede data. Hvis du beslutter dig for at prøve DDE i CDP, så lad os venligst vide, hvordan det hele gik!