ANY aggregat er ikke noget vi kan skrive direkte i Transact SQL. Det er kun en intern funktion, der bruges af forespørgselsoptimerings- og udførelsesmotoren.
Jeg er personligt ret glad for ANY samlet, så det var lidt skuffende at erfare, at det er brudt på en ganske grundlæggende måde. Den særlige smag af 'brudt', jeg henviser til her, er sorten med forkerte resultater.
I dette indlæg tager jeg et kig på to bestemte steder, hvor ANY aggregering dukker ofte op, viser det forkerte resultatproblem og foreslår løsninger, hvor det er nødvendigt.
Til baggrund om ANY samlet, se venligst mit tidligere indlæg Udokumenterede forespørgselsplaner:ANY-aggregatet.
1. En række pr. gruppeforespørgsler
Dette må være et af de mest almindelige daglige forespørgselskrav med en meget velkendt løsning. Du skriver sandsynligvis denne slags forespørgsler hver dag, automatisk efter mønsteret, uden egentlig at tænke over det.
Ideen er at nummerere inputsættet af rækker ved hjælp af ROW_NUMBER vinduesfunktion, opdelt efter grupperingskolonnen eller -kolonnerne. Det er pakket ind i et fælles tabeludtryk eller afledt tabel , og filtreret ned til rækker, hvor det beregnede rækkenummer er lig med én. Siden ROW_NUMBER genstarter ved én for hver gruppe, hvilket giver os den nødvendige række pr. gruppe.
Der er ikke noget problem med det generelle mønster. Typen af en række pr. gruppeforespørgsel, der er underlagt ANY det samlede problem er det, hvor vi er ligeglade med, hvilken bestemt række der er valgt fra hver gruppe.
I så fald er det ikke klart, hvilken kolonne der skal bruges i den obligatoriske ORDER BY klausul i ROW_NUMBER vinduesfunktion. Når alt kommer til alt, er vi udtrykkeligt ligeglade hvilken række der er valgt. En almindelig fremgangsmåde er at genbruge PARTITION BY kolonne(r) i ORDER BY klausul. Det er her, problemet kan opstå.
Eksempel
Lad os se på et eksempel ved hjælp af et legetøjsdatasæt:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Kravet er at returnere en komplet række af data fra hver gruppe, hvor gruppemedlemskab er defineret af værdien i kolonne c1 .

Følger ROW_NUMBER mønster, kan vi skrive en forespørgsel som følgende (læg mærke til ORDER BY klausul i ROW_NUMBER vinduesfunktionen matcher PARTITION BY klausul):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Som præsenteret udføres denne forespørgsel med korrekte resultater. Resultaterne er teknisk ikke-deterministiske da SQL Server gyldigt kunne returnere en af rækkerne i hver gruppe. Ikke desto mindre, hvis du selv kører denne forespørgsel, vil du sandsynligvis se det samme resultat, som jeg gør:
Udførelsesplanen afhænger af den anvendte version af SQL Server og afhænger ikke af databasekompatibilitetsniveauet.
På SQL Server 2014 og tidligere er planen:

For SQL Server 2016 eller nyere vil du se:

Begge planer er sikre, men af forskellige årsager. Distinct Sort planen indeholder en ANY samlet, men Distinct Sort operatørimplementering viser ikke fejlen.
Den mere komplekse SQL Server 2016+ plan bruger ikke ANY samlet overhovedet. Sorter placerer rækkerne i den rækkefølge, der er nødvendige for rækkenummereringsoperationen. Segmentet operatør sætter et flag i starten af hver ny gruppe. Sekvensprojektet beregner rækkenummeret. Til sidst, Filtret operator videregiver kun de rækker, der har et beregnet rækkenummer på én.
Fejlen
For at få forkerte resultater med dette datasæt, skal vi bruge SQL Server 2014 eller tidligere, og ANY aggregater skal implementeres i et Stream Aggregate eller Eager Hash Aggregate operatør (Flow Distinct Hash Match Aggregate producerer ikke fejlen).
En måde at tilskynde optimeringsværktøjet til at vælge et Stream Aggregate i stedet for Distinct Sort er at tilføje et klynget indeks for at give rækkefølge efter kolonne c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Efter den ændring bliver udførelsesplanen:

ANY aggregater er synlige i Egenskaber vinduet, når Stream Aggregate operator er valgt:

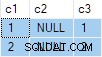
Resultatet af forespørgslen er:
Dette er forkert . SQL Server har returneret rækker, der ikke eksisterer i kildedataene. Der er ingen kilderækker, hvor c2 = 1 og c3 = 1 for eksempel. Som en påmindelse er kildedataene:
Udførelsesplanen beregner fejlagtigt separat ANY aggregater for c2 og c3 kolonner, ignorerer null. Hver aggregater uafhængigt returnerer den første ikke-null værdi den støder på, hvilket giver et resultat hvor værdierne for c2 og c3 kommer fra forskellige kilderækker . Dette er ikke, hvad den oprindelige SQL-forespørgselsspecifikation anmodede om.
Det samme forkerte resultat kan produceres med eller uden det klyngede indeks ved at tilføje en OPTION (HASH GROUP) tip til at lave en plan med et Eager Hash Aggregate i stedet for et Stream Aggregate .
Betingelser
Dette problem kan kun opstå, når der er flere ANY aggregater er til stede, og de aggregerede data indeholder nuller. Som nævnt påvirker problemet kun Stream Aggregate og Eager Hash Aggregate operatører; Særlig sortering og Flow Distinct er ikke berørt.
SQL Server 2016 og fremefter gør en indsats for at undgå at introducere flere ANY aggregeres for forespørgselsmønsteret for en række pr. gruppe rækkenummerering, når kildekolonnerne er nullbare. Når dette sker, vil eksekveringsplanen indeholde Segment , Sekvensprojekt og Filter operatører i stedet for et aggregat. Denne planform er altid sikker, da ingen ANY aggregater anvendes.
Gengivelse af fejlen i SQL Server 2016+
SQL Server optimizer er ikke perfekt til at registrere, hvornår en kolonne oprindeligt var begrænset til at være NOT NULL kan stadig producere en nul mellemværdi gennem datamanipulationer.
For at reproducere dette starter vi med en tabel, hvor alle kolonner er erklæret som NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Vi kan producere nuller fra dette datasæt på mange måder, hvoraf de fleste optimeringsværktøjer med succes kan detektere, og så undgå at introducere ANY aggregater under optimering.
En måde at tilføje nuller, der tilfældigvis glider under radaren, er vist nedenfor:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Den forespørgsel producerer følgende output:
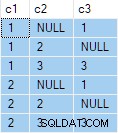
Det næste trin er at bruge denne forespørgselsspecifikation som kildedata for standardforespørgslen "enhver række pr. gruppe":
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; På en hvilken som helst version af SQL Server, der producerer følgende plan:
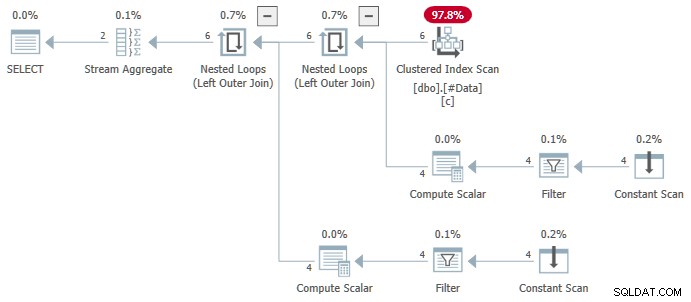
Strømaggregatet indeholder flere ANY aggregater, og resultatet er forkert . Ingen af de returnerede rækker vises i kildedatasættet:
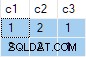
db<>fiddle online demo
Løsning
Den eneste fuldt pålidelige løsning, indtil denne fejl er rettet, er at undgå det mønster, hvor ROW_NUMBER har den samme kolonne i ORDER BY klausul som er i PARTITION BY klausul.
Når vi er ligeglade med hvilken en række er valgt fra hver gruppe, er det uheldigt at en ORDER BY klausul er overhovedet nødvendig. En måde at omgå problemet på er at bruge en køretidskonstant som ORDER BY @@SPID i vinduesfunktionen.
2. Ikke-deterministisk opdatering
Problemet med flere ANY aggregater på nul-input er ikke begrænset til forespørgselsmønsteret med én række pr. gruppe. Forespørgselsoptimeringsværktøjet kan introducere en intern ANY samlet under en række omstændigheder. Et af disse tilfælde er en ikke-deterministisk opdatering.
En ikke-deterministisk opdatering er, hvor erklæringen ikke garanterer, at hver målrække højst bliver opdateret én gang. Med andre ord er der flere kilderækker for mindst én målrække. Dokumentationen advarer eksplicit om dette:
Vær forsigtig, når du angiver FROM-sætningen for at angive kriterierne for opdateringshandlingen.Resultaterne af en UPDATE-sætning er udefinerede, hvis sætningen indeholder en FROM-sætning, der ikke er specificeret på en sådan måde, at der kun er én værdi tilgængelig for hver kolonneforekomst, der opdateres, dvs. er, hvis UPDATE-sætningen ikke er deterministisk.
For at håndtere en ikke-deterministisk opdatering grupperer optimeringsværktøjet rækkerne efter en nøgle (indeks eller RID) og anvender ANY aggregeres til de resterende kolonner. Den grundlæggende idé er at vælge en række blandt flere kandidater og bruge værdier fra den række til at udføre opdateringen. Der er åbenlyse paralleller til den tidligere ROW_NUMBER problem, så det er ingen overraskelse, at det er ret nemt at påvise en forkert opdatering.
I modsætning til det forrige nummer tager SQL Server i øjeblikket ingen særlige trin for at undgå flere ANY aggregeres på nullbare kolonner, når der udføres en ikke-deterministisk opdatering. Det følgende vedrører derfor alle SQL Server-versioner , inklusive SQL Server 2019 CTP 3.0.
Eksempel
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>fiddle online demo
Logisk set bør denne opdatering altid give en fejl:Måltabellen tillader ikke nulværdier i nogen kolonne. Uanset hvilken matchende række der vælges fra kildetabellen, et forsøg på at opdatere kolonne c2 eller c3 til null skal forekomme.
Desværre lykkes opdateringen, og den endelige tilstand af måltabellen er inkonsistent med de leverede data:
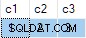
Jeg har rapporteret dette som en fejl. Arbejdet omkring er at undgå at skrive ikke-deterministisk UPDATE udsagn, så ANY aggregater er ikke nødvendige for at løse tvetydigheden.
Som nævnt kan SQL Server introducere ANY aggregater under flere omstændigheder end de to eksempler, der er givet her. Hvis dette sker, når den aggregerede kolonne indeholder nuller, er der risiko for forkerte resultater.