
T-SQL Tuesday #78 hostes af Wendy Pastrick, og udfordringen i denne måned er simpelthen at "lære noget nyt og blogge om det." Hendes blurb hælder mod nye funktioner i SQL Server 2016, men da jeg har blogget og præsenteret mange af dem, tænkte jeg, at jeg ville udforske noget andet på egen hånd, som jeg altid har været oprigtigt nysgerrig efter.
Jeg har set flere personer sige, at en heap kan være bedre end et klynget indeks for visse scenarier. Det kan jeg ikke være uenig i. En af de interessante grunde, jeg har set, er dog, at et RID-opslag er hurtigere end et nøgleopslag. Jeg er en stor fan af klyngede indekser og ikke en stor fan af heaps, så jeg følte, at dette trængte til nogle test.
Så lad os teste det!
Jeg tænkte, at det ville være godt at oprette en database med to tabeller, der er identiske, bortset fra at den ene havde en klynget primærnøgle, og den anden havde en ikke-klynget primærnøgle. Jeg ville have tid til at indlæse nogle rækker i tabellen, opdatere en masse rækker i en løkke og vælge fra et indeks (tvinger enten et nøgle- eller RID-opslag).
Systemspecifikationer
Dette spørgsmål dukker ofte op, så for at afklare de vigtige detaljer om dette system, er jeg på en 8-core VM med 32 GB RAM, understøttet af PCIe-lagring. SQL Server-versionen er 2014 SP1 CU6, uden særlige konfigurationsændringer eller sporingsflag, der kører:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13. apr. 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) på Windows NT 6.3
Databasen
Jeg oprettede en database med masser af ledig plads i både data og logfil for at forhindre eventuelle autogrow-hændelser i at forstyrre testene. Jeg indstillede også databasen til simpel gendannelse for at minimere indvirkningen på transaktionsloggen.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Tabellene
Som jeg sagde, to tabeller, hvor den eneste forskel er, om den primære nøgle er klynget.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
En tabel til registrering af kørselstid
Jeg kunne overvåge CPU og alt det, men egentlig er nysgerrigheden næsten altid omkring runtime. Så jeg oprettede en logningstabel for at fange kørselstiden for hver test:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Indsæt-testen
Så hvor lang tid tager det at indsætte 2.000 rækker 100 gange? Jeg henter nogle ret grundlæggende data fra sys.all_objects , og trækker definitionen med for eventuelle procedurer, funktioner osv.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Opdateringstesten
Til opdateringstesten ville jeg bare teste hastigheden af at skrive til et clustered index vs. en heap på en meget række-for-række måde. Så jeg dumpede 200 tilfældige rækker ind i en #temp-tabel og byggede derefter en markør rundt om den (#temp-tabellen sikrer blot, at de samme 200 rækker opdateres i begge versioner af tabellen, hvilket sandsynligvis er overkill).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Vælg-testen
Så ovenfor så du, at jeg oprettede et indeks med Name som nøglekolonnen i hver tabel; for at evaluere omkostningerne ved at udføre opslag for et betydeligt antal rækker, skrev jeg en forespørgsel, der tildeler outputtet til en variabel (eliminerer netværks I/O og klientgengivelsestid), men tvinger brugen af indekset:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Til denne ønskede jeg at vise nogle interessante aspekter af planerne, før jeg samler testresultaterne. At køre dem individuelt head-to-head giver disse sammenlignende metrics:

Varighed er uden betydning for en enkelt erklæring, men se på disse læsninger. Hvis du er på langsom lagring, er det en stor forskel, du ikke vil se i en mindre skala og/eller på din lokale udviklings-SSD.
Og så planerne, der viser de to forskellige opslag, ved hjælp af SQL Sentry Plan Explorer:

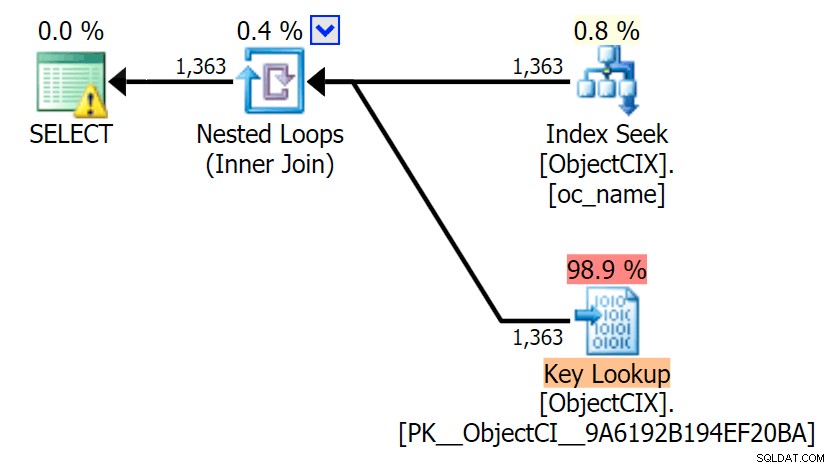
Planerne ser næsten identiske ud, og du vil muligvis ikke bemærke forskellen i læsninger i SSMS, medmindre du fangede Statistics I/O. Selv de estimerede I/O-omkostninger for de to opslag var ens – 1,69 for Nøgleopslag og 1,59 for RID-opslag. (Advarselsikonet i begge planer er for et manglende dækkende indeks.)
Det er interessant at bemærke, at hvis vi ikke tvinger et opslag og tillader SQL Server at bestemme, hvad den skal gøre, vælger den en standardscanning i begge tilfælde – ingen manglende indeksadvarsel, og se på, hvor meget tættere læsningerne er:

Optimizeren ved, at en scanning vil være meget billigere end søge + opslag i dette tilfælde. Jeg valgte en LOB-kolonne til variabel tildeling kun for effekt, men resultaterne var ens ved brug af en ikke-LOB-kolonne.
Testresultaterne
Med Timings-tabellen på plads var jeg i stand til nemt at køre testene flere gange (jeg kørte et dusin tests) og derefter komme med gennemsnit for testene med følgende forespørgsel:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Et simpelt søjlediagram viser, hvordan de sammenlignes:
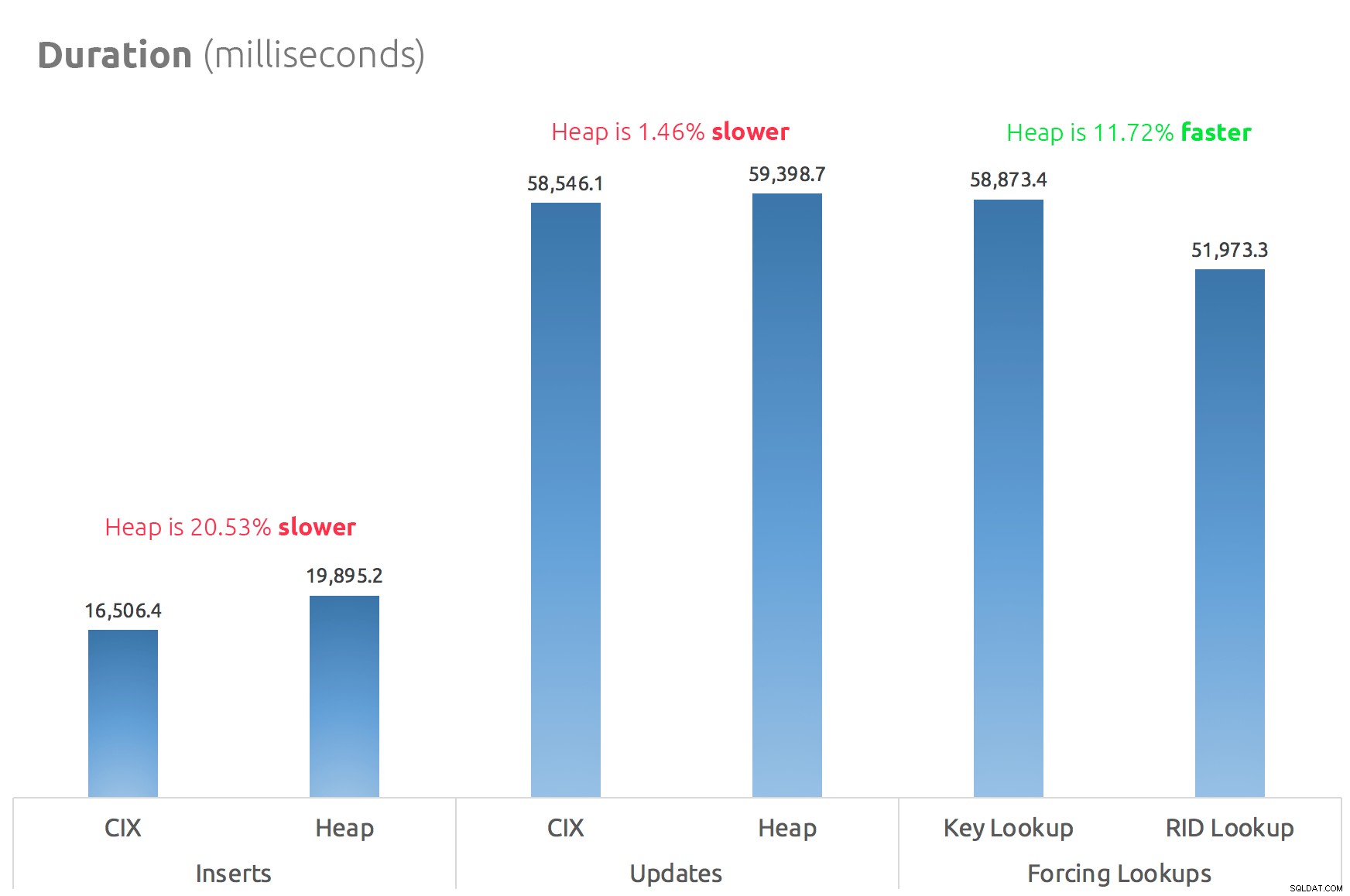
Konklusion
Så rygterne er sande:i det mindste i dette tilfælde er et RID-opslag betydeligt hurtigere end et nøgleopslag. At gå direkte til file:page:slot er tydeligvis mere effektivt med hensyn til I/O end at følge b-træet (og hvis du ikke er på moderne lagring, kan deltaet være meget mere mærkbart).
Om du vil drage fordel af det og tage alle de andre heap-aspekter med, afhænger af din arbejdsbyrde - heapen er lidt dyrere for skriveoperationer. Men det er ikke definitiv – dette kan variere meget afhængigt af tabelstruktur, indekser og adgangsmønstre.
Jeg testede meget simple ting her, og hvis du er på hegnet omkring dette, anbefaler jeg stærkt at teste din faktiske arbejdsbyrde på din egen hardware og sammenligne for dig selv (og glem ikke at teste den samme arbejdsbyrde, hvor dækkende indekser er til stede; du vil sandsynligvis få meget bedre samlet ydeevne, hvis du simpelthen kan fjerne opslag helt). Sørg for at måle alle de målinger, der er vigtige for dig; bare fordi jeg fokuserer på varighed, betyder det ikke, at det er den, du skal bekymre dig mest om. :-)