Du har sikkert lavet nogle af disse fejl, da du startede din karriere i databasedesign. Måske laver du dem stadig, eller også laver du nogle i fremtiden. Vi kan ikke gå tilbage i tiden og hjælpe dig med at fortryde dine fejl, men vi kan redde dig fra nogle fremtidige (eller nuværende) hovedpine.
At læse denne artikel kan spare dig for mange timer brugt på at rette design- og kodeproblemer, så lad os dykke ned. Jeg har opdelt listen over fejl i to hovedgrupper:dem, der er ikke-tekniske i naturen og dem, der er strengt tekniske . Begge disse grupper er en vigtig del af databasedesign.
Det er klart, hvis du ikke har tekniske færdigheder, vil du ikke vide, hvordan du gør noget. Det er ikke overraskende at se disse fejl på listen. Men ikke-tekniske færdigheder? Folk glemmer dem måske, men disse færdigheder er også en meget vigtig del af designprocessen. De tilføjer værdi til din kode, og de relaterer teknologien til det virkelige problem, du skal løse.
Så lad os starte med de ikke-tekniske problemer først, og derefter gå videre til de tekniske.
Ikke-tekniske databasedesignfejl
#1 Dårlig planlægning
Dette er bestemt et ikke-teknisk problem, men det er et stort og almindeligt problem. Vi bliver alle spændte, når et nyt projekt starter, og når vi går ind i det, ser alt godt ud. I starten er projektet stadig en tom side, og du og din kunde er glade for at begynde at arbejde på noget, der vil skabe en bedre fremtid for jer begge. Det hele er fantastisk, og en stor fremtid vil sandsynligvis være det endelige resultat. Men alligevel skal vi holde fokus. Det er den del af projektet, hvor vi kan lave afgørende fejl.
Før du sætter dig ned for at tegne en datamodel, skal du være sikker på, at:
- Du er fuldstændig klar over, hvad din kunde gør (dvs. deres forretningsplaner relateret til dette projekt og også deres overordnede billede), og hvad de ønsker, at dette projekt skal opnå nu og i fremtiden.
- Du forstår forretningsprocessen, og hvis eller når det er nødvendigt, er du klar til at komme med forslag til at forenkle og forbedre den (f.eks. for at øge effektiviteten og indkomsten, reducere omkostninger og arbejdstimer osv.).
- Du forstår datastrømmen i kundens virksomhed. Ideelt set kender du alle detaljer:hvem der arbejder med dataene, hvem der foretager ændringer, hvilke rapporter er nødvendige, hvornår og hvorfor alt dette sker.
- Du kan bruge det sprog/terminologi, din klient bruger. Selvom du måske eller måske ikke er ekspert inden for deres område, er din klient bestemt det. Bed dem om at forklare, hvad du ikke forstår. Og når du forklarer tekniske detaljer for kunden, så brug sprog og terminologi, de forstår.
- Du ved, hvilke teknologier du vil bruge, lige fra databasemotoren og programmeringssprog til andre værktøjer. Det, du beslutter dig for at bruge, er tæt forbundet med det problem, du vil løse, men det er vigtigt at inkludere kundens præferencer og deres nuværende it-infrastruktur.
I planlægningsfasen bør du få svar på disse spørgsmål:
- Hvilke tabeller vil være de centrale tabeller i din model? Du vil sandsynligvis have et par af dem, mens de andre tabeller vil være nogle af de sædvanlige (f.eks. bruger_konto, rolle). Glem ikke ordbøger og relationer mellem tabeller.
- Hvilke navne vil blive brugt til tabeller i modellen? Husk at holde terminologien magen til, hvad end klienten bruger i øjeblikket.
- Hvilke regler gælder ved navngivning af tabeller og andre objekter? (Se punkt 4 om navnekonventioner.)
- Hvor lang tid tager hele projektet? Dette er vigtigt, både for din tidsplan og for kundens tidslinje.
Først når du har alle disse svar, er du klar til at dele en indledende løsning på problemet. Denne løsning behøver ikke at være en komplet ansøgning – måske et kort dokument eller endda et par sætninger på sproget i kundens virksomhed.
God planlægning er ikke specifik for datamodellering; det gælder for næsten alle IT-projekter (og ikke-IT-projekter). Spring over er kun en mulighed, hvis 1) du har et virkelig lille projekt; 2) opgaverne og målene er klare, og 3) du har virkelig travlt. Et historisk eksempel er Sputnik 1-lanceringsingeniørerne, der giver verbale instruktioner til de teknikere, der var ved at samle den. Projektet havde travlt på grund af nyheden om, at USA planlagde at opsende deres egen satellit snart – men jeg gætter på, at du ikke har så travlt.
#2 Utilstrækkelig kommunikation med kunder og udviklere
Når du starter databasedesignprocessen, forstår du sikkert de fleste af hovedkravene. Nogle er meget almindelige uanset virksomhed, f.eks. brugerroller og statusser. På den anden side vil nogle tabeller i din model være ret specifikke. For eksempel, hvis du bygger en model til et førerhusfirma, har du borde til køretøjer, chauffører, kunder osv.
Alligevel vil ikke alt være indlysende i starten af et projekt. Du kan misforstå nogle krav, klienten kan tilføje nogle nye funktionaliteter, du vil se noget, der kunne gøres anderledes, processen kan ændre sig osv. Alle disse forårsager ændringer i modellen. De fleste ændringer kræver tilføjelse af nye tabeller, men nogle gange vil du fjerne eller ændre tabeller. Hvis du allerede er begyndt at skrive kode, der bruger disse tabeller, skal du også omskrive denne kode.
For at reducere den tid, der bruges på uventede ændringer, bør du:
- Tal med udviklere og kunder, og vær ikke bange for at stille vigtige forretningsspørgsmål. Når du tror, du er klar til at starte, så spørg dig selv Er situation X dækket af vores database? Klienten gør i øjeblikket Y på denne måde; forventer vi en ændring i den nærmeste fremtid? Når vi er sikre på, at vores model har evnen til at gemme alt, hvad vi har brug for på den rigtige måde, kan vi begynde at kode.
- Hvis du står over for en større ændring i dit design, og du allerede har skrevet en masse kode, bør du ikke prøve at finde en hurtig løsning. Gør det, som det skulle have været gjort, uanset den aktuelle situation. En hurtig løsning kunne spare lidt tid nu og ville sandsynligvis fungere fint i et stykke tid, men det kan blive til et rigtigt mareridt senere.
- Hvis du mener, at noget er okay nu, men kan blive et problem senere, skal du ikke ignorere det. Analyser dette område og implementer ændringer, hvis de vil forbedre systemets kvalitet og ydeevne. Det vil koste noget tid, men du vil levere et bedre produkt og sove meget bedre.
Hvis du forsøger at undgå at foretage ændringer i din datamodel, når du ser et potentielt problem - eller hvis du vælger en hurtig løsning i stedet for at gøre det ordentligt - vil du betale for det før eller siden.
Hold også kontakten med din klient og udviklerne under hele projektet. Tjek altid og se, om der er foretaget ændringer siden din sidste diskussion.
#3 Dårlig eller manglende dokumentation
For de fleste af os kommer dokumentation i slutningen af projektet. Hvis vi er velorganiserede, har vi sikkert dokumenteret tingene undervejs, og vi skal kun pakke det hele ind. Men ærligt talt er det normalt ikke tilfældet. At skrive dokumentation sker lige før projektet lukkes - og lige efter at vi mentalt er færdige med den datamodel!
Prisen, der betales for et dårligt dokumenteret projekt, kan være ret høj, et par gange højere end den pris, vi betaler for at dokumentere alt korrekt. Forestil dig, at du finder en fejl et par måneder efter, at du har lukket projektet. Fordi du ikke dokumenterede ordentligt, ved du ikke, hvor du skal starte.
Mens du arbejder, så glem ikke at skrive kommentarer. Forklar alt, der kræver yderligere forklaring, og skriv dybest set alt ned, som du tror vil være nyttigt en dag. Du ved aldrig, om eller hvornår du får brug for den ekstra information.
Tekniske databasedesignfejl
#4 Bruger ikke en navnekonvention
Du ved aldrig med sikkerhed, hvor længe et projekt vil vare, og om du har mere end én person, der arbejder på datamodellen. Der er et tidspunkt, hvor du er virkelig tæt på datamodellen, men du er faktisk ikke begyndt at tegne den endnu. Det er her, det er klogt at beslutte, hvordan du vil navngive objekter i din model, i databasen og i den generelle applikation. Før du modellerer, bør du vide:
- Er tabelnavne ental eller flertal?
- Vil vi gruppere tabeller ved hjælp af navne? (Alle klientrelaterede tabeller indeholder f.eks. "client_", alle opgaverelaterede tabeller indeholder "task_" osv.)
- Vil vi bruge store og små bogstaver, eller bare små bogstaver?
- Hvilket navn vil vi bruge til ID-kolonnerne? (Det vil højst sandsynligt være "id".)
- Hvordan navngiver vi fremmednøgler? (Sandsynligvis "id_" og navnet på den refererede tabel.)
Sammenlign en del af en model, der ikke bruger navngivningskonventioner, med den samme del, der bruger navngivningskonventioner, som vist nedenfor:
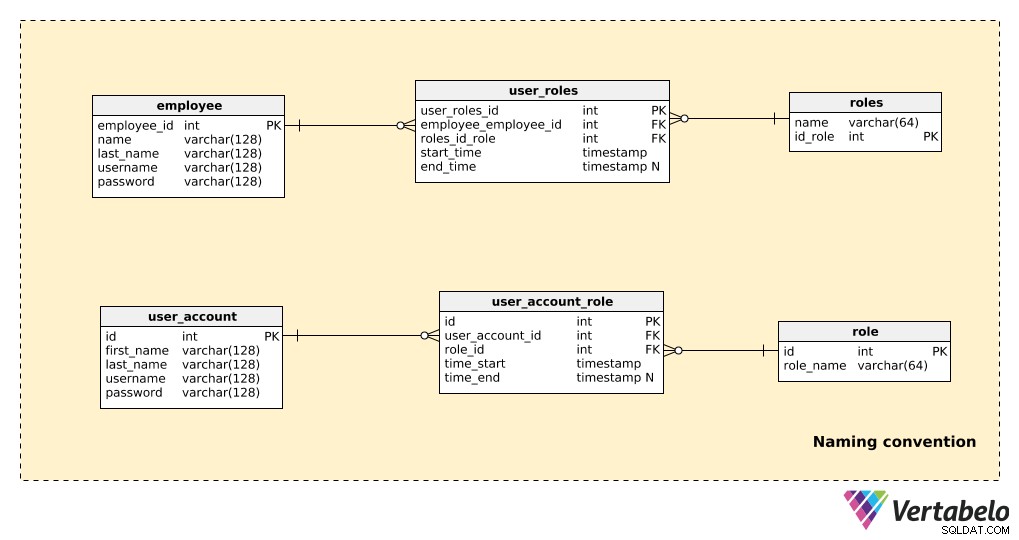
Der er kun få tabeller her, men det er stadig ret indlysende, hvilken model der er nemmere at læse. Bemærk at:
- Begge modeller "virker", så der er ingen problemer på den tekniske side.
- I eksemplet med ikke-navngivningskonventionen (de øverste tre tabeller) er der et par ting, der væsentligt påvirker læsbarheden:Brug af både entals- og flertalsformer i tabelnavnene; ikke-standardiserede primærnøglenavne (
employees_id,id_role); og attributter i forskellige tabeller deler det samme navn (navn vises f.eks. i både "employee” og “roles” tabeller).
Forestil dig nu det rod, vi ville skabe, hvis vores model indeholdt hundredvis af borde. Måske kunne vi arbejde med sådan en model (hvis vi selv skabte den), men vi ville gøre nogen meget uheldige, hvis de skulle arbejde på den efter os.
For at undgå fremtidige problemer med navne skal du ikke bruge reserverede SQL-ord, specialtegn eller mellemrum i dem.
Så før du begynder at oprette navne, skal du lave et simpelt dokument (måske kun et par sider langt), der beskriver den navnekonvention, du har brugt. Dette vil øge læsbarheden af hele modellen og forenkle det fremtidige arbejde.
Du kan læse mere om navnekonventioner i disse to artikler:
- Navngivningskonventioner i databasemodellering
- Et følelsesløst logisk blik på SQL Server-navnekonventioner
#5 Normaliseringsproblemer
Normalisering er en væsentlig del af databasedesign. Hver database bør normaliseres til mindst 3NF (primære nøgler er defineret, kolonner er atomare, og der er ingen gentagne grupper, delvise afhængigheder eller transitive afhængigheder). Dette reducerer dataduplikering og sikrer referentiel integritet.
Du kan læse mere om normalisering i denne artikel. Kort sagt, når vi taler om den relationelle databasemodel, taler vi om den normaliserede database. Hvis en database ikke er normaliseret, støder vi på en masse problemer relateret til dataintegritet.
I nogle tilfælde vil vi måske denormalisere vores database. Hvis du gør dette, har du en rigtig god grund. Du kan læse mere om databasedenormalisering her.
#6 Brug af Entity-Attribute-Value-modellen (EAV)
EAV står for entity-attribute-value. Denne struktur kan bruges til at gemme yderligere data om alt i vores model. Lad os tage et kig på et eksempel.
Antag, at vi ønsker at gemme nogle yderligere kundeattributter. "customer tabellen er vores enhed, "attribute Tabellen er naturligvis vores attribut og "attribute_value ”-tabellen indeholder værdien af den attribut for den pågældende kunde.
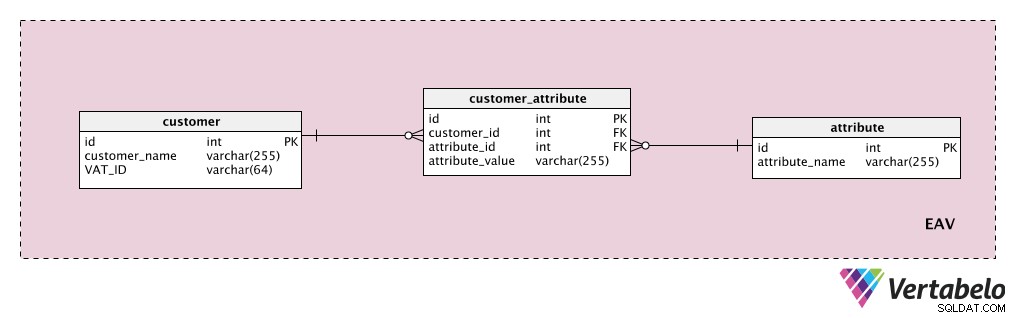
Først tilføjer vi en ordbog med en liste over alle de mulige egenskaber, vi kunne tildele en kunde. Dette er "attribute " bord. Det kan indeholde egenskaber som "kundeværdi", "kontaktoplysninger", "yderligere oplysninger" osv. "customer_attribute Tabellen indeholder en liste over alle attributter, med værdier, for hver kunde. For hver kunde har vi kun registreringer for de attributter, de har, og vi gemmer "attribute_value ” for den egenskab.
Det her kunne virke rigtig godt. Det ville give os mulighed for nemt at tilføje nye egenskaber (fordi vi tilføjer dem som værdier i "customer_attribute " bord). Dermed ville vi undgå at lave ændringer i databasen. Næsten for godt til at være sandt.
Og det er for godt. Selvom modellen gemmer de data, vi har brug for, er arbejdet med sådanne data meget mere kompliceret. Og det inkluderer næsten alt, fra at skrive simple SELECT-forespørgsler til at få alle kunderelaterede værdier til at indsætte, opdatere eller slette værdier.
Kort sagt bør vi undgå EAV-strukturen. Hvis du skal bruge det, skal du kun bruge det, når du er 100 % sikker på, at det virkelig er nødvendigt.
#7 Brug af en GUID/UUID som den primære nøgle
En GUID (Globally Unique Identifier) er et 128-bit tal genereret i henhold til regler defineret i RFC 4122. De er nogle gange også kendt som UUID'er (Universally Unique Identifiers). Den største fordel ved en GUID er, at den er unik; chancen for at du rammer den samme GUID to gange er virkelig usandsynlig. Derfor virker GUID'er som en god kandidat til den primære nøglekolonne. Men det er ikke tilfældet.
En generel regel for primærnøgler er, at vi bruger en heltalskolonne med egenskaben autoincrement sat til "yes". Dette vil tilføje data i sekventiel rækkefølge til den primære nøgle og give optimal ydeevne. Uden en sekventiel nøgle eller et tidsstempel er der ingen måde at vide, hvilke data der blev indsat først. Dette problem opstår også, når vi bruger UNIKKE værdier fra den virkelige verden (f.eks. et moms-id). Selvom de har UNIKE værdier, er de ikke gode primære nøgler. Brug dem som alternative taster i stedet.
En yderligere bemærkning: Jeg foretrækker at bruge enkeltkolonne autogenererede heltalsattributter som den primære nøgle. Det er helt klart den bedste praksis. Jeg anbefaler, at du undgår at bruge sammensatte primærnøgler.
#8 Utilstrækkelig indeksering
Indekser er en meget vigtig del af arbejdet med databaser, men en grundig diskussion af dem er uden for denne artikels rammer. Heldigvis har vi allerede et par artikler relateret til indekser, som du kan tjekke ud for at lære mere:- Hvad er et databaseindeks?
- Alt om indekser:Det helt grundlæggende
- Alt om indekser Del 2:MySQL-indeksstruktur og ydeevne
Den korte version er, at jeg anbefaler, at du tilføjer et indeks, hvor du forventer, at det bliver nødvendigt. Du kan også tilføje dem, efter at databasen er i produktion, hvis du ser, at tilføjelse af indeks på et bestemt sted vil forbedre ydeevnen.
#9 Redundante data
Overflødige data bør generelt undgås i enhver model. Det optager ikke kun ekstra diskplads, men det øger også i høj grad chancerne for problemer med dataintegritet. Hvis noget skal være overflødigt, bør vi sørge for, at de originale data og "kopi" altid er i konsistente tilstande. Faktisk er der nogle situationer, hvor overflødige data er ønskelige:
- I nogle tilfælde er vi nødt til at tildele prioritet til en bestemt handling - og for at få dette til at ske, skal vi udføre komplekse beregninger. Disse beregninger kunne bruge mange tabeller og forbruge mange ressourcer. I sådanne tilfælde vil det være klogt at udføre disse beregninger uden for arbejdstiden (og dermed undgå præstationsproblemer i arbejdstiden). Hvis vi gør det på denne måde, kan vi gemme den beregnede værdi og bruge den senere uden at skulle genberegne den. Selvfølgelig er værdien overflødig; det, vi opnår i ydeevne, er dog væsentligt mere end det, vi mister (noget harddiskplads).
- Vi gemmer muligvis også et lille sæt rapporteringsdata inde i databasen. I slutningen af dagen gemmer vi f.eks. antallet af opkald, vi har foretaget den dag, antallet af succesfulde salg osv. Rapporteringsdata bør kun gemmes på denne måde, hvis vi skal bruge dem ofte. Endnu en gang mister vi lidt harddiskplads, men vi undgår at genberegne data eller oprette forbindelse til rapporteringsdatabasen (hvis vi har en).
I de fleste tilfælde bør vi ikke bruge overflødige data, fordi:
- At gemme de samme data mere end én gang i databasen kan påvirke dataintegriteten. Hvis du gemmer en klients navn to forskellige steder, bør du foretage eventuelle ændringer (indsæt/opdater/slet) på begge steder på samme tid. Dette komplicerer også den kode, du skal bruge, selv til de enkleste handlinger.
- Selvom vi kunne gemme nogle aggregerede tal i vores operationelle database, bør vi kun gøre dette, når vi virkelig har brug for det. En operationel database er ikke beregnet til at gemme rapporteringsdata, og at blande disse to er generelt en dårlig praksis. Enhver, der producerer rapporter, skal bruge de samme ressourcer som brugere, der arbejder med driftsopgaver; rapporteringsforespørgsler er normalt mere komplekse og kan påvirke ydeevnen. Derfor bør du adskille din operationelle database og din rapporteringsdatabase.
Nu er det din tur til at veje ind
Jeg håber, at læsning af denne artikel har givet dig nogle nye indsigter og vil opmuntre dig til at følge bedste praksis for datamodellering. De vil spare dig noget tid!
Har du oplevet nogle af problemerne nævnt i denne artikel? Tror du, vi gik glip af noget vigtigt? Eller synes du, vi skal fjerne noget fra vores liste? Fortæl os venligst i kommentarerne nedenfor.