Hash-indekser er en integreret del af databaser. Hvis du nogensinde har brugt en database, er der stor sandsynlighed for, at du har set dem i aktion uden selv at være klar over det.
Hash-indekser adskiller sig i arbejde fra andre typer indekser, fordi de gemmer værdier snarere end pointere til poster placeret på en disk. Dette sikrer hurtigere søgning og indsættelse i indekset. Det er derfor, hash-indekser ofte bruges som primære nøgler eller unikke identifikatorer.
Forstå Hash-indekser
Et hash-indeks er en indekstype, der er mest almindeligt brugt i datahåndtering. Den oprettes typisk på en kolonne, der indeholder unikke værdier, såsom en primær nøgle eller e-mailadresse. Den største fordel ved at bruge hash-indekser er deres hurtige ydeevne.
Konceptet bag disse indekser kan være sofistikeret at forstå for nogen, der aldrig har hørt om dem før. Det er dog vigtigt at forstå hash-indekser, hvis du skal forstå, hvordan databaser fungerer. Det er nødvendigt for at løse almindelige problemer relateret til databaser og deres hastighed.
Den gode nyhed er, at med en lille smule tålmodighed og en slukket mobiltelefon, kan du helt sikkert mestre hash-indekser! Så lad os se nærmere.
Hurtigt og nemt
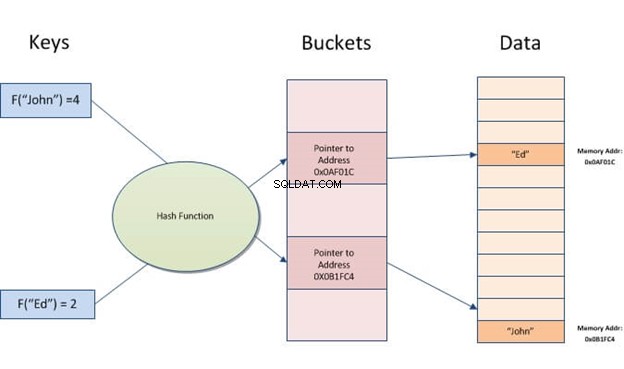
Et hash-indeks er en datastruktur, der kan bruges til at fremskynde databaseforespørgsler. Det virker ved at konvertere inputposter til en række buckets. Hver bucket har det samme antal poster som alle andre buckets i tabellen. Således, uanset hvor mange forskellige værdier du har for en bestemt kolonne, vil hver række altid knyttes til én bucket.
Hash-indekser giver mulighed for hurtige opslag på data gemt i tabeller. De fungerer ved at oprette en indeksnøgle ud fra værdien og derefter lokalisere den baseret på den resulterende hash. Det er nyttigt, når der er mange input med lignende værdier eller dubletter, da det kun skal sammenligne nøgler i stedet for at kigge alle poster igennem.
Var det hverken hurtigt eller nemt? For at forstå, hvordan hash-indekser fungerer, og hvorfor de er så kraftfulde, skal du forstå, hvad der menes med hash.
Hashing tager et stykke information (en streng) og forvandler den til en adresse eller pointer for hurtig adgang senere.
Ideen med hashing er, at data bliver tildelt et lille nummer. Når du slår dataene op, behøver du faktisk ikke at gennemsøge masser. I stedet skal du bare slå det ene tal op. Det enkleste eksempel er Ctrl+F-indtastning af det ord, du leder efter i en tekst, i stedet for selv at læse snesevis af sider.
Hvad er hash-indekser til?
Et hashindeks er en måde at fremskynde søgeprocessen på. Med traditionelle indekser skal du scanne gennem hver række for at sikre, at din forespørgsel er vellykket. Men med hash-indekser er dette ikke tilfældet!
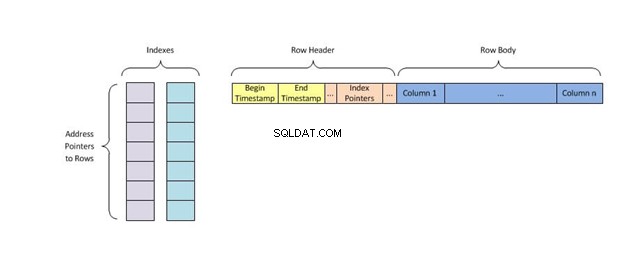
Hver nøgle i indekset indeholder kun én række af tabeldata og bruger indekseringsalgoritmen kaldet hashing som tildeler dem en unik placering i hukommelsen og eliminerer alle andre nøgler med duplikerede værdier, før de finder det, den leder efter.
Hash-indekser er en af mange måder at organisere data på i en database. De fungerer ved at tage input og bruge det som en nøgle til lagring på en disk. Disse nøgler eller hashværdier , kan være alt fra strenglængder til tegn i inputtet.
Hash-indekser bruges mest, når der forespørges på specifikke input med specifikke attributter. Det kan for eksempel være at finde alle A-bogstaver, der er højere end 10 cm. Du kan gøre det hurtigt ved at oprette en hash-indeksfunktion.
Hash-indekser er en del af PostgreSQL-databasesystemet. Dette system blev udviklet for at øge hastigheden og ydeevnen. Hash-indekser kan bruges sammen med andre indekstyper, såsom B-tree eller GiST.
Et hash-indeks gemmer nøgler ved at opdele dem i mindre bidder kaldet buckets, hvor hver bucket får et heltal-id-nummer for hurtigt at hente det, når man søger efter en nøgles placering i hash-tabellen. Bøtterne gemmes sekventielt på en disk, så de data, de indeholder, hurtigt kan tilgås.
Flere tekniske forklaringer kan findes på denne side (højreklik og vælg "Oversæt til engelsk").
Fordele
Den største fordel ved at bruge hash-indekser er, at de giver mulighed for hurtig adgang, når posten hentes efter nøgleværdien. Det er ofte nyttigt til forespørgsler med en lighedsbetingelse. Desuden vil brug af hash-benchmarks ikke kræve meget lagerplads. Det er således et effektivt værktøj, men ikke uden ulemper.
Ulempe
Hash-indekser er en relativt ny indekseringsstruktur med potentiale til at give betydelige præstationsfordele. Du kan tænke på dem som en forlængelse af binære søgetræer (BST'er).
Hash-indekser fungerer ved at gemme data i buckets baseret på deres hash-værdier, hvilket giver mulighed for hurtig og effektiv hentning af dataene. De er garanteret i orden.
Det er dog umuligt at opbevare duplikerede nøgler i en spand. Derfor vil der altid være nogle overhead. Men indtil videre opvejer fordelene ved at bruge hash-indekser ulemperne.
Hvordan fungerer det hele i lidt mere dybde?
Lad os tage en demo aviasales database for at få en mere dybdegående forståelse af, hvordan hash-indekser fungerer.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Her kan du se, hvordan vi implementerer hash-indekser ved at kompilere data i sæt.
Dette er et nemt eksempel, men bemærk, at begrænsninger kommer med mindre kodeinfrastruktur. Der kan være mangel på WAL-log adgang eller manglende evne til at gendanne indekser (indekser?) efter et nedbrud. Desuden deltager indekser muligvis ikke i replikering - det skyldes, at PostgreSQL er forældet. Men ligesom med Python får du advarsler, der ofte giver dig mulighed for at forhindre fejl.
Du kan tage et dybere kig inde i disse indekser, hvis du er tilstrækkelig fascineret. Til det opretter vi en sideinspektion udvidelsesforekomst.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Hvis du ønsker at inspicere koden fuldstændigt, skal du starte med README.
Oversigt
Hash-indekser er en datastruktur, der fremskynder processen med at søge efter information i store databaser. De fungerer ved at opdele dataene i mindre bidder og derefter sortere dem. Når du søger efter noget, kan du således finde det meget hurtigere.
Hvis du vil slå flere ting op, er der ressourcer til DYOR. Hold også øje med vores nye artikler, som udkommer hurtigere, end du kan Ctrl+F ordet “hash” på denne side. Håber dette hjælper!