Ønskede at springe ind med mulighed for at løse din opgave med ren BigQuery (Standard SQL)
Forudsætninger/antagelser :Kildedata er i sandbox.temp.id1_id2_pairs
Du bør erstatte dette med dit eget, eller hvis du vil teste med dummy-data fra dit spørgsmål - du kan oprette denne tabel som nedenfor (erstat selvfølgelig sandbox.temp med dit eget project.dataset )
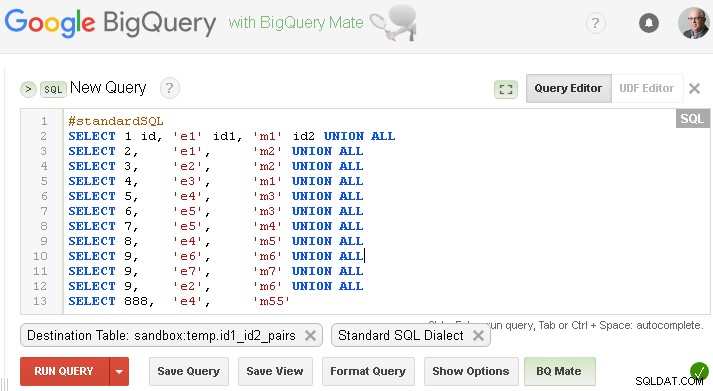
Sørg for, at du angiver den respektive destinationstabel
Bemærk :du kan finde alle respektive forespørgsler (som tekst) nederst i dette svar, men indtil videre illustrerer jeg mit svar med skærmbilleder - så alt er præsenteret - forespørgsel, resultat og brugte muligheder
Så der vil være tre trin:
Trin 1 - Initialisering
Her laver vi bare indledende gruppering af id1 baseret på forbindelser med id2:
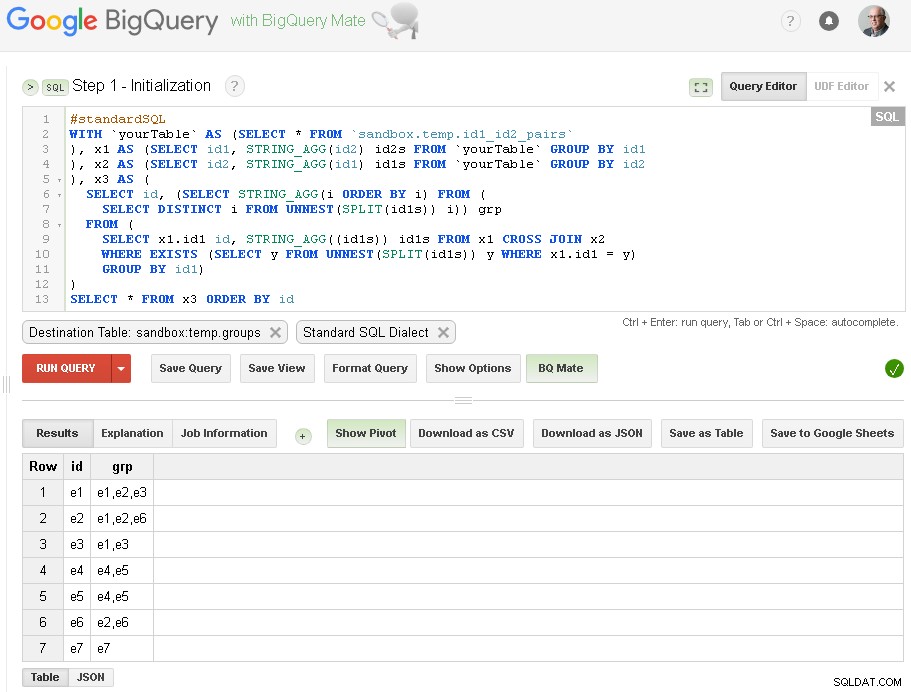
Som du kan se her - har vi lavet en liste over alle id1-værdier med respektive forbindelser baseret på simpel et-niveau forbindelse gennem id2
Outputtabel er sandbox.temp.groups
Trin 2 - Grupper iterationer
I hver iteration vil vi berige gruppering baseret på allerede etablerede grupper.
Kilde til forespørgsel er outputtabel fra forrige trin (sandbox.temp.groups ) og Destination er den samme tabel (sandbox.temp.groups ) med Overskriv
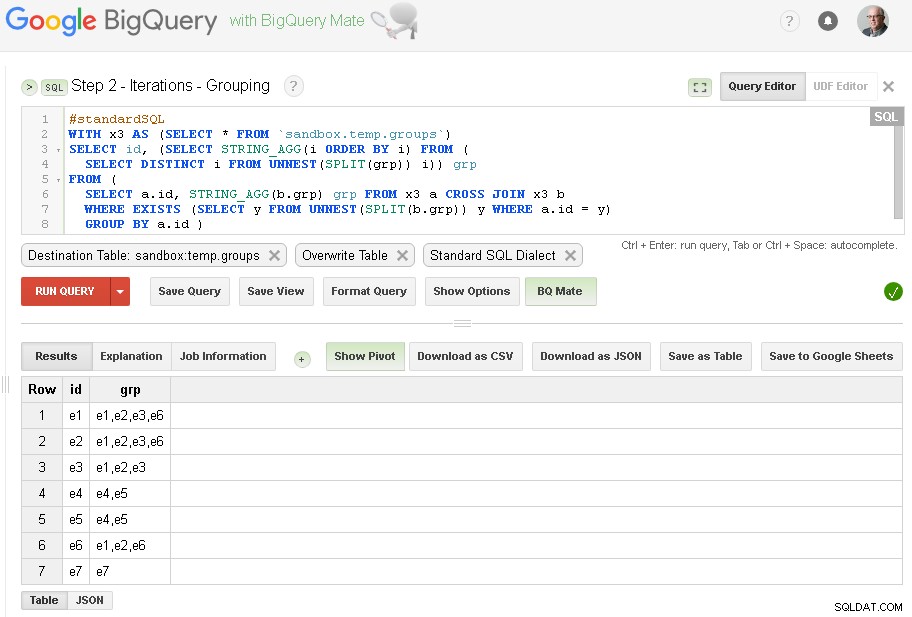
Vi fortsætter gentagelser, indtil antallet af fundne grupper vil være det samme som i forrige iteration
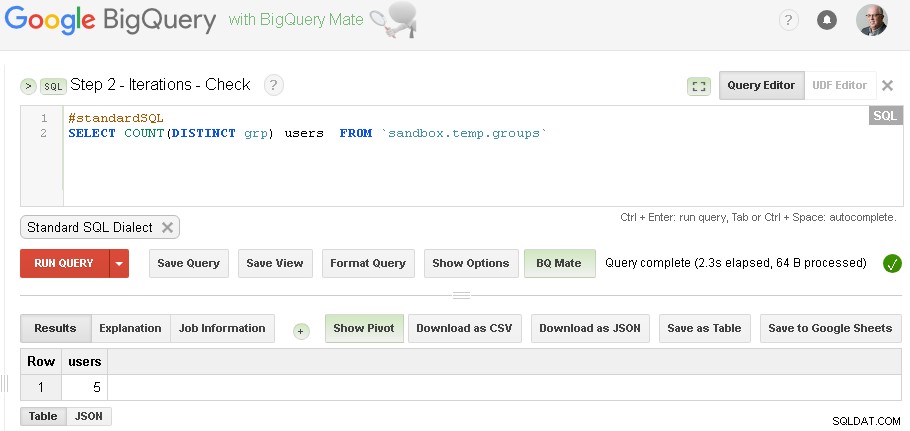
Bemærk :du kan bare have to BigQuery Web UI-faner åbnet (som det er vist ovenfor) og uden at ændre nogen kode skal du bare køre gruppering og derefter kontrollere igen og igen, indtil iteration konvergerer
(for specifikke data, som jeg brugte i afsnittet med forudsætninger - jeg havde tre iterationer - første iteration producerede 5 brugere, anden iteration producerede 3 brugere og tredje iteration producerede igen 3 brugere - hvilket indikerede, at vi var færdige med iterationer.
Selvfølgelig, i det virkelige liv - antallet af iterationer kan være mere end blot tre - så vi har brug for en form for automatisering (se det respektive afsnit nederst i svaret).
Trin 3 – Endelig gruppering
Når id1-gruppering er afsluttet - kan vi tilføje endelig gruppering for id2
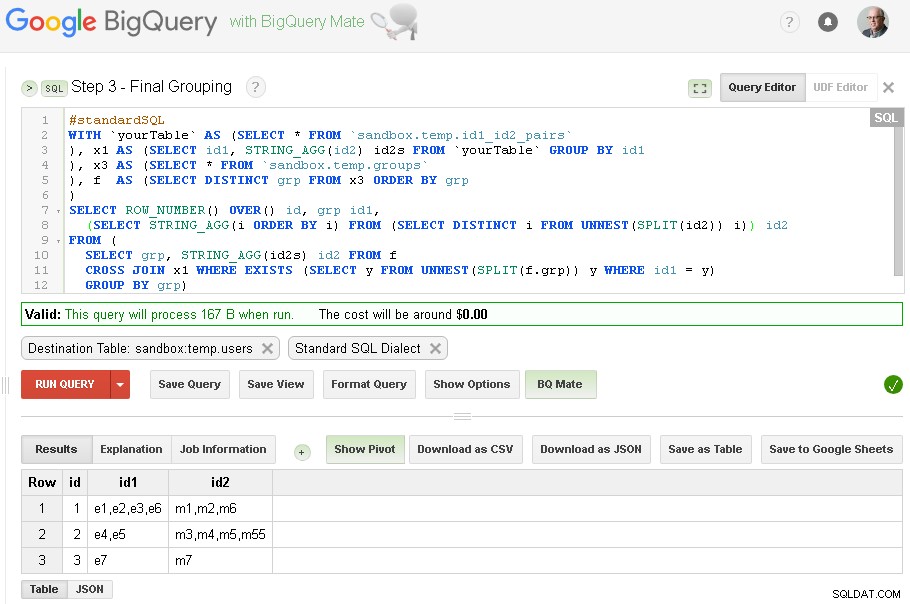
Det endelige resultat er nu i sandbox.temp.users tabel
Brugte forespørgsler (glem ikke at indstille respektive destinationstabeller og overskriver, når det er nødvendigt i henhold til ovenstående beskrevne logik og skærmbilleder):
Forudsætninger:
#standardSQLSELECT 1 id, 'e1' id1, 'm1' id2 UNION ALLSELECT 2, 'e1', 'm2' UNION ALLSELECT 3, 'e2', 'm2' UNION ALLSELECT 4, 'e3', 'm1' UNION ALLSELECT 5, 'e4', 'm3' UNION ALLSELECT 6, 'e5', 'm3' UNION ALLSELECT 7, 'e5', 'm4' UNION ALLSELECT 8, 'e4', 'm5' UNION ALLSELECT 9 , 'e6', 'm6' UNION ALLSELECT 9, 'e7', 'm7' UNION ALLSELECT 9, 'e2', 'm6' UNION ALLSELECT 888, 'e4', 'm55' Trin 1
#standardSQLWITH `dinTabel` AS (vælg * fra `sandbox.temp.id1_id2_pairs`), x1 AS (VÆLG id1, STRING_AGG(id2) id2s FRA `dinTabel` GRUPPE AF id1), x2 AS (VÆLG id2 , STRING_AGG(id1) id1s FRA `dinTabel` GROUP BY id2 ), x3 AS ( SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM ( SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp FROM ( SELECT x1.id1 id, STRING_AGG((id1s)) id1s FRA x1 CROSS JOIN x2 HVOR EKSISTERER (VÆLG y FRA UNNEST(SPLIT(id1s)) y HVOR x1.id1 =y) GRUPPER EFTER id1) )VÆLG * FRA x3 Trin 2 - Gruppering
#standardSQLWITH x3 AS (vælg * fra `sandbox.temp.groups`)SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grpFROM ( SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id =y) GROUP BY a.id ) Trin 2 - Tjek
#standardSQLSELECT COUNT(DISTINCT grp) brugere FRA `sandbox.temp.groups` Trin 3
#standardSQLWITH `dinTabel` AS (vælg * fra `sandbox.temp.id1_id2_pairs`), x1 AS (VÆLG id1, STRING_AGG(id2) id2s FRA `dinTabel` GRUPPE AF id1 ), x3 som (vælg * fra `sandbox.temp.groups`), f AS (SELECT DISTINCT BY i) FRA (SELECT DISTINCT BY i) FRA (SELECT DISTINCT BY grp) SELECT ROW_NUMBER() OVER() id, grp id1, (SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT BY i) (SPLIT(id2)) i)) id2FROM ( SELECT grp, STRING_AGG(id2s) id2 FROM f CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 =y) GROUP BY grp)
Automatisering :
Selvfølgelig kan ovenstående "proces" udføres manuelt i tilfælde af, at gentagelser konvergerer hurtigt - så du ender med 10-20 kørsler. Men i mere virkelige tilfælde kan du nemt automatisere dette med enhver klient
efter eget valg