Introduktion
Lige nu kan dine matchningsbetingelser være for brede. Du kan dog bruge levenshtein afstand til at tjekke dine ord. Det er måske ikke for let at opfylde alle ønskede mål med det, som lydlighed. Derfor foreslår jeg, at du deler dit problem op i nogle andre problemer.
For eksempel kan du oprette en brugerdefineret kontrol, som vil bruge bestået kaldbar input, som tager to strenge og derefter besvare spørgsmål om, er de ens (for levenshtein det vil være afstand mindre end en værdi, for similar_text - nogle procent af lighed e t.c. - det er op til dig at definere regler).
Lighed, baseret på ord
Nå, alle indbyggede funktioner vil svigte, hvis vi taler om sag, når du leder efter delvis match - især hvis det handler om ikke-ordnet match. Derfor bliver du nødt til at oprette et mere komplekst sammenligningsværktøj. Du har:
- Datastreng (det vil f.eks. være i DB). Det ser ud som D =D0 D1 D2 ... Dn
- Søgestreng (det vil være brugerinput). Det ser ud som S =S0 S1 ... Sm
Her betyder mellemrumssymboler ethvert mellemrum (jeg antager, at mellemrumssymboler ikke vil påvirke ligheden). Også n > m . Med denne definition handler dit problem om - at finde et sæt m ord i D som vil ligne S . Ved set Jeg mener enhver uordnet sekvens. Derfor, hvis vi finder en sådan sekvens i D , derefter S ligner D .
Det er klart, hvis n < m så indeholder input flere ord end datastreng. I dette tilfælde kan du enten tro, at de ikke ligner hinanden eller opføre sig som ovenfor, men skifte data og input (det ser dog lidt mærkeligt ud, men er anvendeligt i en eller anden forstand)
Implementering
For at gøre tingene, skal du være i stand til at oprette et sæt af strenge, som er dele fra m ord fra D . Baseret på mit dette spørgsmål
du kan gøre dette med:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-så for ethvert array, getAssoc() returnerer en række uordnede valg bestående af m genstande hver.
Næste trin handler om rækkefølge i produceret udvalg. Vi bør søge både Niels Andersen og Andersen Niels i vores D snor. Derfor skal du være i stand til at oprette permutationer for array. Det er et meget almindeligt problem, men jeg vil også lægge min version her:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Efter dette vil du være i stand til at oprette valg af m ord og derefter, ved at permutere hver af dem, få alle varianter til sammenligning med søgestrengen S . Denne sammenligning vil hver gang blive foretaget via noget tilbagekald, såsom levenshtein . Her er et eksempel:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Dette vil kontrollere lighed, baseret på brugertilbagekald, som skal acceptere mindst to parametre (dvs. sammenlignede strenge). Du kan også ønske at returnere en streng, der udløste et positivt tilbagekald. Bemærk venligst, at denne kode ikke vil adskille store og små bogstaver - men det kan være, at du ikke ønsker en sådan adfærd (så skal du bare erstatte strtolower() ).
Eksempel på fuld kode er tilgængelig i denne fortegnelse (Jeg brugte ikke sandbox, da jeg ikke er sikker på, hvor længe kodelisten vil være tilgængelig der). Med dette eksempel på brug:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
du får et resultat som:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-her er en demo for denne kode, for en sikkerheds skyld.
Kompleksitet
Da du ikke bare interesserer dig for en hvilken som helst metode, men også om - hvor god er den, vil du måske bemærke, at en sådan kode vil producere ret overdrevne operationer. Jeg mener i det mindste generation af strengedele. Kompleksiteten består her af to dele:
- Strings dele generation del. Hvis du vil generere alle strengdele - skal du gøre dette som jeg har beskrevet ovenfor. Muligt punkt at forbedre - generering af uordnede strengsæt (der kommer før permutation). Men jeg tvivler stadig på, at det kan lade sig gøre, fordi metoden i den medfølgende kode vil generere dem ikke med "brute-force", men som de er matematisk beregnede (med kardinalitet af
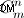 )
) - Del til kontrol af lighed. Her afhænger din kompleksitet af givet lighedstjek. For eksempel,
similar_text()har O(N) kompleksitet, så med store sammenligningssæt vil det være ekstremt langsomt.
Men du kan stadig forbedre den nuværende løsning med at tjekke direkte. Nu vil denne kode først generere alle streng-undersekvenser og derefter begynde at kontrollere dem én efter én. I almindelige tilfælde behøver du ikke at gøre det, så du vil måske erstatte det med adfærd, når det efter generering af næste sekvens vil blive kontrolleret med det samme. Så vil du øge ydeevnen for strenge, der har et positivt svar (men ikke for dem, der ikke matcher).