Sådan bliver disse to tilgange fysisk repræsenteret i databasen:
Lad os analysere begge tilgange...
Fremgangsmåde 1 (begge retninger gemt i tabellen):
- PRO:Enklere forespørgsler.
- CON:Data kan beskadiges ved kun at indsætte/opdatere/slette én retning.
- MINOR PRO:Kræver ikke yderligere begrænsninger for at sikre, at et venskab ikke kan duplikeres.
- Yderligere analyse er nødvendig:
- TIE:Ét indeks omslag begge retninger, så du behøver ikke et sekundært indeks.
- TIE:Lagerkrav.
- TIE:Ydeevne.
Fremgangsmåde 2 (kun én retning gemt i tabellen):
- CON:Mere komplicerede forespørgsler.
- PRO:Kan ikke ødelægge dataene ved at glemme at håndtere den modsatte retning, da der ikke er nogen modsat retning .
- MINOR CON:Kræver
CHECK(UID < FriendID), så et samme venskab kan aldrig repræsenteres på to forskellige måder, og tasten på(UID, FriendID)kan gøre sit arbejde. - Yderligere analyse er nødvendig:
- TIE:To indekser er nødvendige for at dækning
begge retninger af forespørgsel (sammensat indeks på
{UID, FriendID}og sammensat indeks på{FriendID, UID}). - TIE:Lagerkrav.
- TIE:Ydeevne.
- TIE:To indekser er nødvendige for at dækning
begge retninger af forespørgsel (sammensat indeks på
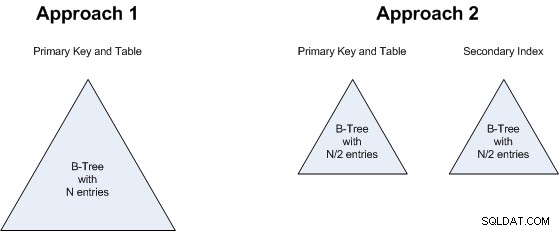
punkt 1 er af særlig interesse. MySQL/InnoDB altid klynger data, og sekundære indekser kan være dyre i clustered tabeller (se "Ulempe ved clustered-indexes" i denne artikel ), så det kan virke som om det sekundære indeks i tilgang 2 ville optære alle fordelene ved færre rækker. Men , indeholder det sekundære indeks nøjagtig de samme felter som det primære (kun i modsat rækkefølge), så der er ingen lageroverhead i dette særlige tilfælde. Der er heller ingen pointer to table heap (da der ikke er nogen table heap), så det er nok endnu billigere lagringsmæssigt end et normalt heap-baseret indeks. Og forudsat at forespørgslen er dækket af indekset, vil der heller ikke være et dobbeltopslag, der normalt er forbundet med et sekundært indeks i en klynget tabel. Så dette er dybest set uafgjort (hverken tilgang 1 eller tilgang 2 har væsentlige fordele).
punkt 2 er relateret til punkt 1:det er ligegyldigt, om vi vil have et B-Tree med N-værdier eller to B-Trees, hver med N/2-værdier. Så dette er også uafgjort:begge tilgange vil bruge omtrent samme mængde lagerplads.
Det samme ræsonnement gælder for punkt 3 :om vi søger et større B-træ eller 2 mindre, gør ikke den store forskel, så dette er også uafgjort.
Så for robusthedens skyld og på trods af noget grimmere forespørgsler og et behov for yderligere CHECK , jeg ville gå med tilgang 2.