ProxySQL er en dedikeret belastningsbalancer til MySQL, som kommer med en række funktioner, herunder, men ikke begrænset til, omdirigering af forespørgsler, cachelagring af forespørgsler eller trafikformning. Det kan bruges til nemt at opsætte en læse-skrive-split og omdirigere forespørgsler til adskille backend-noder. Som et resultat giver det mange overbevisende grunde til at bruge. På den anden side er HAProxy en fantastisk belastningsbalancer, men den er ikke dedikeret til databaser, og selvom den kan bruges, kan den ikke rigtig sammenlignes funktionsmæssigt med ProxySQL. Dette kan være årsagen til, at miljøer, der stadig er afhængige af HAProxy, forsøger at migrere til ProxySQL.
I dette korte blogindlæg deler vi et par forslag vedrørende migreringsprocessen.
Planlægning af din opgradering
Dette er ret indlysende og burde være uden spørgsmål, men vi vil stadig gerne have det på skrift. Planlæg din opgradering. Sørg for, at du er fortrolig med processen, at du har testet alt grundigt. Opsæt et testmiljø, hvor du kan verificere forskellige tilgange til opgraderingen og beslutte, hvilken der ville fungere bedst for dig.
Test læse-/skriveopdeling i ProxySQL, hvis du overvejer at bruge det
Afhængigt af dine krav, kan du overveje at bruge læse/skriveopdeling i ProxySQL. Dette er sandsynligvis en af de mest overbevisende grunde til at opgradere. I stedet for at implementere det på applikationssiden (eller slet ikke implementere det, hvis du ikke kan opnå det i applikationen), kan du stole på, at ProxySQL udfører læse/skriveopdelingen for dig. Opsætningen er meget nem, især hvis du implementerer ProxySQL ved hjælp af ClusterControl - det sker stort set automatisk.
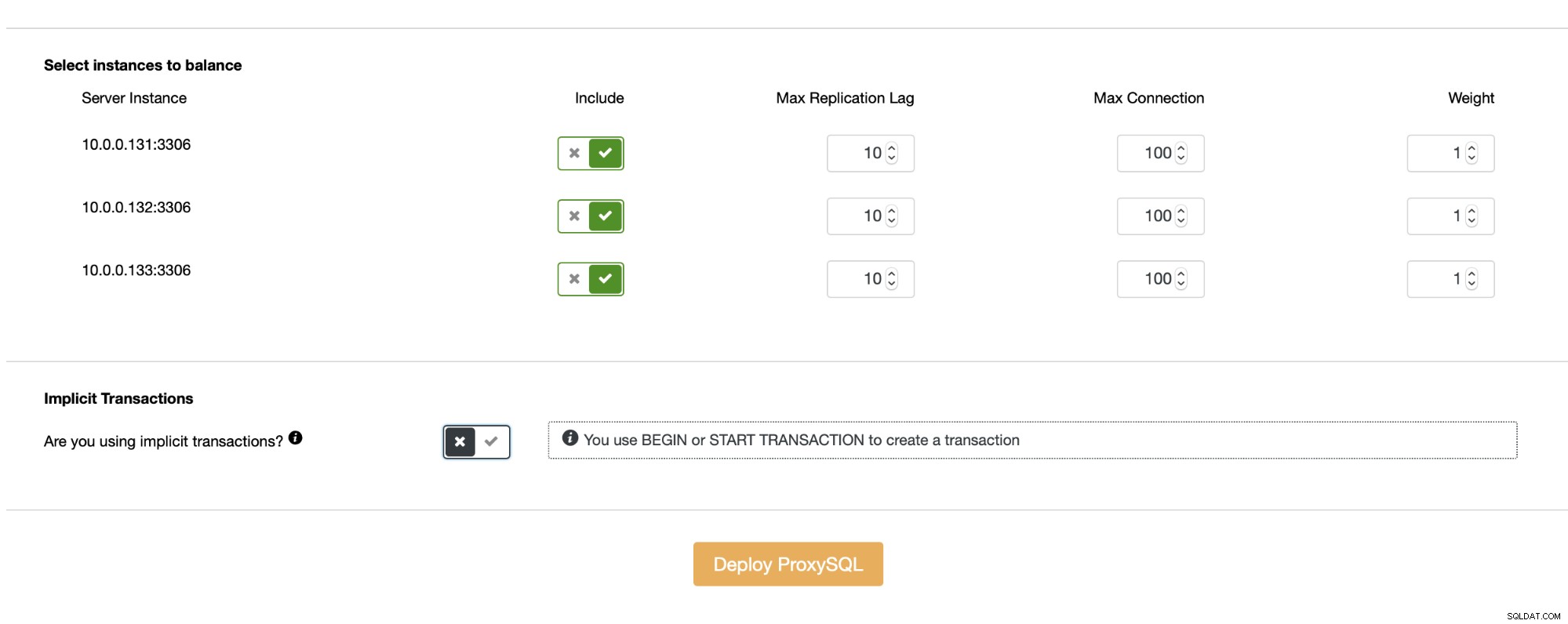
Så længe du ikke bruger implicitte transaktioner, opsætter ClusterControl læse-/skriveopdeling for dig ved hjælp af et sæt forespørgselsregler:
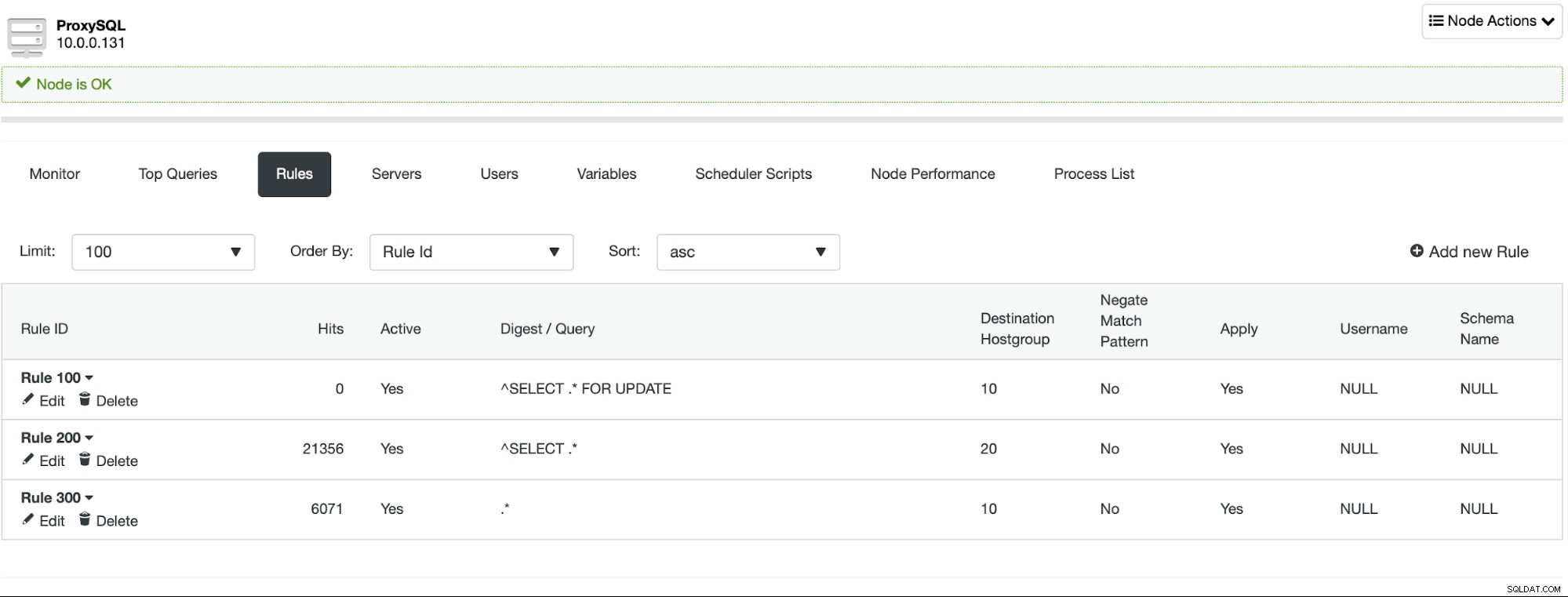
Selvom det er meget enkelt at implementere læse/skriveopdeling, bør du udvis forsigtighed, når du planlægger at gøre det. Applikationer kan være afhængige af nogle funktioner, der ikke rigtig fungerer ud af boksen i ProxySQL. I de fleste tilfælde vil yderligere konfiguration lade dig drage fordel af denne funktion, men det er meget vigtigt i testfasen at identificere, om din app bare vil fungere, eller har du brug for at tilføje en brugerdefineret konfiguration. Særligt vanskelige dele er læs-efter-skrive-problemer - i så fald skal du muligvis omkonfigurere ProxySQL for at deaktivere forbindelsesmultipleksing for nogle af forespørgslerne.
Glem alt om konfigurationsfilen i ProxySQL
Dette er en af de ting, der kommer som en overraskelse for nye brugere af ProxySQL. Det bruger ikke rigtig konfigurationsfiler. Der er en, ja, men den fungerer stort set som en måde at bootstrap ProxySQL på under den første start. ProxySQL bruger en SQLite-database, der indeholder dens konfiguration, og den korrekte måde at foretage konfigurationsændringer på er gennem en MySQL-klient, der er forbundet til den administrative port på ProxySQL. Derfra kan du foretage konfigurationsændringerne i runtime, stort set uden behov for at genstarte ProxySQL.
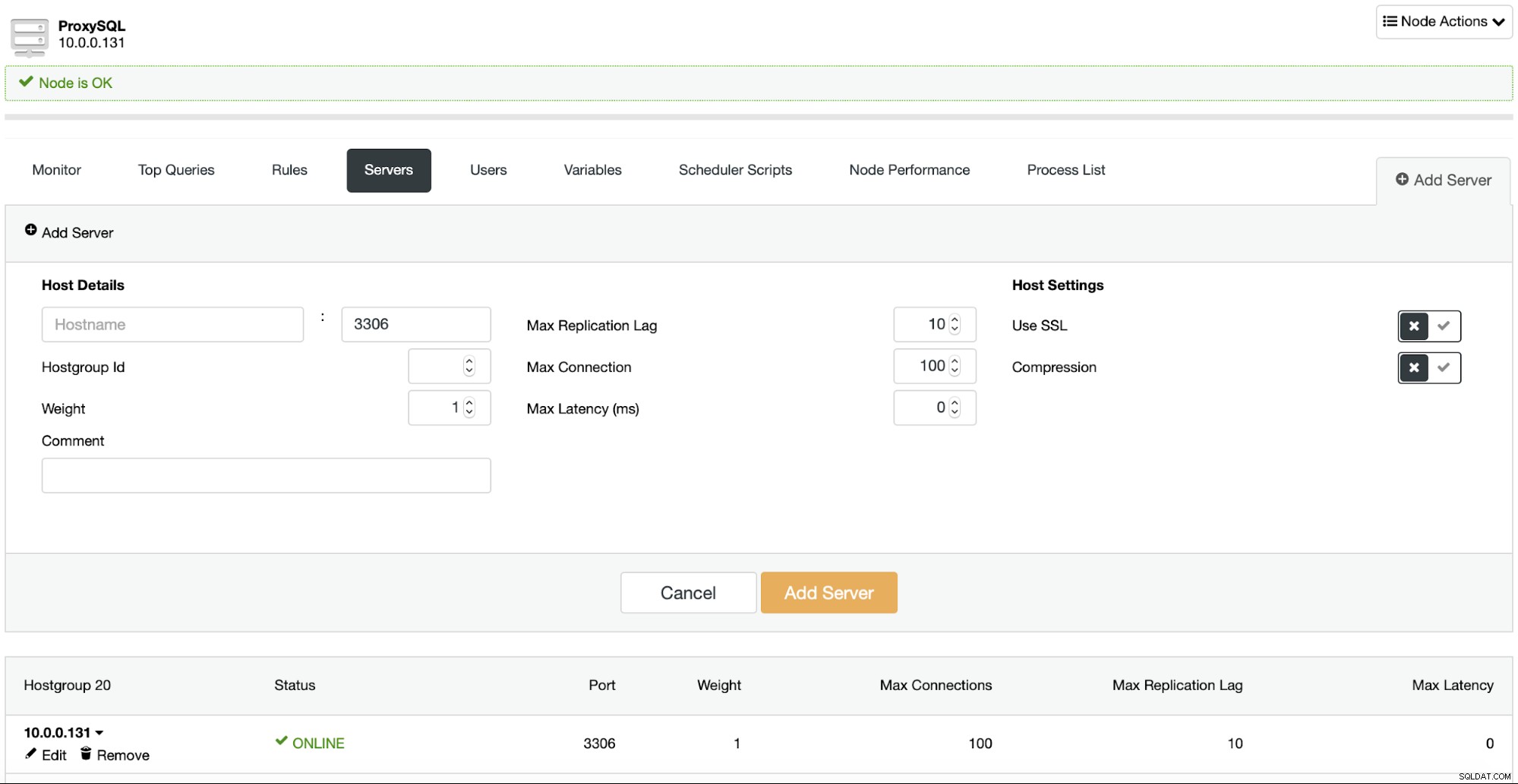
Selvfølgelig giver ClusterControl UI også mulighed for at omkonfigurere ProxySQL:
ProxySQL-implementeringsmønstre
Der er to hovedmåder, hvorpå du vil implementere ProxySQL. Du kan enten bruge en dedikeret server til at implementere ProxySQL på:
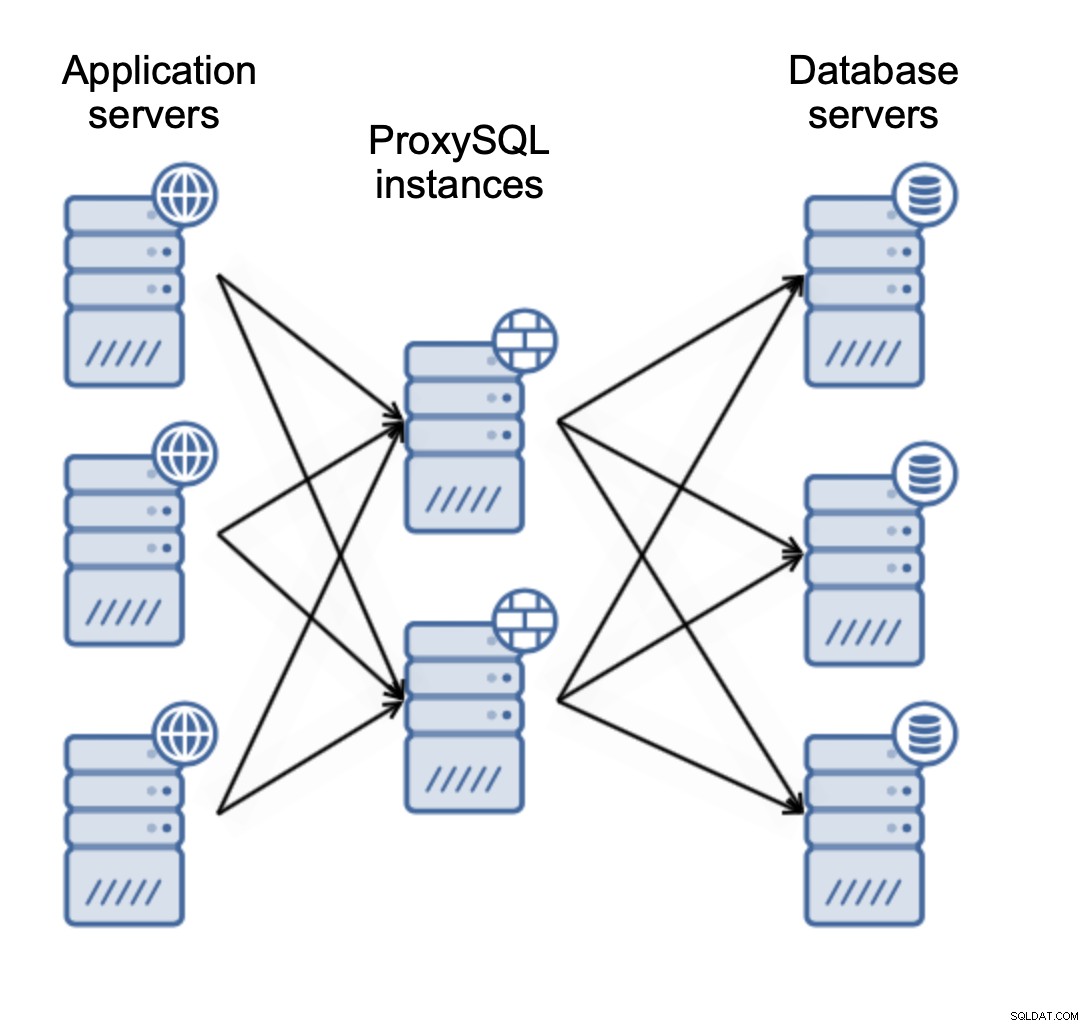
Eller du kan samle ProxySQL med applikationsservere:
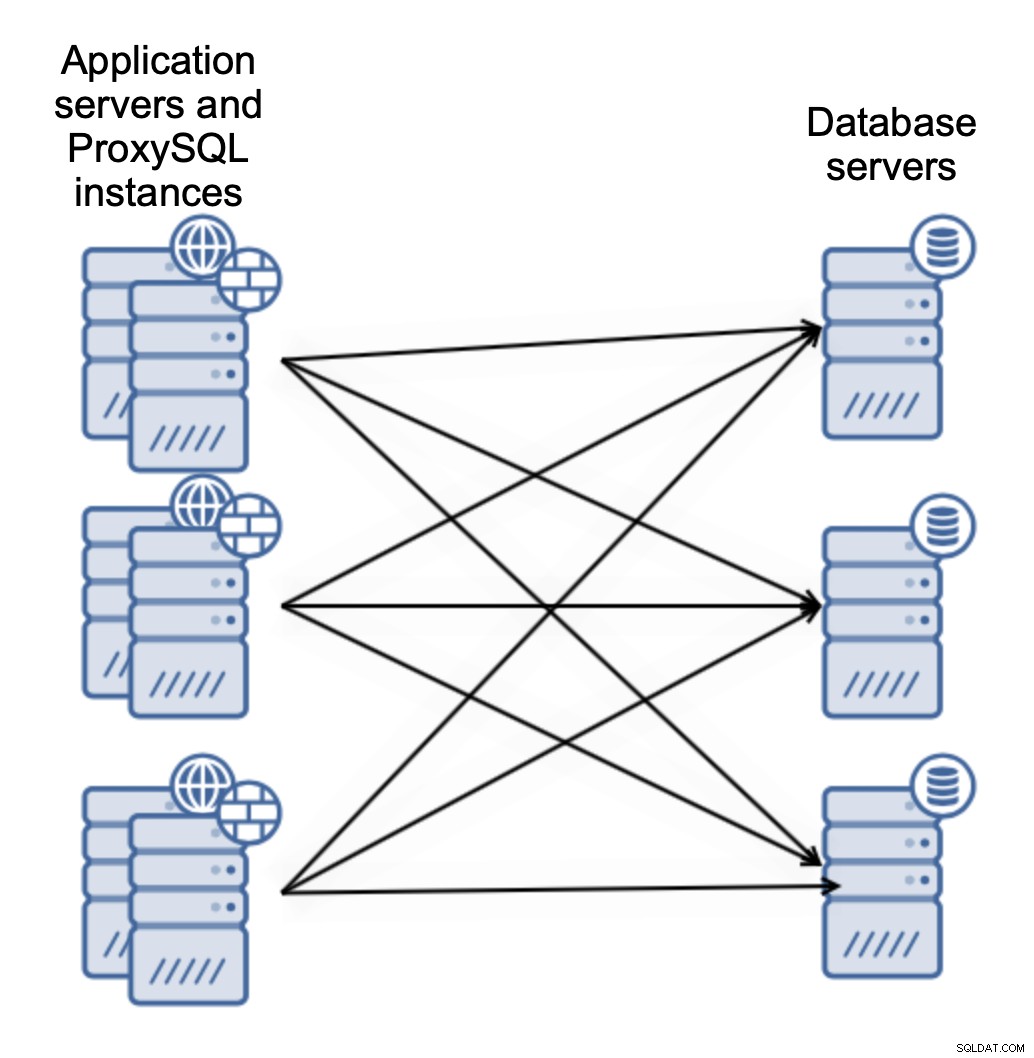
Dette lader din applikation oprette forbindelse til den lokale ProxySQL-instans ved hjælp af Unix-socket, som er bedre ydelsesmæssigt end at bruge en fjern-TCP-forbindelse. Det forenkler også opsætningen - der er ingen grund til at implementere Keepalved eller en anden Virtual IP-udbyder for at indlæse balance på tværs af ProxySQL-instanser. Applikationen opretter kun forbindelse til den lokale ProxySQL, og det er stort set det.
Brug ProxySQL-klynger til større implementeringer
Det kan være udfordrende at sikre, at dine ProxySQL-instanser hele tiden indeholder den samme konfiguration, især hvis antallet er stort. Der er adskillige måder at håndtere sådanne udfordringer på - Ansible/Chef/Puppet, shell-scripts og så videre. Vi vil foreslå at stole på den indbyggede løsning - ProxySQL Cluster. Med blot et par konfigurationsændringer kan du konfigurere ProxySQL-noder til at danne en klynge, hvor en konfigurationsændring på en af knudepunkterne vil blive spredt på tværs af alle medlemmer af klyngen.
Tinker med SO_REUSEPORT for yndefuld belastningsbalancerskift
En af de mere udfordrende dele kan være at sikre, at du skifter trafikken fra HAProxy til ProxySQL på en måde, så det minimerer indvirkningen på applikationen. Typisk vil du skulle ændre mindst én indstilling - værtsnavn eller port, som applikationen skal oprette forbindelse til. Afhængigt af dit miljø er dette muligvis ikke ideelt, især hvis databaseforbindelseskonfigurationen er indbygget i applikationen. Det ville stort set kræve en ændring i kodebasen og skubbe en ny kode til produktionen. Ikke den største af tilbud, men du kan gøre det bedre end det.
Det interessante er, at både ProxySQL og nyere versioner af HAProxy (startende fra 1.8) er i stand til at bruge SO_REUSEPORT. Denne socket-indstilling er tilgængelig i Linux fra 3.9-kernen, og den tillader flere processer at dele den samme port. ProxySQL kan bruge det til yndefulde opgraderinger mellem ProxySQL-versioner, HAProxy bruger det til at genindlæse konfiguration uden nogen indvirkning på applikationen. Hvad der er interessant, er det muligt at konfigurere ProxySQL til at dele porten med HAProxy for den problemfri migrering mellem disse to belastningsbalancere.
Der er et par ting du skal overveje, når du forsøger at gøre dette - for det første bruger ProxySQL ikke denne mulighed som standard, du skal tilføje -r flag til ProxySQL ved opstart. Du kan gøre det ved at redigere ProxySQL systemd enhedsfil:
example@sqldat.com:~# systemctl edit proxysql --fullog ændrer ExecStart-direktivet til:
ExecStart=/usr/bin/proxysql -c /etc/proxysql.cnf -rEn anden begrænsning, som du bør være opmærksom på i Linux, er, at kun processer startet af det samme bruger-id må dele porten. Dette vil betyde, at du bliver nødt til at omkonfigurere ProxySQL for at blive udført som en "haproxy"-bruger.
Som sædvanligt vil du måske køre test, før du forsøger at udføre denne handling i et produktionsmiljø. Det er bestemt muligt at opnå denne bedrift, men du bør udvise forsigtighed og dobbelttjekke, at det ikke vil påvirke din produktion på grund af en eller anden form for ikke-standard konfiguration relateret til dit miljø.
Vi håber, at denne korte blog vil give dig et indblik i migreringsprocessen fra HAProxy til ProxySQL. For databasens backends vil denne ændring være meget fordelagtig, selvom forberedelsesdelen kan være tidskrævende. Hvis du gennemgår ordentlig test, bør den endelige migrering være ret ligetil og sikker.