I den første del af denne blog dækkede vi en implementeringsgennemgang af MySQL InnoDB Cluster med et eksempel på, hvordan applikationerne kan oprette forbindelse til klyngen via en dedikeret læse/skriveport.
I denne operationsgennemgang vil vi vise eksempler på, hvordan man overvåger, administrerer og skalerer InnoDB-klyngen som en del af de igangværende klyngevedligeholdelsesoperationer. Vi bruger den samme klynge, som vi implementerede i den første del af bloggen. Følgende diagram viser vores arkitektur:
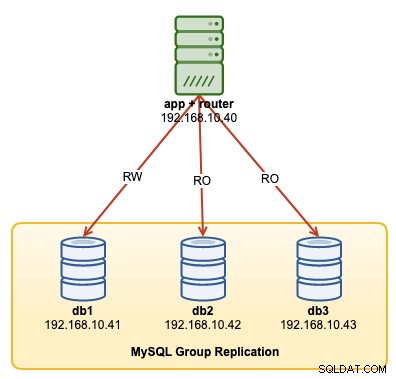
Vi har en MySQL-gruppereplikering med tre noder og én applikationsserver, der kører med MySQL router. Alle servere kører på Ubuntu 18.04 Bionic.
MySQL InnoDB Cluster Command Options
Før vi går videre med nogle eksempler og forklaringer, er det godt at vide, at du kan få en forklaring på hver funktion i MySQL cluster for cluster-komponent ved at bruge help()-funktionen, som vist nedenfor:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()Den følgende liste viser de tilgængelige funktioner på MySQL Shell 8.0.18, for MySQL Community Server 8.0.18:
- addInstance(instance[, options])- Tilføjer en instans til klyngen.
- checkInstanceState(instance)- Bekræfter forekomstens gtid-tilstand i forhold til klyngen.
- describe()- Beskriv klyngens struktur.
- disconnect()- Afbryder forbindelsen til alle interne sessioner, der bruges af klyngeobjektet.
- opløse([options])- Deaktiverer replikering og afregistrerer ReplicaSets fra klyngen.
- forceQuorumUsingPartitionOf(instans[, adgangskode])- Gendanner klyngen fra kvorumstab.
- getName()- Henter navnet på klyngen.
- hjælp([medlem])- Giver hjælp til denne klasse og dens medlemmer
- options([options])- Viser klyngekonfigurationsindstillingerne.
- rejoinInstance(instance[, options])- Forener en instans til klyngen.
- removeInstance(instance[, options])- Fjerner en instans fra klyngen.
- genscan([options])- Genscanner klyngen.
- resetRecoveryAccountsPassword(options)- Nulstil adgangskoden til klyngens gendannelseskonti.
- setInstanceOption(instans, option, værdi)- Ændrer værdien af en konfigurationsindstilling i et klyngemedlem.
- setOption(option, value)- Ændrer værdien af en konfigurationsindstilling for hele klyngen.
- setPrimaryInstance(instance)- Vælger et specifikt klyngemedlem som det nye primære.
- status([options])- Beskriv klyngens status.
- switchToMultiPrimaryMode()- Skifter klyngen til multiprimær tilstand.
- switchToSinglePrimaryMode([instance])- Skifter klyngen til enkelt-primær tilstand.
Vi vil undersøge de fleste af de tilgængelige funktioner for at hjælpe os med at overvåge, administrere og skalere klyngen.
Overvågning af MySQL InnoDB-klyngeoperationer
Klyngestatus
For at kontrollere klyngestatus, skal du først bruge MySQL shell-kommandolinjen og derefter oprette forbindelse som eksempel@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Opret derefter et objekt kaldet "cluster" og erklær det som "dba" globalt objekt, som giver adgang til InnoDB-klyngeadministrationsfunktioner ved hjælp af AdminAPI (tjek MySQL Shell API-dokumenter):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Derefter kan vi bruge objektnavnet til at kalde API-funktionerne for "dba"-objekt:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Outputtet er ret langt, men vi kan filtrere det fra ved at bruge kortstrukturen. Hvis vi f.eks. kun vil se replikeringsforsinkelsen for db3, kan vi gøre følgende:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Bemærk, at replikeringsforsinkelse er noget, der vil ske i gruppereplikering, afhængigt af skriveintensiteten for det primære medlem i replikasættet og variablerne group_replication_flow_control_*. Vi vil ikke dække dette emne i detaljer her. Tjek dette blogindlæg for at forstå yderligere om gruppereplikeringsydelsen og flowkontrol.
En anden lignende funktion er describe()-funktionen, men denne er lidt mere enkel. Den beskriver klyngens struktur inklusive alle dens oplysninger, ReplicaSets og Instances:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}På samme måde kan vi filtrere JSON-outputtet ved hjælp af kortstruktur:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryNår den primære node gik ned (i dette tilfælde er db1), returnerede outputtet følgende:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Vær opmærksom på status OK_NO_TOLERANCE, hvor klyngen stadig er oppe og køre, men den kan ikke tolerere flere fejl, efter at en over tre node ikke er tilgængelig. Den primære rolle er blevet overtaget af db2 automatisk, og databaseforbindelserne fra applikationen vil blive omdirigeret til den korrekte node, hvis de forbinder via MySQL Router. Når db1 kommer online igen, bør vi se følgende status:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Det viser, at db1 nu er tilgængelig, men tjente som sekundær med skrivebeskyttet aktiveret. Den primære rolle er stadig tildelt til db2, indtil noget går galt med noden, hvor den automatisk vil blive overført til den næste tilgængelige node.
Tjek forekomsttilstand
Vi kan kontrollere tilstanden af en MySQL-node, før vi planlægger at tilføje den til klyngen ved at bruge checkInstanceState()-funktionen. Den analyserer de forekomst udførte GTID'er med de udførte/rensede GTID'er på klyngen for at afgøre, om forekomsten er gyldig for klyngen.
Følgende viser forekomsttilstanden for db3, da den var i selvstændig tilstand, før en del af klyngen:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Hvis noden allerede er en del af klyngen, bør du få følgende:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Overvåg enhver tilstand, der kan forespørges
Med MySQL Shell kan vi nu bruge den indbyggede \show and \watch kommando til at overvåge enhver administrativ forespørgsel i realtid. For eksempel kan vi få realtidsværdien af tråde forbundet ved at bruge:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Eller få den aktuelle MySQL-procesliste:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTVi kan derefter bruge \watch-kommandoen til at køre en rapport på samme måde som \show-kommandoen, men den opdaterer resultaterne med jævne mellemrum, indtil du annullerer kommandoen med Ctrl + C. Som vist i følgende eksempler:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTStandardopdateringsintervallet er 2 sekunder. Du kan ændre værdien ved at bruge --interval flaget og angive en værdi fra 0,1 op til 86400.
MySQL InnoDB Cluster Management Operations
Primær overgang
Primær instans er den node, der kan betragtes som lederen i en replikeringsgruppe, der har evnen til at udføre læse- og skriveoperationer. Kun én primær instans pr. klynge er tilladt i enkelt-primær topologitilstand. Denne topologi er også kendt som replikasæt og er den anbefalede topologitilstand for gruppereplikering med beskyttelse mod låsekonflikter.
For at udføre primær instansomskiftning skal du logge ind på en af databasenoderne som clusteradmin-brugeren og angive den databasenode, du vil fremme ved at bruge funktionen setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Vi har netop promoveret db1 som den nye primære komponent og erstattede db2, mens db3 forbliver som den sekundære node.
Lukning af klyngen
Den bedste måde at lukke klyngen ned ved at stoppe MySQL Router-tjenesten først (hvis den kører) på applikationsserveren:
$ myrouter/stop.shOvenstående trin giver klyngebeskyttelse mod utilsigtet skrivning fra applikationerne. Luk derefter én databasenode ad gangen ved at bruge standard MySQL stop-kommandoen, eller udfør systemlukning, som du ønsker:
$ systemctl stop mysqlStart af klyngen efter en nedlukning
Hvis din klynge lider af et fuldstændigt udfald, eller du ønsker at starte klyngen efter en ren nedlukning, kan du sikre dig, at den er omkonfigureret korrekt ved hjælp af dba.rebootClusterFromCompleteOutage()-funktionen. Det bringer simpelthen en klynge tilbage ONLINE, når alle medlemmer er OFFLINE. I tilfælde af at en klynge er stoppet helt, skal instanserne startes, og først derefter kan klyngen startes.
Sørg derfor for, at alle MySQL-servere er startet og kører. På hver databaseknude, se om mysqld-processen kører:
$ ps -ef | grep -i mysqlVælg derefter en databaseserver til at være den primære node, og opret forbindelse til den via MySQL-shell:
MySQL|JS> shell.connect("example@sqldat.com:3306");Kør følgende kommando fra den vært for at starte dem op:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Du vil blive præsenteret for følgende spørgsmål:
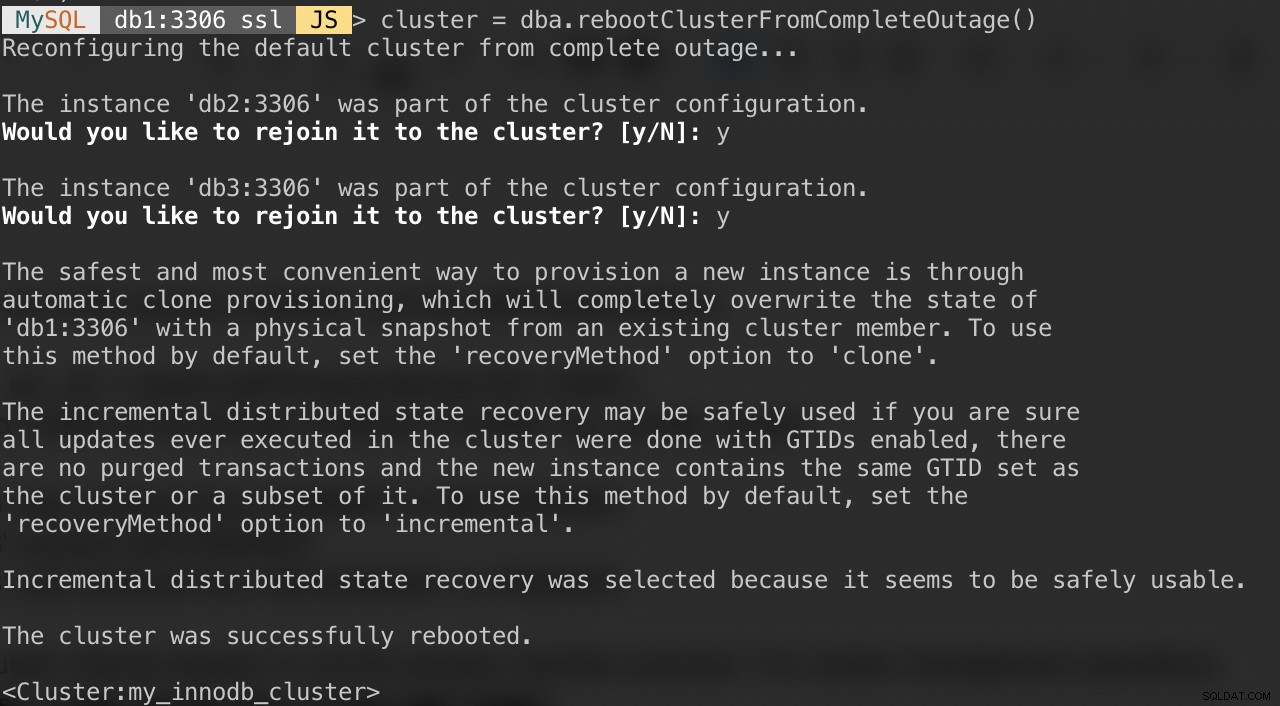
Når ovenstående er fuldført, kan du bekræfte klyngestatussen:
MySQL|db1:3306 ssl|JS> cluster.status()På dette tidspunkt er db1 den primære node og skriveren. Resten vil være de sekundære medlemmer. Hvis du gerne vil starte klyngen med db2 eller db3 som den primære, kan du bruge funktionen shell.connect() til at oprette forbindelse til den tilsvarende node og udføre genstartenClusterFromCompleteOutage() fra den pågældende node.
Du kan derefter starte MySQL Router-tjenesten (hvis den ikke er startet) og lade applikationen oprette forbindelse til klyngen igen.
Indstilling af medlems- og klyngeindstillinger
For at få de klynge-omfattende muligheder skal du blot køre:
MySQL|db1:3306 ssl|JS> cluster.options()Ovenstående viser de globale muligheder for replikasættet og også individuelle muligheder pr. medlem i klyngen. Denne funktion ændrer en InnoDB Cluster-konfigurationsmulighed i alle medlemmer af klyngen. De understøttede muligheder er:
- clusterName:strengværdi for at definere klyngenavnet.
- exitStateAction:strengværdi, der angiver handlingen for gruppereplikeringsafslutningstilstand.
- memberWeight:heltalsværdi med en procentvægt for automatisk primærvalg ved failover.
- failoverConsistency:strengværdi, der angiver den konsistensgaranti, som klyngen giver.
- konsistens: strengværdi, der angiver den konsistensgaranti, som klyngen giver.
- expelTimeout:heltalsværdi for at definere den tidsperiode i sekunder, som klyngemedlemmer skal vente på et ikke-svarende medlem, før de udelukker det fra klyngen.
- autoRejoinTries:heltalsværdi til at definere antallet af gange, en instans vil forsøge at slutte sig til klyngen igen efter at være blevet udvist.
- disableClone:boolesk værdi, der bruges til at deaktivere klonbrugen på klyngen.
I lighed med andre funktioner kan output filtreres i kortstruktur. Følgende kommando viser kun mulighederne for db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Du kan også få ovenstående liste ved at bruge help()-funktionen:
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Følgende kommando viser et eksempel på at indstille en indstilling kaldet memberWeight til 60 (fra 50) for alle medlemmer:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Vi kan også udføre konfigurationsstyring automatisk via MySQL Shell ved at bruge setInstanceOption()-funktionen og videregive databaseværten, indstillingens navn og værdi i overensstemmelse hermed:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)De understøttede muligheder er:
- exitStateAction: strengværdi, der angiver handlingen for gruppereplikeringsafslutningstilstand.
- memberWeight:heltalsværdi med en procentvægt for automatisk primærvalg ved failover.
- autoRejoinTries:heltalsværdi til at definere antallet af gange, en instans vil forsøge at slutte sig til klyngen igen efter at være blevet udvist.
- mærk en streng-id for forekomsten.
Skift til multi-primær/enkelt-primær tilstand
Som standard er InnoDB Cluster konfigureret med enkelt-primært, kun ét medlem, der er i stand til at udføre læsning og skrivning på et givet tidspunkt. Dette er den sikreste og anbefalede måde at køre klyngen på og egnet til de fleste arbejdsbelastninger.
Men hvis applikationslogikken kan håndtere distribuerede skrivninger, er det nok en god idé at skifte til multi-primær tilstand, hvor alle medlemmer i klyngen er i stand til at behandle læsninger og skrivninger på samme tid. For at skifte fra enkelt-primær til multi-primær tilstand skal du blot bruge switchToMultiPrimaryMode()-funktionen:
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Bekræft med:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}I multi-primær tilstand er alle noder primære og i stand til at behandle læsninger og skrivninger. Når du sender en ny forbindelse via MySQL Router på single-writer-porten (6446), sendes forbindelsen kun til én node, som i dette eksempel, db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Hvis applikationen opretter forbindelse til multi-writer-porten (6447), vil forbindelsen blive belastningsbalanceret via round robin-algoritme til alle medlemmer:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Som du kan se fra outputtet ovenfor, er alle noder i stand til at behandle læsninger og skrivninger med read_only =OFF. Du kan distribuere sikre skrivninger til alle medlemmer ved at oprette forbindelse til multi-writer-porten (6447) og sende de modstridende eller tunge skrivninger til single-writer-porten (6446).
For at skifte tilbage til den enkelt-primære tilstand skal du bruge switchToSinglePrimaryMode()-funktionen og angive ét medlem som den primære node. I dette eksempel valgte vi db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.På dette tidspunkt er db1 nu den primære node, der er konfigureret med skrivebeskyttet deaktiveret, og resten vil blive konfigureret som sekundær med skrivebeskyttet aktiveret.
MySQL InnoDB Cluster Scaling Operations
Opskalering (Tilføjelse af en ny DB-node)
Når du tilføjer en ny forekomst, skal en node først klargøres, før den får tilladelse til at deltage i replikeringsgruppen. Klargøringsprocessen vil blive håndteret automatisk af MySQL. Du kan også kontrollere instanstilstanden først, om noden er gyldig til at tilslutte sig klyngen ved at bruge checkInstanceState()-funktionen som tidligere forklaret.
For at tilføje en ny DB-node skal du bruge funktionen addInstances() og angive værten:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Det følgende er, hvad du ville få, når du tilføjer en ny instans:
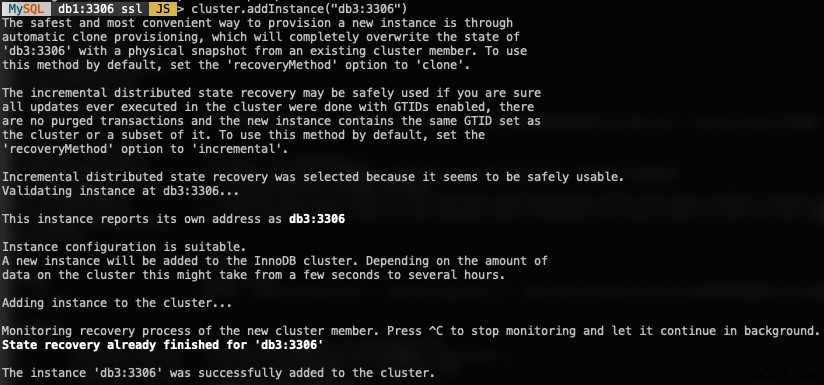
Bekræft den nye klyngestørrelse med:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router vil automatisk inkludere den tilføjede node, db3 i belastningsbalanceringssættet.
Nedskalering (fjernelse af en node)
For at fjerne en node skal du oprette forbindelse til en af DB-knuderne undtagen den, vi skal fjerne, og bruge funktionen removeInstance() med databaseinstansens navn:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Følgende er, hvad du ville få, når du fjerner en forekomst:
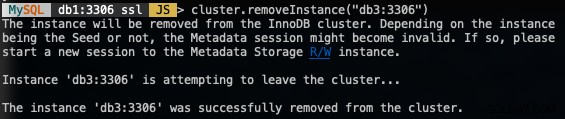
Bekræft den nye klyngestørrelse med:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router vil automatisk udelukke den fjernede node, db3 fra belastningsbalanceringssættet.
Tilføjelse af en ny replikeringsslave
Vi kan udskalere InnoDB-klyngen med asynkrone replikeringsslavereplikater fra enhver af klyngeknuderne. En slave er løst koblet til klyngen og vil være i stand til at håndtere en tung belastning uden at påvirke klyngens ydeevne. Slaven kan også være en levende kopi af databasen til gendannelsesformål. I multi-primær tilstand kan du bruge slaven som den dedikerede MySQL skrivebeskyttede processor til at udskalere læsearbejdsbelastningen, udføre analyseoperationer eller som en dedikeret backupserver.
På slaveserveren skal du downloade den seneste APT-konfigurationspakke, installere den (vælg MySQL 8.0 i konfigurationsguiden), installere APT-nøglen, opdatere repolist og installere MySQL-serveren.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellRediger MySQL-konfigurationsfilen for at forberede serveren til replikeringsslave. Åbn konfigurationsfilen via teksteditor:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfOg tilføj følgende linjer:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Genstart MySQL-serveren på slaven for at anvende ændringerne:
$ systemctl restart mysqlPå en af InnoDB Cluster-serverne (vi valgte db3), opret en replikeringsslavebruger og efterfulgt af en fuld MySQL-dump:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlOverfør dumpfilen fra db3 til slaven:
$ scp dump.sql example@sqldat.com:~Og udfør restaureringen på slaven:
$ mysql -uroot -p < dump.sqlMed master-data=1 vil vores MySQL-dumpfil automatisk konfigurere den GTID-eksekverede og rensede værdi. Vi kan bekræfte det med følgende sætning på slaveserveren efter gendannelsen:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Ser godt ud. Vi kan derefter konfigurere replikeringslinket og starte replikeringstrådene på slaven:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Bekræft replikeringstilstanden, og sørg for, at følgende status returnerer 'Ja':
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...På dette tidspunkt ser vores arkitektur nu sådan ud:
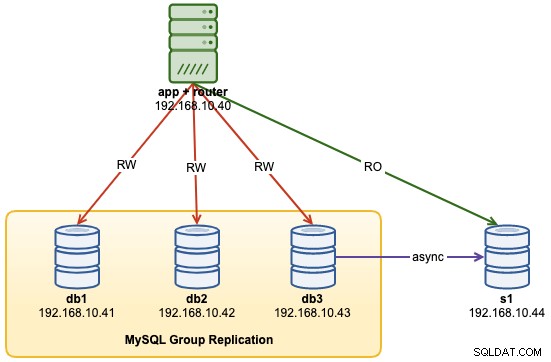
Almindelige problemer med MySQL InnoDB-klynger
Hukommelsesudmattelse
Når vi brugte MySQL Shell med MySQL 8.0, fik vi konstant følgende fejl, når forekomsterne blev konfigureret med 1 GB RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Opgradering af hver værts RAM til 2 GB RAM løste problemet. Tilsyneladende kræver MySQL 8.0-komponenter mere RAM for at fungere effektivt.
Mistet forbindelse til MySQL-server
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Konklusion
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).