MariaDB-replikering er en af de mest populære løsninger med høj tilgængelighed til MariaDB og er meget brugt af topvirksomheder som Booking.com og Google. Det er meget nemt at sætte op, med nogle afvejninger på den løbende vedligeholdelse som softwareopgraderinger, skemaændringer, topologiændringer, failover og gendannelse, som altid har været vanskelige. Ikke desto mindre bør du med det rigtige værktøjssæt være i stand til at håndtere topologien med lethed. I dette blogindlæg skal vi se nærmere på nogle tips til at overvåge MariaDB-replikering effektivt ved hjælp af ClusterControl.
Brug af Topology Viewer
En replikeringsopsætning består af en række roller. En node i en replikeringsopsætning kunne være en:
- Mester - Den primære forfatter/læser.
- Backup-master - En skrivebeskyttet slave med semi-synkroniseringsreplikering, udelukkende til masterredundans.
- Mellem master - Repliker fra en master, mens andre slaver replikerer fra denne node.
- Binlog-server - Indsaml/opbevar kun binlogs uden visningsdata.
- Slave – Repliker fra en master og er almindeligvis angivet som skrivebeskyttet.
- Multi-source slave - Repliker fra flere mastere.
Hver rolle har sit eget ansvar og begrænsning, og man skal forstå den korrekte topologi, når man beskæftiger sig med databasenoder. Dette gælder også for applikationen, hvor applikationen kun skal skrive til masterknuden på et givet tidspunkt. Derfor er det vigtigt at have overblik over, hvilken node der har hvilken rolle, så vi ikke skruer op for vores database.
I ClusterControl kan Topology Viewer give dig et overblik over replikeringstopologien og dens tilstand, som vist på følgende skærmbillede:
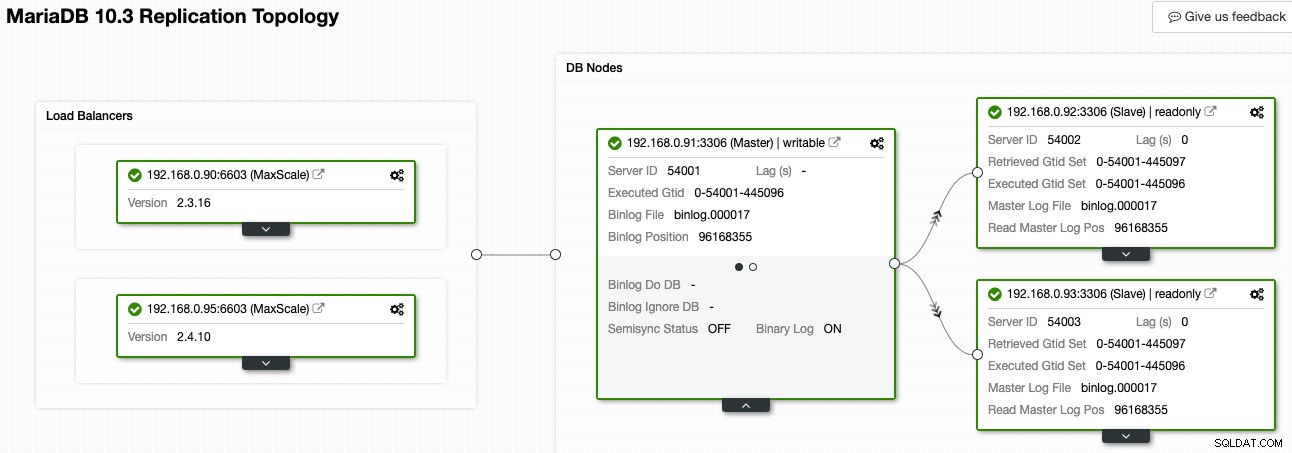
ClusterControl forstår MariaDB-replikering og er i stand til at visualisere topologien med det korrekte replikeringsdataflow, som repræsenteret af pilene, der peger på slaveknuderne. Vi kan nemt skelne, hvilken node der er master, slaver og load balancers (MaxScale) i vores replikeringsopsætning. Det grønne felt angiver, at alle vigtige tjenester kører som forventet med den tildelte rolle.
Overvej følgende skærmbillede, hvor en række af vores noder har problemer:
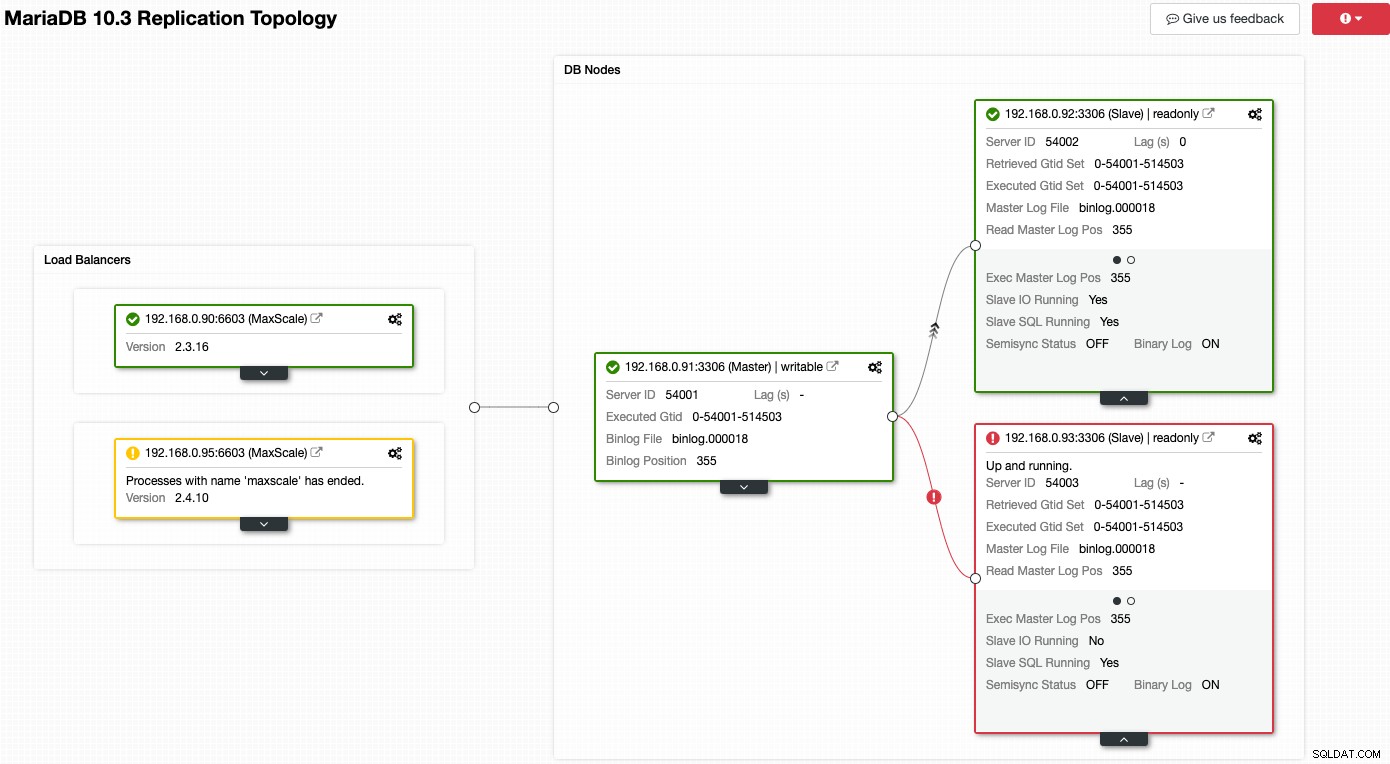
ClusterControl vil straks fortælle dig, hvad der er galt med den aktuelle topologi. En af slaverne (rød boks) viser "Slave IO Running" som Nej for at indikere et forbindelsesproblem, der skal replikeres fra masteren. Mens den gule boks viser, at vores MaxScale-tjeneste ikke kører. Vi kan også fortælle, at MaxScale-versionerne ikke er identiske for begge noder. Du kan også udføre administrationsopgaver ved at klikke på tandhjulsikonet (øverst til højre på hver boks), hvilket reducerer risikoen for at opfange en forkert node.
replikeringsforsinkelse
Dette er det vigtigste, hvis du stoler på datareplikeringskonsistens. Replikeringsforsinkelse opstår, når slaverne ikke kan følge med de opdateringer, der sker på masteren. Ikke-anvendte ændringer akkumuleres i slavernes relælogfiler, og versionen af databasen på slaverne bliver stadig mere forskellig fra masteren.
I ClusterControl kan du finde replikeringsforsinkelseshistogrammet under Oversigt -> Replikeringsforsinkelse, hvor ClusterControl konstant sampler Seconds_Behind_Master værdien fra "VIS SLAVE STATUS" output:
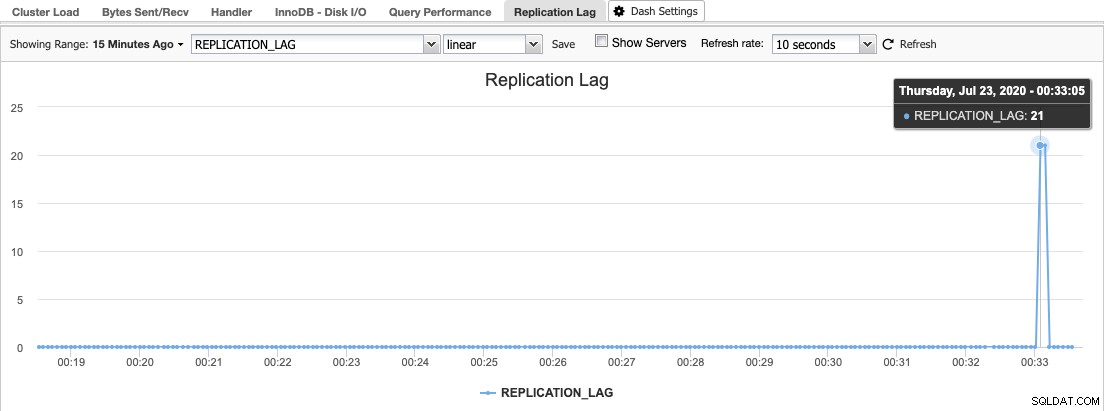
Replikeringsforsinkelse sker, når enten I/O-tråden eller SQL-tråden ikke kan klare de krav, der stilles til den. Hvis I/O-tråden lider, betyder det, at netværksforbindelsen mellem masteren og dens slaver er langsom eller har problemer. Du vil måske overveje at aktivere slave_compressed_protocol for at komprimere netværkstrafik eller rapportere til din netværksadministrator.
Hvis det er SQL-tråden, skyldes problemet sandsynligvis dårligt optimerede forespørgsler, som tager slaven for lang tid at anvende. Der kan være langvarige transaktioner eller for meget I/O-aktivitet. At der ikke er nogen primær nøgle på slavetabellerne, når du bruger ROW- eller MIXED-replikeringsformatet, er også en almindelig årsag til lag på denne tråd. Tjek, at master- og slaveversionerne af tabeller har en primær nøgle.
Nogle flere tips og tricks er dækket i dette blogindlæg, Sådan reducerer du replikeringsforsinkelse i multi-sky-implementeringer.
Binær/relæ-logstørrelse
Det er vigtigt at overvåge binær- og relælog-diskstørrelsen, fordi den kan forbruge en betydelig mængde lagerplads på hver node i en replikeringsklynge. Normalt ville man indstille systemvariablen expire_logs_days til at udløbe binære logfiler automatisk efter et givet antal dage, for eksempel expire_logs_days=7. Størrelsen af binære logfiler er fuldstændig afhængig af antallet af oprettede binære hændelser (indkommende skrivninger) og lidt, som vi ved, hvor meget diskplads det ville forbruge, før logfilerne udløber af MariaDB. Husk, at hvis du aktiverer log_slave_updates på slaverne, vil størrelsen af logfiler næsten blive fordoblet på grund af eksistensen af både binære og relælogfiler på den samme server.
For ClusterControl kan vi indstille en tærskel for diskpladsudnyttelse under ClusterControl -> Indstillinger -> Tærskler for at få en advarsel og kritiske meddelelser som nedenfor:
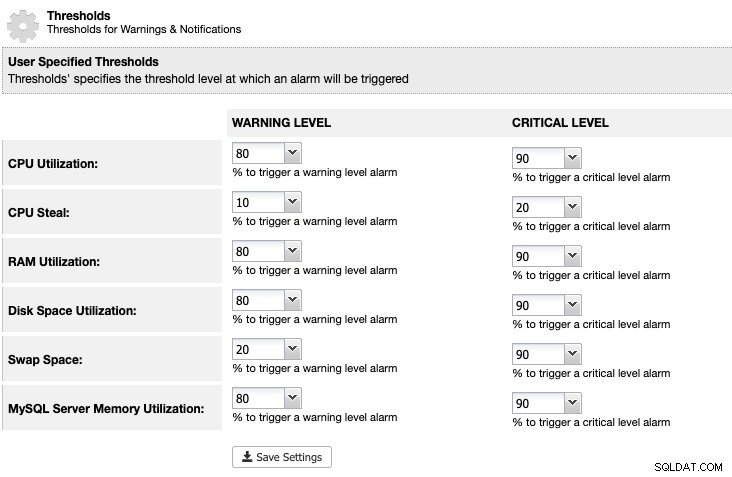
ClusterControl overvåger al diskplads relateret til MariaDB-tjenester såsom placeringen af MariaDB-data biblioteket, det binære logbibliotek og også rodpartitionen. Hvis du har nået tærsklen, kan du overveje at rense de binære logfiler manuelt ved at bruge kommandoen PURGE BINARY LOGS, som forklaret og diskuteret i denne artikel.
Aktiver overvågningsdashboards
ClusterControl giver to overvågningsmuligheder til at sample databasenoderne - agentfri eller agentbaseret. Standarden er agentløs, hvor prøvetagning sker via SSH i en pull-only mekanisme. Agentbaseret overvågning kræver, at en Prometheus-server kører, og at alle overvågede noder konfigureres med mindst tre eksportører:
- Proceseksportør (port 9011)
- Eksportør af node/systemmetrik (port 9100)
- MySQL/MariaDB-eksportør (port 9104)
For at aktivere det agentbaserede overvågningsdashboard skal man gå til ClusterControl -> Dashboards -> Aktiver agentbaseret overvågning. Når det er aktiveret, vil du se et sæt dashboards konfigureret til vores MariaDB-replikering, som giver os et meget bedre indblik i vores replikeringsopsætning. Følgende skærmbillede viser, hvad du ville se for masternoden:
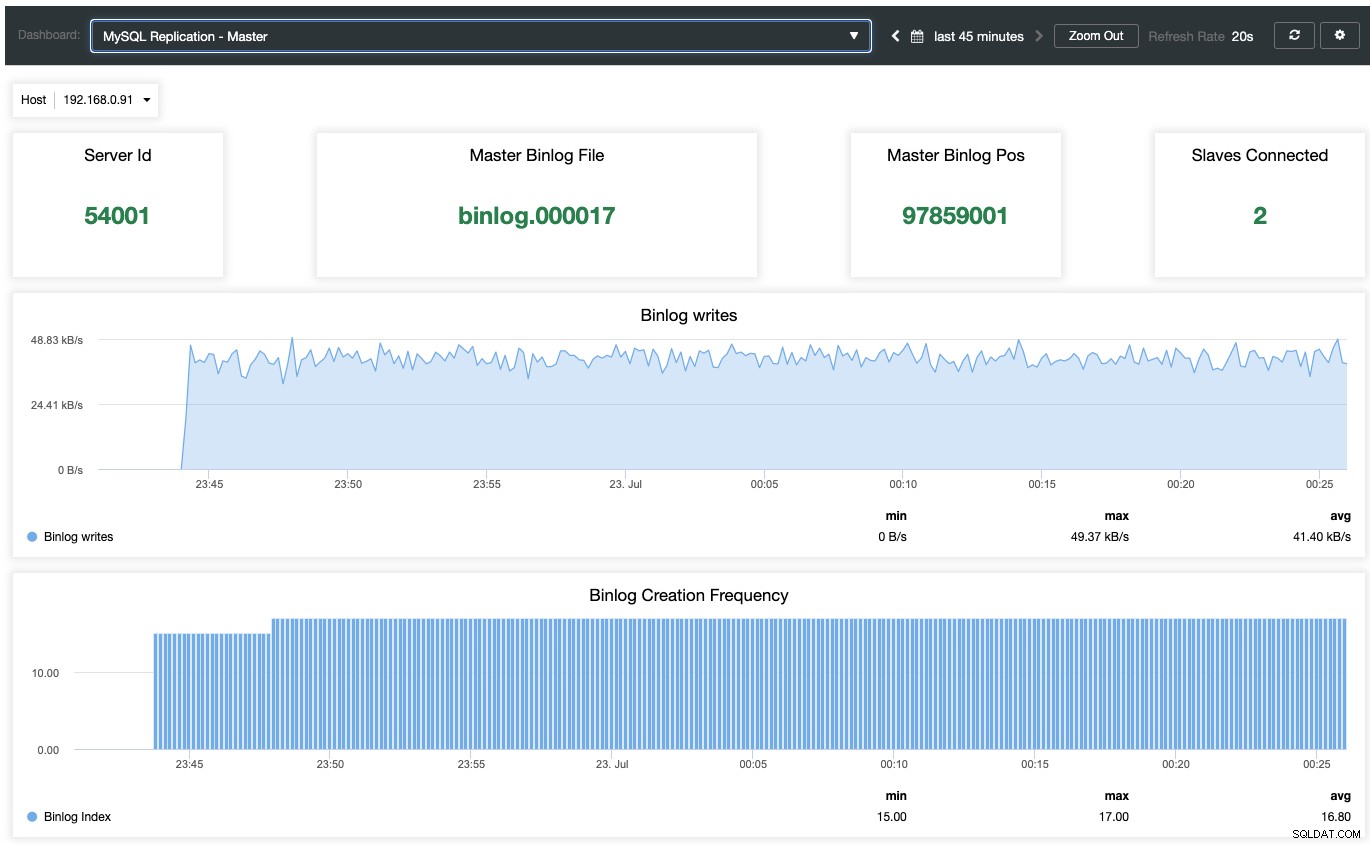
Udover MariaDB-standardovervågningsdashboards som generelle, caches og InnoDB-metrics, kan du vil blive præsenteret med et replikeringsdashboard. For masterknudepunktet kan vi få en masse nyttig information om masterens tilstand, skrivegennemstrømningen og binlog-oprettelsesfrekvensen.
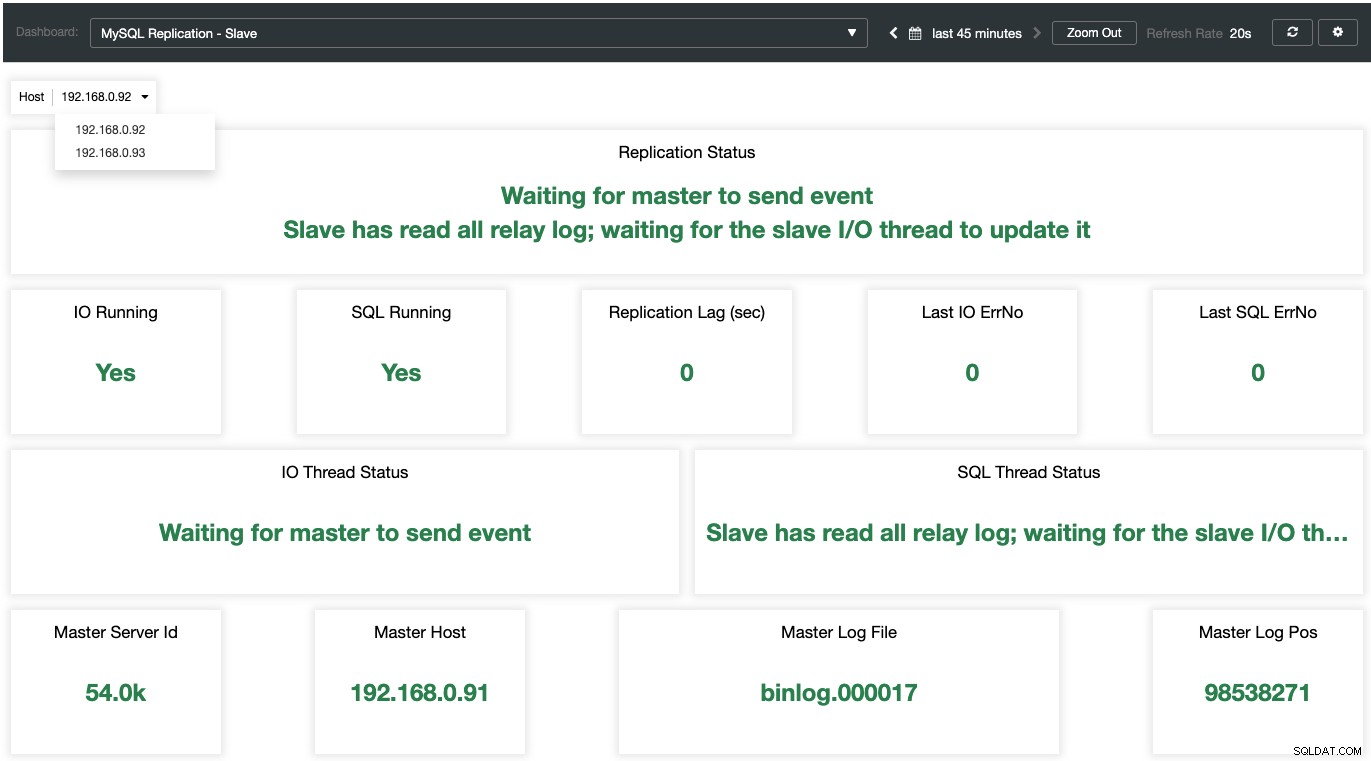
Mens for slaverne er alle de vigtige tilstande samplet og opsummeret som følgende skærmbillede. hvis alt er grønt, er du i gode hænder:
Forstå MariaDB-fejlloggen
MariaDB logger sine vigtige hændelser inde i fejlloggen, hvilket er nyttigt til at forstå, hvad der foregik på serveren, især før, under og efter en topologiændring. ClusterControl giver en central visning af fejllogfiler under ClusterControl -> Logs -> Systemlogs ved at trække dem fra hver databaseknude. Du klikker på "Opdater logs" for at udløse et job for at trække de seneste logfiler fra serveren.
Samlede filer er repræsenteret i en navigationstræstruktur og et tekstområde med syntaksfremhævning for bedre læsbarhed:
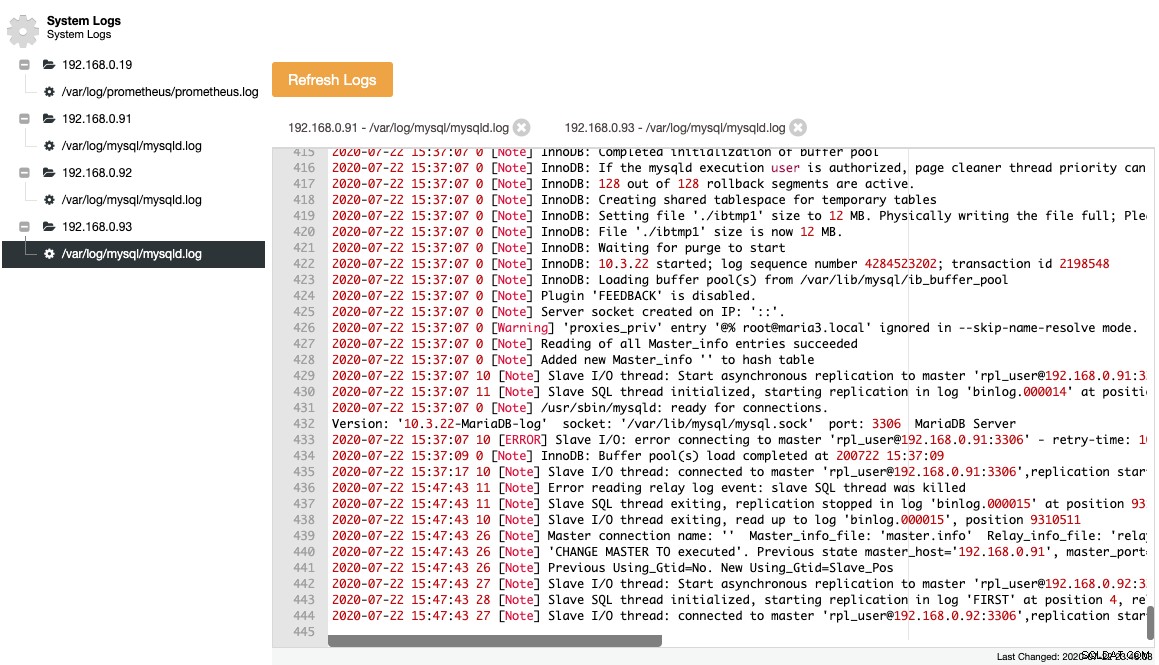
Fra ovenstående skærmbillede kan vi forstå rækkefølgen af begivenheder, og hvad der skete med denne knude under en topologiændringshændelse. Fra de sidste 12 linjer i fejlloggen ovenfor, havde slaven en fejl, når den først oprettede forbindelse til masteren, og den sidste binære logfil og position blev registreret i loggen, før den stoppede. Derefter blev en nyere CHANGE MASTER-kommando udført med GTID-oplysninger, som vist i linjen "Forrige Using_Gtid=No. New Using_Gtid=Slave_Pos", og derefter genoptages replikeringen, som vi ønskede.
MariaDB-advarsler og -meddelelser
Overvågning er ufuldstændig uden advarsler og meddelelser. Alle hændelser og alarmer genereret af ClusterControl kan sendes til e-mailen eller andre understøttede tredjepartsværktøjer. For e-mail-notifikationer kan man konfigurere, om typen af begivenheder skal leveres med det samme, ignoreres eller fordøjes (en daglig opsummeret rapport):

For alle alvorlige hændelser, anbefales det at indstille alt til "Lever", så du får underretningerne så hurtigt som muligt. Indstil "Digest" til advarselshændelser, så du er godt klar over klyngens helbred og tilstand.
Du kan integrere dine foretrukne kommunikations- og meddelelsesværktøjer med ClusterControl ved at bruge funktionen Notifications Management under ClusterControl -> Integrationer -> Tredjepartsmeddelelser. ClusterControl kan sende alarmer og hændelser til PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow eller enhver brugerregistreret webhooks.
Følgende skærmbillede viser, at alle kritiske hændelser vil blive skubbet til den konfigurerede telegramkanal for vores MariaDB 10.3-replikeringsklynge:

ClusterControl understøtter også chatbot-integration, hvor du kan interagere med controller-tjenesten via s9s-klient direkte fra dit meddelelsesværktøj som vist i dette blogindlæg, Automatiser din database med CCBot:ClusterControl Hubot Integration.
Konklusion
ClusterControl tilbyder et komplet sæt af proaktive overvågningsværktøjer til dine databaseklynger. Brug ClusterControl til at overvåge din MariaDB-replikeringsopsætning, fordi de fleste af overvågningsfunktionerne er tilgængelige gratis i community-udgaven. Gå ikke glip af dem!